
SR-LUT | 比bicubic还快的图像超分,延世大学提出将查找表思路用于图像超分
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

本文是延世大学在图像超分方面的颠覆性之作,它首次提出采用LUT进行图像超分,尽管该方法的性能仅比传统插值方法稍好,甚至不如FSRCNN性能高。但是,该方案最大的优势在于推理速度快,比双三次插值还要快。SR-LUT斜眼看到插值方案以及深度学习方案,轻轻的说了句:“论速度,还有谁!”
Abstract
从上古时代的“插值方法”到中世纪的“自相似性方案”,再到 前朝时代的“稀疏方案”,最后到当前主流的“深度学习方案”,图像超分领域诞生了数以千计的方案,他们均期望对低分辨率图像遗失的纹理细节进行复原重建。伴随着移动设备、硬件显示设备的普及,实用超分的需求进一步提升。尽管当前主流的深度学习方案具有更好的视觉质量,但它们往往依赖于并行计算模组(比如GPU),而在手机或者TV端的部署难度非常大(主要体现在速度方面,输入动不动就上2M,8M,16M,此时我们就非常羡慕检测和分类领域不超过500x500输入,😂)。
为此,通过采用查找表,我们提出一种高效且实用的超分方案。我们采用小感受野训练超分网络并将期输出值迁移到查找表;在测试阶段,我们根据输入从LUT中索引与计算的HR输出。由于不需要大量的浮点计算,所提方法计算非常快。
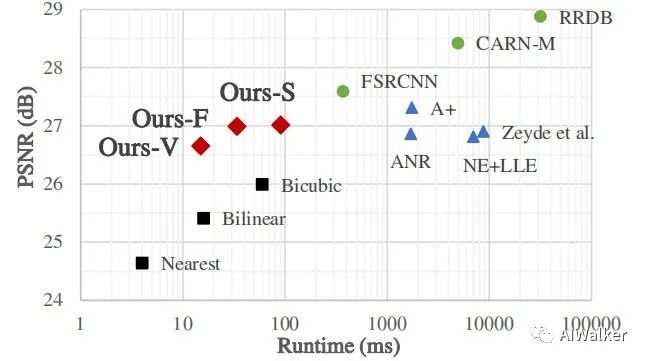
最后,我们通过实验验证了所提方法的效率与有效性。值得一提的是,所提方法具有比双三次插值更快、更好多的视觉效果。下图给出了三星S7手机上的度量对比(输入为,输出为)。
Method
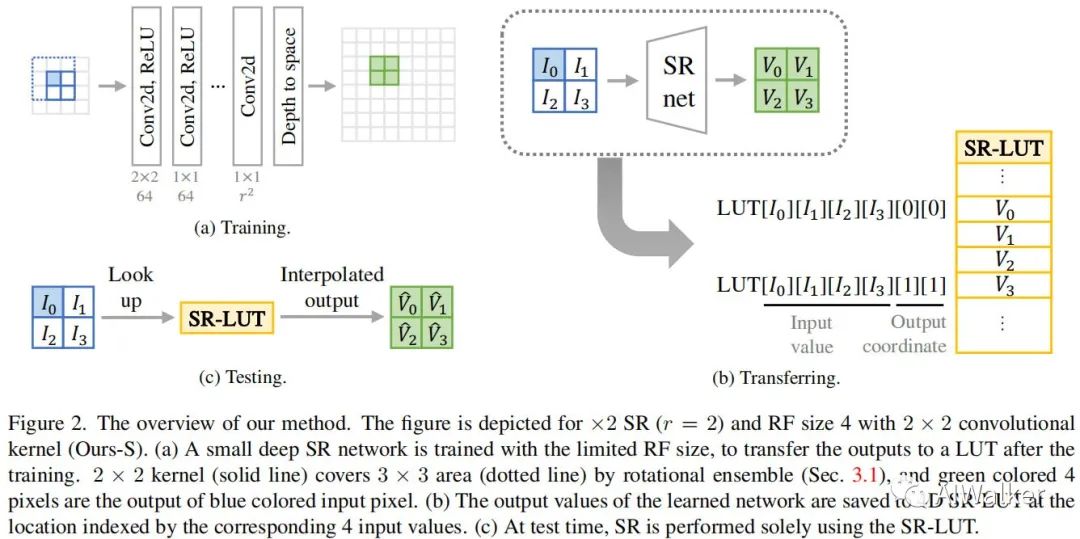
上图给出了本文所提方案SR-LUT训练与测试示意图,整个过程包含这样几个步骤:
首先,训练一个具有非常小感受野的的超分网络,见上图a; 然后,将上述训练网络的输出迁移到SR-LUT,见上图c; 最后,在对于输入图像块,其对应的HR像素可以通过SR-LUT得到。
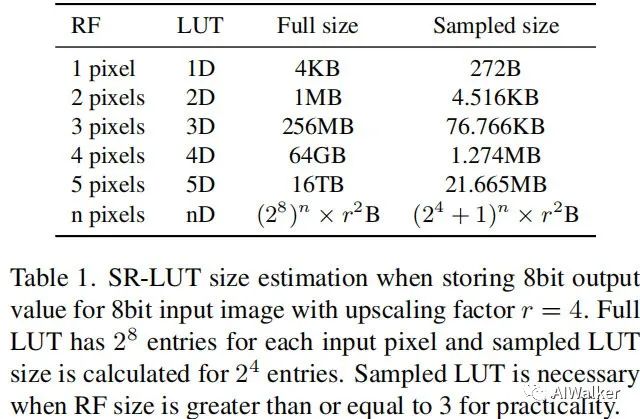
对于一个实用SR-LUT,超分网络的感受野应当足够小,因为SR-LUT的大小会随感受野指数增加。上表对比了不同感受野时的SR-LUT大小对比。从中可以看到:
当感受野为2,超分倍率为4时,SR-LUT的大小为1M; 当感受野为3、4、5时,SR-LUT的大小迅速增长到256M、64G、1T。
当感受野尺寸大于3时,SR-LUT的大小非常大,不利于实际应用。在本文,我们令Ours-V表示感受野为2,Ours-F的感受野为3,Ours-S的感受野为4。接下来的内容,我们主要以感受野为4的Ours-S为例进行介绍,其他感受野的同样适用。
Training Deep SR Network
Network Architecture 受限于感受野,过多的卷积层并不会提升性能但会加速收敛。因此,我们构建了一个6层的超分网络。对于感受野为4而言,我们固定第一层的卷积为,其他卷积层的尺寸为1。通道数设为64,最后一层的输出通道数设为。注:网络的层数并不会影响最终的推理耗时,因其仅用于构建SR-LUT。
Rotational Ensemble Training 一般来说,更多的像素有助于提升超分性能。然而,感受野为4的模型对于HR图像估计而言太小了。比如FSRCNN需要169个像素,甚至双三次插值都需要16个像素。为探索LR输入更多区域,我们在训练阶段采用了旋转集成策略(即常见的0-90-180-270旋转),通过这种方式其感受野就扩充到了9个像素。此时,最终的输出可以表示如下:
超分网络的训练采用常规的训练方式即可。
旋转自集成策略往往用于在测试阶段提升模型的性能,而本文则将其用到了训练阶段提升模型性能。
Transferring to LUT
完成超分模型训练后,我们构建一个4D尺寸的SR-LUT。对于全LUT,我们计算超分模型的所有可能输出并将其保存到LUT。输入值则作为LUT的索引,对应位置保存对应的输出值。
实际上,我们如果采用均匀采用LUT,SR-LUT会非常大,约64GB。具体来收,我们将输入空间采样均匀的拆分为,也就是说,我们对原始输入范围进行下采样。因此,下采样的后的值变成了,SR-LUT的大小就变成了1.274MB。在测试阶段,非采样点的值通过近邻采样点插值,这个地方有点类似与3DLUT。
Testing Using SR-LUT
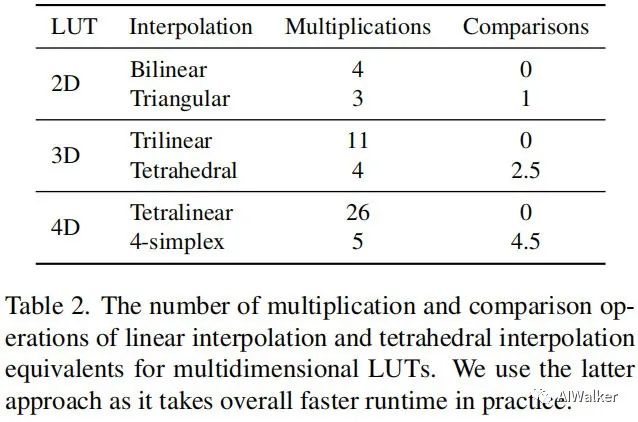
一旦完成SR-LUT的构建,我们就可以通过SR-LUT进行图像超分。为得到最终的输出,我们还需要应用了插值,这里我们已线性插值作为基线。线性、三次、四次等插值与SR-LUT则构成了2D、3D、4D、5D+SR-LUT。实际上,我们采用了四面体插值,它比三次插值更快。下图对比了不同插值方法的计算量对比,相比三次插值,四面体插值计算量少了2.5倍。
为更好的理解四面体插值,我们以下图为例进行简单的说明。对于输入,我们首先将其拆分为高4位和低四位,两者的高4位分别位1和3,用于确定近邻采样点,低4位分别位8和12,用于确定加权值。两个边界顶点位;另一个边界顶点通过比较确定,由于,所以选择。每个顶点的加权值对应了其对角面积:。最终输出值计算:.
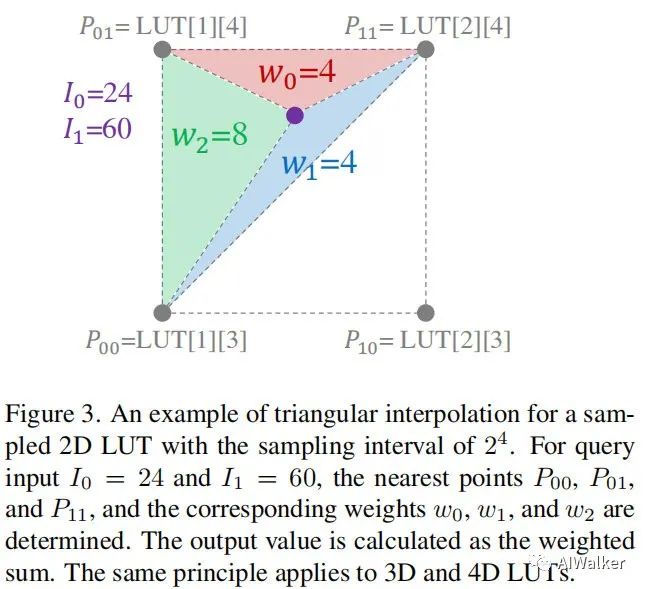
四面体插值可以扩展到4D空间,此时仅需5个边界顶点,下表给出了示意说明。

Experiments
训练数据为DIV2K,训练方式略。直接看结果吧。
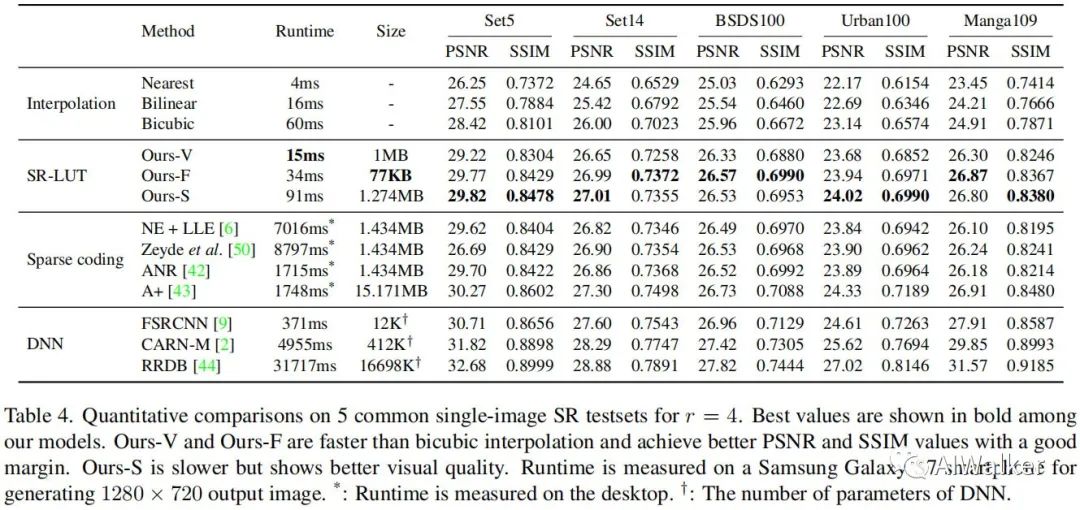
从上表对比可以看到:
相比双三次插值,所提Ours-V速度快45ms,PSNR指标高0.8dB; 相比双三次插值,所提Ours-F速度快26ms,PSNR指标高1.35dB; 相比双三次插值,所提Ours-S速度慢31ms,PSNR指标高1.40dB; 相比稀疏编码方法,所提方法具有具有更快的推理速度、更高PSNR指标,且LUT比起字典更小; 相比FSRCNN,所提方案指标稍低,但推理速度快25倍; 总而言之,所提方法具有超快的推理速度,同时具有比插值方法更优的性能。

上图对比了不同方案的视觉效果对比,从中可以看到:
由于较小的感受野,Ours-V与Ours-S存在一定程度的伪影问题; 相比双三次插值,所提方案生成结果更为锐利。
【论文与code】下载
链接:https://pan.baidu.com/s/1YS5YY06W7l5zrh-vXOREAQ
密码:3e4n
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文 点亮
,告诉大家你也在看
