
数仓建模—OneID
今天是我在上海租房的小区被封的第三天,由于我的大意,没有屯吃的,外卖今天完全点不到了,中午的时候我找到了一包快过期的肉松饼,补充了1000焦耳的能量。但是中午去做核酸的时候,我感觉走路有点不稳,我看到大白的棉签深入我的嘴里,我竟然以为是吃的,差点咬住了,还好我有仅存的一点意识。下午我收到女朋友给我点的外卖——面包(我不知道她是怎么点到的外卖,我很感动),很精致的面包,搁平时我基本不喜欢吃面包,但是已经到了这个份上,我大口吃起来,竟然觉得这是世界上最好吃的食物了。明天早晨5:50的闹钟,去叮咚和美团买菜,看能不能抢几桶泡面吧。愿神保佑,我暗暗下着决心并祈祷着,胸前画着十字。。。
数据仓库系列文章(持续更新)
- 数仓架构发展史
- 数仓建模方法论
- 数仓建模分层理论
- 数仓建模—宽表的设计
- 数仓建模—指标体系
- 数据仓库之拉链表
- 数仓—数据集成
- 数仓—数据集市
- 数仓—商业智能系统
- 数仓—埋点设计与管理
- 数仓—ID Mapping
- 数仓—OneID
- 数仓—AARRR海盗模型
- 数仓—总线矩阵
- 数仓—数据安全
- 数仓—数据质量
- 数仓—数仓建模和业务建模
OneID
前面我们学习了ID Mapping,包括ID Mapping 的背景介绍和业务场景,以及如何使用Spark 实现ID Mapping,这个过程中涉及到了很多东西,当然我们都通过文章的形式介绍给大家了,所以你再学习今天这一节之前,可以先看一下前面的文章
在上一节我们介绍ID Mapping 的时候我们就说过ID Mapping 是为了打通用户各个维度的数据,从而消除数据孤岛、避免数据歧义,从而更好的刻画用户,所以说ID Mapping是手段不是目的,目的是为了打通数据体系,ID Mapping最终的产出就是我们今天的主角OneID,也就是说数据收集过来之后通过ID Mapping 打通,从而产生OneID,这一步之后我们的整个数据体系就将使用OneID作为用户的ID,这样我们整个数据体系就得以打通
OneData
开始之前我们先看一下阿里的OneData 数据体系,从而更好认识一下OneID,前面我们说过ID Mapping 只是手段不是目的,目的是为了打通数据体系,ID Mapping最终的产出就是OneID
其实OneID在我们整个数据服务体系中,也只是起点不是终点或者说是手段,我们最终的目的是为了建设统一的数据资产体系。
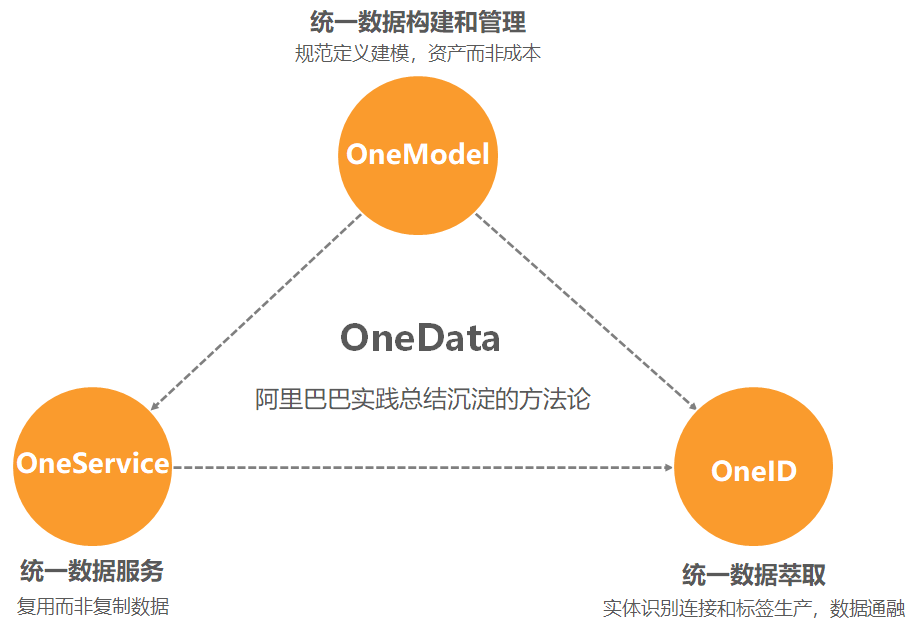
没有建设统一的数据资产体系之前,我们的数据体系建设存在下面诸多问题
- 数据孤岛:各产品、业务的数据相互隔离,难以通过共性ID打通
- 重复建设:重复的开发、计算、存储,带来高昂的数据成本
- 数据歧义:指标定义口径不一致,造成计算偏差,应用困难
在阿里巴巴 OneData 体系中,OneID 指统一数据萃取,是一套解决数据孤岛问题的思想和方法。数据孤岛是企业发展到一定阶段后普遍遇到的问题。各个部门、业务、产品,各自定义和存储其数据,使得这些数据间难以关联,变成孤岛一般的存在。
OneID的做法是通过统一的实体识别和连接,打破数据孤岛,实现数据通融。简单来说,用户、设备等业务实体,在对应的业务数据中,会被映射为唯一识别(UID)上,其各个维度的数据通过这个UID进行关联。
各个部门、业务、产品对业务实体的UID的定义和实现不一样,使得数据间无法直接关联,成为了数据孤岛。基于手机号、身份证、邮箱、设备ID等信息,结合业务规则、机器学习、图算法等算法,进行 ID-Mapping,将各种 UID 都映射到统一ID上。通过这个统一ID,便可关联起各个数据孤岛的数据,实现数据通融,以确保业务分析、用户画像等数据应用的准确和全面。
OneModel 统一数据构建和管理
将指标定位细化为:
1. 原子指标
2. 时间周期
3. 修饰词(统计粒度、业务限定, etc)
通过这些定义,设计出各类派生指标 基于数据分层,设计出维度表、明细事实表、汇总事实表,其实我们看到OneModel 其实没有什么新的内容,其实就是我们数仓建模的那一套东西
OneService 统一数据服务
OneService 基于复用而不是复制数据的思想,指得是我们的统一的数据服务,因为我们一直再提倡复用,包括我们数仓的建设,但是我们的数据服务这一块却是空白,所以OneService核心是服务的复用,能力包括:
- 利用主题逻辑表屏蔽复杂物理表的主题式数据服务
- 一般查询+ OLAP 分析+在线服务的统一且多样化数据服务
- 屏蔽多种异构数据源的跨源数据服务
OneID 统一数据萃取
基于统一的实体识别、连接和标签生产,实现数据通融,包括:
- ID自动化识别与连接
- 行为元素和行为规则
- 标签生产
OneID基于超强ID识别技术链接数据,高效生产标签;业务驱动技术价值化,消除数据孤岛,提升数据质量,提升数据价值。
而ID的打通,必须有ID-ID之间的两两映射打通关系,通过ID映射关系表,才能将多种ID之间的关联打通,完全孤立的两种ID是无法打通的。
打通整个ID体系,看似简单,实则计算复杂,计算量非常大。假如某种对象有数亿个个体,每个个体又有数十种不同的ID标识,任意两种ID之间都有可能打通关系,想要完成这类对象的所有个体ID打通需要数亿次计算,一般的机器甚至大数据集群都无法完成。
大数据领域中的ID-Mapping技术就是用机器学习算法类来取代野蛮计算,解决对象数据打通的问题。基于输入的ID关系对,利用机器学习算法做稳定性和收敛性计算,输出关系稳定的ID关系对,并生成一个UID作为唯一识别该对象的标识码。
OneID实现过程中存在的问题
前面我们知道我们的ID Mapping 是通过图计算实现,核心就是连通图,其实实现OneID我们在打通ID 之后,我们就可以为一个个连通图生成一个ID, 因为一个连通图 就代表一个用户,这样我们生成的ID就是用户的OneID,这里的用户指的是自然人,而不是某一个平台上的用户。
OneID 的生成问题
首先我们需要一个ID 生成算法,因为我们需要为大量用户生成ID,我们的ID 要求是唯一的,所以在算法设计的时候就需要考虑到这一点,我们并不推荐使用UUID,原因是UUID了可能会出现重复,而且UUID 没有含义,所以我们不推荐使用UUID,我们这里使用的是MD5 算法,所以我们的MD5 算法的参数是我们的图的标示ID。
OneID 的更新问题
这里的更新问题主要就是我们的数据每天都在更新,也就是说我们的图关系在更新,也就是说我们要不要给这个自然人重新生成OneID ,因为他的图关系可能发生了变化。
其实这里我们不能为该自然人生成新的OneID ,否则我们数仓里的历史数据可能无法关联使用,所以我们的策略就是如果该自然人已经有OneID了,则不需要重新生成,其实这里我们就是判断该图中的所有的顶点是否存在OneID,我们后面在代码中体现着一点。
OneID 的选择问题
这个和上面的更新问题有点像,上面更新问题我们可以保证一个自然人的OneID不发生变化,但是选择问题会导致发生变化,但是这个问题是图计算中无法避免的,我们举个例子,假设我们有用户的两个ID(A_ID,C_ID),但是这两个ID 在当前是没有办法打通的,所以我们就会为这个两个ID 生成两个OneID,也就是(A_OneID,B_OneID),所以这个时候我们知道因为ID Mapping 不上,所以我们认为这两个ID 是两个人。
后面我们有了另外一个ID(B_ID),这个ID可以分别和其他的两个ID 打通,也就是B_ID<——>A_ID , B_ID<——>C_ID 这样我们就打通这个三个ID,这个时候我们知道
这个用户存在三个ID,并且这个时候已经存在了两个OneID,所以这个时候我们需要在这两个OneID中选择一个作为用户的OneID,简单粗暴点就可以选择最小的或者是最大的。
我们选择了之后,要将另外一个OneID对应的数据,对应到选择的OneID 下,否则没有被选择的OneID的历史数据就无法追溯了
OneID 代码实现
这个代码相比ID Mapping主要是多了OneID 的生成逻辑和更新逻辑 ,需要注意的是关于顶点集合的构造我们不是直接使用字符串的hashcode ,这是因为hashcode 很容易重复
object OneID {
val spark = SparkSession
.builder()
.appName("OneID")
.getOrCreate()
val sc = spark.sparkContext
def main(args: Array[String]): Unit = {
val bizdate=args(0)
val c = Calendar.getInstance
val format = new SimpleDateFormat("yyyyMMdd")
c.setTime(format.parse(bizdate))
c.add(Calendar.DATE, -1)
val bizlastdate = format.format(c.getTime)
println(s" 时间参数 ${bizdate} ${bizlastdate}")
// dwd_patient_identity_info_df 就是我们用户的各个ID ,也就是我们的数据源
// 获取字段,这样我们就可以扩展新的ID 字段,但是不用更新代码
val columns = spark.sql(
s"""
|select
| *
|from
| lezk_dw.dwd_patient_identity_info_df
|where
| ds='${bizdate}'
|limit
| 1
|""".stripMargin)
.schema.fields.map(f => f.name).filterNot(e=>e.equals("ds")).toList
// 获取数据
val dataFrame = spark.sql(
s"""
|select
| ${columns.mkString(",")}
|from
| lezk_dw.dwd_patient_identity_info_df
|where
| ds='${bizdate}'
|""".stripMargin
)
// 数据准备
val data = dataFrame.rdd.map(row => {
val list = new ListBuffer[String]()
for (column <- columns) {
val value = row.getAs[String](column)
list.append(value)
}
list.toList
})
import spark.implicits._
// 顶点集合
val veritx= data.flatMap(list => {
for (i <- 0 until columns.length if StringUtil.isNotBlank(list(i)) && (!"null".equals(list(i))))
yield (new BigInteger(DigestUtils.md5Hex(list(i)),16).longValue, list(i))
}).distinct
val veritxDF=veritx.toDF("id_hashcode","id")
veritxDF.createOrReplaceTempView("veritx")
// 生成边的集合
val edges = data.flatMap(list => {
for (i <- 0 to list.length - 2 if StringUtil.isNotBlank(list(i)) && (!"null".equals(list(i)))
; j <- i + 1 to list.length - 1 if StringUtil.isNotBlank(list(j)) && (!"null".equals(list(j))))
yield Edge(new BigInteger(DigestUtils.md5Hex(list(i)),16).longValue,new BigInteger(DigestUtils.md5Hex(list(j)),16).longValue, "")
}).distinct
// 开始使用点集合与边集合进行图计算训练
val graph = Graph(veritx, edges)
val connectedGraph=graph.connectedComponents()
// 连通节点
val vertices = connectedGraph.vertices.toDF("id_hashcode","guid_hashcode")
vertices.createOrReplaceTempView("to_graph")
// 加载昨日的oneid 数据 (oneid,id,id_hashcode)
val ye_oneid = spark.sql(
s"""
|select
| oneid,id,id_hashcode
|from
| lezk_dw.dwd_patient_oneid_info_df
|where
| ds='${bizlastdate}'
|""".stripMargin
)
ye_oneid.createOrReplaceTempView("ye_oneid")
// 关联获取 已经存在的 oneid,这里的min 函数就是我们说的oneid 的选择问题
val exists_oneid=spark.sql(
"""
|select
| a.guid_hashcode,min(b.oneid) as oneid
|from
| to_graph a
|inner join
| ye_oneid b
|on
| a.id_hashcode=b.id_hashcode
|group by
| a.guid_hashcode
|""".stripMargin
)
exists_oneid.createOrReplaceTempView("exists_oneid")
// 不存在则生成 存在则取已有的 这里nvl 就是oneid 的更新逻辑,存在则获取 不存在则生成
val today_oneid=spark.sql(
s"""
|insert overwrite table dwd_patient_oneid_info_df partition(ds='${bizdate}')
|select
| nvl(b.oneid,md5(cast(a.guid_hashcode as string))) as oneid,c.id,a.id_hashcode,d.id as guid,a.guid_hashcode
|from
| to_graph a
|left join
| exists_oneid b
|on
| a.guid_hashcode=b.guid_hashcode
|left join
| veritx c
|on
| a.id_hashcode=c.id_hashcode
|left join
| veritx d
|on
| a.guid_hashcode=d.id_hashcode
|""".stripMargin
)
sc.stop
}
}
这个代码中我们使用了SparkSQL,其实你如果更加擅长RDD的API,也可以使用RDD 优化,需要注意的是网上的很多代码中使用了广播变量,将vertices 变量广播了出去,其实这个时候存在一个风险那就是如果你的vertices 变量非常大,你广播的时候存在OOM 的风险,但是如果你使用了SparkSQL的话,Spark 就会根据实际的情况,帮你自动优化。
优化点 增量优化
我们看到我们每次都是全量的图,其实我们可以将我们的OneID 表加载进来,然后将我们的增量数据和已有的图数据进行合并,然后再去生成图
val veritx = ye_veritx.union(to_veritx)
val edges = ye_edges.union(to_edges)
val graph = Graph(veritx, edges)
总结
ID Mapping是OneID的提前,OneID是ID Mapping的结果,所以要想做OneID必须先做ID Mapping;OneID是为了打通整个数据体系的数据,所以OneID需要以服务的方式对外提供服务,在数仓里面就是作为基础表使用,对外的话我们就需要提供接口对外提供服务