
英伟达首席科学家Bill Dally:摩尔定律已失效,“黄氏定律”成全新指标
大数据文摘
共 4247字,需浏览 9分钟
·
2020-12-16 22:24

安培如何合理运用稀疏性特征


未来,GAN也能语音助手化了

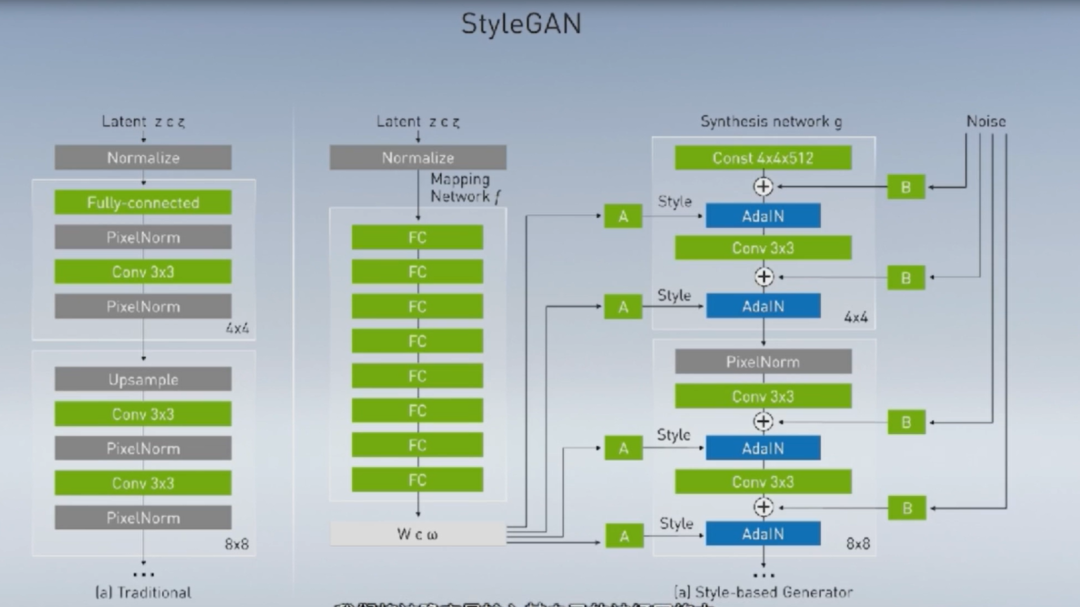
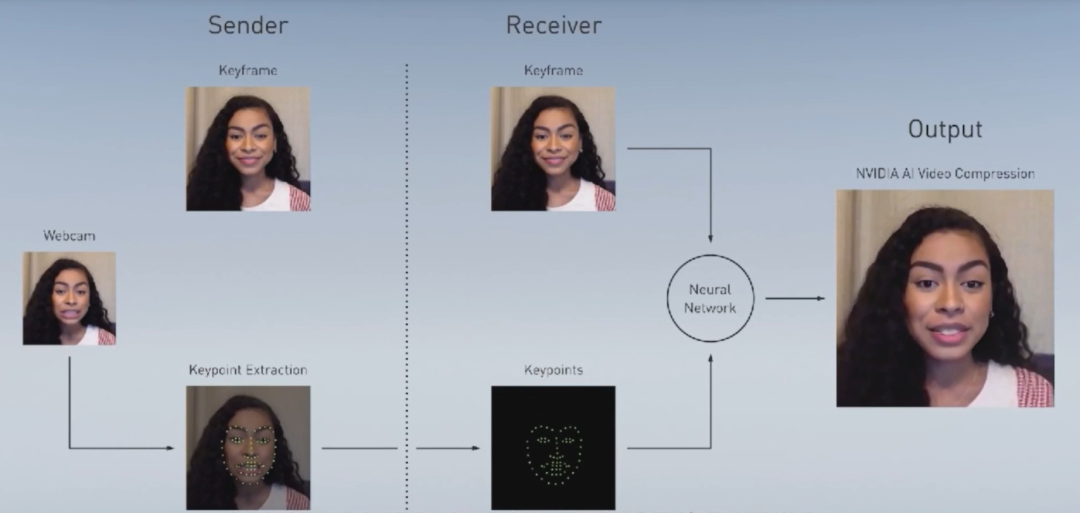

GPU成就了深度学习
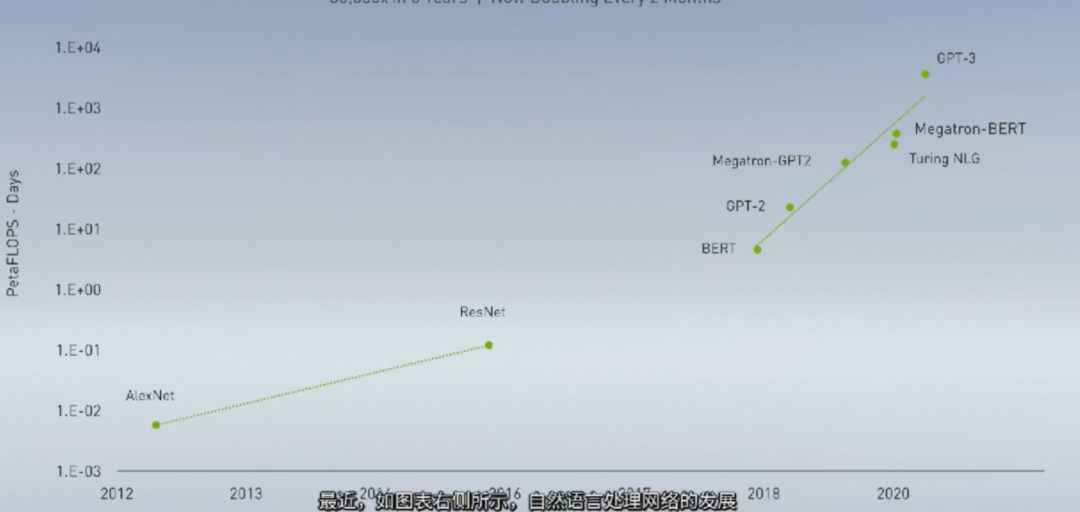
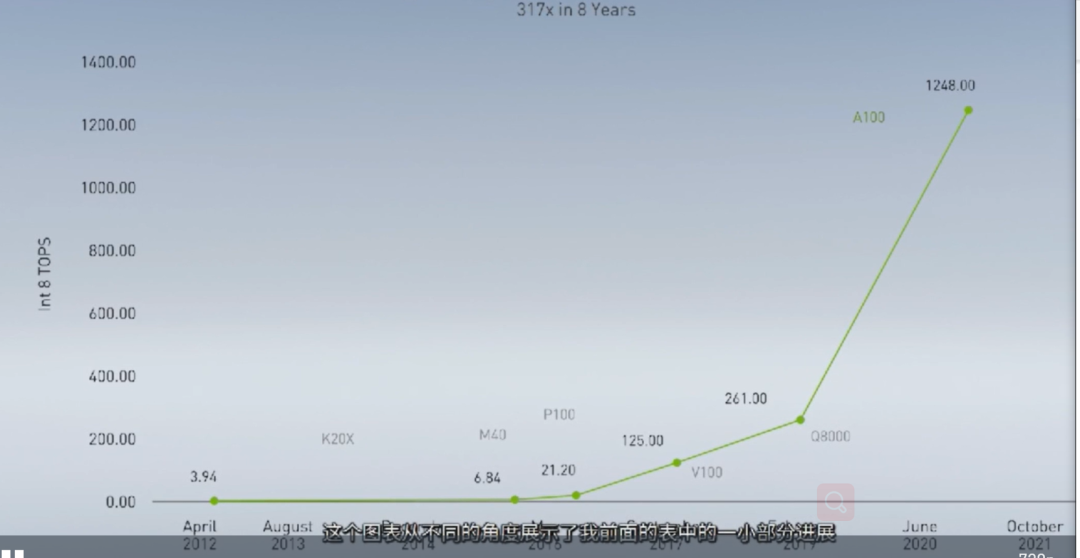
自动驾驶:分场景的解决方案


并行模拟机器人,合理应对各类路况
如今,越来越多的工厂都配备了机器人,它们都能做到毫米级精度的精准定位,但很多也都缺少与人的交互能力。

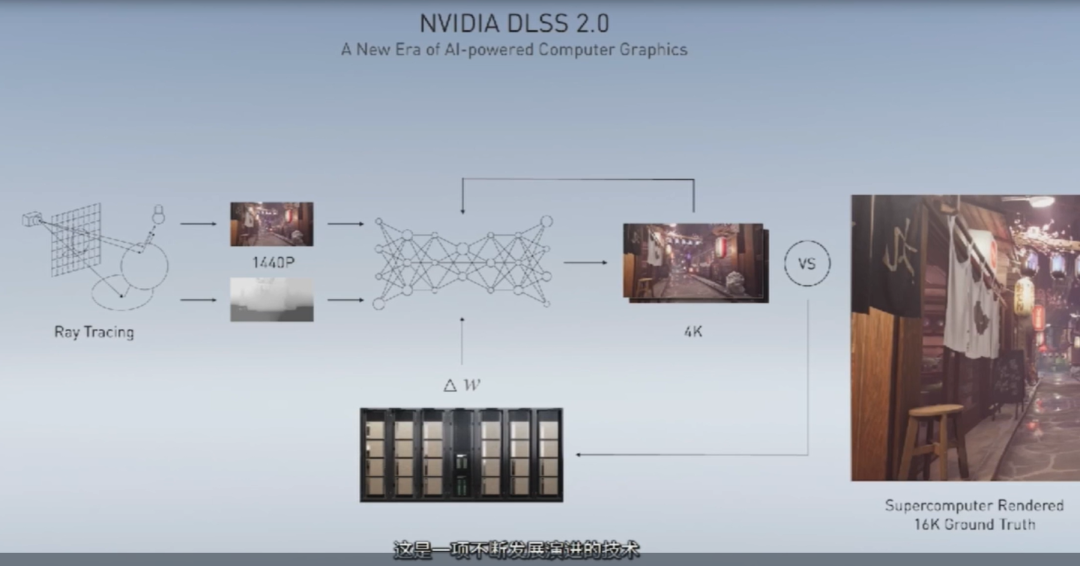
优化图形光源和照明

评论