
OpenAI新发现:GPT-3做小学数学题能得55分,验证胜过微调!
共 3349字,需浏览 7分钟
·
2021-11-04 09:18
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
现在小学数学题有多难?小学生拍图上传作题App找不到现成答案,稍微变换下题设语句,就要买会员换人工答题。
一时间小学生纷纷成了“氪金玩家”。
即便是题目换汤不换药,讲题APP还是罢了工。如果有一款能听懂大白话的作题软件能有多好!
近日,OpenAI训练了一个新系统,可解决小学数学题,称其提升了GPT-3的逻辑推理问题。
自去年6月11日以来,OpenAI公布GPT-3语言模型,GPT-3成为OpenAI的旗舰语言生成算法,参数规模达1750亿,在文本生成上与人类写作相媲美。
三个月后,OpenAI 又推出用于数学问题的 GPT-f,利用基于 Transformer 语言模型的生成能力进行自动定理证明。
时至今日,GPT-3的能力依据被冠以“大力出奇迹”,光凭解答小学程度的几道数学题,就能盖过对OpenAI的质疑声吗?

论文地址:https://arxiv.org/pdf/2110.14168.pdf
数据集地址:https://github.com/openai/grade-school-math
其中涉及一大难点:GPT-3真的懂逻辑吗?即便是数学语言不同于大白话,但依旧涉及很多逻辑关系,一步错步步错。
为此,OpenAI 基于四个设计原则创建了 GSM8K 数据集供GPT-3反复训练,即数据集为高质量、高多样性、中等难度和自然语言的答题形式。
GSM8K 数据集由 8.5K 个高质量小学数学应用题组成,每个问题需要 2 到 8 步解决,涉及到加减乘除整合运算,难度近乎9-12岁的小学数学题。
结果发现,60亿参数的GPT-3采用“新方法”,准确率直接翻倍!甚至追平了拥有1750亿参数,采用微调方法的GPT-3模型。
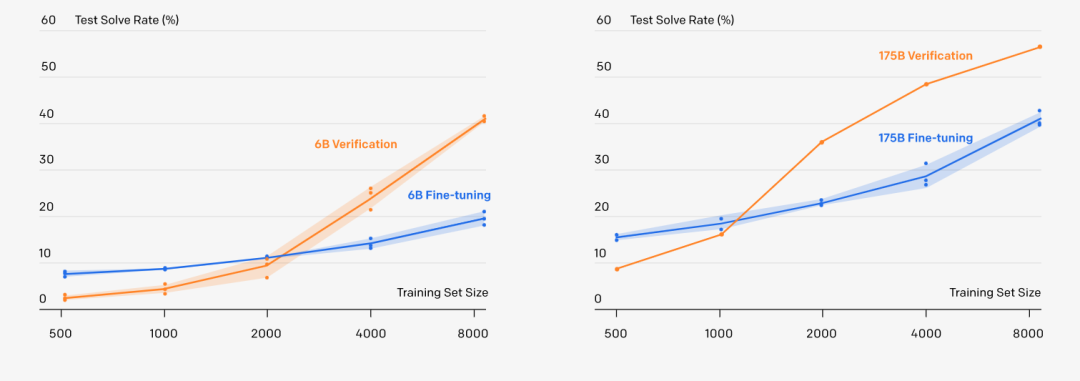
新方法挑战比自己高30倍的大参数模型,力证参数并非越大越好,这一新方法是什么?
1 训练验证器:从错误中学习的模型
像GPT-3这样的大型语言模型有许多惊人的技能,包括模仿多种写作风格,自动编程、自然对话、语义搜索等。然而,它们很难完成需要精确的多步骤推理的任务,比如解决小学数学应用题。
「小明每半小时喝一瓶水。一个普通的数独难题要花他45分钟。一个极难的数独需要4倍的时间。做一道极难的数独的时间他喝了多少瓶水?」
在这样的数学题中,GPT-3要匹配人类在复杂逻辑领域中的表现,一味提高参数,是解决办法的长远之策吗?
并不!OpenAI在新方法中提到,为什么不让模型学会识别自己的错误呢?从许多候选的解决方案中选择出最佳方案!
为此,OpenAI训练了验证器(verifier),来评估所提出的解决方案是否正确。可比通过更新模型参数,最小化所有训练token的交叉熵损失的方法要多一个思路。
增加一个“验证”模块,通过反复试错,学习,再计算,原先微调无法解决的GPT-3逻辑推理能力,在新方法中得到进步。
对于两种思路,OpenAI通过新的GSM8K数据集来测试两种方法:
高质量:GSM8K中的问题都是人工设计的,避免了错误问题的出现。
高多样性:GSM8K中的问题都被设计得相对独特,避免了来自相同语言模板或仅在表面细节上有差异的问题。
中等难度:GSM8K中的问题分布对大型SOTA语言模型是有挑战的,但又不是完全难以解决的。这些问题不需要超出早期代数水平的概念,而且绝大多数问题都可以在不明确定义变量的情况下得到解决。
自然语言解决方案:GSM8K中的解决方案是以自然语言而不是纯数学表达式的形式编写的。模型由此生成的解决方案也可以更容易被人理解。此外,OpenAI也期望它能阐明大型语言模型内部独白的特性。

在GSM8K数据集上,OpenAI测试了新方法验证(verification)和基线方法微调(fine-tuning)生成的答案。
即4种不同的解决方案:6B微调、6B 验证、175B 微调和 175B 验证。
在性能展示中,OpenAI提供了十个数学题实例,其中一个是的解决方案如下:
小明种了 5 棵树。他每年从每棵树上收集 6 个柠檬。他十年能得到多少柠檬?
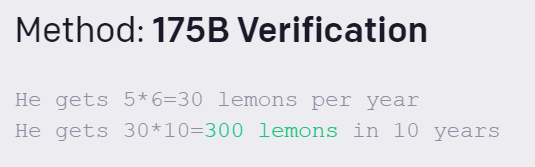


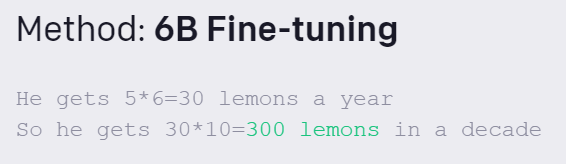
很明显,验证方法(verification)比基线方法微调(fine-tuning)在回答数学应用题上有了很大的提升。
在完整的训练集上,采用「验证」方法的60亿参数模型,会略微优于采用「微调」的1750亿参数模型!
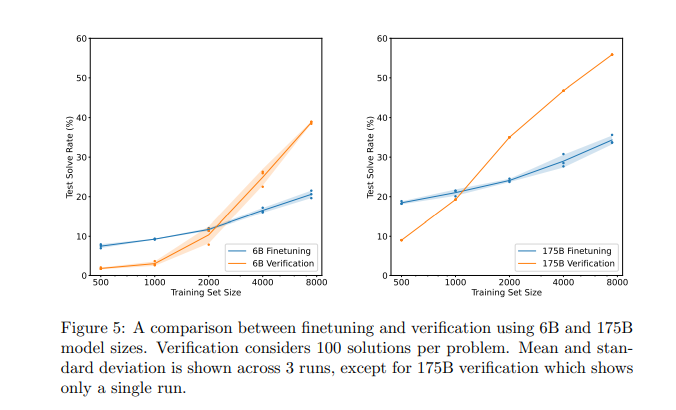
但大模型也不是一无是处,采用「验证」的1750亿参数模型还是比采用「验证」方法的60亿参数模型学习速度更快,只需要更少的训练问题,就能超过微调基线。
OpenAI发现,只要数据集足够大,大模型就能从「验证」中获得强大的性能提升。
但是,对于太小的数据集,验证器会通过记忆训练集中的答案而过度拟合,而不是学习基本的数学推理这种更有用的属性。
所以,根据目前的结果进行推断,「验证」似乎可以更有效地扩展到额外的数据。
大模型毕竟有大模型的优势,如果之后能够用大模型+验证的方式,将会使得模型性能再上一个level !
2 新方法是如何验证的?
验证器训练时,只训练解决方案是否达到正确的最终答案,将其标记为正确或不正确。但是在实践中,一些解决方案会使用有缺陷的推理得出正确的最终答案,从而导致误报。
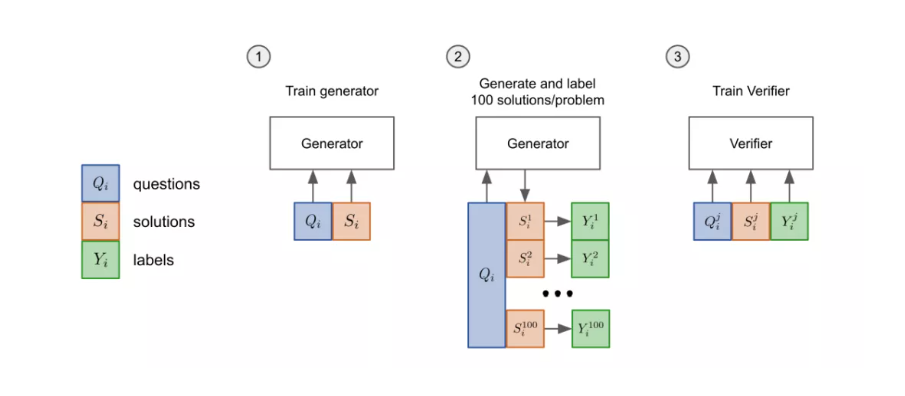
现在的验证器具体训练方法分为三步走:
先把模型的「生成器」在训练集上进行2个epoch的微调。
从生成器中为每个训练问题抽取100个解答,并将每个解答标记为正确或不正确。
在数据集上,验证器再训练单个epoch。
生成器只训练2个epoch是因为2个epoch的训练就足够学习这个领域的基本技能了。如果采用更长时间的训练,生成的解决方案会过度拟合。
测试时,解决一个新问题,首先要生成100个候选解决方案,然后由验证器打分,排名最高的解决方案会被最后选中。
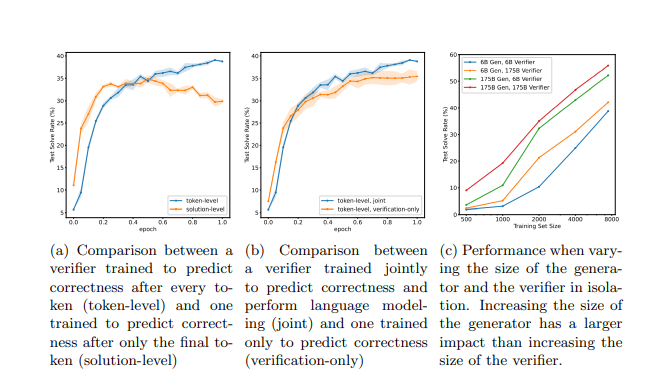
训练验证器既可以在全部的生成解决方案里进行单个标量预测(single scalar prediction),也可以在解决方案的每个 token 后进行单个标量预测,OpenAI 选择后者,即训练验证器在每个 token 之后进行预测。
如下图所示,它们分别标记为“解决方案级别”和“token 级别”。
在b图中,通过消融实验验证训练验证器中使用目标(objective)的作用, OpenAI 将使用两个目标与仅使用验证目标进行比较。
在c图中,OpenAI 对生成器和验证器的大小进行了实验,研究发现使用大的生成器、小的验证器组合性能显著优于小的生成器、大的验证器组合。
3 写在最后
通过OpenAI所展现出的10个数学实例是看出,使用验证方法比单纯扩大参数要更加智能,但缺点是并不稳定。比如在另一个问题实例中,仅有175B验证模型输出正确结果:小明是一所私立学校的院长,他有一个班。小红是一所公立学校的院长,他有两个班,每个班的人数是小明班级人数120人的1/8。问两所学校的总人数是多少?
AI发展道阻且长,目前绝大多数的机器学习仍依赖于数据堆砌,缺乏根本性的技术突破,存在一定的发展瓶颈。Google 工程总监 Ray Kurzweil 曾在采访中表示,直到 2029 年,人类才有超过 50% 的概率打造出 AGI 系统,还有一部分专家表示至少要到2099年或2200年。
现下,通过在一些简单的领域试验新路径,识别和避免机器学习的错误是推动模型发展的关键方法,比如这种简单的小学数学题。最终当我们试图将模型应用到逻辑上更复杂的领域时,那些不被了解的黑箱子将变得越来越透明。
参考链接:

点个在看 paper不断!