
9个value_counts()的小技巧,提高Pandas 数据分析效率

来源:DeepHub IMBA 本文约1800字,建议阅读5分钟
我们将探讨 Pandas value_counts() 的不同用例。
数据科学家通常将大部分时间花在探索和预处理数据上。当谈到数据分析和理解数据结构时,Pandas value_counts() 是最受欢迎的函数之一。该函数返回一个包含唯一值计数的系列。生成的Series可以按降序或升序排序,通过参数控制包括或排除NA。
在本文中,我们将探讨 Pandas value_counts() 的不同用例。您将学习如何使用它来处理以下常见任务。
默认参数
按升序对结果进行排序
按字母顺序排列结果
结果中包含空值
以百分比计数显示结果
将连续数据分入离散区间
分组并调用 value_counts()
将结果系列转换为 DataFrame
应用于DataFrame
1、默认参数
Pandas value_counts() 函数返回一个包含唯一值计数的系列。默认情况下,结果系列按降序排列,不包含任何 NA 值。例如,让我们从 Titanic 数据集中获取“Embarked”列的计数。
>>> df['Embarked'].value_counts()
S 644
C 168
Q 77
Name: Embarked, dtype: int64
2、按升序对结果进行排序
value_count() 返回的系列默认按降序排列。对于升序结果,我们可以将参数升序设置为 True。
>>> df['Embarked'].value_counts(ascending=True)
Q 77
C 168
S 644
Name: Embarked, dtype: int64
3、按字母顺序排列结果
我们已经学习了参数升序以获得按值计数 ASC 或 DESC 排序的结果。在某些情况下,最好按字母顺序显示我们的结果。这可以通过在 value_counts() 之后调用 sort_index(ascending=True) 来完成,例如
>>> df['Embarked'].value_counts(ascending=True).sort_index(ascending=True)
C 168
Q 77
S 644
Name: Embarked, dtype: int64
4、包括结果中的 NA
默认情况下,结果中会忽略包含任何 NA 值的行。有一个参数 dropna 来配置它。我们可以将该值设置为 False 以包含 NA 的行数。
df['Embarked'].value_counts(dropna=False)
S 644
C 168
Q 77
NaN 2
Name: Embarked, dtype: int64
5、以百分比计数显示结果
在进行探索性数据分析时,有时查看唯一值的百分比计数会更有用。这可以通过将参数 normalize 设置为 True 来完成,例如:
df['Embarked'].value_counts(normalize=True)
S 0.724409
C 0.188976
Q 0.086614
Name: Embarked, dtype: float64
如果我们更喜欢用百分号 (%) 格式化结果,我们可以设置 Pandas 显示选项如下:
>>> pd.set_option('display.float_format', '{:.2f}%'.format)
>>> df['Embarked'].value_counts(normalize = True)
S 0.72%
C 0.19%
Q 0.09%
Name: Embarked, dtype: float64
6、将连续数据分入离散区间
Pandas value_counts() 可用于使用 bin 参数将连续数据分入离散区间。与 Pandas cut() 函数类似,我们可以将整数或列表传递给 bin 参数。
当整数传递给 bin 时,该函数会将连续值离散化为大小相等的 bin,例如:
>>> df['Fare'].value_counts(bins=3)
(-0.513, 170.776] 871
(170.776, 341.553] 17
(341.553, 512.329] 3
Name: Fare, dtype: int64
当列表传递给 bin 时,该函数会将连续值划分为自定义组,例如:
>>> df['Fare'].value_counts(bins=[-1, 20, 100, 550])
(-1.001, 20.0] 515
(20.0, 100.0] 323
(100.0, 550.0] 53
Name: Fare, dtype: int64
7、分组并执行 value_counts()
Pandas groupby() 允许我们将数据分成不同的组来执行计算以进行更好的分析。一个常见的用例是按某个列分组,然后获取另一列的唯一值的计数。例如,让我们按“Embarked”列分组并获取不同“Sex”值的计数。
>>> df.groupby('Embarked')['Sex'].value_counts()
Embarked Sex
C male 95
female 73
Q male 41
female 36
S male 441
female 203
Name: Sex, dtype: int64
8、将结果系列转换为 DataFrame
Pandas value_counts() 返回一个Series,包括前面带有 MultiIndex 的示例。如果我们希望我们的结果显示为 DataFrame,我们可以在 value_count() 之后调用 to_frame()。
>>> df.groupby('Embarked')['Sex'].value_counts().to_frame()

9、应用于DataFrame
到目前为止,我们一直将 value_counts() 应用于 Pandas Series,在 Pandas DataFrame 中有一个等效的方法。Pandas DataFrame.value_counts() 返回一个包含 DataFrame 中唯一行计数的系列。
让我们看一个例子来更好地理解它:
df = pd.DataFrame({
'num_legs': [2, 4, 4, 6],
'num_wings': [2, 0, 0, 0]},
index=['falcon', 'dog', 'cat', 'ant']
)
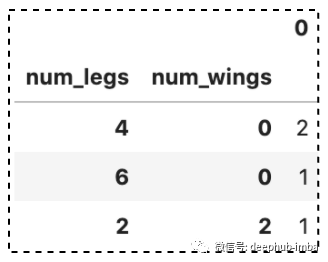
>>> df.value_counts()
num_legs num_wings
4 0 2
6 0 1
2 2 1
dtype: int64
通过在 df 上调用 value_counts(),它返回一个以 num_legs 和 num_wings 作为索引的 MultiIndex 系列。从结果中,我们可以发现有 2 条记录的 num_legs=4 和 num_wing=0。
同样,我们可以调用 to_frame() 将结果转换为 DataFrame
>>> df.value_counts().to_frame()
总结
在本文中,我们探讨了 Pandas value_counts() 的不同用例。我希望这篇文章能帮助你节省学习 Pandas 的时间。我建议您查看 value_counts() API 的文档并了解您可以做的其他事情。
谢谢阅读。本文代码在这里:
https://github.com/BindiChen/machine-learning/blob/master/data-analysis/046-pandas-value_counts/pandas-value_counts.ipynb
编辑:文婧
校对:林亦霖