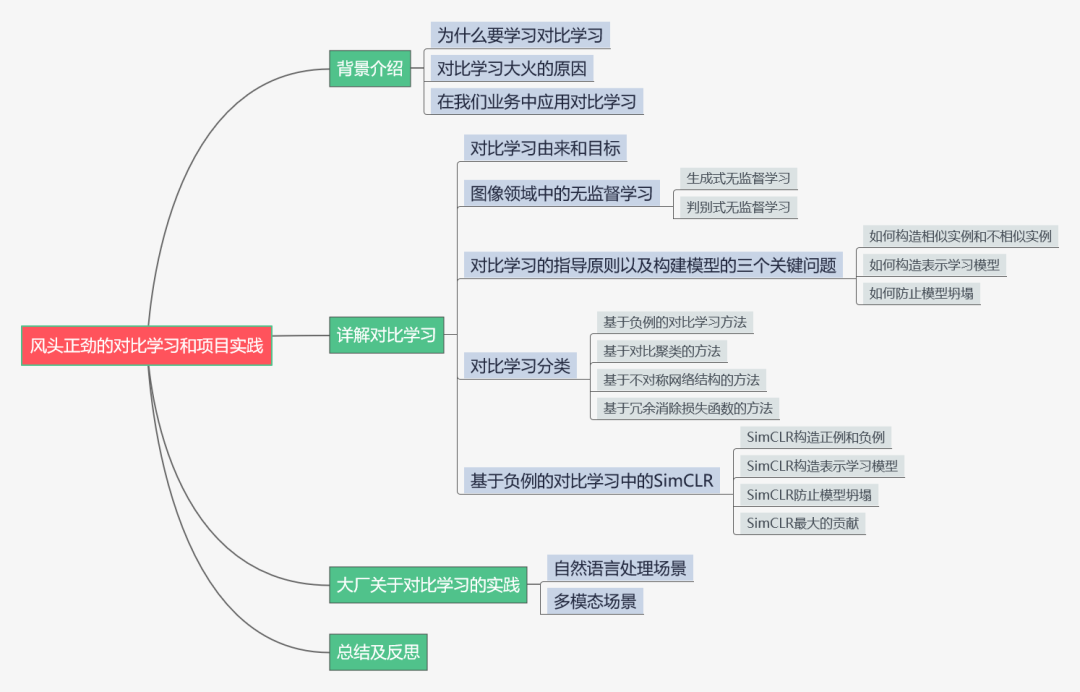
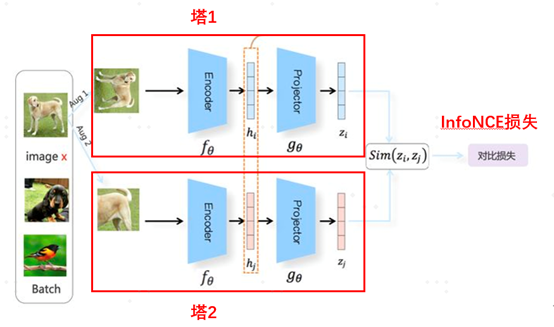
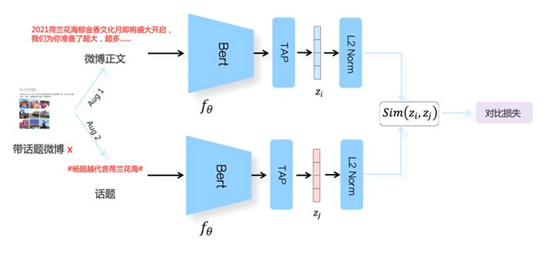
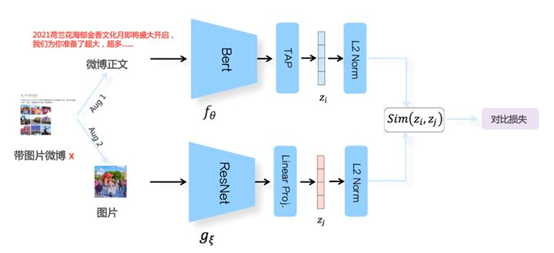
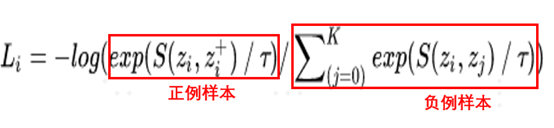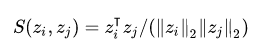风头正劲的对比学习和项目实践NLP从入门到放弃共 6615字,需浏览 14分钟 ·2021-07-01 12:26 知乎专栏:数据拾光者公众号:数据拾光者摘要:本篇从理论到实践介绍了当前很火的对比学习模型。首先介绍了背景,主要是对比学习大火的原因以及如何应用到我们的实际业务中;然后从理论方面重点介绍了对比学习,包括对比学习的由来和目标、对比学习的指导原则以及构建模型的三个关键问题、对比学习分类,其中重点介绍了基于负例的对比学习方法中的SimCLR模型;最后介绍了微博将对比学习应用到自然语言处理场景和多模态场景项目实践。对于希望将对比学习应用到实际项目中的小伙伴可能有所帮助。 下面主要按照如下思维导图进行学习分享: 01背景介绍1.1 当前风头正劲的对比学习最近一段时间对比学习(Contrastive Learning)风头正劲,不管是一线大神还是一线大厂,大家似乎都在讨论对比学习,最直观的现象就是关注的很多机器学习相关的公众号都有发表对比学习相关的文章。紧跟技术前沿,我调研了很多对比学习相关的文章以及大厂关于对比学习的项目实践整理成这篇文章,希望不仅可以了解对比学习的原理,而且可以将对比学习落地到我们的项目实践并产出价值,让技术为业务赋能。也希望机器学习相关的小伙伴能注重这种技术赋能业务的思维,技术尤其是机器学习相关的技术如果不能落地产生实际业务价值,那么这项技术的价值本身就会大打折扣。 1.2 对比学习大火的原因对比学习突然在工业界和学术界大火主要原因在于:对比学习作为一种无监督训练模型,在很多场景中效果已经超过有监督训练模型。在此之前先提一句有监督学习模型和无监督学习模型。有监督学习模型需要一定的标注数据,比如识别猫狗图片的任务,需要提前标注一批猫和狗的图片提供给模型训练。而无监督学习模型则不需要标注数据。通常情况下有监督学习模型的效果要优于无监督学习模型,因为可以通过标注数据学习到有价值的信息。而有监督学习模型的缺点在于模型的普适性效较差。而无监督学习模型因为不需要标注数据,所以模型的普适性较好,但是效果稍微差点。然后这时候作为无监督学习模型的对比学习竟然在多个任务中模型效果要优于有监督学习模型,这种有点“反常”的操作自然就像一颗炸弹引爆了机器学习圈。这就是对比学习大火的主要原因。 1.3 在我们业务中应用对比学习对比学习最早是应用在图像领域,后来又快速扩展到自然语言处理领域。对于我们实际项目中,可以利用对比学习更好的理解文本、图片、视频等item数据源,从而更好的为数据源打标(item-tag任务),召回相似搜索(item-相似item任务),获取更有价值的embedding向量用于下游扩量任务等等。 02详解对比学习2.1 对比学习的由来和目标说起对比学习,还必须先讲讲自然语言处理领域具有里程碑意义的BERT模型。BERT模型是典型的预训练和微调两阶段模型,因为效果好和应用范围广而大火,其中最重要的原因就是预训练阶段通过海量的文本数据进行无监督训练学习语言学知识,然后通过迁移学习将预训练学到的知识应用到下游任务中。所以通过无监督学习利用海量的无标签数据非常重要。而图像领域中的预训练主要是有监督的预训练方式,一般是用有标签的数据集用ImageNet来进行预训练。这里有监督的预训练和无监督的预训练最大的区别就在于数据集是否有标签,而这也是最重要的。深度学习之所以能取得如此傲人的战绩,在于可以使用更多的数据集。从BERT、GPT、RoBERTa到T5再到GPT2、GPT3等模型不断的刷新很多任务的SOTA,一次次的说明使用更多的数据集可以有效提升模型的效果。对于无监督学习模型来说使用更多的数据集根本不是问题,而对于有监督学习模型来说简直就是噩梦,因为标注成本是昂贵的,基本就限制了模型可用的数据规模。图像领域的研究者们为了像BERT一样构建基于无监督学习的预训练模型提出了对比学习,这就是对比学习的由来。 说完了对比学习的由来,那对比学习的目标也就清楚了:和BERT模型类似,通过无监督学习的方式利用海量的数据构建预训练模型,从而获取图像的先验知识。然后通过迁移学习将获取的图像知识应用到下游任务中。 2.2 图像领域中的无监督学习前面也说过无监督学习就是使用无标签的数据集来学习知识。图像领域中的无监督学习主要分成两种:生成式无监督学习和判别式无监督学习。生成式无监督学习主要包括变分自编码器VAE和生成对抗网络GAN,在图像领域听的比较多,他们的一个重要特征是要求模型重建图像或者图像的一部分。这类任务难度很高,需要像素级的重构,中间的图像编码需要包含很多细节信息。相比于生成式无监督学习来说,判别式无监督学习则简单很多,对比学习就属于判别式无监督学习。2.3 对比学习的指导原则以及构建模型的三个关键问题上面说过,对比学习属于判别式无监督学习,对比学习核心的指导原则是:通过构造相似实例和不相似实例获得一个表示学习模型,通过这个模型可以让相似的实例在投影的向量空间中尽可能的接近,而不相似的实例尽可能的远离。 明确了对比学习的指导原则,要构建对比学习模型就需要解决三个关键问题:第一个问题是如何构造相似实例和不相似实例;第二个问题是如何构造满足对比学习指导原则的表示学习模型;第三个问题是如何防止模型坍塌(Modal Collapse)。至于这个防止模型坍塌就是要让相似的实例在投影的空间中尽可能接近,不相似的尽可能远离。如果模型坍塌了,那么可能所有的实例都映射到了一个点,也就是一个常数。 2.4 对比学习分类为了构建满足对比学习指导原则的模型,从防止模型坍塌的角度来说可以把现有的对比学习方法分成以下几类:基于负例的对比学习方法基于对比聚类的对比学习方法基于不对称网络结构的对比学习方法基于冗余消除损失函数的对比学习方法 2.5 基于负例的对比学习中的SimCLR整体来看对比学习目前百花齐放,我们选一种最容易理解并且效果还不错的SimCLR模型进行讲解。SimCLR模型是Hinton在论文《A Simple Framework for Contrastive Learning of Visual Representations》中提出来的,属于基于负例的对比学习方法。SimCLR模型容易理解主要是因为模型采用对称结构,整体简单清晰,奠定了对比学习模型的标准结构。不仅如此,SimCLR模型效果还非常不错。后续很多的对比学习模型也是基于SimCLR进行改造的。要讲清楚SimCLR模型,最重要的是看它如何解决构建对比学习的三个关键问题。2.5.1 SimCLR构造正例和负例图1 SimCLR构造正例和负例 对于图像领域来说,构造正例和负例的方法是对一张图片t进行图像增强,这里图像增强可以是旋转、亮度、灰度等操作,然后从增强之后的图像数据集里面选择两张图片t1和t2,训练的时候将数据对<t1,t2>作为正例,将batch里面其他的图片s和t1(或者t2)构建负例对<t1,s>。因为对比学习的指导原则是希望得到一个表示学习模型,让图片映射到向量空间,使正例距离拉近,负例距离拉远。通过这种构建正负例的方式可以让模型学习到图片内在一致结构信息,也就是某些类型的不变性,比如旋转不变性、亮度不变性等等。同时SimCLR模型证明了使用更加复杂的图像增强技术或者融合多种图像增强技术可以提升对比学习任务的难度,从而有效提升模型的效果。 2.5.2 SimCLR构造表示学习模型上面已经构造好正负例,下面就是根据对比学习的指导原则来构建表示学习模型,这个模型可以样本映射到向量空间,并且使得相似的样本距离尽可能近,不相似的样本距离尽可能的远。下面是SimCLR模型结构:图2 SimCLR模型结构 SimCLR模型结构基本上就是标准的双塔结构DSSM,关于双塔结构之前写过一篇文章,感兴趣的小伙伴可以去看看《广告行业中那些趣事系列10:推荐系统中不得不说的DSSM双塔模型》。从无标签训练集中随机获取N个数据集作为一个batch,对于batch里的任意图片进行图像增强,根据上述方法构造正负例,并形成两个增强视图Aug1和Aug2,增强视图Aug1和Aug2分别包含N个增强的数据。因为上下两个塔是标准对称的,所以只需要说明塔1就可以了。图像数据会经过一个编码器encoder,一般情况是ResNet模型,经过CNN操作之后会得到隐层向量hi;然后经过另一个非线性变换结构projector得到向量zi,其中projector结构是由[FC->BN->ReLU->FC]两层MLP构成。也就是经过两次非线性变换先将图片样本转换成hi,再转换成zi,就将图片映射到了表示空间。 2.5.3 SimCLR防止模型坍塌将图片映射到向量空间之后,下一步就是让正例的距离尽量拉近,负例的距离尽量拉远,也就是SimCLR模型如何防止模型坍塌,这里需要通过定义损失函数来实现。SimCLR使用InfoNCE loss作为损失函数,对于单个实例i来说InfoNCE loss计算公式如下:图3 InfoNCE损失函数计算公式 通过InfoNCE损失函数公式可以看出,分子正例样本对<zi,zi+>的距离越近loss越小,对应的分母负例样本对<zi,zj>距离越大loss越小。通过这种方式可以满足对比学习拉近正例疏远负例的指导原则。具体计算向量之间的距离主要是对表示向量进行L2正则化后进行点击相乘,下面是计算两个向量之间距离的公式:图4 计算两个向量之间的距离 通过上述介绍我们了解了对比学习实现了通过无监督学习的方式利用海量的数据用于模型预训练流程,并且学习得到的向量可以满足对比学习让正例距离尽量相近,负例距离尽量拉远的指导原则。 2.5.4 SimCLR最大的贡献说到SimCLR最大的贡献,要先提下SimCLR的模型结构。SimCLR将图片样本经过特征编码器encoder得到隐层向量hi,然后再经过一次非线性变化projector将hi向量转化成向量zi,相当于做了两次非线性变换。但是了解BERT的小伙伴都知道,我们将BERT作为编码器进行编码之后会直接接入下游任务相关的网络层。关于SimCLR模型为什么要加入projector,SimCLR论文中对encoder和projecter的编码差异化进行了实验,结论是encoder之后的特征向量中包含很多图像增强信息。经过projector之后可以将一部分图像增强的信息过滤掉。相当于为了构建无监督学习模型,SimCLR需要通过图像增强来构建正负例,而这种方法引入了额外的图像增强相关的信息。为了过滤掉这些信息,会在encoder之后添加projector,从而将这些额外增加的信息过滤掉。最后的实验结果也证明添加projector结构可以提升模型的效果。 介绍projector结构的原因是SimCLR模型最大的贡献之一就是添加了projector结构,除此之外还证明了复合图像增强可以有效提升模型的效果。 小结下,本节首先介绍了对比学习的由来和目标,然后介绍了图像领域中两种无监督学习方式,分别是生成式无监督学习和判别式无监督学习;接着介绍了对比学习的指导原则以及构建模型的三个关键问题,分别是如何构造相似实例和不相似实例、如何构造表示学习模型以及如何防止模型坍塌;最后介绍了对比学习分类,并详细介绍了其中最经典的基于负例的对比学习中的SimCLR模型。 03大厂关于对比学习实践上一节重点介绍了对比学习相关的理论知识,下面从实践的角度讲下一线大厂关于对比学习的实践。微博将对比学习落地到自然语言处理领域和多模态领域,并产生了不错的线上效果。3.1 自然语言处理场景微博在自然语言处理场景中利用对比学习构建了CD-TOM模型(Contrastive Document-Topic Model)。将同一微博中的<文档,话题>数据对作为训练数据通过对比学习构建表示学习模型,将微博正文和话题映射到同一表示空间中,从而使得语义相近的正文和话题距离拉近,语义不相近的距离拉远。通过这种方式可以获得微博正文和话题的高质量embedding用于下游任务中。CD-TOM模型结构如下图所示:图5 CD-TOM模型结构 可以看出CD-TOM模型结构和SimCLR相似,采用了典型的batch内负例的对比学习方法。使用BERT作为encoder,之后会对句中每个单词对应Embedding累加后求均值(TAP, Token Average Pooling)操作。因为微博的算法工程师认为在文本表示时BERT的[CLS]向量表征文本内容的效果不佳,使用TAP操作或者将第一层Transformer和最后最一层Transformer得到的字向量累加之后再进行TAP操作效果可能更好(这里原因猜测是第一层Transformer之后的embedding向量包含更多的词向量信息,最后一层Transformer之后的embedding向量包含更多语句向量信息,将两者累加之后可以最大程度上保留词和语句的向量信息)。这个有一定的借鉴意义,之前在文本分类场景汽车分类器的优化实验中其实有对比过[CLS]向量和最后一层Transformer之后得到的向量进行Average、Sum等Pooling操作对文本分类效果的影响,当时的实验结论是影响不大,可能因为当时训练数据集规模不大,后面可以进行更加深入的尝试。 和SimCLR模型不同的是CD-TOM并没有使用projector结构,根据微博算法工程师的解释说添加projector结构对模型导致负向效果。这里是否需要使用projector结构应该和实际项目相关,通过实验的方式来决定会更加合理,并不一定需要完全照搬SimCLR模型。 3.2 多模态场景微博在多模态场景中构建了多模态模型W-CLIP(Weibo-CLIP),模型结构基本和CD-TOM保持一致,只不过是用于构建微博正文和图片的对比表示学习模型。W-CLIP模型结构如下图所示:图6 W-CLIP模型结构 从上图中可以看出W-CLIP模型结构涉及两种模态数据:微博正文和图片。微博正文塔还是使用BERT作为编码器encoder,图片塔则使用ResNet作为encoder,其他基本不变。通过W-CLIP模型可以将微博正文和图片映射到同一表示空间,得到微博正文和图片的高质量embedding向量用于下游任务。 关于对比学习的实践主要是介绍了微博的项目,后续我们也会将对比学习应用到实际业务场景中,比如item数据源打标、相似item召回以及应用到下游扩量模型的实践等。 04总结和反思本篇从理论到实践介绍了当前很火的对比学习模型。首先介绍了背景,主要是对比学习大火的原因以及如何应用到我们的实际业务中;然后从理论方面重点介绍了对比学习,包括对比学习的由来和目标、对比学习的指导原则以及构建模型的三个关键问题、对比学习分类,其中重点介绍了基于负例的对比学习方法中的SimCLR模型;最后介绍了微博将对比学习应用到自然语言处理场景和多模态场景项目实践。对于希望将对比学习应用到实际项目中的小伙伴可能有所帮助。 05参考文献[1] A Simple Framework for ContrastiveLearning of Visual Representations[2] 对比学习(ContrastiveLearning):研究进展精要[3] 如何利用噪声数据:对比学习在微博场景的应用码字不易,欢迎小伙伴们点赞和分享。 浏览 93点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 数字经济风头正劲,Filecoin勇攀高峰!IPFS西麟0信息系统项目管理师和PMP®对比信息系统项目管理师和PMP®对比,通过几个角度进行分析和对比。下面由科科过小编整理。有很多小伙伴问是先考信息系统项目管理师还是先考PMP®?或说信息系统项目管理师和PMP®哪个含金量高,针对这一问题,做一下分析。首先要做的是自己想清楚自己考证是为了入户、公司需要,还是自己充电,拓展视野用。需求不同,当然证书对每个人的价值也有所不同。通过几个方面介绍,希望能更清楚的认识信息系统项目管理师和PMP®证书。 一、证书介绍: “信息系统项目管理师”是由国家人力资源和社会保障部、工业和信息化部共同组织的国家级考试,这种考试既是职业资格考试,又是职称资格考试。考试合格者将颁发由中华人民共和国人力资源和社会保障部、工业和信息化部用印的计算机技术与科科过0项目管理工具对比目前在进行敏捷管理项目实施的时候,对比了一下市面上主流的项目协作管理的软件&开源工具。 对比对象包括Teambition, OrangeScrum, Tuleap Open ALM, Taiga.io, 飞书,企业微信, Slack, Trello, Asana, Mattermost, Wrike, Teamwork, Proofhub. 功能对比结果图 在其中挑选出六个功能比较完备的软件和开源软件进行优劣势以及价格的对比: 分别为:Teambition, Taiga, OrangeScrum, Tuleap, 飞书, 企业微信。 其中飞书目前不支持燃尽图,任务管理也比较粗糙,但是目前中小企业申请可以三年免费,而且支持聊独孤千泷0大健康产业风头正劲,下一个黄金赛道在哪里?物联网智库0qiankun 项目实践和优化(React+Vue)SegmentFault0Prometheus和Zabbix的对比程序员面试吧0疾风正劲电影以《疾风正劲》命名,正是取自《旧唐书·萧瑀传》中“疾风知劲草,板荡识忠臣”的典故,作为一部热血献礼片,故事背景设置在1937年的上海,正值国事凋敝、外忧内患的艰难时刻,这部电影将聚焦于1937年国疾风正劲0正劲饮料山东正劲饮料有限公司位于五岳之首的泰山脚下——山东省泰安市宁阳经济开发区,主要从事蛋白饮料、果汁饮料、粗粮复配谷物饮料、植物饮料、八宝粥、饮用水等系列产品的自主研发、生产销售以及技术咨询,是泰安市农业正劲饮料0正劲饮料山东正劲饮料有限公司位于五岳之首的泰山脚下——山东省泰安市宁阳经济开发区,主要从事蛋白饮料、果汁饮料正劲饮料0回顾6年深度学习的算法实践和演进极市平台0点赞 评论 收藏 分享 手机扫一扫分享分享 举报