
【机器学习】关于逻辑回归,面试官都怎么问
作者 | Chilia
整理 | NewBeeNLP
最近准备开始如同考研一般的秋招复习了!感觉要复习的东西真的是浩如烟海;) 有2023届做算法的同学可以加入我们一起复习~
1. 介绍
逻辑回归假设数据服从「伯努利分布」(因为是二分类),通过「极大化似然函数」的方法,运用梯度下降来求解参数,来达到将数据二分类的目的。
决策函数
设「x」是m维的样本特征向量(input);y是标签label,为正例和负例。这里 是模型参数,也就是回归系数。则该样本是正例的概率为:
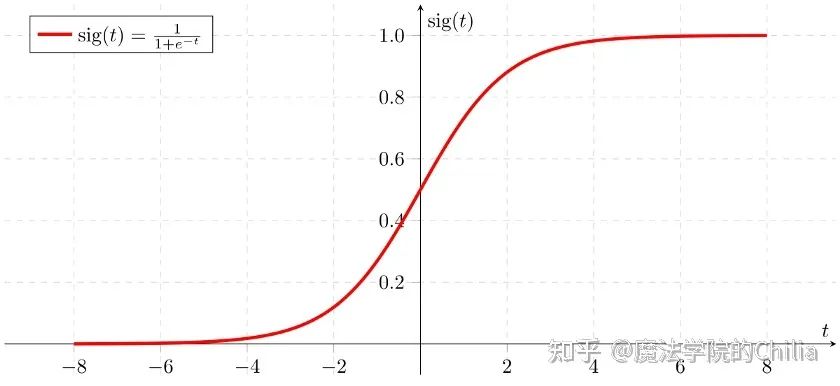
这里使用sigmoid函数的目的是为了把普通的线性回归问题转化为输出为[0,1]区间的二分类问题。
损失函数
在统计学中,常常使用极大似然估计法来求解参数。即找到一组参数,使得在这组参数下,我们的数据的似然度(概率)最大。
设:
那么,似然函数为:
为了更方便求解,我们对等式两边同取对数,写成「对数似然函数」:
从另一个角度来讲,对于一个样本来说,它的「交叉熵损失函数」为:
所有样本的交叉熵损失函数为:
这就是对数似然函数取相反数嘛!所以,在逻辑回归模型中,「最大化对数似然函数和最小化损失函数实际上是等价的」。
梯度下降求解

对一个样本做梯度下降,
并行化
LR的一个好处就是它能够并行化,效率很高。使用小批量梯度下降:
这些操作均可用矩阵运算来并行解决。
2. 常见面试题
Q1: LR与线性回归的区别与联系
逻辑回归是一种广义线性模型,它引入了Sigmoid函数,是非线性模型,但本质上还是一个线性回归模型,因为除去Sigmoid函数映射关系,其他的算法都是线性回归的。
逻辑回归和线性回归首先都是广义的线性回归,在本质上没多大区别,区别在于逻辑回归多了个Sigmoid函数,使样本映射到[0,1]之间的数值,从而来处理分类问题。另外逻辑回归是假设变量服从伯努利分布,线性回归假设变量服从高斯分布。逻辑回归输出的是离散型变量,用于分类,线性回归输出的是连续性的,用于预测。逻辑回归是用最大似然法去计算预测函数中的最优参数值,而线性回归是用最小二乘法去对自变量量关系进行拟合。
Q2: 连续特征的离散化:在什么情况下将连续的特征离散化之后可以获得更好的效果?例如CTR预估中,特征大多是离散的,这样做的好处在哪里?
答:在工业界,很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
离散特征的增加和减少都很容易,易于模型的快速迭代,容易扩展; 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰; 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合。具体来说,离散化后可以进行特征交叉,由M+N个变量变为M*N个变量; 特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问。
Q3:逻辑回归在训练的过程当中,如果有很多的特征高度相关,或者说有一个特征重复了100遍,会造成怎样的影响?
先说结论,如果在损失函数最终收敛的情况下,其实就算有很多特征高度相关也不会影响分类器的效果。可以认为这100个特征和原来那一个特征扮演的效果一样,只是可能中间很多特征的值正负相消了。
为什么我们还是会在训练的过程当中将高度相关的特征去掉?
去掉高度相关的特征会让模型的可解释性更好 可以大大提高训练的速度。如果模型当中有很多特征高度相关的话,就算损失函数本身收敛了,但实际上参数是没有收敛的,这样会拉低训练的速度。其次是特征多了,本身就会增大训练的时间。
- END -
往期精彩回顾 本站qq群955171419,加入微信群请扫码: