文章将少样本学习的方法分为三类:基于数据、基于模型和基于算法。其中,基于数据的方法包括对训练集进行变换和对其他数据集进行变换;基于模型的主要思想是通过先验知识限制假设空间的大小,使模型只需要较少样本便能训练最优分类器;基于算法的思想主要是通过学习最优参数的优化步骤或者以较优参数为起点。
转载自 | Jy的炼丹炉@知乎
链接 | https://zhuanlan.zhihu.com/p/389689066
论文地址: https://arxiv.org/abs/1904.05046
下面对上述的方法进行详细介绍。
01
该策略通过将每个样本转换为几个有一定变化的样本来增广训练集的样本数。但是,目前为止变换训练集的方法只适用于图像。 人工规则(Handcrafted Rule): 在图像识别任务中,使用手工制作的规则变换原始样本作为预处理程序,例如、翻转、剪切、缩放、反射、裁剪和旋转。 学习规则(Learned Transformation): 该策略通过将原始的样本复制到几个样本中,然后通过学习到的转换规则进行修改来增广训练集。 讨论:因为少样本并没有很好地体现出数据的分布,因此基于简单地进行人工规则进行数据增广而不考虑任务或者需要的数据分布可能只能提供很少的额外监督信息。 该策略将来自其他数据集的样本进行变换,达到增广数据得到目的。 弱标记或无标记数据集(Weakly Labeled or Unlabeled Data Set): 该策略使用了一个大规模的弱标记或未标记的相同数据集
举个栗子:在视频手势识别中,有研究团队使用一个大但弱标记的手势库。通过训练集训练的分类器,来从若标记手势库中选择与训练集相同的手势样本,然后使用这些选择的示例构建最后的手势分类器。
类似的数据集(Similar Data Set): 这种策略通过聚合来自其他类似但更大的数据集的样本对来增广训练集。可以通过聚合从类似数据集的样本来生成新的样本,其中聚合权重通常是从其他信息源提取的相似度量。
新奇的思路:老虎数据集类似于猫数据集,因此可以使用生成对抗网络(GAN),从老虎数据集中合成猫的新样本。
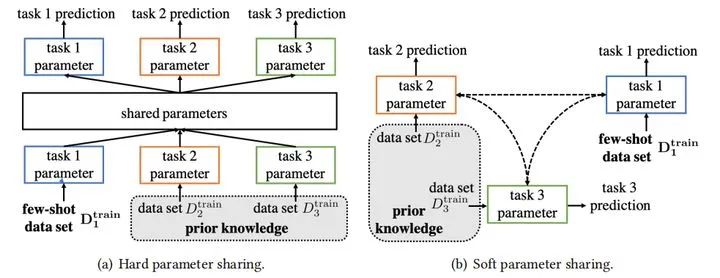
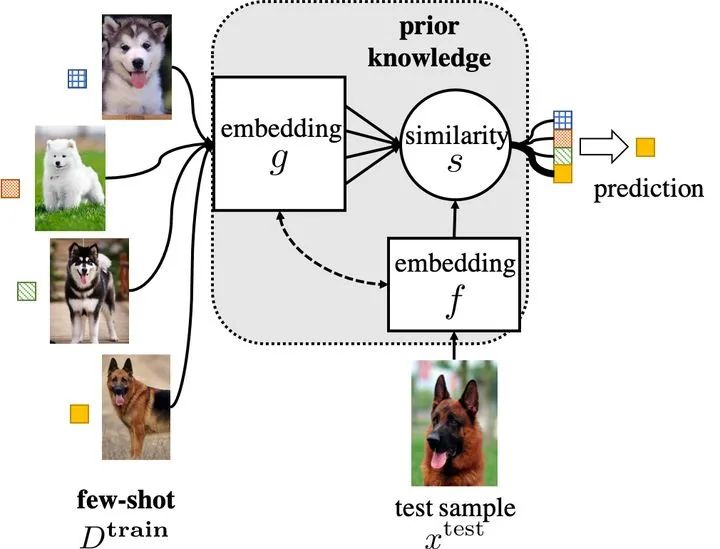
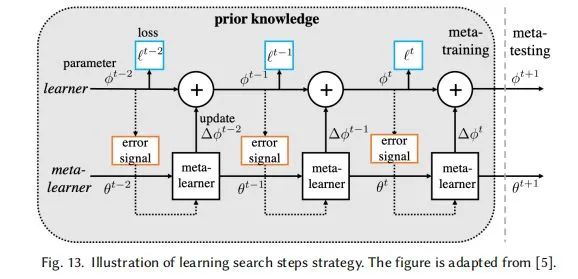
讨论:1.2中这两种方法实际成本是比较高的:弱标记数据集质量可能很低,从更大数据集选择相似样本也需要足够的的监督信息。 对于使用普通的机器学习模型来处理少样本训练,则必须选择一个小的假设空间H。一个小的假设空间仅需要训练更少的样本就可以得到最优假设。 因此,基于模型的策略利用先验知识来影响假设空间的选择,例如:对假设空间进行约束,这样仅用较少训练样本就能实现最优拟合。 2.1 多任务学习(Multitask learning) 多任务学习方法自发地学习多个学习任务,利用跨任务共享的通用信息和每个任务的特定学习信息来实现权重共享,从而进一步约束假设空间H。 其中参数共享分为硬参数共享和软参数共享,如下图所示 硬参数共享:任务之间明确共享参数,可以只共享部分参数,例如可以通过多个任务共享几个网络的前几层来学习通用信息,最后一层来处理每个任务的不同输出。其他任务只能更新其特定于任务的层,而源任务可以更新共享层和特定层。 2.2 嵌入学习(embedding learning)—— 一般用于分类 嵌入学习将样本映射到低维嵌入空间,在那里可以很容易地识别相似和不同的样本,因此H收到约束。将样本特征和测试数据特征embedding到低维空间Z,通过相似性度量,将测试数据预测为最相似的训练样本的类。 2.3 外部记忆学习(Learning with External Memory): 用外部记忆学习将所需的知识直接记忆在外部记忆中,以供检索或更新,通过一些相似性度量。然后,它使用相似性来确定从内存中提取哪些知识,使得之后的x能够通过外部记忆获取相关图像进行比对来实现更好的预测。 2.4 生成式模型(Generative Modeling) 这个方法是基于概率分布的方法,利用先验知识和数据来获得估计的分布,来限制假设空间H的形状 基于算法是学习在假设空间H中搜索最佳假设h∗的参数θ的策略。 3.1 改善现有的参数:从其他任务中获得初始参数用于初始化搜索,然后在新的训练集上进行优化。(例如;迁移学习) Fine-tune θ0 with Regularization(使用正则化微调θ0(之前训练好的参数)) 当初始化参数遇到新问题时,只需少量的样本进行几步梯度下降就可以取得较好的效果。防止overfitting:正则化、冻结部分层的参数、先聚类后分组反向传播微调 聚合一组θ0: 从多个网络的训练好的θ0中选取相关的值,并将它们聚合到适合Dtrain调整的初始化中。 新参数微调θ0: 预先训练的θ0可能不适合新FSL任务的结构。具体来说,该策略在学习δ的同时微调θ0,使要学习的模型参数变为θ = {θ0,δ},其中δ为额外的新参数。 3.2 Refine Meta-learned θ : Model-Agnostic Meta-Learning (MAML)(模型无关自适应) 该策略是与模型无关的meta-learning的方法,其核心思想是学习模型的初始化参数使得在一步或几步迭代后在新任务上的精度最大化。它学的不是模型参数的更新函数或是规则,它不局限于参数的规模和模型架构(比如用RNN或siamese)。本质上也是学习一个好的特征使得可以适合很多任务(包括分类、回归、增强学习),并通过fine-tune来获得好的效果。 3.3 学习搜索步骤(优化器学习): 使用元学习提供的搜索步骤/更新参数的规则(最佳的梯度下降方向 or 步长)。最终学会如何在新的分类任务上,对分类器网络(learner)进行初始化和参数更新。这个优化算法同时考虑一个任务的短时知识和跨多个任务的长时知识。
双一流大学研究生团队创建,专注于目标检测与深度学习,希望可以将分享变成一种习惯! 整理不易,点赞 三连↓