
算力猛兽:浪潮NF5468A5 GPU服务器深度测评








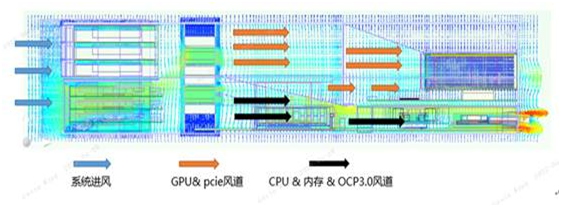

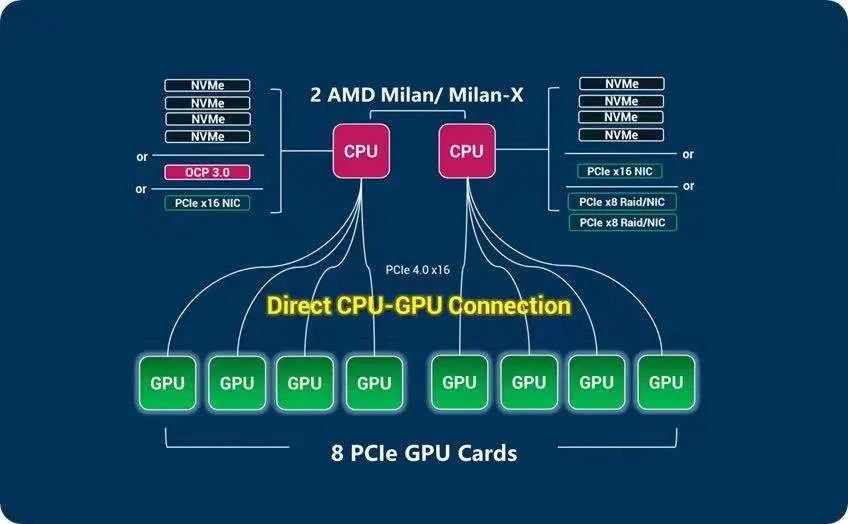
# mpi_options="$mpi_options --map-by ppr:1:l3cache -x OMP_NUM_THREADS=4 -x OMP_PROC_BIND=TRUE -x OMP_PLACES=cores" # mpirun $mpi_options -app ./appfile_ccx |
echo 1 > /proc/sys/vm/compact_memory echo 0 > /proc/sys/kernel/numa_balancing echo ‘always‘ > /sys/kernel/mm/transparent_hugepage/enabled echo ‘always‘ > /sys/kernel/mm/transparent_hugepage/defrag |
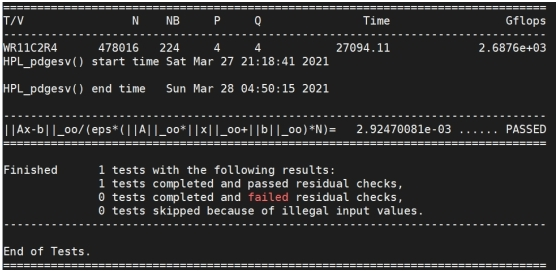
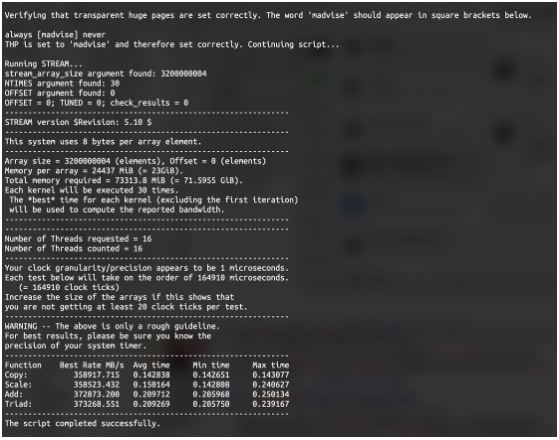





评论