
Kyuubi 实践 | 如何优化 Spark 小文件,Kyuubi 一步搞定!

Hive 表中太多的小文件会影响数据的查询性能和效率,同时加大了 HDFS NameNode 的压力。Hive (on MapReduce) 一般可以简单的通过一些参数来控制小文件,而 Spark 中并没有提供小文件合并的功能。下面我们来简单了解一下 Spark 小文件问题,以及如何处理小文件。
![]() 1.1 环境
1.1 环境
Kyuubi 版本:1.6.0-SNAPSHOT
Spark 版本:3.1.3、3.2.0
![]() 1.2 TPCDS 数据集
1.2 TPCDS 数据集
Kyuubi 中提供了一个 TPCDS Spark Connector,可以通过配置 Catalog 的方式,在读取时自动生成 TPCDS 数据。
只需要将 kyuubi-spark-connector-tpcds_2.12-1.6.0-SNAPSHOT.jar 包放入 Spark jars 目录中,并配置:
spark.sql.catalog.tpcds=org.apache.kyuubi.spark.connector.tpcds.TPCDSCatalog;
这样我们就可以直接读取 TPCDS 数据集:
use tpcds;
show databases;
use sf3000;
show tables;
select * from sf300.catalog_returns limit 10;
![]() 1.3 小文件产生
1.3 小文件产生
首先我们在 Hive 中创建一个 sample.catalog_returns 表,用于写入生成的 TPCDScatalog_returns 数据,并添加一个 hash 字段作为分区。


我们先关闭 Kyuubi 的优化,读取 catalog_returns 数据并写入 Hive:

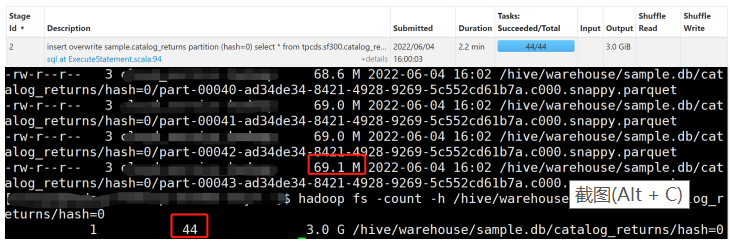
Spark SQL 最终产生的文件数最多可能是最后一个写入的 Stage 的 Task 数乘以动态分区的数量。我们 可以看到由于读取输入表的 Task 数是 44 个,所以最终产生了 44 个文件,每个文件大小约 69 M。
![]() 1.4 改变分区数(Repartition)
1.4 改变分区数(Repartition)
由于写入的文件数跟最终写入 Stage 的 Task 数据有关,那么我们可以通过添加一个 Repartition 操作, 来减少最终写入的 task 数,从而控制小文件:

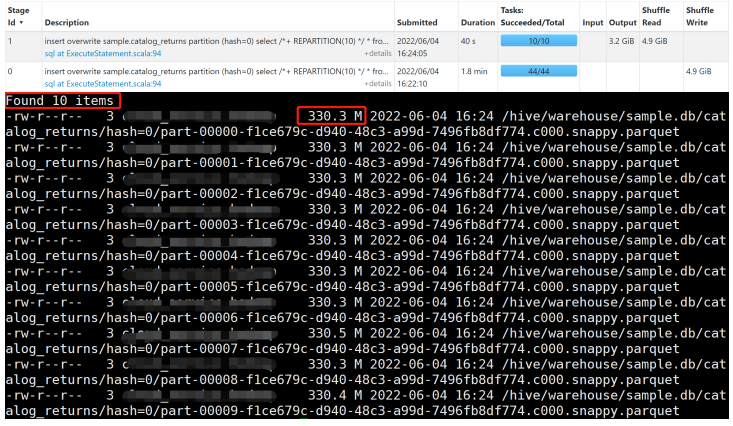
添加 REPARTITION(10) 后,会在读取后做一个 Repartition 操作,将 partition 数变成 10,所以最终 写入的文件数变成 10 个。
![]() 1.5 Spark AQE 自动合并小分区
1.5 Spark AQE 自动合并小分区
Spark 3.0 以后引入了自适应查询优化(Adaptive Query Execution, AQE),可以自动合并较小的分区。
开启 AQE,并通过添加 distribute by cast(rand() * 100 as int) 触发 Shuffle 操作:

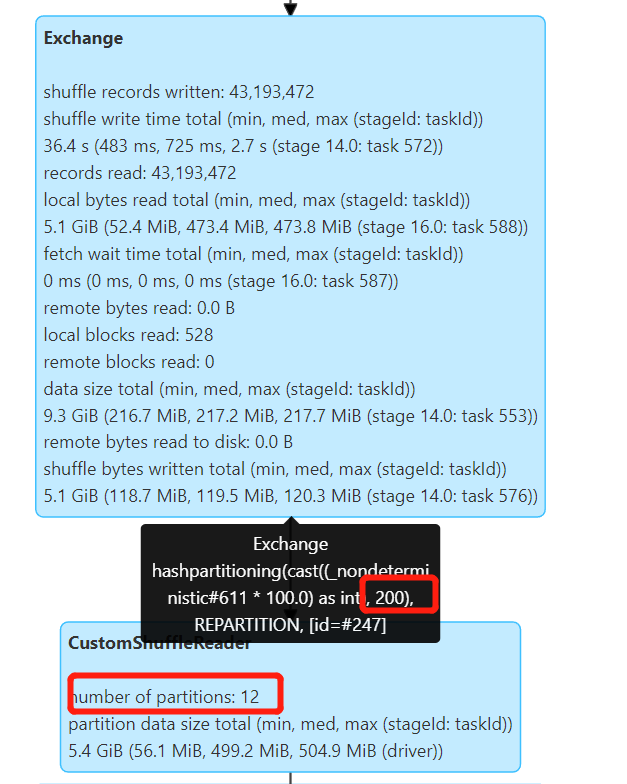
默认 Shuffle 分区数 spark.sql.shuffle.partitions=200 ,如果不开启 AQE 会产生 200 个小文件, 开启 AQE 后,会自动合并小分区,根据spark.sql.adaptive.advisoryPartitionSizeInBytes=512M 配置合并较小的分区,最终产生 12 个文件。

Apache Kyuubi (Incubating) 作为增强版的 Spark Thrift Server 服务,可通过 Spark SQL 进行大规模的 数据处理分析。Kyuubi 通过 Spark SQL Extensions 实现了很多的 Spark 优化,其中包括了RepartitionBeforeWrite 的优化,再结合 Spark AQE 可以自动优化小文件问题,下面我们具体分析 一下 Kyuubi 如何实现小文件优化。
![]() 2.1 Kyuubi 如何优化小文件
2.1 Kyuubi 如何优化小文件
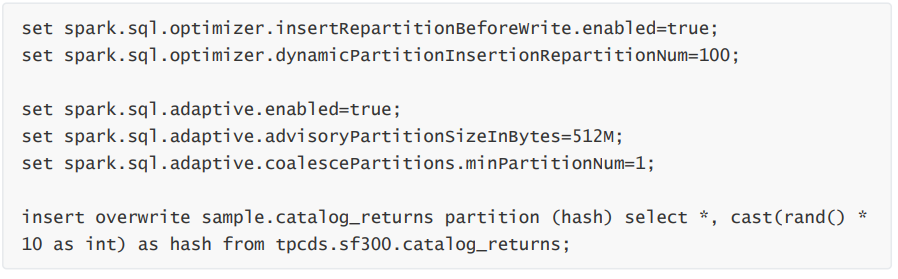
Kyuubi 提供了在写入前加上 Repartition 操作的优化,我们只需要将 kyuubi-extension-spark-3- 1_2.12-1.6.0-SNAPSHOT.jar 放入 Spark jars 目录中,并配置spark.sql.extensions=org.apache.kyuubi.sql.KyuubiSparkSQLExtension 。相关配置:
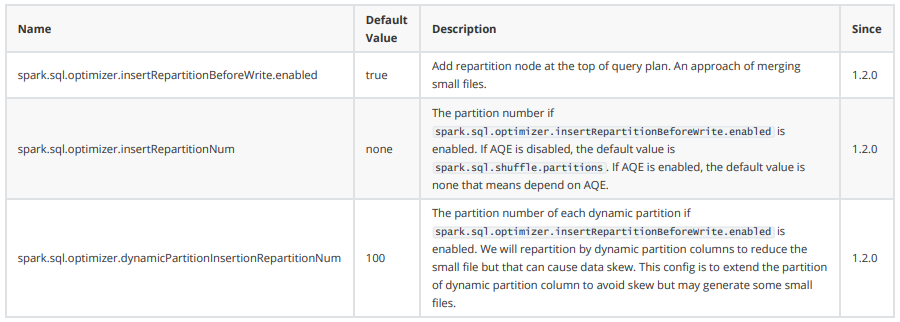
通过 spark.sql.optimizer.insertRepartitionNum 参数可以配置最终插入 Repartition 的分区数, 当不开启 AQE,默认为 spark.sql.shuffle.partitions 的值。需要注意,当我们设置此配置会导致 AQE 失效,所以开启 AQE 不建议设置此值。
对于动态分区写入,会根据动态分区字段进行 Repartition,并添加一个随机数来避免产生数据倾斜,spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum 用来配置随机数的范围,不 过添加随机数后,由于加大了动态分区的基数,还是可能会导致小文件。这个操作类似在 SQL 中添加distribute by DYNAMIC_PARTITION_COLUMN, cast(rand() * 100 as int)。
![]() 2.2 静态分区写入
2.2 静态分区写入
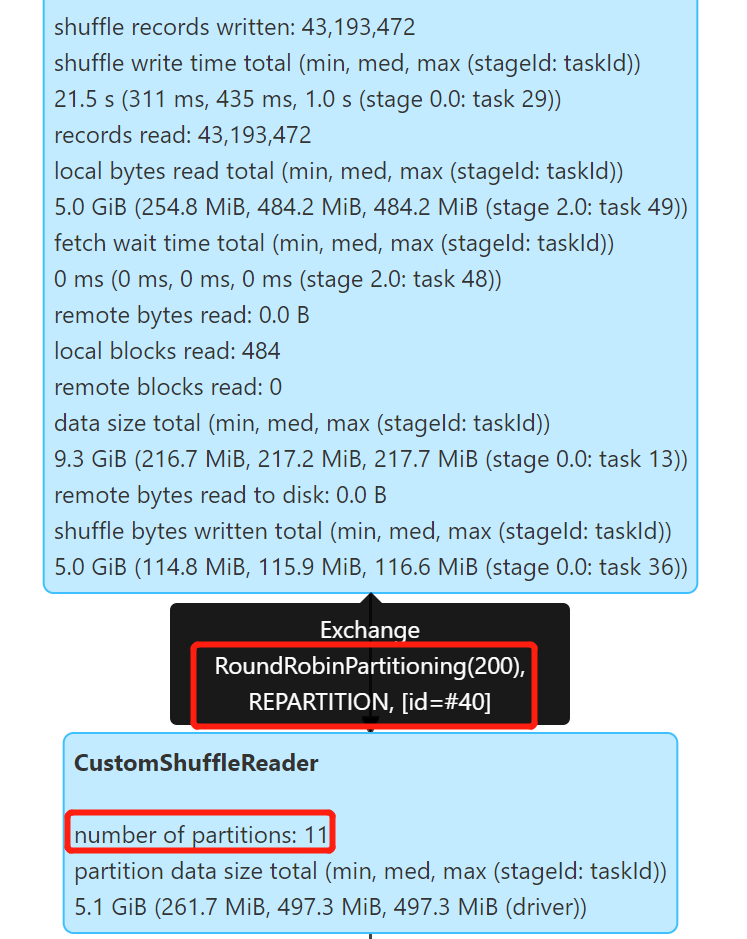
开启 Kyuubi 优化和 AQE,测试静态分区写入:

可以看到 AQE 生效了,很好地控制了小文件,产生了 11 个文件,文件大小 314.5 M 左右。

![]() 2.3 动态分区写入
2.3 动态分区写入
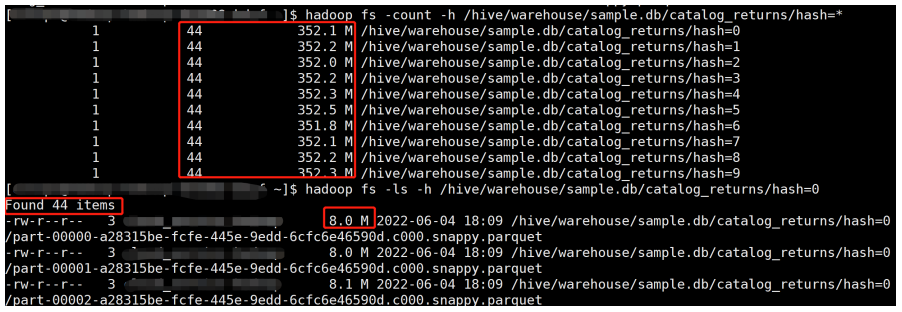
我们测试一下动态分区写入的情况,先关闭 Kyuubi 优化,并生成 10 个 hash 分区:

产生了 44 × 10 = 440 个文件,文件大小 8 M 左右。
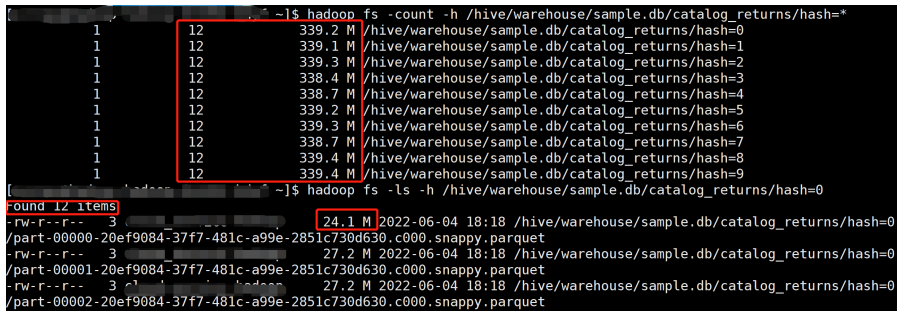
开启 Kyuubi 优化和 AQE:
产生了 12 × 10 = 120 个文件,文件大小 30 M 左右,可以看到小文件有所改善,不过仍然不够理想。
此案例中 hash 分区由 rand 函数产生,分布比较均匀,所以我们将spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum 设置成 0 ,重新运行,同时将动态分区数设置为5 :
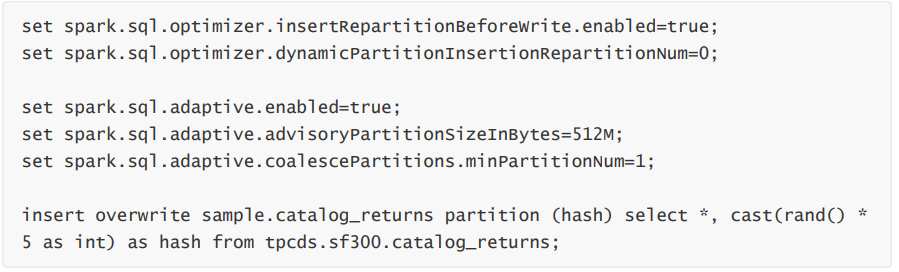
由于动态分区数只有 5 个,所以实际上只有 5 个 Task 有数据写入,每个 Task 对应一个分区,导致最终每个分区只有一个较大的大文件。

通过上面的分析可以看到,对于动态分区写入,Repartition 的优化可以缓解小文件,配置spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum=100 解决了数据倾斜问题, 不过同时还是可能会有小文件。
![]() 2.4 Rebalance 优化
2.4 Rebalance 优化
Spark 3.2+ 引入了 Rebalance 操作,借助于 Spark AQE 来平衡分区,进行小分区合并和倾斜分区拆 分,避免分区数据过大或过小,能够很好地处理小文件问题。
Kyuubi 对于 Spark 3.2+ 的优化,是在写入前插入 Rebalance 操作,对于动态分区,则指定动态分区列 进行 Rebalance 操作。不再需要 spark.sql.optimizer.insertRepartitionNum 和spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum 配置。
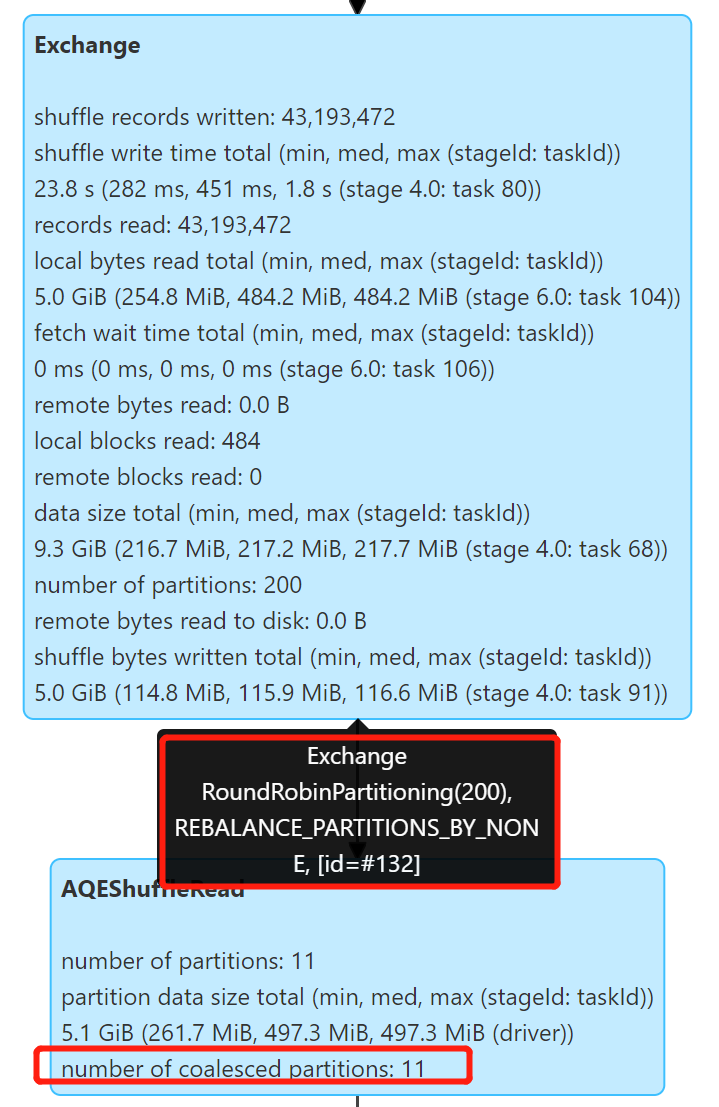
测试静态分区写入,使用 Spark 3.2.0 开启 Kyuubi 优化和 AQE:

Repartition 操作自动合并了小分区,产生了 11 个文件,文件大小 334.6 M 左右,解决了小文件的问题。

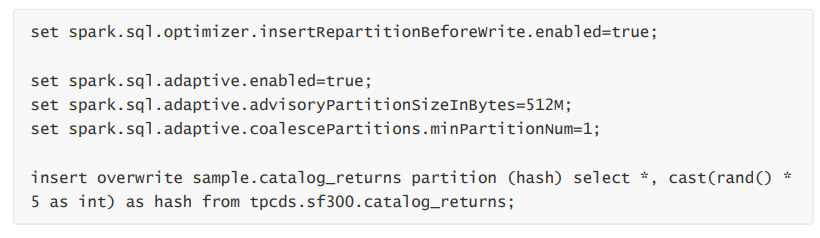
测试动态分区写入,使用 Spark 3.2.0 开启 Kyuubi 优化和 AQE,生成 5 个动态分区:
Repartition 操作自动拆分较大分区,产生了 2 × 5 = 10 个文件,文件大小 311 M 左右,很好地解决倾斜问题。
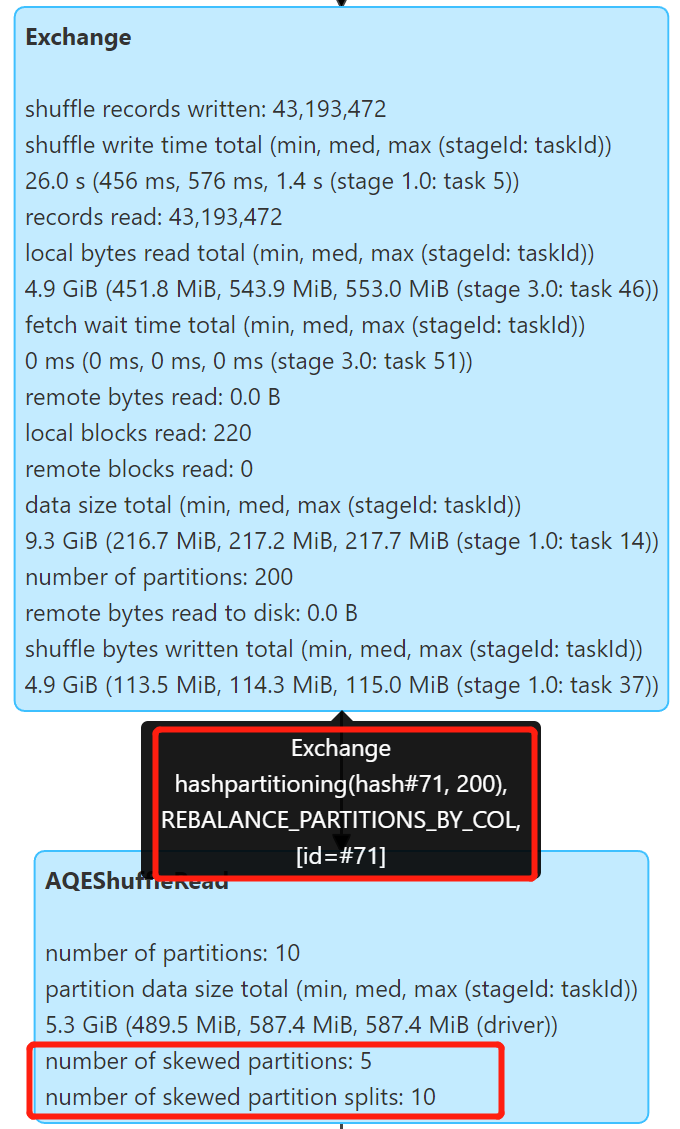
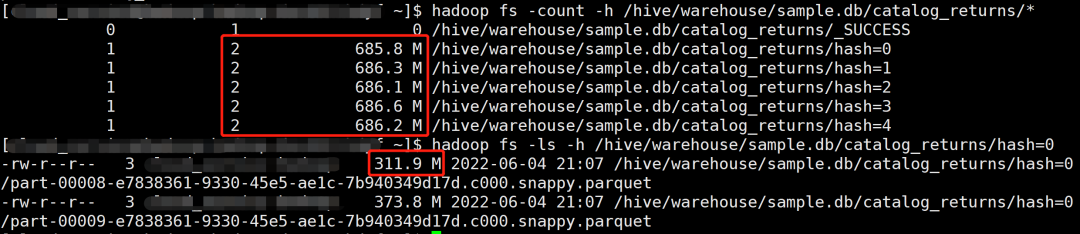
从上面的分析可以看到,对于 Spark 3.2+,Kyuubi 结合 Rebalance 能够很好地解决小文件问题,对于 Spark 3.1,Kyuubi 也能自动优化小文件,不过动态分区写入的情况还是可能存在问题。
相关的配置总结:

更多 AQE 配置可以参考:How To Use Spark Adaptive Query Execution (AQE) in Kyuubi
![]() END
END
如果你也想成为 Committer
👇👇👇👇👇👇
·Become A Committer of Apache Kyuubi

