
2020算法工程师超实用技术路线图
这是一份写给公司算法组同事们的技术路线图,其目的主要是为大家在技术路线的成长方面提供一些方向指引,配套一些自我考核项,可以带着实践进行学习,加深理解和掌握。
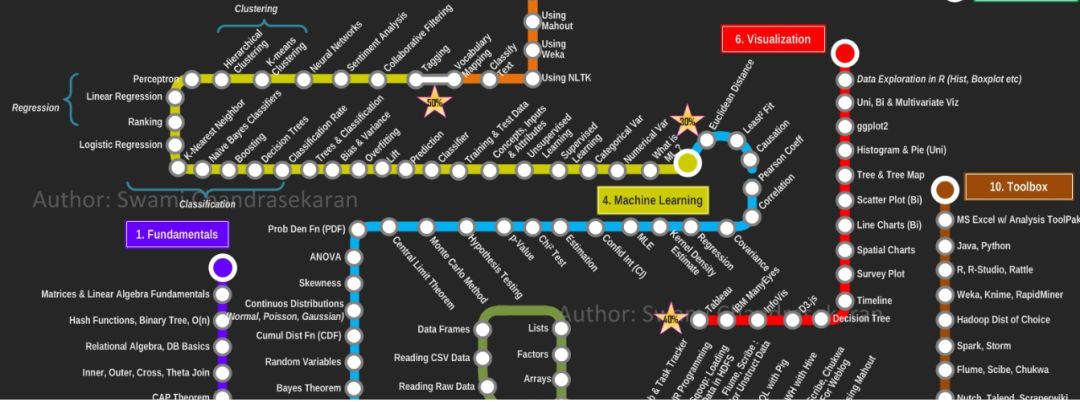
初级:可以在一些指导和协助下独立完成开发任务。具体到算法方面,需要你对于工具框架,建模技术,业务特性等方面有一定的了解,可以独立实现一些算法项目上的需求。
中级:可以基本独立完成一个项目的开发与交付。在初级工程师的基础上,对于深入了解技术原理的要求会更高,并且能够应对项目中各种复杂多变的挑战,对于已有技术和工具进行改造适配。在整体工程化交付方面,对于代码质量,架构设计,甚至项目管理方面的要求会开始显现。另外从业务出发来评估技术选型和方案也变得尤为重要。
高级:可以独立负责一条产品线的运作。在中级工程师的基础上,需要更广阔的技术视野与开拓创新能力,定义整个产品线的前进方向。解决问题已经不是关键,更重要的是提出和定义问题,能够打造出在业界具有领先性和差异性的产品,为公司创造更大的价值。
学习掌握 Python 的基本语法,可以通过各类入门教程来看,个人推荐《Learn Python the Hard Way》。
自我考核:能够读懂大多数的内部项目及一些开源项目代码的基本模块,例如 pandas, sklearn 等。
学习 Python 的编程风格,建议学习观远内部的 Python 代码规范。
自我考核:编写的代码符合编码规范,能够通过各类 lint 检查。
Python 进阶,这方面有一本非常著名的书《Fluent Python》,深入介绍了 Python 内部的很多工作原理,读完之后对于各类疑难问题的理解排查,以及语言高级特性的应用方面会很有帮助。另外动态语言元编程这块,《Ruby 元编程》也是一本非常值得推荐的书。
自我考核:能够读懂一些复杂的 Python 项目,例如 sqlalchemy 中就大量使用了元编程技巧。在实际工程项目中,能够找到一些应用高级技巧的点进行实践,例如基于 Cython 的性能优化等。
领域应用,Python 的应用相当广泛,在各个领域深入下去都有很多可以学习的内容,比如 Web 开发,爬虫,运维工具,数据处理,机器学习等。这块主要就看大家各自的兴趣来做自由选择了,个人推荐熟悉了解一下 Python web 开发,测试开发相关的内容,开拓视野。
自我考核:以 Web 开发和测试开发为例,尝试写一个简单的 model serving http 服务,并编写相应的自动化测试。
学习掌握 Scala 的基本语法,开发环境配置,项目编译运行等基础知识。这里推荐 Coursera 上 Martin Odersky 的课程,《快学 Scala》或《Programming in Scala》两本书也可以搭配着浏览参考。
自我考核:能使用 Scala 来实现一些简单算法问题,例如 DFS/BFS。或者使用 Scala 来处理一些日常数据工作,例如读取日志文件,提取一些关键信息等。
学习使用 Scala 来开发 Spark 应用,推荐 edX 上的《Big Data Analytics Using Spark》或者 Coursera 上的《Big Data Analytics with Scala and Spark》,另外有些相关书籍也可以参考,比如《Spark 快速大数据分析》等。
自我考核:能够使用 Spark 的 Scala API 来进行大规模的数据分析及处理,完成 lag feature 之类的特征工程处理。
JVM 的原理学习,Scala/Java 都是 JVM 上运行的优秀语言,其背后是一个非常大的生态,包括在 Web,Android,数据基础架构等方面有广泛的应用。JVM 相比 Python 虚拟机,发展更加成熟,有一套非常完善的 JDK 工具链及衍生的各类项目,便于开发者 debug,调优应用。这方面推荐学习周志明的《深入理解 Java 虚拟机》。
自我考核:理解 JVM GC 原理,能通过 JDK 中相关工具或者优秀的第三方工具如 arthas 等,排查分析 Spark 数据应用的资源使用情况,GC profiling,hot method profiling 等,进而进行参数优化。
计算机语言理论。Programming Language 作为计算机科学的一个重要分支,包含了很多值得深入研究的主题,例如类型论,程序分析,泛型,元编程,DSL,编译原理等。这方面的很多话题,在机器学习方面也有很多实际应用,比如 TVM 这类工作,涉及到大量编译原理的应用,知乎大佬 “蓝色” 也作为这个领域的专家在从事深度学习框架相关的工作。llvm, clang 作者 Chris Lattner 也加入 Google 主导了 Swift for Tensorflow 等工作。Scala 作为一门学术范非常强的语言,拥有极佳的 FP,元编程等能力支持,强大的类型系统包括自动推理,泛型等等高级语言特性,相对来说是一门非常 “值得” 学习的新语言,也是一个进入 PL 领域深入学习的 "gateway drug" :) 对这个方面有兴趣的同学,可以考虑阅读《Scala 函数式编程》,《冒号课堂》,以及 Coursera 上《Programming Languages》也是一门非常好的课程。另外只想做科普级了解的同学,也可以读一读著名的《黑客与画家》感受一下。
自我考核:能够读懂 LightGBM 里对于 tweedie loss 的相关定义代码。
自我考核:能够基本明确运行一个模型训练任务过程中,底层使用到的硬件,操作系统组件,及其交互运作的方式是如何的。
自我考核:开发一个 shell 小工具,实现一些日常工作需求,例如定时自动清理数据文件夹中超过一定年龄的数据文件,自动清理内存占用较大且运行时间较久的 jupyter notebook 进程等。
自我考核:能够分析定位出 LightGBM 训练过程中的性能瓶颈,精确到函数调用甚至代码行号的级别。
自我考核:能够设计相关的数据结构,实现一个类似 airflow 中点击任意节点向后运行的功能。
自我考核:审视自己写的项目代码,能发现并修正至少三处不符合最佳编码实践的问题。
自我考核:在项目中,找到一处可以应用设计模式的地方,进行重构改进。
自我考核:在项目中,实现基础的数据输入测试,预测输出测试。
自我考核:在某个负责项目中运用项目管理方法,完成一个实际的需求评估,项目规划,设计与评审,开发执行,项目上线,监控维护流程,并对整个过程做复盘总结。
自我考核:设计一个算法项目 Docker 镜像自动打包系统。
自我考核:理解实际项目中的数据分布情况,并使用统计建模手段,推断预测值的置信区间。
自我考核:对内沟通方面,能使用可视化技术,分析模型的 bad case 情况,并确定优化改进方向。对外沟通方面,能独立完成项目的数据分析沟通报告。
从分析出发指导调优更有方向性,而不是凭经验加个特征,改个参数碰运气。哪怕是业务方提供的信息,也最好是有数据分析为前提再做尝试,而不是当成一个既定事实。
由分析发现的根源问题,对于结果验证也更有帮助。尤其在预测的数据量极大情况下,加一个单一特征很可能总体只有千分位准确率的提升,无法确定是天然波动还是真实的提升。但如果有分析的前提,那么我们可以有针对性的看对于这个已知问题,我们的调优策略是否生效,而不是只看一个总体准确率。
对于问题的彻底排查解决也更有帮助,有时候结果没有提升,不一定是特征没用,也可能是特征代码有 bug 之类的问题。带着数据分析的目标去看为什么这个特征没有效果,是模型没学到还是特征没有区分度等,有没有改进方案,对于我们评判调优尝试是否成功的原因也更能彻查到底。
数据分析会帮助我们发现一些额外的问题点,比如销量数据清洗处理是不是有问题,是不是业务本身有异常,需要剔除数据等。
自我考核:在项目中形成一套可以重复使用的误差分析方案,能够快速从预测输出中定位到目前模型最重要的误差类别,并一定程度上寻找到根本原因。
自我考核:结合实际业务和机器学习理论知识,挖掘项目中算法表现不够好的问题,并通过算法改造进行提升或解决。
自我考核:能够在实际项目中,使用深度学习模型,达到接近甚至超过传统 GBDT 模型的精确度效果,或者通过 ensemble,embedding 特征方式,提升已有模型的精度。
自我考核:在项目中复现一个 Kaggle 获胜方案,检验其效果,分析模型表现背后的原因,并尝试进行改进。
自我考核:在已有项目中,能把至少三个使用 apply 方法的 pandas 处理修改成向量化运行,并测试性能提升。使用 window function 或其它方案来实现 lag 特征,减少 join 次数。
通用机器学习:scikit-learn,Spark ML,LightGBM
通用深度学习:Keras/TensorFlow,PyTorch
特征工程:tsfresh, Featuretools,Feast
AutoML:hyperopt,SMAC3,nni,autogluon
可解释机器学习:shap,aix360,eli5,interpret
异常检测:pyod,egads
可视化:pyecharts,seaborn
数据质量:cerberus,pandas_profiling,Deequ
时间序列:fbprophet,sktime,pyts
大规模机器学习:Horovod,BigDL,mmlspark
Pipeline:MLflow, metaflow,KubeFlow,Hopsworks
自我考核:在 LightGBM 框架下,实现一个自定义的损失函数,并跑通训练与预测流程。
自我考核:实现一个简单的 model serving http 服务。
自我考核:能够在多机上进行亿级数据的 GBDT 模型训练与预测。
自我考核:能够通过 LLVM JIT 来优化实现 Spark window function 的执行性能。
自我考核:在典型的销量预测场景中实现增量训练与预测。
自我考核:使用 Airflow 完成一个标准的项目 pipeline 搭建与运行。
自我考核:在项目中实现输入数据的分布测试,特征工程测试及特征重要性准入测试。
自我考核:在实际项目中实行一套标准的实验记录手段,并能从中找出各类实验尝试带来的精度提升的 top 5 分别是哪些操作。
自我考核:部署一个实时预测服务,能够根据用户输入产生相应的预测结果。
自我考核:通过 Jenkins 实现 pipeline 自动测试,打包,上线流程。
自我考核:将三个项目中做过的问题排查改造成常规监控手段,支持自动的问题发现,告警通知,如有可能,提供自动化或半自动化的问题排查解决方案。
自我考核:总结各个 MLOps 产品的功能模块矩阵对比,能够根据项目需求来进行产品选型与使用。
自我考核:能够理解 SQL 执行计划,并能够根据执行计划来做索引或查询调优。
自我考核:在 MySQL 中设计相关表结构,存储实际项目中的一系列中间数据集。
自我考核:考虑一个线上模型服务的场景,用户输入作为基础特征,使用类似 Redis 的 KV 系统,实现实时获取其它特征,并进行模型预测。
自我考核:对于已有的算法项目,总结制定一套开发,测试,发布,运维的标准流程,且尽可能自动化执行。
自我考核:在项目中实现不同机器能够访问同一个 s3 路径的文件,并进行正常的数据读写,模型文件读写等功能。
自我考核:用 Spark 来实现项目中的特征工程,并在一定数据量情况下取得比单机 Pandas 更好的性能效果。
自我考核:了解超参优化的基础概念,能够在项目中应用框架工具来实现模型超参的贝叶斯优化流程。
自我考核:设计一系列 meta feature 与 meta learning 手段,实现对新任务的参数选择的初始化。
自我考核:使用一种 AutoML 系统来进行项目的模型自动优化,并与手工优化的结果进行比较,看是否有所提升,及寻找背后的原因。
自我考核:理解 LIME,Shapley 的运作原理,并分析其局限性,尝试提出改进方案。
自我考核:使用 shap,eli5 等工具来进行模型解释,并在此基础上形成面向开发者的模型 debug,误差分析及改进方案,或形成面向业务的 what-if 分析看板。

原文链接:https://zhuanlan.zhihu.com/p/192633890