
盘点4个典型的知识图谱项目
导读:本文将列举几个典型的知识图谱项目。
图1-6给出了具有代表性的知识图谱项目的发展历史。
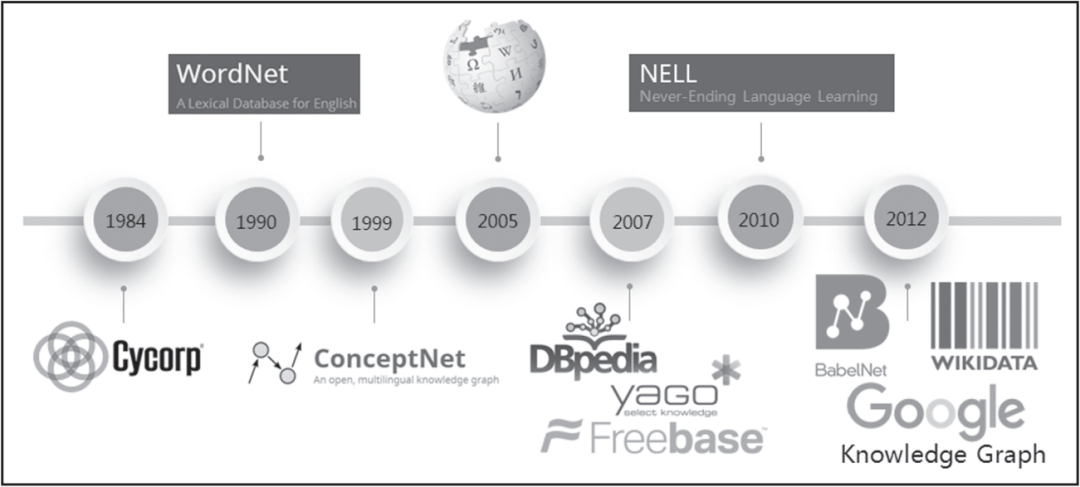
▲图1-6 知识图谱发展历史
从20世纪80年代开始的CYC项目,到Google 2012年提出的知识图谱,再到现在不同语种、不同领域的知识图谱项目大量涌现,知识图谱已经被深入研究并广泛应用于各个行业。
例如,WordNet是典型的词典知识库,BabelNet也是类似于WordNet的多语言词典知识库,YAGO集成了Wikipedia、WordNet、GeoNames三个源的数据,NELL则持续不断从互联网上自动抽取三元组知识。
由于这些项目的相关资料较为丰富,本文仅挑选若干具有代表性的知识图谱项目加以介绍。
01 CYC
https://cyc.com/
CYC项目开始于1984年,最初目标是建立人类最大的常识知识库,将上百万条知识编码成机器可用的形式。根据维基百科数据,CYC包含320万条人类定义的断言,涉及30万个概念和15000个谓词。
1986年,Douglas Lenat推断要构建这样庞大的知识库需设计25万条规则,同时需要350个人年才能完成。这个看似疯狂的计划之所以能够推进,和当时的历史背景是不可分开的。
在CYC中,大部分工作是以知识工程为基础,且大部分事实都是通过手动添加到知识库上的。CYC主要由两部分构成,第一部分是作为数据载体的多语境知识库,第二部分是系统本身的推理引擎。
比如,通过“每棵树都是植物”和“植物最终都会死亡”的知识,推理引擎可以推断出“树会死亡”的结论。1994年图灵奖获得者爱德华·费根鲍姆曾称:“CYC是世界上最大的知识库,也是技术论的最佳代表。”
02 ConceptNet
https://www.conceptnet.io/
ConceptNet是一个利用众包构建的常识知识图谱,起源于麻省理工大学媒体实验室的Open Mind Common Sense(OMCS)项目,它免费开放并且具有多语言版本。其英文版本自1999年发布以来,由15000个贡献者积累了超过100多万个事实。
ConceptNet的一大特点是它的知识描述是非形式化的,更加贴近自然语言的描述。图1-7给出了ConceptNet的一个组织架构。这里列举了一些更为具体的描述,例如:“企鹅是一种鸟”“企鹅出现在动物园”“企鹅想要有足够的食物”等。
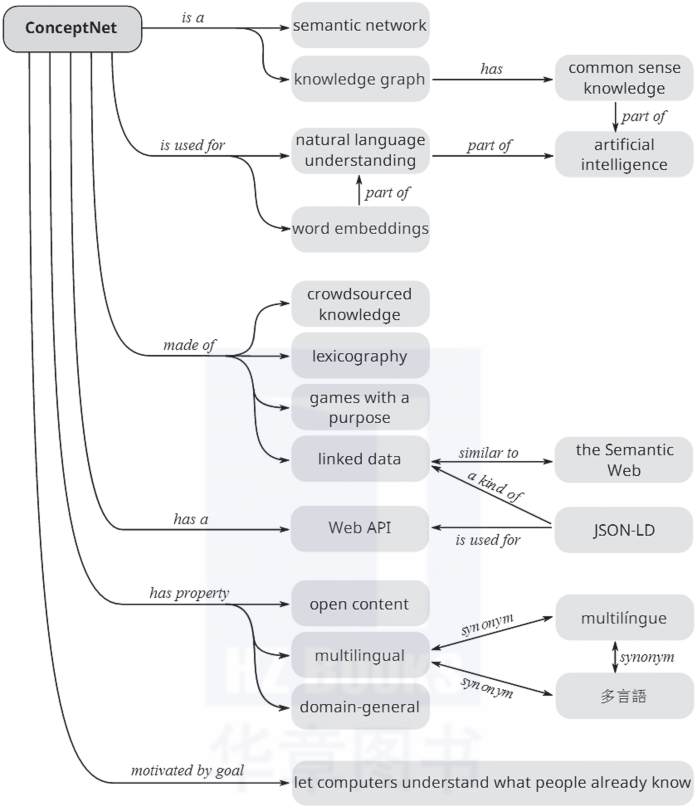
▲图1-7 ConceptNet的组织架构示例
03 DBpedia
https://www.dbpedia.org/
DBpedia是指数据库版本的Wikipedia,是从Wikipedia中的信息框抽取出的链接数据库。英文版本的DBpedia包含600万实体,其中510万个实体可以链接到本体上。并且,DBpedia还和Freebase、OpenCYC、Bio2RDF等多个数据集建立了数据链接。
截至目前,DBpedia是链接开放数据(LOD)中最大的具有代表性的开放链接数据库之一。
04 LOD
https://lod-cloud.net/
上文提到,LOD的初衷是实现Tim有关链接数据作为语义网的一种实现的设想。
其遵循四个原则:
使用URI进行标识;
使用HTTP URI,以便用户可以像访问网页一样查看事物的描述;
使用RDF和SPARQL标准;
为事物添加与其他事物的URI链接,建立数据关联。
截至2020年7月,LOD有1260个知识图谱,包含16187个链接。图1-8给出了LOD统计的知识图谱的示意图,它按照不同的颜色将知识图谱分为9个大类,其中社交媒体、政府、出版和生命科学四个领域的数据占比之和超过 90%。
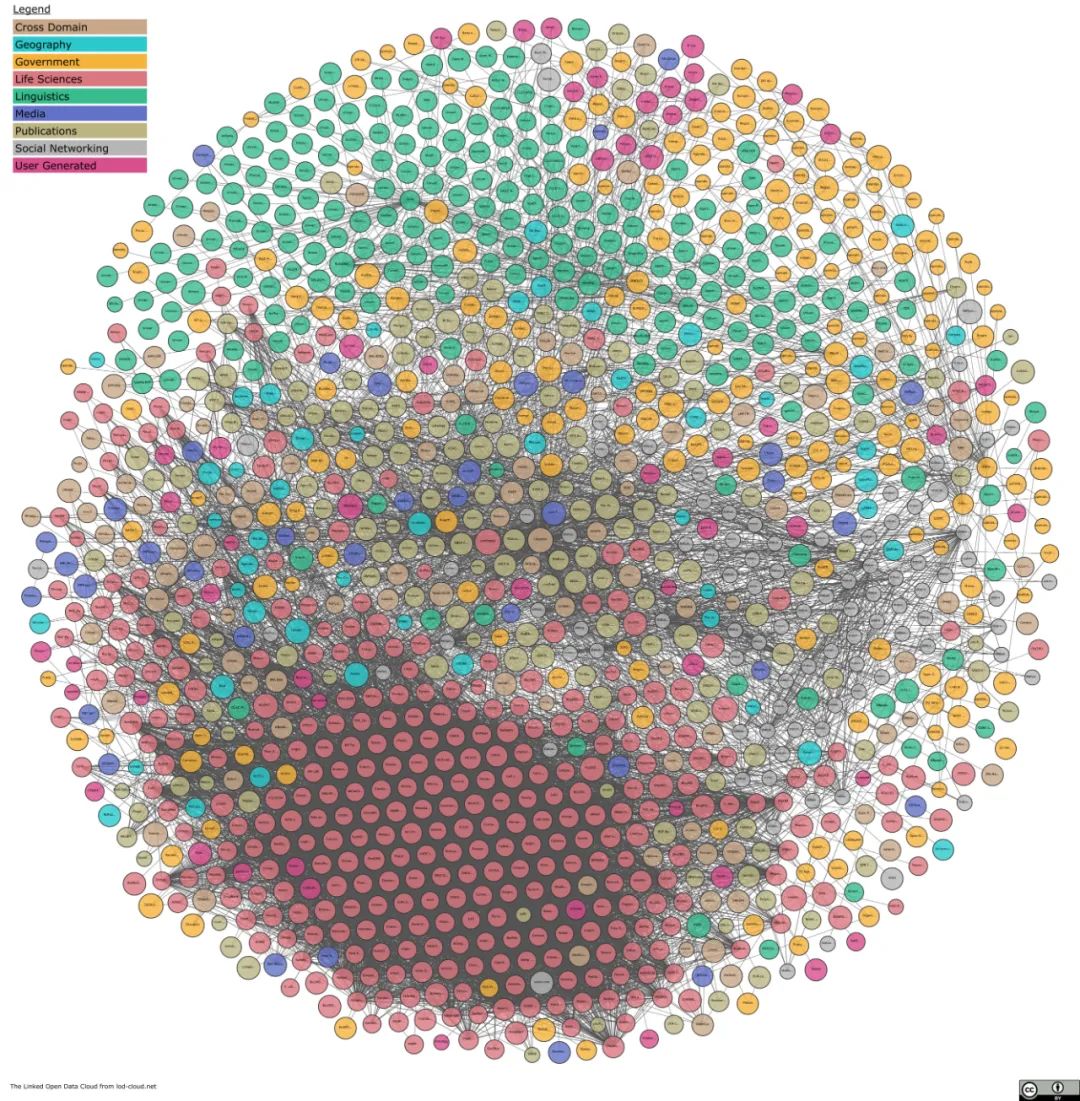
▲图1-8 LOD知识图谱概览

