
如何保证缓存与数据库双写时的数据一致性?
共 2210字,需浏览 5分钟
·
2021-10-26 15:03
点击上方蓝色字体,选择“设为星标”
回复”学习资料“获取学习宝典

来源:https://www.jianshu.com/p/a8eb1412471f
| 背景
在做系统优化时,想到了将数据进行分级存储的思路。因为在系统中会存在一些数据,有些数据的实时性要求不高,比如一些配置信息。
基本上配置了很久才会变一次。而有一些数据实时性要求非常高,比如订单和流水的数据。所以这里根据数据要求实时性不同将数据分为三级。
第1级:订单数据和支付流水数据;这两块数据对实时性和精确性要求很高,所以不添加任何缓存,读写操作将直接操作数据库。 第2级:用户相关数据;这些数据和用户相关,具有读多写少的特征,所以我们使用redis进行缓存。 第3级:支付配置信息;这些数据和用户无关,具有数据量小,频繁读,几乎不修改的特征,所以我们使用本地内存进行缓存。
| 解决方案
那么我们这里列出来所有策略,并且讨论他们优劣性。
先更新数据库,后更新缓存 先更新数据库,后删除缓存 先更新缓存,后更新数据库 先删除缓存,后更新数据库
| 先更新数据库,后更新缓存
| 先更新缓存,后更新数据库
|先删除缓存,后更新数据库
该方案也会出问题,具体出现的原因如下。
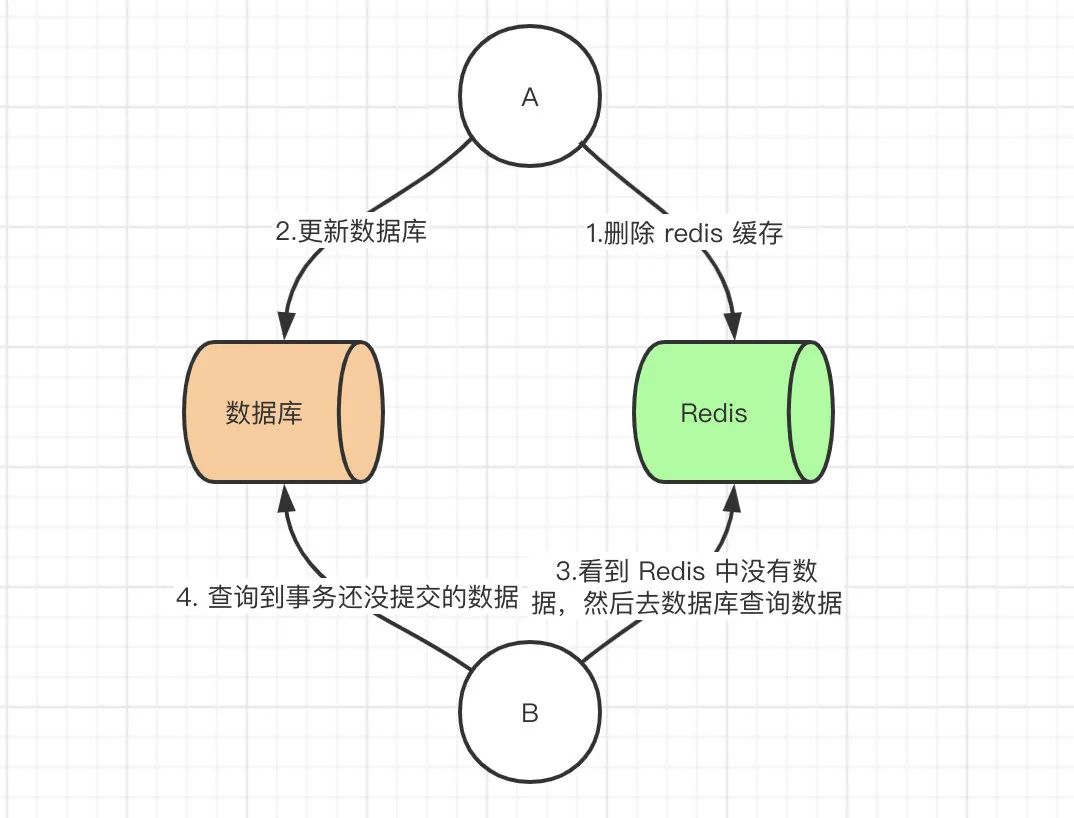
此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)。
请求 A 会先删除 Redis 中的数据,然后去数据库进行更新操作。 此时请求 B 看到 Redis 中的数据时空的,会去数据库中查询该值,补录到 Redis 中。 但是此时请求 A 并没有更新成功,或者事务还未提交。
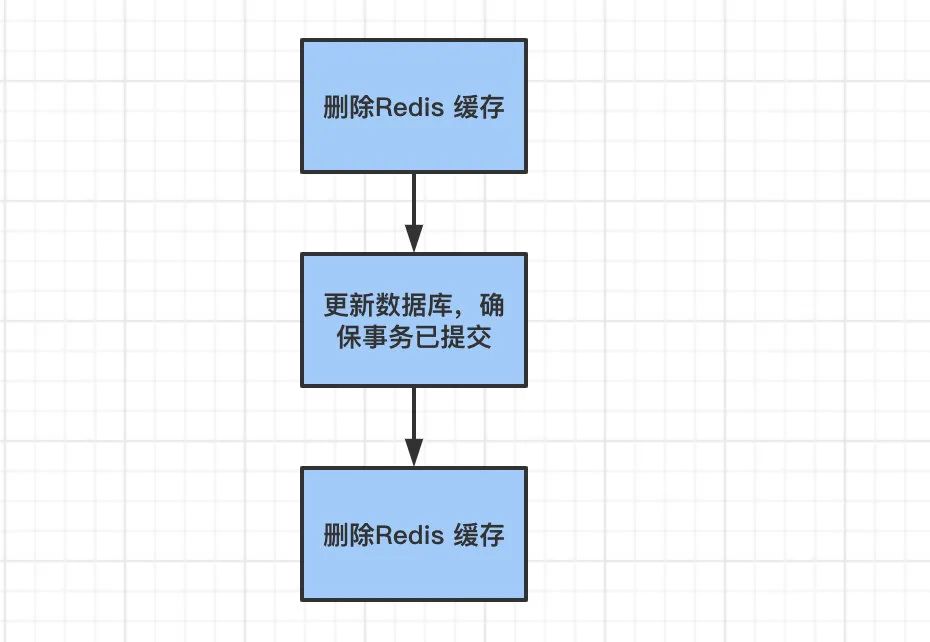
那么这时候就会产生数据库和 Redis 数据不一致的问题。如何解决呢?其实最简单的解决办法就是延时双删的策略。
但是上述的保证事务提交完以后再进行删除缓存还有一个问题,就是如果你使用的是 Mysql 的读写分离的架构的话,那么其实主从同步之间也会有时间差。
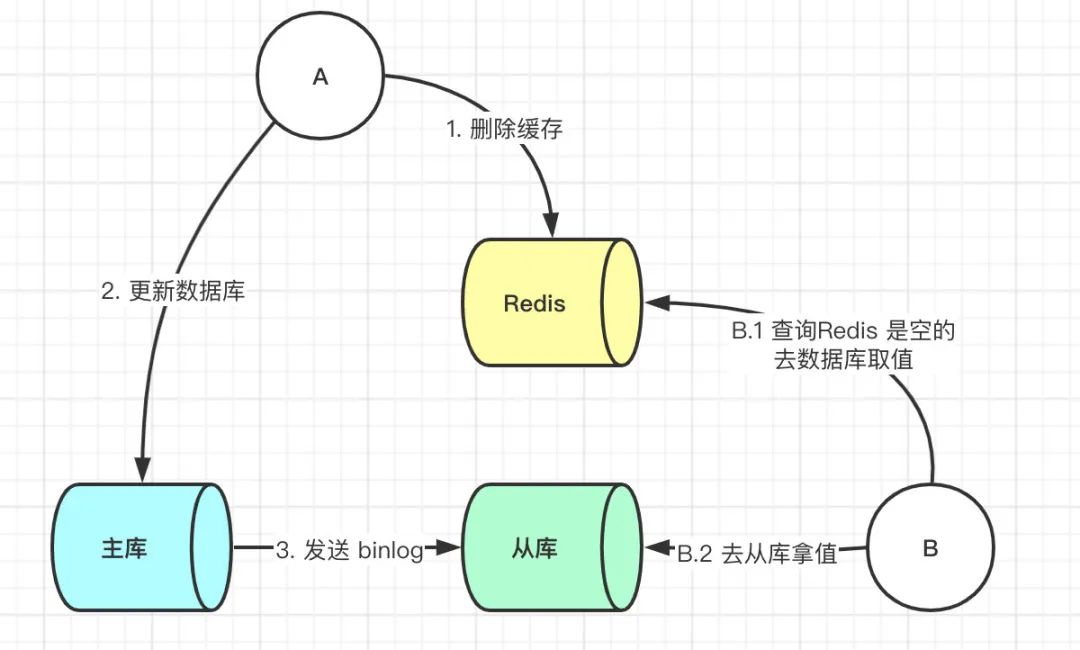
此时来了两个请求,请求 A(更新操作) 和请求 B(查询操作)。
请求 A 更新操作,删除了 Redis。 请求主库进行更新操作,主库与从库进行同步数据的操作。 请 B 查询操作,发现 Redis 中没有数据。 去从库中拿去数据。 此时同步数据还未完成,拿到的数据是旧数据。
此时的解决办法就是如果是对 Redis 进行填充数据的查询数据库操作,那么就强制将其指向主库进行查询。
| 先更新数据库,后删除缓存
问题:这一种情况也会出现问题,比如更新数据库成功了,但是在删除缓存的阶段出错了没有删除成功,那么此时再读取缓存的时候每次都是错误的数据了。
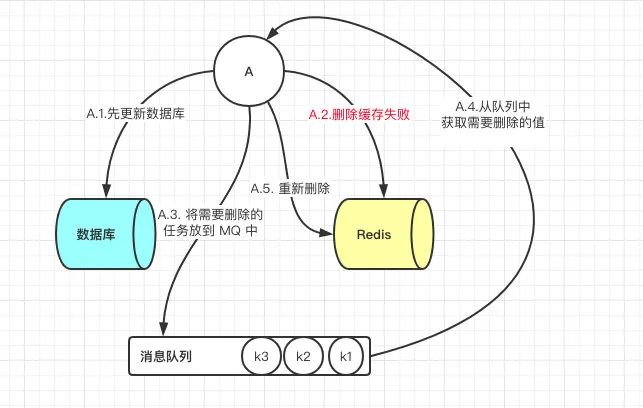
此时解决方案就是利用消息队列进行删除的补偿。具体的业务逻辑用语言描述如下:
请求 A 先对数据库进行更新操作。 在对 Redis 进行删除操作的时候发现报错,删除失败。 此时将Redis 的 key 作为消息体发送到消息队列中。 系统接收到消息队列发送的消息后再次对 Redis 进行删除操作。
但是这个方案会有一个缺点就是会对业务代码造成大量的侵入,深深的耦合在一起,所以这时会有一个优化的方案,我们知道对 Mysql 数据库更新操作后再 binlog 日志中我们都能够找到相应的操作,那么我们可以订阅 Mysql 数据库的 binlog 日志对缓存进行操作。
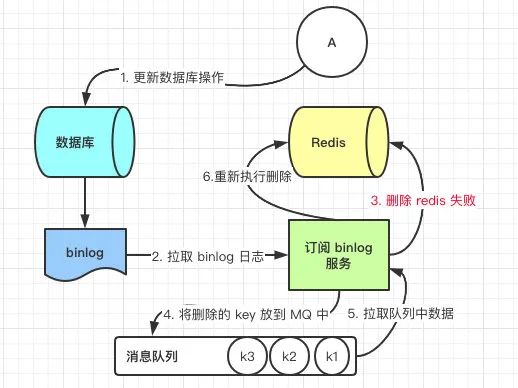
利用订阅binlog 删除缓存
最后一种方案我们最后讨论了利用订阅 binlog 日志进行搭建独立系统操作 Redis,这样的缺点其实就是增加了系统复杂度。
其实每一次的选择都需要我们对于我们的业务进行评估来选择,没有一种技术是对于所有业务都通用的。没有最好的,只有最适合我们的。
后台回复 学习资料 领取学习视频