
人手一个编程助手!北大最强代码大模型CodeShell-7B开源,性能霸榜,IDE插件全开源
恋习Python
共 6043字,需浏览 13分钟
·
2023-11-07 21:55
来自公众号:新智元
编辑:桃子 好困
【导读】继CodeLlama开源之后,北大等机构正式开源了性能更强的代码基座大模型CodeShell-7B和代码助手CodeShell-Chat。不仅如此,团队还把方便易用的IDE插件也开源了!
近日,北京大学软件工程国家工程研究中心知识计算实验室联合四川天府银行AI实验室,正式开源70亿参数的代码大模型CodeShell,成为同等规模最强代码基座。
与此同时,团队将软件开发代码助手的完整解决方案全部开源,人手一个本地化轻量化的智能代码助手的时代已经来临!

具体来说,CodeShell-7B基于5000亿Tokens进行了冷启动训练,上下文窗口长度为8192。
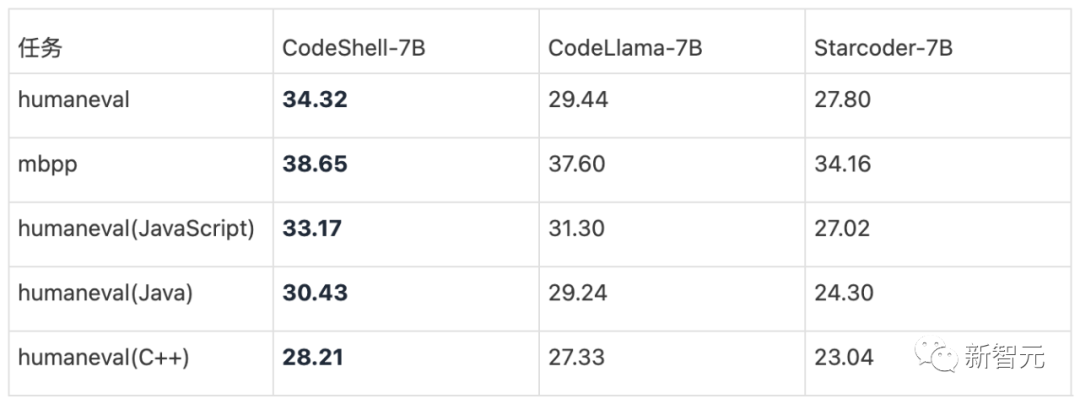
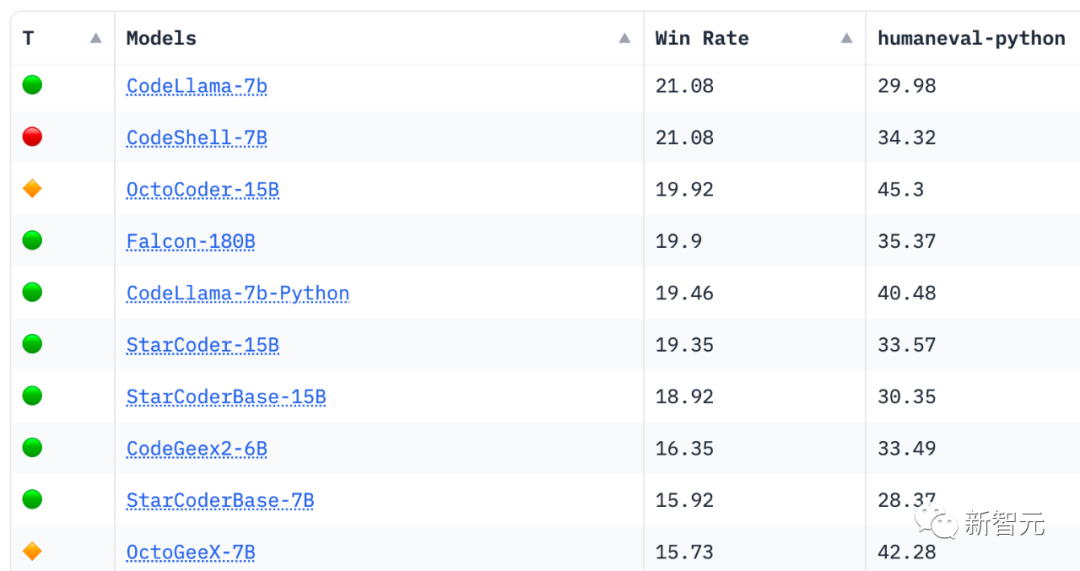
在权威的代码评估基准(HumanEval和MBPP)上,CodeShell取得同等规模最好的性能,超过了CodeLlama-7B和StarCodeBase-7B。
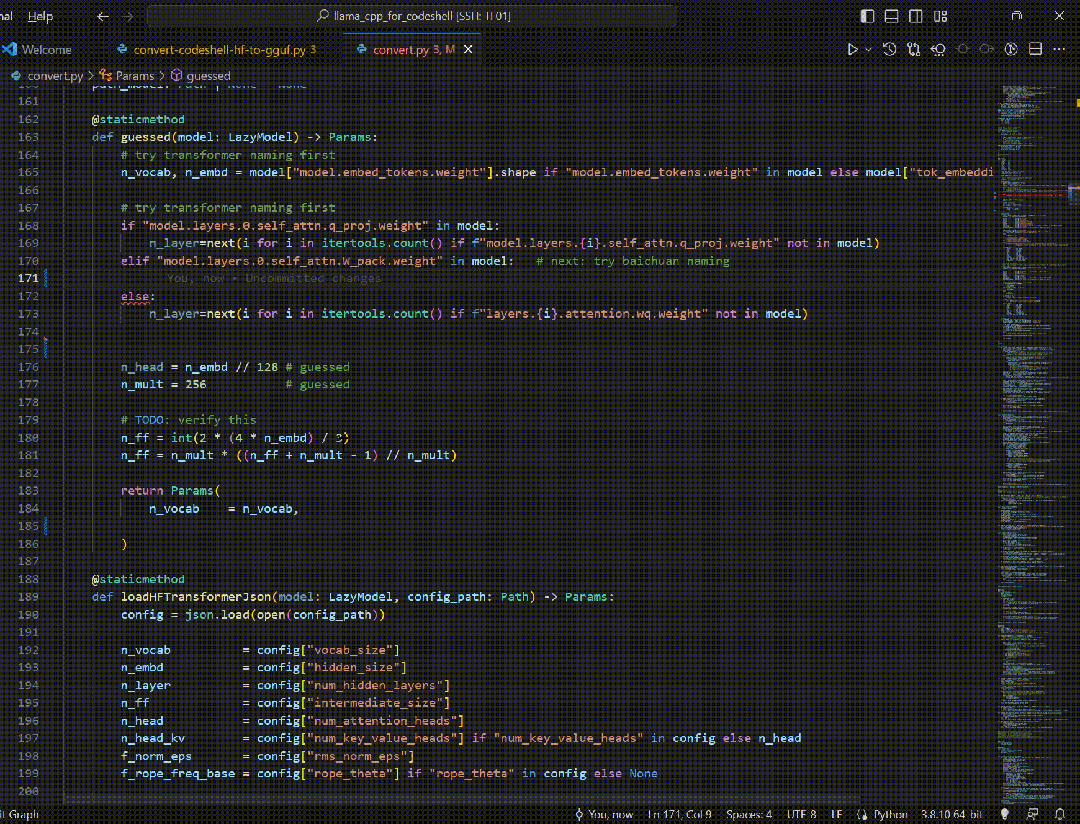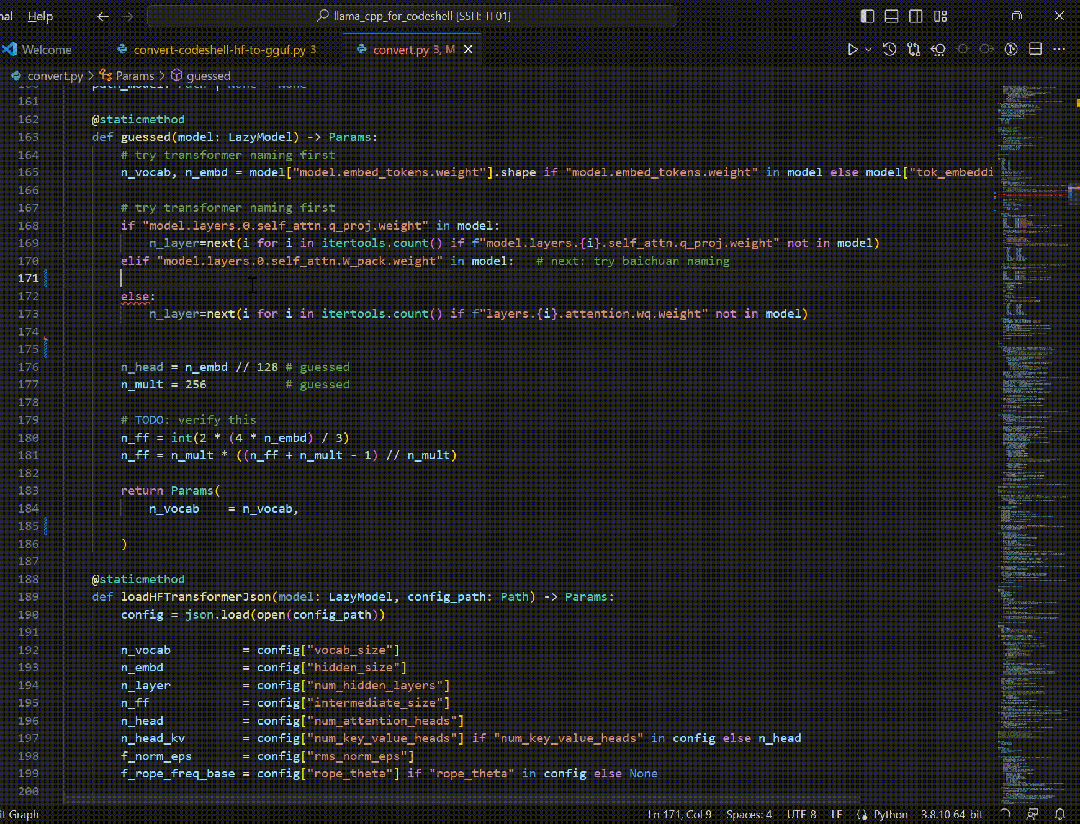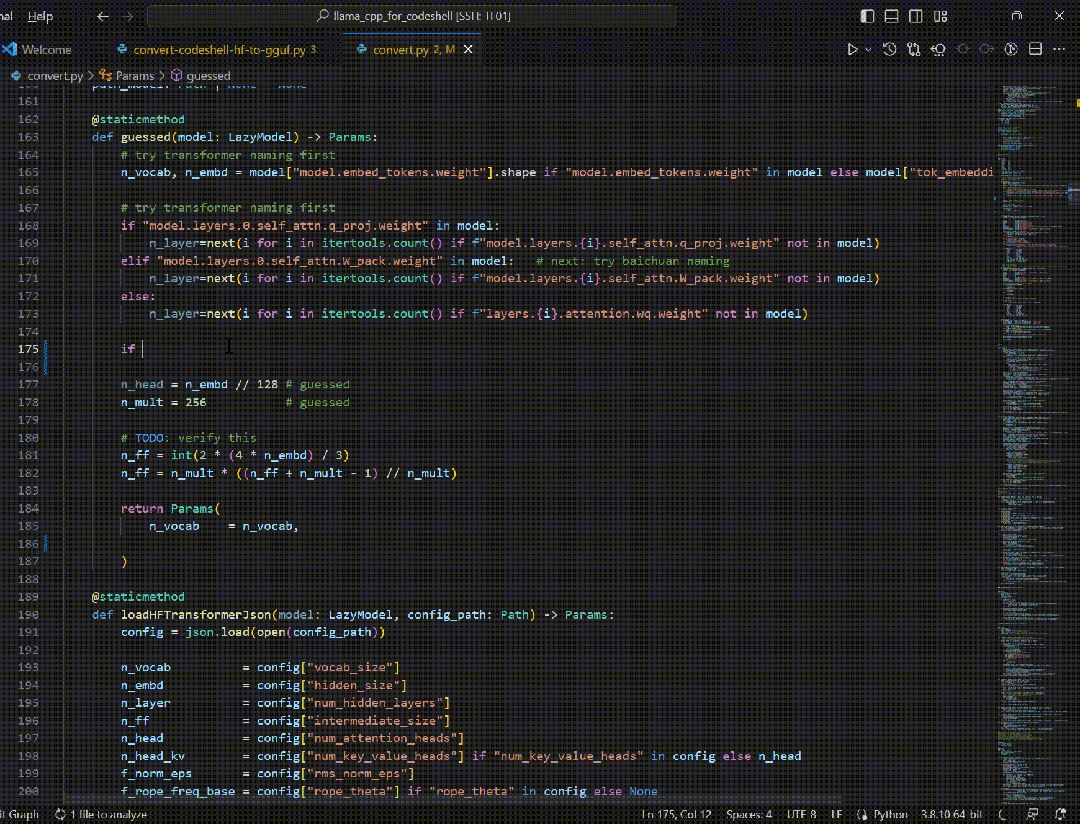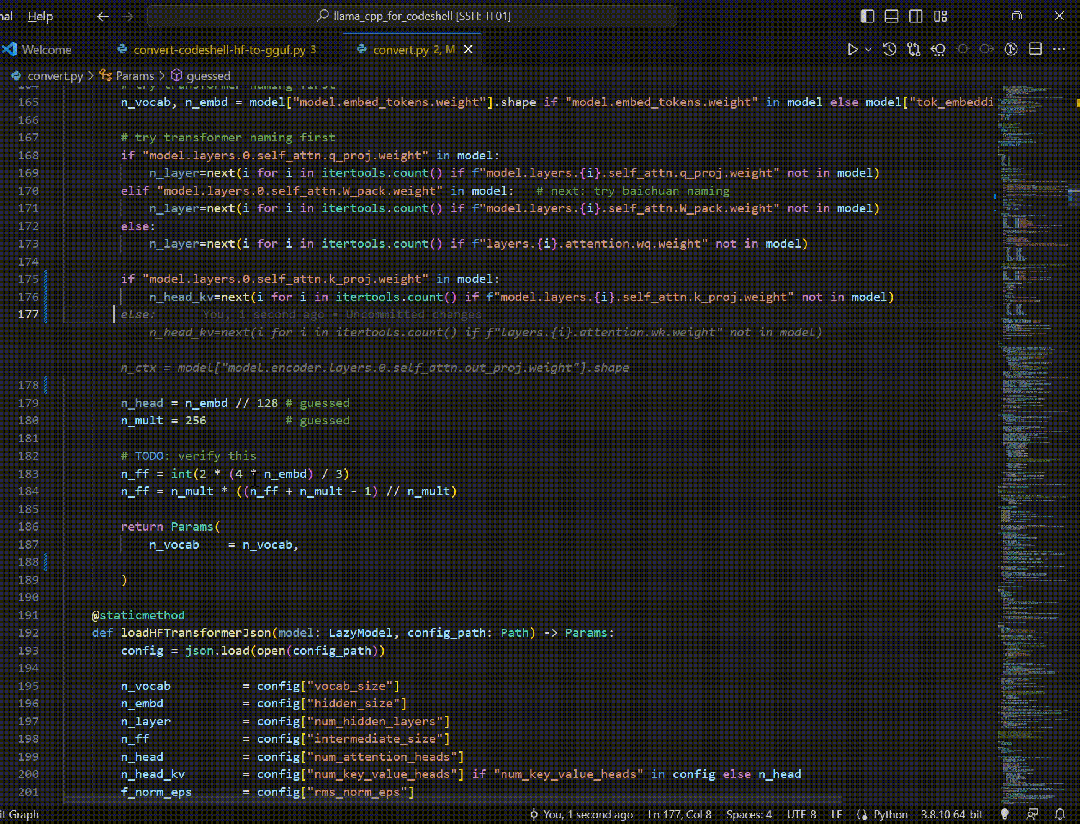
与此同时,同CodeShell-7B配套的量化与本地部署方案,以及支持VSCode与JetBrains IDE的插件也全部开源,为新一代智能代码助手提供了轻量高效的全栈开源解决方案。
CodeShell模型和插件的相关代码已经在Github发布,并严格遵循Apache 2.0开源协议,模型在HuggingFace平台发布,支持商用。
CodeShell:性能最强的7B代码基座大模型
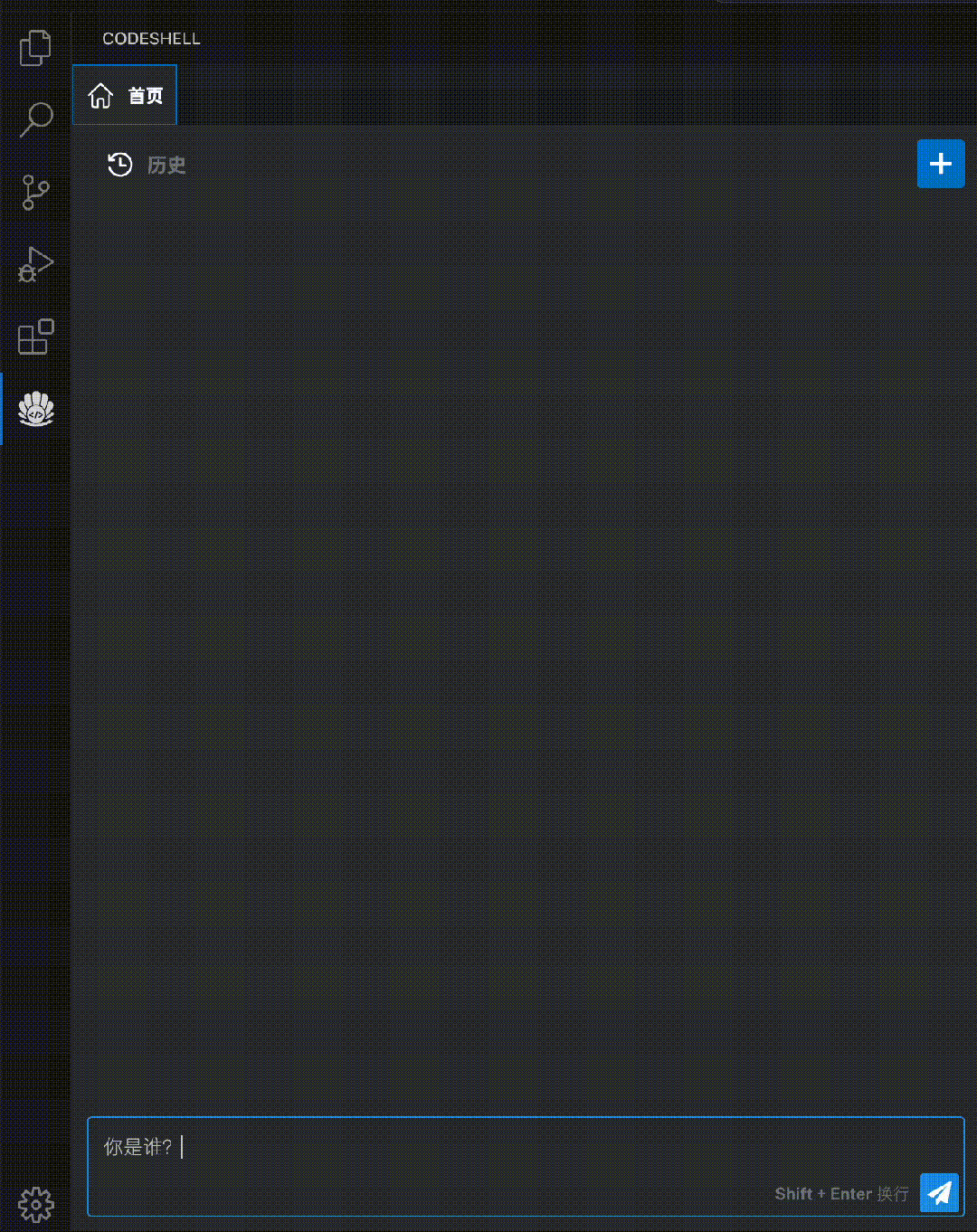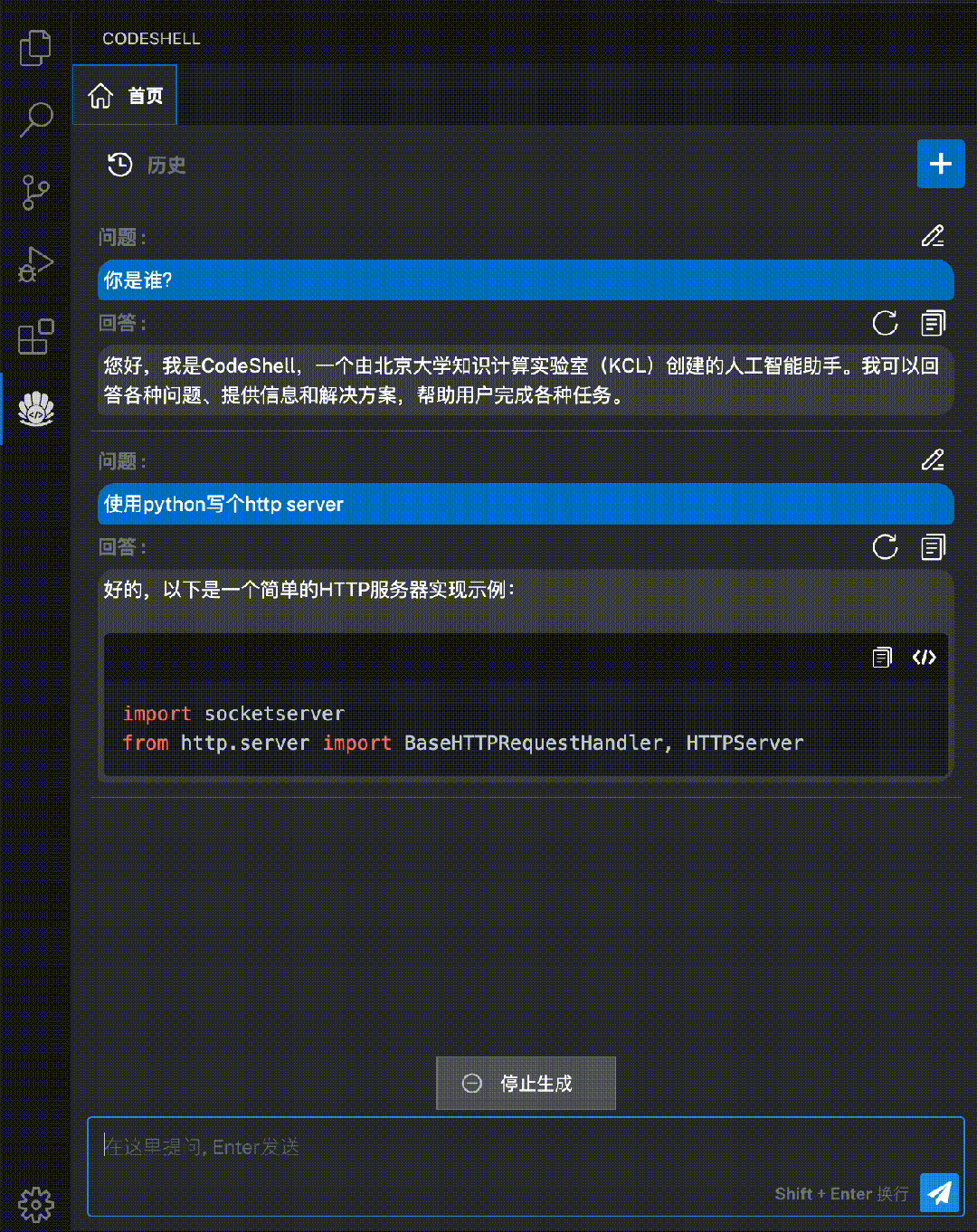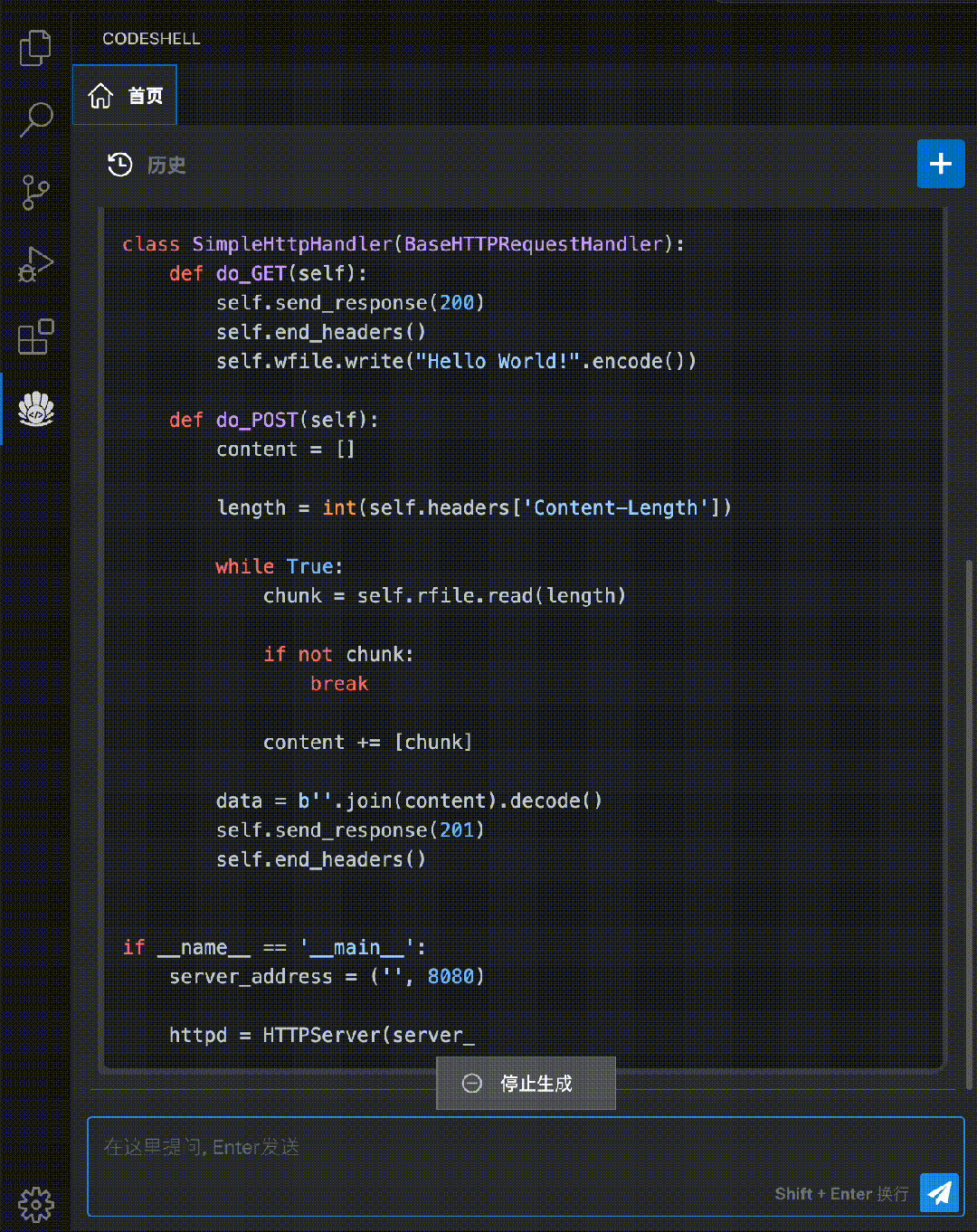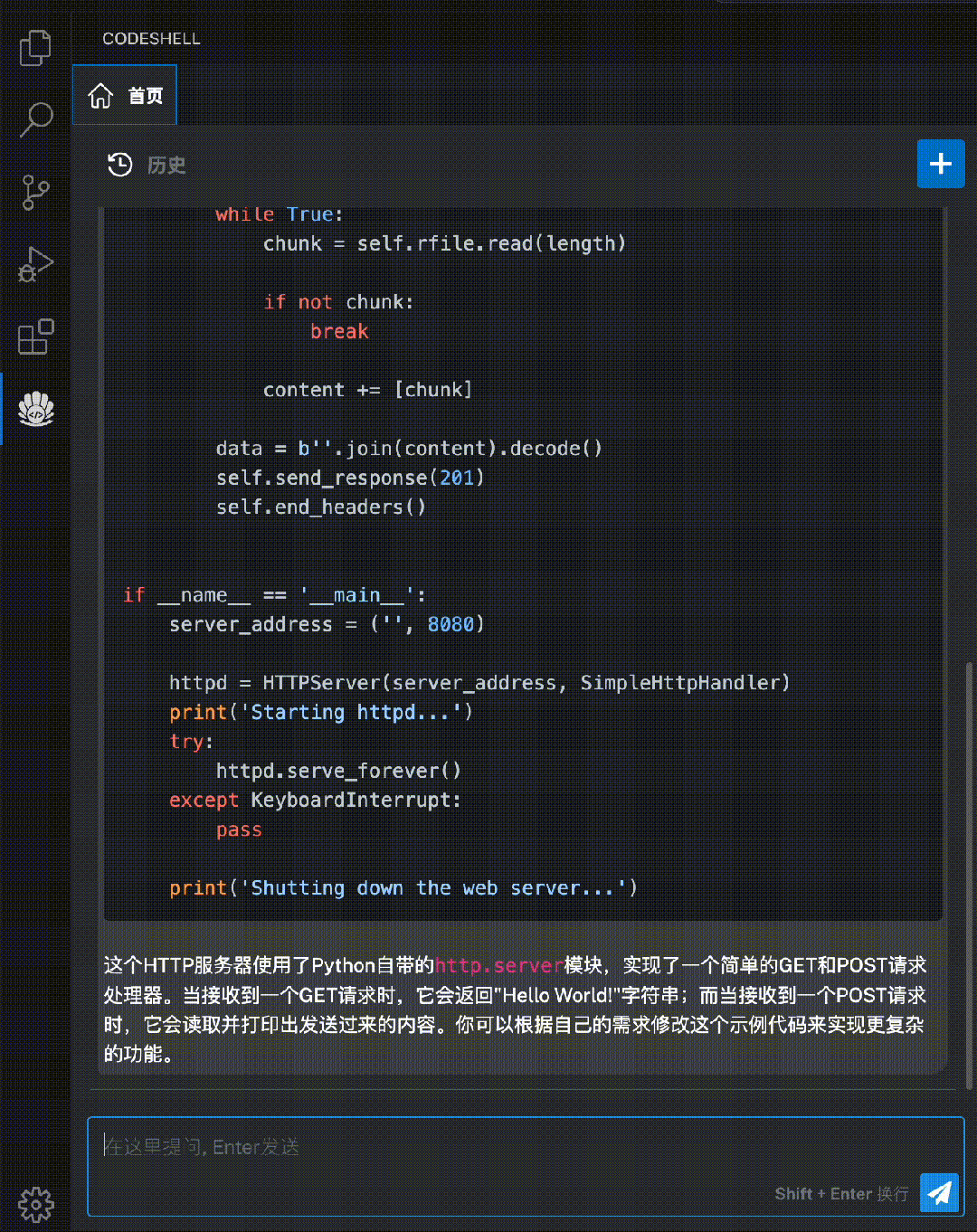
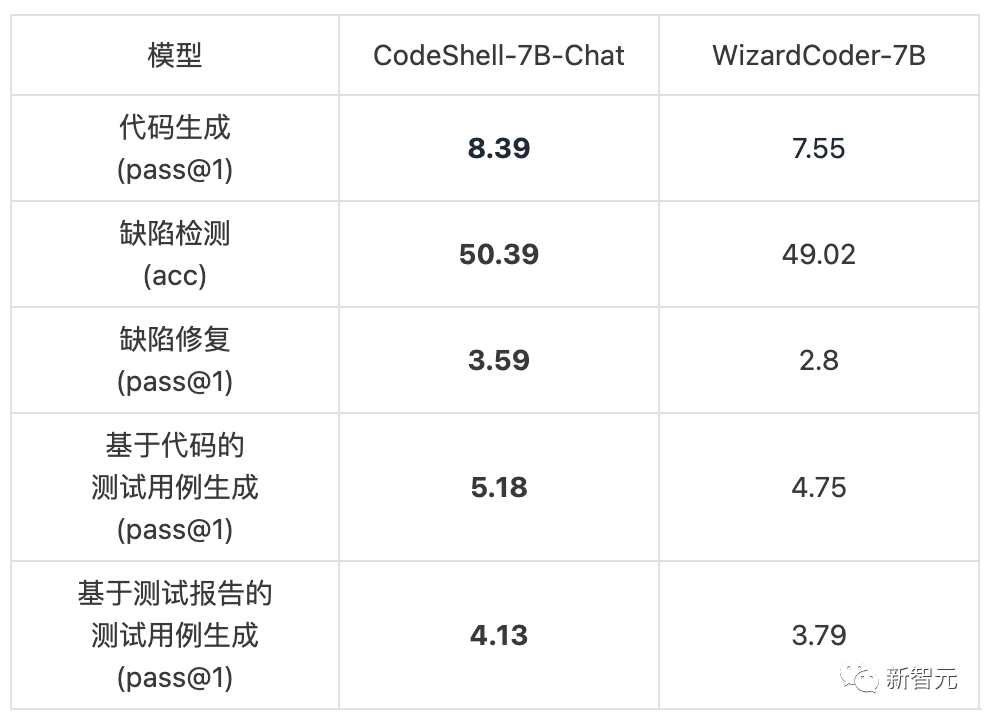
CodeShell-Chat:功能齐全的代码助手模型
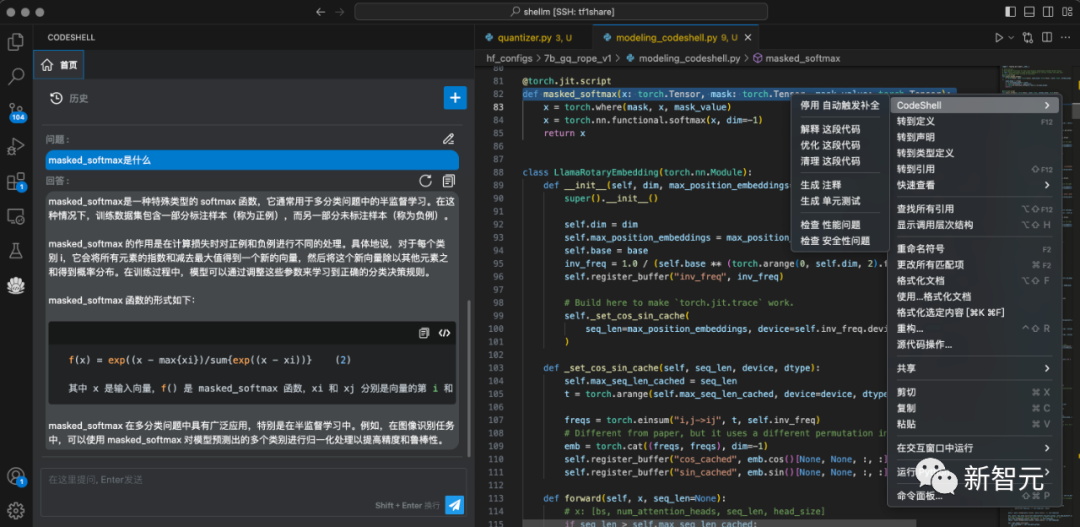
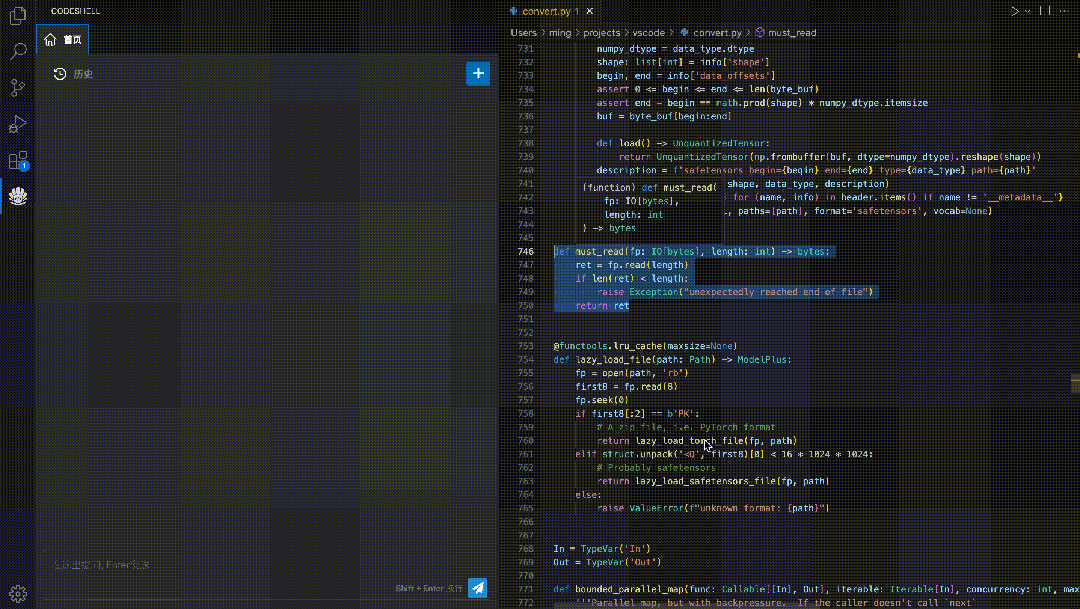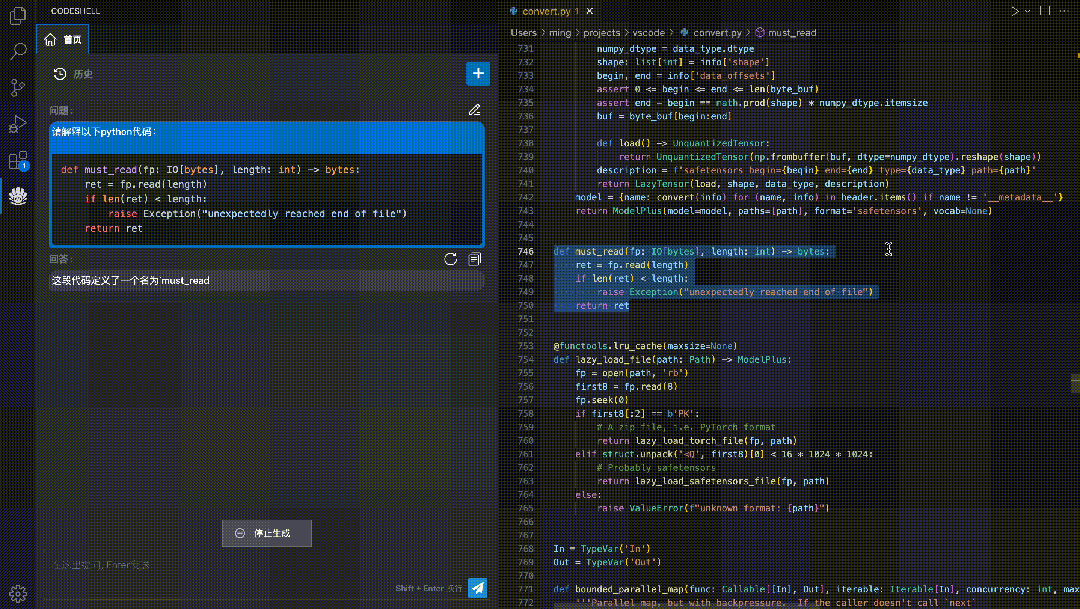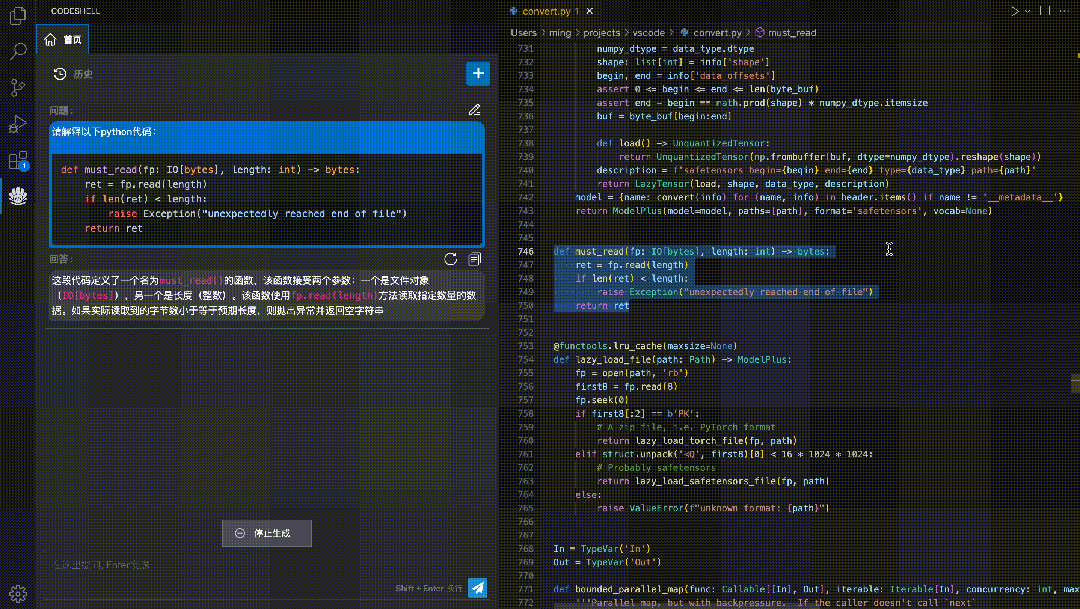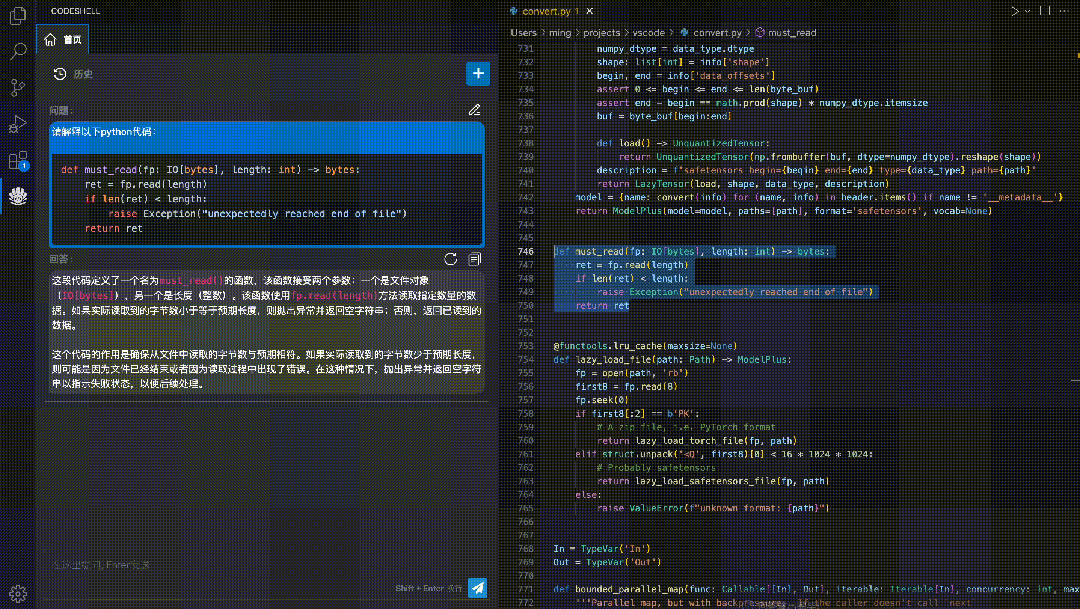
方便易用的CodeShell代码助手插件
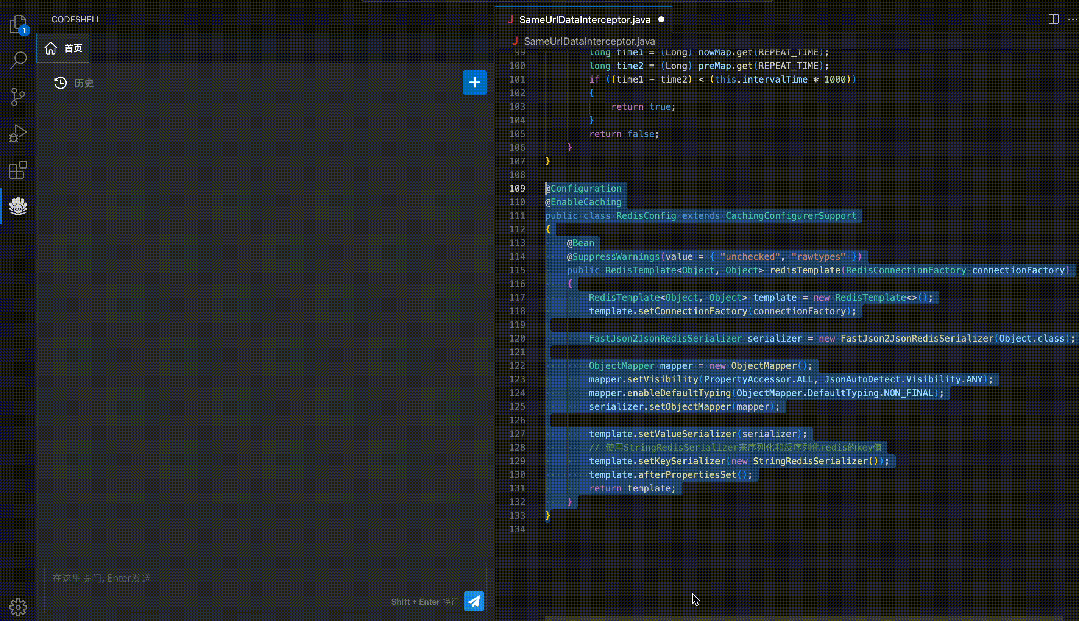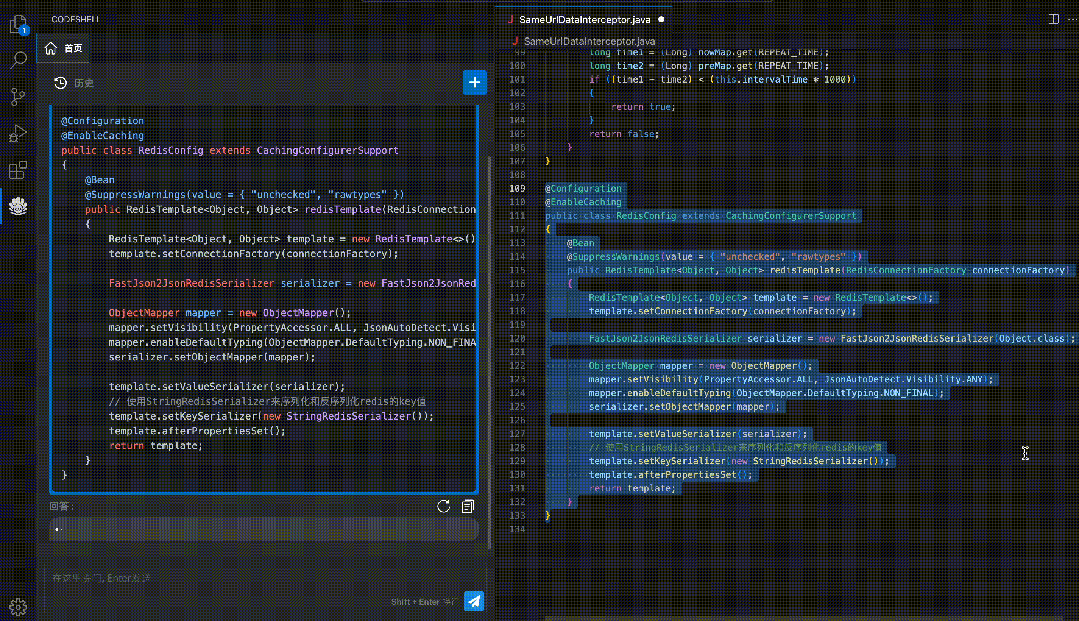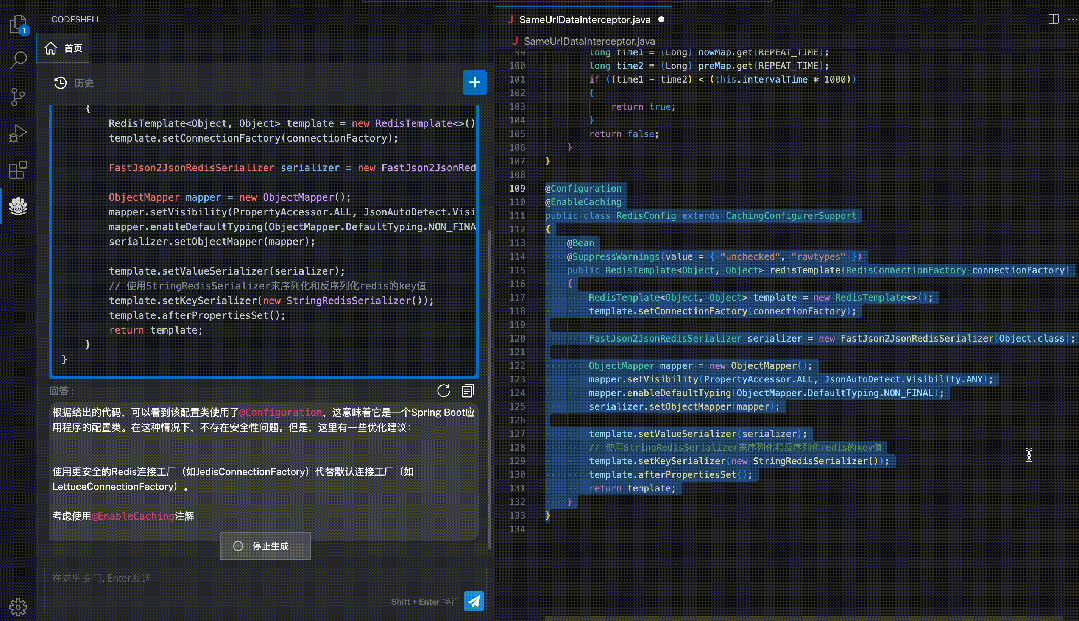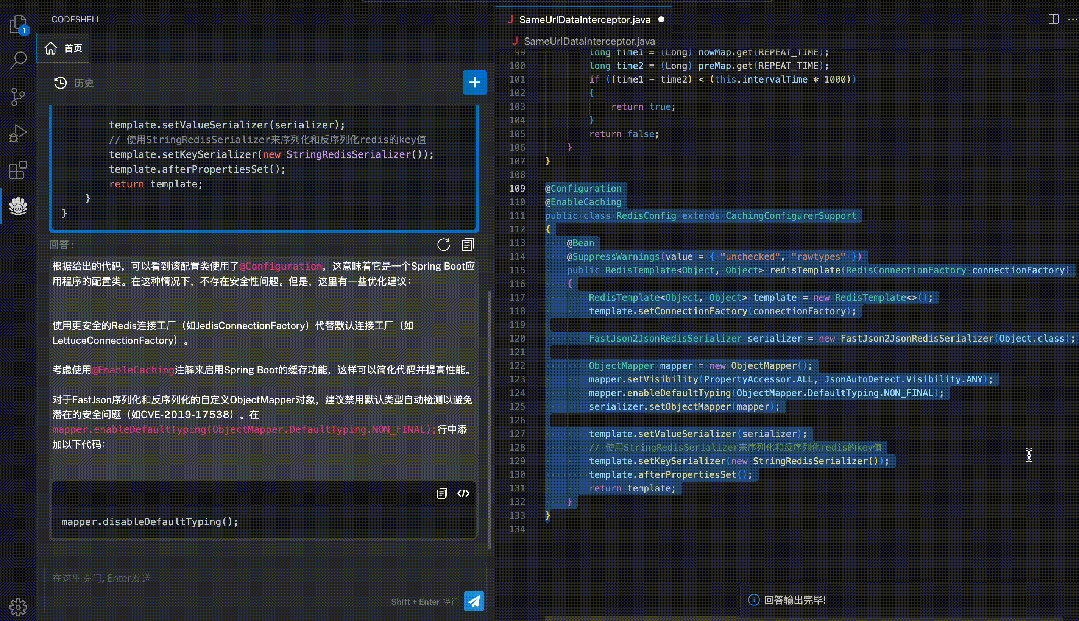
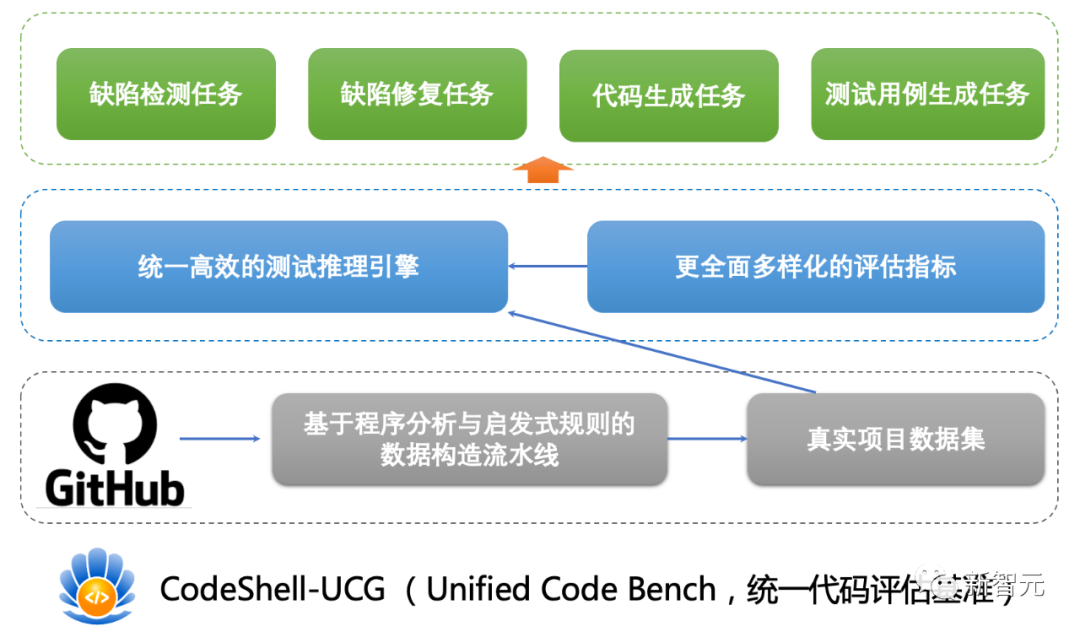
全面的代码能力自动评估工具
评论