
Debezium Server Databend support Auto Schema Evolution
背景
Debezium Server Databend 是一个基于 Debezium Engine 自研的轻量级 CDC 项目,用于实时捕获数据库更改并将其作为事件流传递最终将数据写入目标数据库 Databend。它提供了一种简单的方式来监视和捕获关系型数据库的变化,并支持将这些变化转换为可消费事件。使用 Debezium server databend 实现 CDC 无须依赖大型的 Data Infra 比如 Flink, Kafka, Spark 等,只需一个启动脚本即可开启实时数据同步。
CDC 过程中的表 Schema 变更处理是上游数据库中十分常见的用户场景,也是数据同步框架实现的难点。针对该场景,Debezium-server-databend 0.3.0 引入了 Auto Schema Evolution 的能力,在每一批次的数据中协调并控制作业拓扑中的 schema 变更事件处理。
实现过程
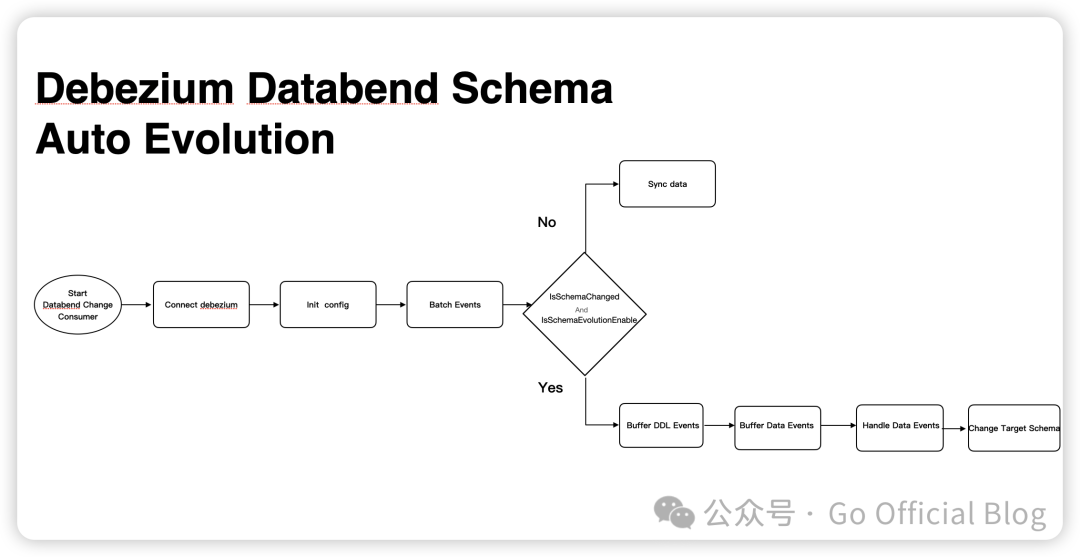
Debezium Server Databend 实现 Auto Schema Evolution 功能的原理大致是:
首先在配置文件中新增 debezium.sink.databend.schema.evolution 的配置来控制是否开启自动同步表结构变更的功能,默认为 false 不开启该功能。
当上游数据源发生 schema 变更时,先将流水线中已经读出的的数据全部刷出以保证进入数据流的这一批 schema 的一致性。
然后先将该类 schemachangekey 事件暂存到 schemaEvolutionEvents 的 ArrayList 中。
List<DatabendChangeEvent> schemaEvolutionEvents = new ArrayList<>();
for (DatabendChangeEvent event : events) {
if (DatabendUtil.isSchemaChanged(event.schema()) && isSchemaEvolutionEnabled) {
schemaEvolutionEvents.add(event);
}
}
先将上面刷出的数据执行写入操作,写入这批数据之后且解析 schema 变更的事件之前的时间里不会有新的数据进来。数据处理完后再去解析 schema change events,如果事件类型属于 DDL 并且为 alter table 语句,就对目标 database.table 执行该 DDL。
// handle schema evolution
try {
schemaEvolution(table, schemaEvolutionEvents);
} catch (Exception e) {
throw new RuntimeException(e.getMessage());
}
public void schemaEvolution(RelationalTable table, List<DatabendChangeEvent> events) {
for (DatabendChangeEvent event : events) {
Map<String, Object> values = event.valueAsMap();
for (Map.Entry<String, Object> entry : values.entrySet()) {
if (entry.getKey().contains("ddl") && entry.getValue().toString().toLowerCase().contains("alter table")) {
String tableName = getFirstWordAfterAlterTable(entry.getValue().toString());
String ddlSql = replaceFirstWordAfterTable(entry.getValue().toString(), table.databaseName + "." + tableName);
try (PreparedStatement statement = connection.prepareStatement(ddlSql)) {
System.out.println(ddlSql);
statement.execute(ddlSql);
} catch (SQLException e) {
throw new RuntimeException(e.getMessage());
}
}
}
}
}
当 schema 变更事件处理成功后,会继续新的数据同步流程。
基本的处理流程如下图所示:
实践&演示
Debezium Server Databend
-
Clone 项目:
git clone ``https://github.com/databendcloud/debezium-server-databend.git -
从项目根目录开始:
debezium.sink.type=databend
debezium.sink.databend.upsert=true
debezium.sink.databend.upsert-keep-deletes=false
debezium.sink.databend.database.databaseName=debezium
debezium.sink.databend.database.url=jdbc:databend://tnf34b0rm--xxxxxx.default.databend.cn:443
debezium.sink.databend.database.username=cloudapp
debezium.sink.databend.database.password=password
debezium.sink.databend.database.primaryKey=id
debezium.sink.databend.database.tableName=products
debezium.sink.databend.database.param.ssl=true
debezium.sink.databend.schema.evolution=true // Enable Auto Schema Evolution
# enable event schemas
debezium.format.value.schemas.enable=true
debezium.format.key.schemas.enable=true
debezium.format.value=json
debezium.format.key=json
# mysql source
debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector
debezium.source.offset.storage.file.filename=data/offsets.dat
debezium.source.offset.flush.interval.ms=60000
debezium.source.database.hostname=127.0.0.1
debezium.source.database.port=3306
debezium.source.database.user=root
debezium.source.database.password=123456
debezium.source.database.dbname=mydb
debezium.source.database.server.name=from_mysql
debezium.source.include.schema.changes=false
debezium.source.table.include.list=mydb.products
# debezium.source.database.ssl.mode=required
# Run without Kafka, use local file to store checkpoints
debezium.source.database.history=io.debezium.relational.history.FileDatabaseHistory
debezium.source.database.history.file.filename=data/status.dat
# do event flattening. unwrap message!
debezium.transforms=unwrap
debezium.transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
debezium.transforms.unwrap.delete.handling.mode=rewrite
debezium.transforms.unwrap.drop.tombstones=true
# ############ SET LOG LEVELS ############
quarkus.log.level=INFO
# Ignore messages below warning level from Jetty, because it's a bit verbose
quarkus.log.category."org.eclipse.jetty".level=WARN- 使用提供的脚本运行服务:
bash run.sh - Debezium Server with Databend 将会启动
- 构建和打包 debezium server:
mvn -Passembly -Dmaven.test.skip package - 构建完成后,解压服务器分发包:
unzip debezium-server-databend-dist/target/debezium-server-databend-dist*.zip -d databendDist - 进入解压后的文件夹:
cd databendDist - 创建
application.properties文件并修改:nano conf/application.properties,将下面的 application.properties 拷贝进去,根据用户实际情况修改相应的配置。
- 使用提供的脚本运行服务:
Mysql 准备表和数据
创建数据库 mydb 和表 products,并插入数据:
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,description VARCHAR(512));
ALTER TABLE products AUTO_INCREMENT = 10;
INSERT INTO products VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"cloud","test for databend"),
(default,"spare tire","24 inch spare tire");
Databend Cloud 中创建 Database
create database debezium
NOTE: 用户可以不必先在 Databend 中创建表,系统检测到后会自动为用户建表。
启动 Debezium Server Databend
bash run.sh
首次启动会进入 init snapshot 模式,通过配置的 Batch Size 全量将 MySQL 中的数据同步到 Databend,所以在 Databend 中可以看到 MySQL 中的数据已经同步过来了:
改变 Mysql 表结构
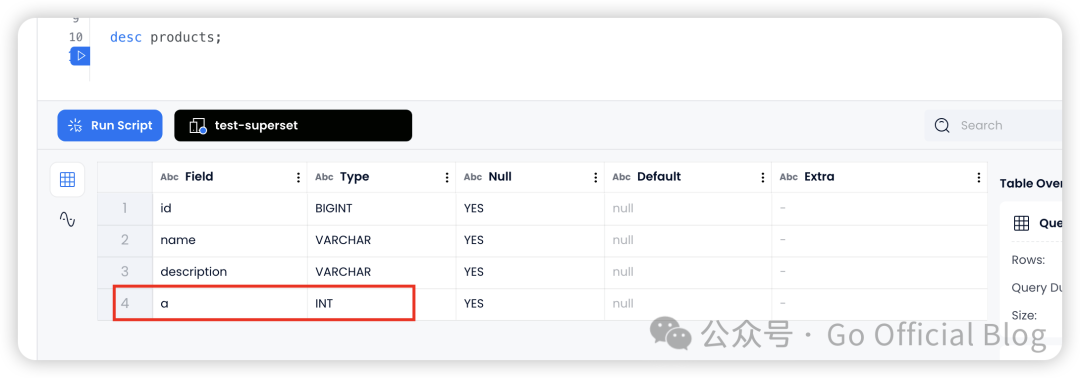
alter table products add columm a int;
在 products 表中新增一列 a int,由于我们已经在配置文件中使用 debezium.sink.databend.schema.evolution=true 开启了表结构自动同步所以在 Databend Cloud 中也可以看到目标表的结构也随之变更了:
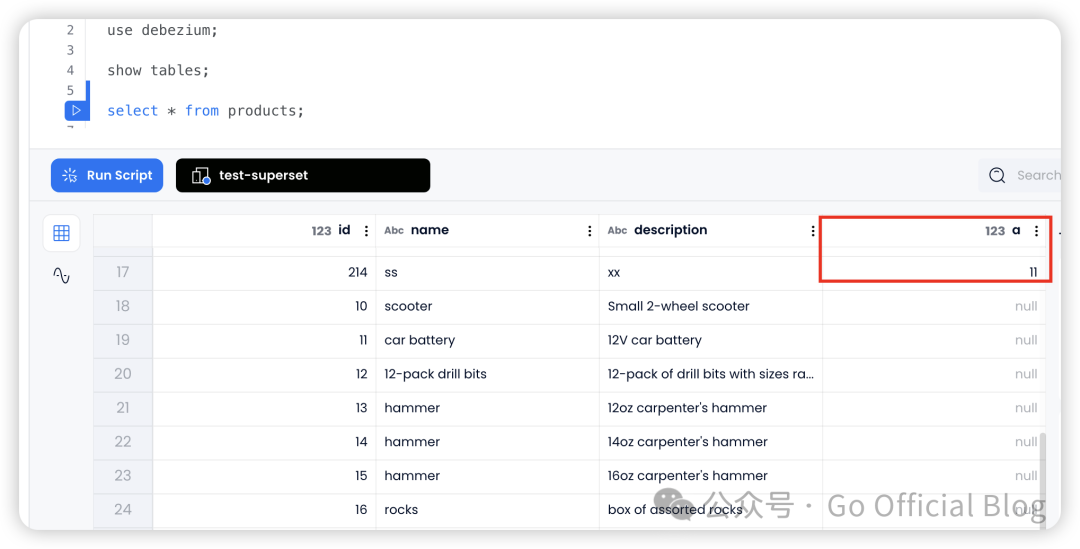
此时在 mysql 中插入数据,新的数据就会以新的 Schema 形式写入目标表:
结论
Debezium Server Databend 在支持 Auto Schema Evolution 之后,用户无需在数据源发生 schema 变更时手动介入,大大降低用户的运维成本;只需对同步任务进行简单配置即可将多表、多个数据库同步至下游,提高了数据同步的效率并且降低了用户的开发难度。