
简单的 ConvMixer 会给 CV 带来新范式吗?
1Patch 就够了?
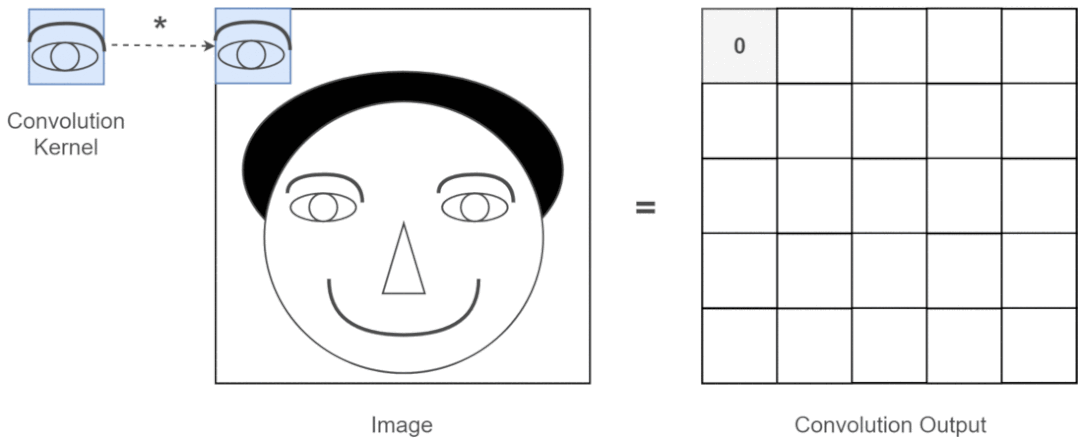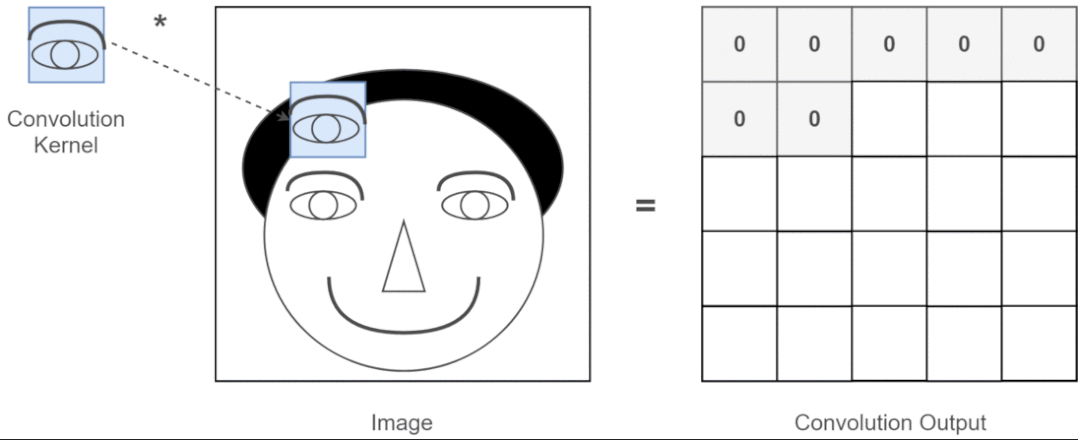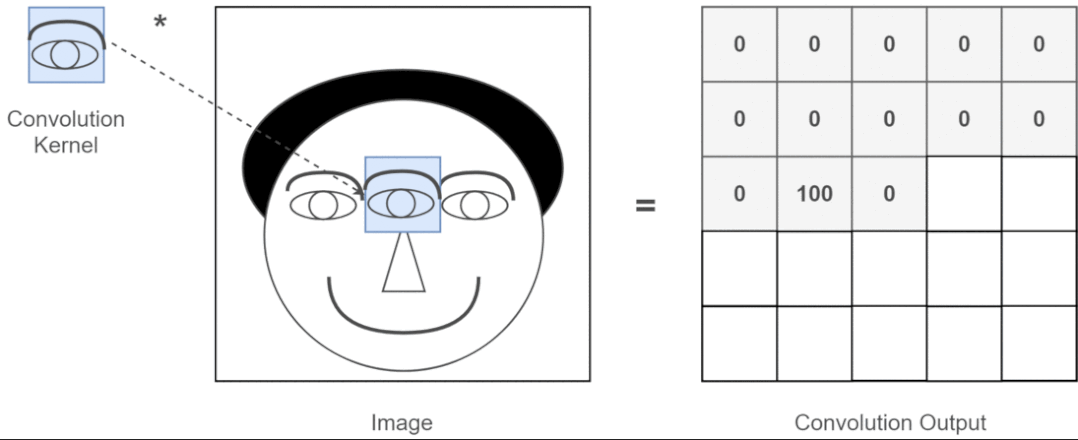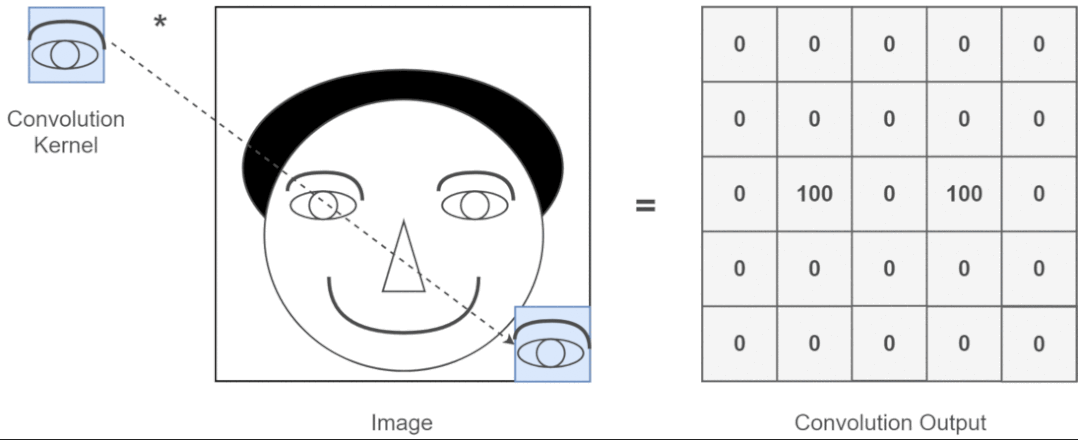
近年来,卷积神经网络一直是视觉任务的主要架构,但最近的实验表明,基于 Transformer 的模型,尤其是 Vision Transformer (ViT),在某些情况下可能会超过 CNN 的性能。
然而,由于 Transformer 中自注意力层的计算复杂度是关于 patch 数量的二次方,对于大图的计算量可观,因此后续一大波工作从这个角度作了一些改进,关于这点这里就不谈了。
ViT 的成功同时也带来了一个问题,那就是它的性能主要是由于 Transformer 架构(自注意力机制)的强大引起的,或者还是由于使用了 patch 作为输入表示主导的呢?而本篇的主角,也是 ICLR 2022 还在审稿中的新作 ConvMixer,就为后者提供了一些证据。
具体而言,ConvMixer 是一个极其简单的模型,在架构精神上与 ViT 以及更基本的 MLP-Mixer 相似,它也是直接将 patch 作为输入进行操作,但是它分离了空间和通道两个维度上的混合,并在整个网络中保持相同的通道数和分辨率。
所谓 ConvMixer,就是仅使用卷积来实现混合步骤。尽管它很简单,但作者表明 ConvMixer 的性能甚至优于 ViT、MLP-Mixer 及其类似的变体,此外还优于 ResNet 等经典视觉模型。
Patches Are All You Need从这个题目以及模型名字 ConvMixer 似乎可以感觉到,ViT 中的自注意力并不是必须的,只要使用合适大小的 patch,再加上通道内以及通道间的分离卷积混合,照样能抓取像素之间的远程关联,实现很好的数据表示。
该论文尚在评审中,有兴趣的可以前往参观 https://openreview.net/forum?id=TVHS5Y4dNvM。有些人认为该论文似乎并没有提供非常大的洞见以及理论,更偏向于从实验中发现了好用的结构设计并给以大家一定的启示。
2动机
ConvMixer 架构基于 patch 以及混合的基本思想。具体来说,
用 depthwise 卷积来混合通道内的值, 用 pointwise 卷积来混合通道间的值。
以往工作的一个关键思想是 MLP 和自注意力可以混合较远的空间信息,即它们可以具有任意大的感受野。因此,该研究通过使用较大的卷积核来实现混合远程关联。
3主要参数
ConvMixer 的实例化取决于四个参数:
1、patch 大小 ; 2、patch 的嵌入维度 ; 3、深度 ,即 ConvMixer 层的重复次数; 4、卷积层的 kernel 大小 。
可以根据它们的嵌入维度和深度命名具体的 ConvMixers,如 ConvMixer-h/d。
4ConvMixer 核心内容
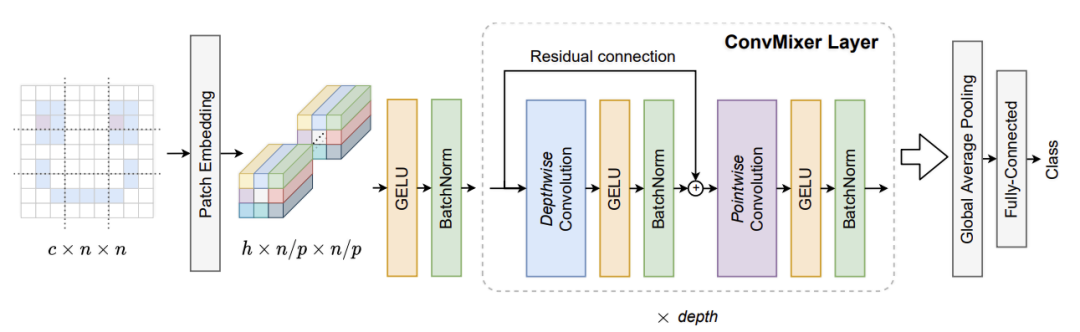
参看上图,模型 ConvMixer 是由一个 patch 嵌入层以及一个简单的全卷积块的循环所构成。patch 大小为
ConvMixer 块本身由 depthwise 卷积(即,组数等于通道数 h 的分组卷积)和 pointwise(即 kernel 大小为 1×1)卷积组成。
每个卷积之后是一个激活和 BatchNorm:
在多次应用这个块之后,执行全局池化以获得大小为
5实 验
from tensorflow.keras import layers
from tensorflow import keras
import matplotlib.pyplot as plt
import tensorflow_addons as tfa
import tensorflow as tf
import numpy as np
+超参数
learning_rate = 0.001
weight_decay = 0.0001
batch_size = 128
num_epochs = 10
为了快速看到结果,模型仅仅训练 10 个 epoch,但后面可以看到,结果还是可以的。
+加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
val_split = 0.1
val_indices = int(len(x_train) * val_split)
new_x_train, new_y_train = x_train[val_indices:], y_train[val_indices:]
x_val, y_val = x_train[:val_indices], y_train[:val_indices]
print(f"Training data samples: {len(new_x_train)}")
print(f"Validation data samples: {len(x_val)}")
print(f"Test data samples: {len(x_test)}")
Training data samples: 45000
Validation data samples: 5000
Test data samples: 10000
+数据增强
image_size = 32
auto = tf.data.AUTOTUNE
data_augmentation = keras.Sequential(
[layers.RandomCrop(image_size, image_size), layers.RandomFlip('horizontal'),],
name='data_augmentation',
)
def make_datasets(images, labels, is_train=False):
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
if is_train:
dataset = dataset.shuffle(batch_size * 10)
dataset = dataset.batch(batch_size)
if is_train:
dataset = dataset.map(
lambda x, y: (data_augmentation(x), y), num_parallel_calls=auto
)
return dataset.prefetch(auto)
train_dataset = make_datasets(new_x_train.astype(np.float32), new_y_train, is_train=True)
val_dataset = make_datasets(x_val.astype(np.float32), y_val)
test_dataset = make_datasets(x_test.astype(np.float32), y_test)
6网络实现
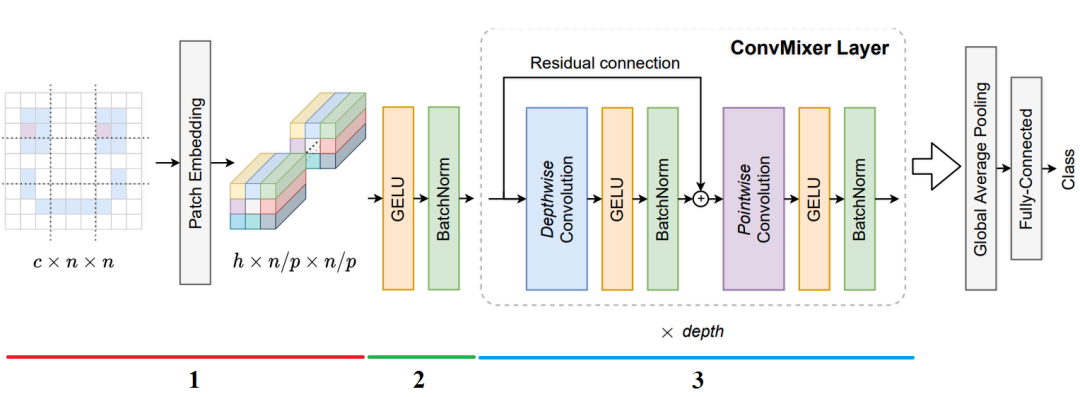
再次查看此图,我们直接根据这个流程图中的几个步骤来撸代码。
+1、计算 patch 的嵌入
块大小为
def conv_stem(x, filters: int, patch_size: int):
x = layers.Conv2D(filters, kernel_size=patch_size, strides=patch_size)(x)
return activation_block(x)
+2、ConvMixer 前的激活块
def activation_block(x):
x = layers.Activation('gelu')(x)
return layers.BatchNormalization()(x)
+3、ConvMixer 块
def conv_mixer_block(x, filters: int, kernel_size: int):
# Depthwise 卷积
x0 = x
x = layers.DepthwiseConv2D(kernel_size=kernel_size, padding='same')(x)
x = layers.Add()([activation_block(x), x0]) # 残差连接
# Pointwise 卷积
x = layers.Conv2D(filters, kernel_size=1)(x)
x = activation_block(x)
return x
+4、完整的网络
def get_conv_mixer_256_8(
image_size=32, filters=256, depth=8, kernel_size=5, patch_size=2, num_classes=10
):
"""ConvMixer-256/8: https://openreview.net/pdf?id=TVHS5Y4dNvM.
The hyperparameter values are taken from the paper.
"""
inputs = keras.Input((image_size, image_size, 3))
x = layers.Rescaling(scale=1.0 / 255)(inputs)
# 计算 patch 的嵌入
x = conv_stem(x, filters, patch_size)
# ConvMixer 块,depth 层
for _ in range(depth):
x = conv_mixer_block(x, filters, kernel_size)
# 输入分类器
x = layers.GlobalAvgPool2D()(x)
outputs = layers.Dense(num_classes, activation='softmax')(x)
return keras.Model(inputs, outputs)
本实验中使用的模型称为 ConvMixer-256/8,其中 256 表示通道数,8 表示深度。
7模型训练和评估
def run_experiment(model):
optimizer = tfa.optimizers.AdamW(
learning_rate=learning_rate, weight_decay=weight_decay
)
model.compile(
optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
checkpoint_filepath = './checkpoint'
checkpoint_callback = keras.callbacks.ModelCheckpoint(
checkpoint_filepath,
monitor='val_accuracy',
save_best_only=True,
save_weights_only=True,
)
history = model.fit(
train_dataset,
validation_data=val_dataset,
epochs=num_epochs,
callbacks=[checkpoint_callback],
)
model.load_weights(checkpoint_filepath)
_, accuracy = model.evaluate(test_dataset)
print(f'Test accuracy: {round(accuracy * 100, 2)}%')
return history, model
conv_mixer_model = get_conv_mixer_256_8()
history, conv_mixer_model = run_experiment(conv_mixer_model)
Epoch 1/10
352/352 [==============================] - 84s 150ms/step - loss: 1.2139 - accuracy: 0.5626 - val_loss: 3.4178 - val_accuracy: 0.1010
Epoch 2/10
352/352 [==============================] - 52s 147ms/step - loss: 0.7774 - accuracy: 0.7291 - val_loss: 0.8245 - val_accuracy: 0.7088
Epoch 3/10
352/352 [==============================] - 52s 147ms/step - loss: 0.5902 - accuracy: 0.7955 - val_loss: 0.5996 - val_accuracy: 0.7938
Epoch 4/10
352/352 [==============================] - 52s 147ms/step - loss: 0.4836 - accuracy: 0.8330 - val_loss: 0.5909 - val_accuracy: 0.7966
Epoch 5/10
352/352 [==============================] - 52s 147ms/step - loss: 0.4038 - accuracy: 0.8619 - val_loss: 0.5585 - val_accuracy: 0.8062
Epoch 6/10
352/352 [==============================] - 52s 147ms/step - loss: 0.3450 - accuracy: 0.8803 - val_loss: 0.5237 - val_accuracy: 0.8168
Epoch 7/10
352/352 [==============================] - 52s 147ms/step - loss: 0.3019 - accuracy: 0.8970 - val_loss: 0.5351 - val_accuracy: 0.8270
Epoch 8/10
352/352 [==============================] - 52s 148ms/step - loss: 0.2618 - accuracy: 0.9096 - val_loss: 0.5051 - val_accuracy: 0.8352
Epoch 9/10
352/352 [==============================] - 51s 146ms/step - loss: 0.2363 - accuracy: 0.9168 - val_loss: 0.5453 - val_accuracy: 0.8260
Epoch 10/10
352/352 [==============================] - 51s 146ms/step - loss: 0.2128 - accuracy: 0.9269 - val_loss: 0.5667 - val_accuracy: 0.8290
79/79 [==============================] - 3s 39ms/step - loss: 0.5329 - accuracy: 0.8271
Test accuracy: 82.71%
虽然训练集和验证集上的性能差异较大,但这点可以通过额外的正则化技术来拉近。从结果看,具有 80 万个参数的网络模型能够在 10 个 epochs 内达到 ~83% 的准确度是一个不错的结果。是不是感觉它还是值得进一步学习和研究一下的。
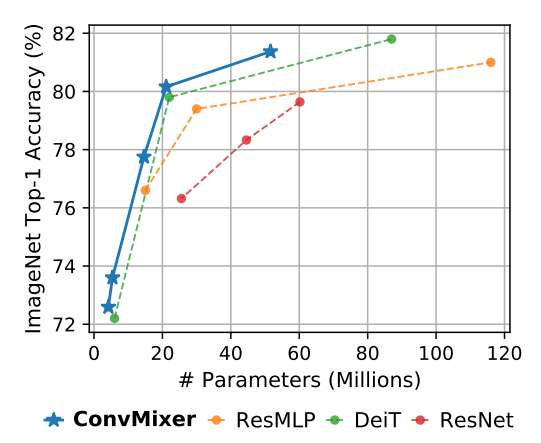
看一下论文中给出的在 ImageNet-1k 上的性能比较,
8可视化
我们可以可视化 patch 嵌入和学习到的卷积滤波器。这里,每个 patch 嵌入和中间 feature map 都具有相同数量的通道数,即 256。
def visualization_plot(weights, idx=1):
p_min, p_max = weights.min(), weights.max()
weights = (weights - p_min) / (p_max - p_min)
num_filters = 256
plt.figure(figsize=(8, 8))
for i in range(num_filters):
current_weight = weights[:, :, :, i]
if current_weight.shape[-1] == 1:
current_weight = current_weight.squeeze()
ax = plt.subplot(16, 16, idx)
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(current_weight, cmap='coolwarm')
idx += 1
# 可视化 patch 嵌入
patch_embeddings = conv_mixer_model.layers[2].get_weights()[0]
visualization_plot(patch_embeddings)

即使我们没有训练网络收敛,我们也可以注意到不同的 kernel 具有不同的模式。有些有相似之处,而有些则截然不同。这些可视化对于更大的图像尺寸将更显着。
同样,我们也可以可视化学习到的卷积核。
for i, layer in enumerate(conv_mixer_model.layers):
if isinstance(layer, layers.DepthwiseConv2D):
if layer.get_config()['kernel_size'] == (5, 5):
print(i, layer)
idx = 26 # 靠近网络中间选择一层 depthwise conv 展示
kernel = conv_mixer_model.layers[idx].get_weights()[0]
kernel = np.expand_dims(kernel.squeeze(), axis=2)
visualization_plot(kernel)
5
12
19
26
33
40
47
54

总共 256 个 filter,可以看到 kernel 中的不同 filter 具有不同的局部跨度,并且这种模式可能会随着更多的训练而演变。
9附录 - 深度可分离卷积
Separable convolution 早在 Google 的 Xception 以及 MobileNet 论文中就提出来了,这里仅供初学卷积神经网络的童鞋阅读。
它的核心思想是将一个传统卷积运算分解为两步进行,分别为 Depthwise convolution 与 Pointwise convolution。可以认为它将传统卷积从通道内与通道间两个角度分离。
+传统卷积运算
先看一个动画,感受一下传统的卷积运算。
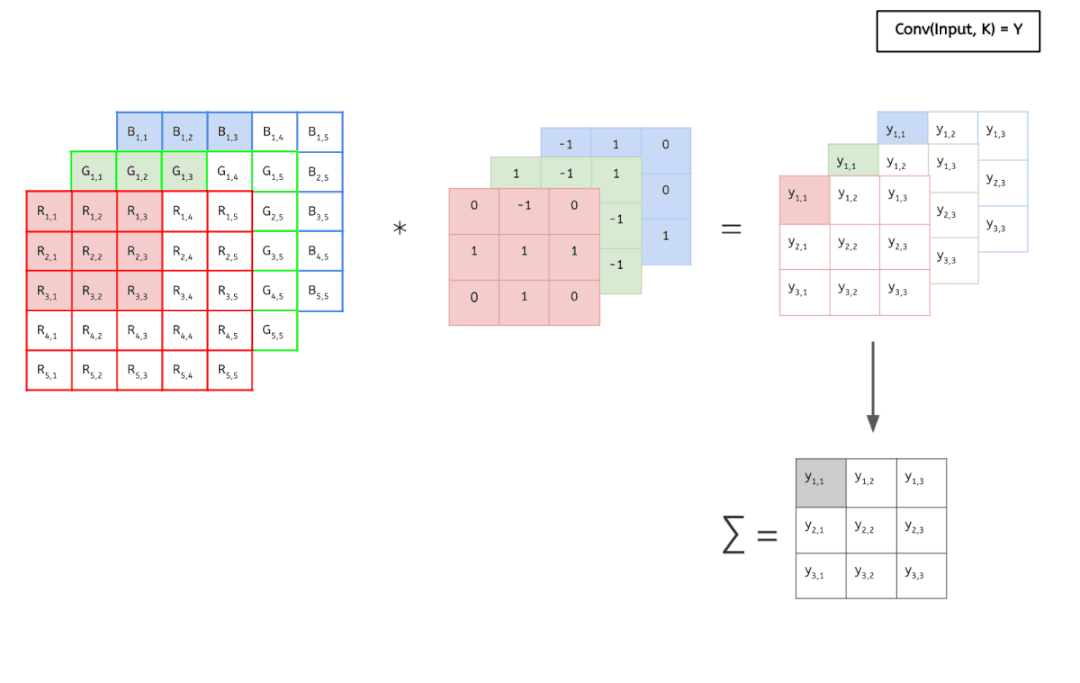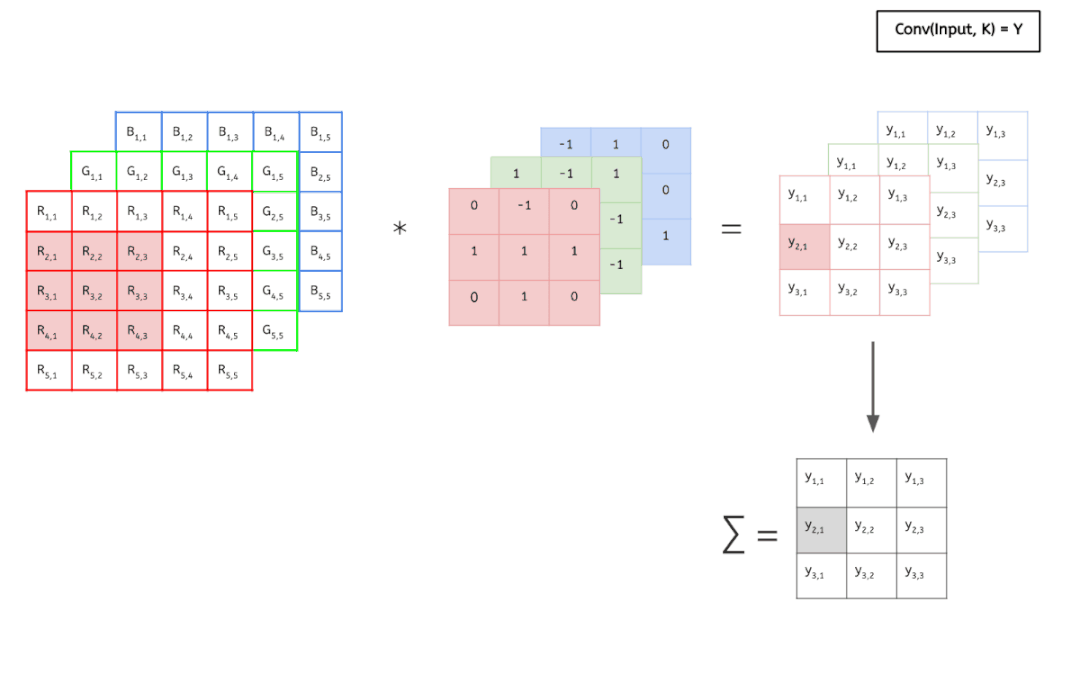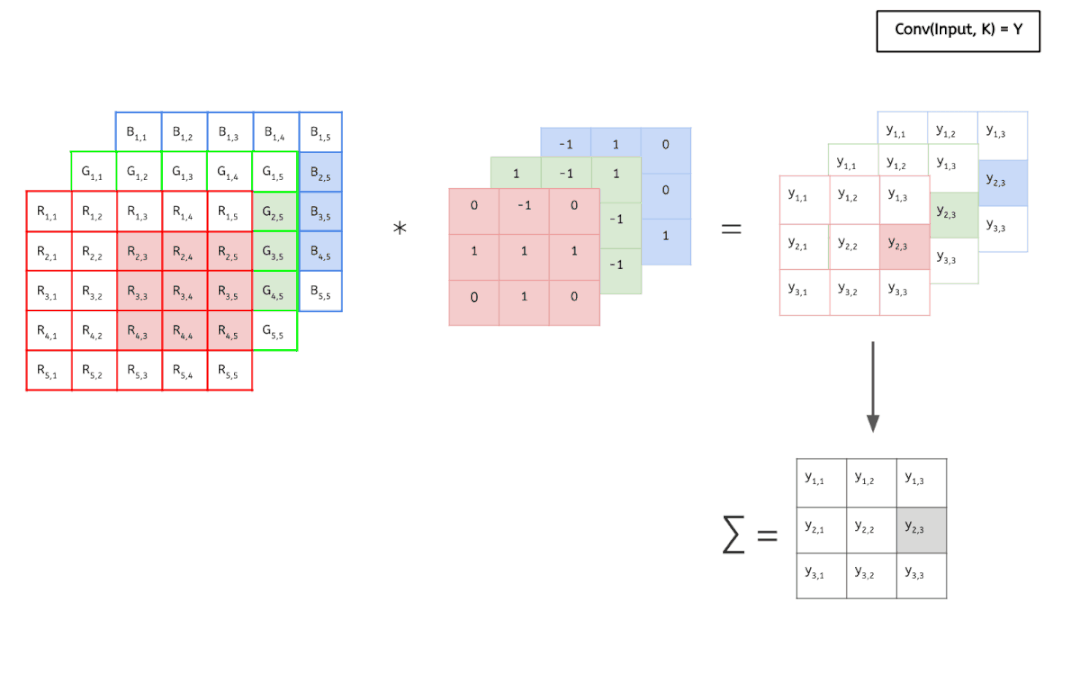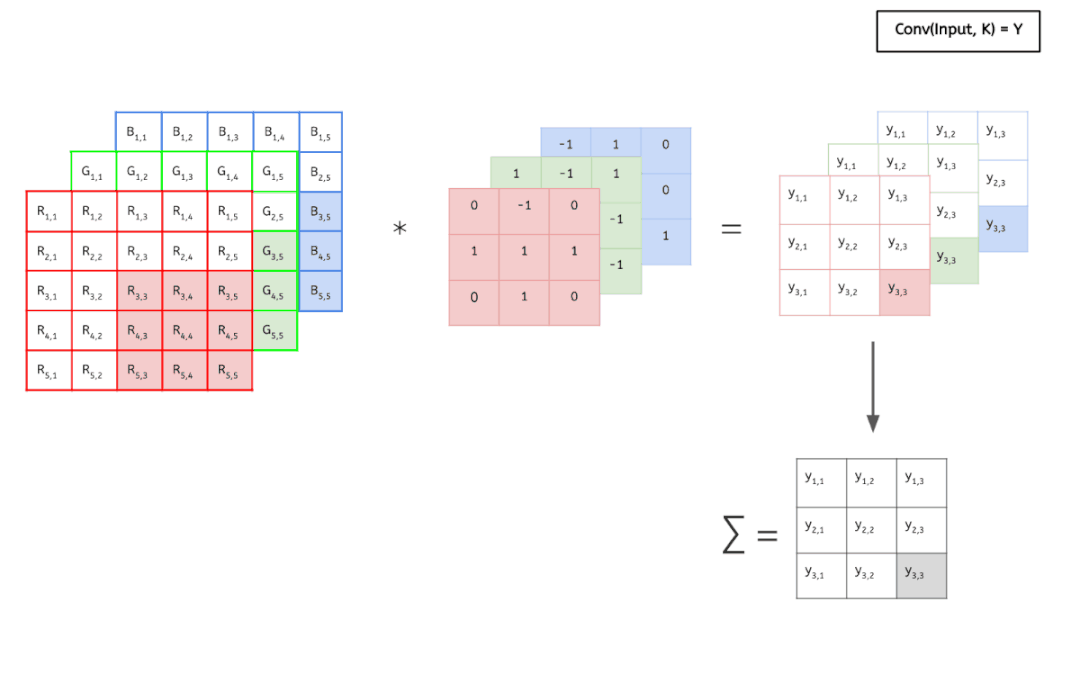
输入数据具有 3 个大小为 5 × 5 的通道,即 3 × 5 × 5,而卷积核也同样是 3 个通道,大小为 3 × 3,因此共有 3 × 3 × 3 个参数。这里只有一个卷积核,因此最终得到一张 feature map。
再来看一个有两个卷积核从而得到两张 feature map 的动画。
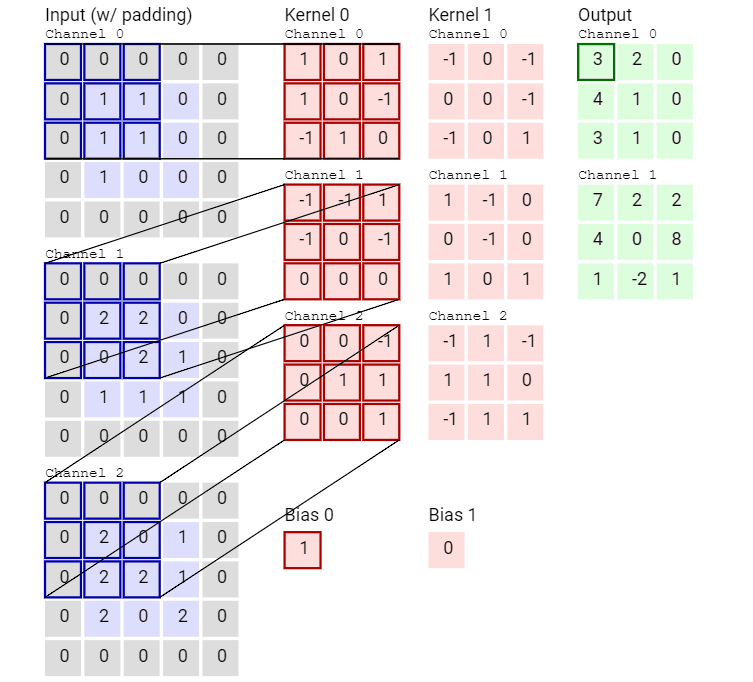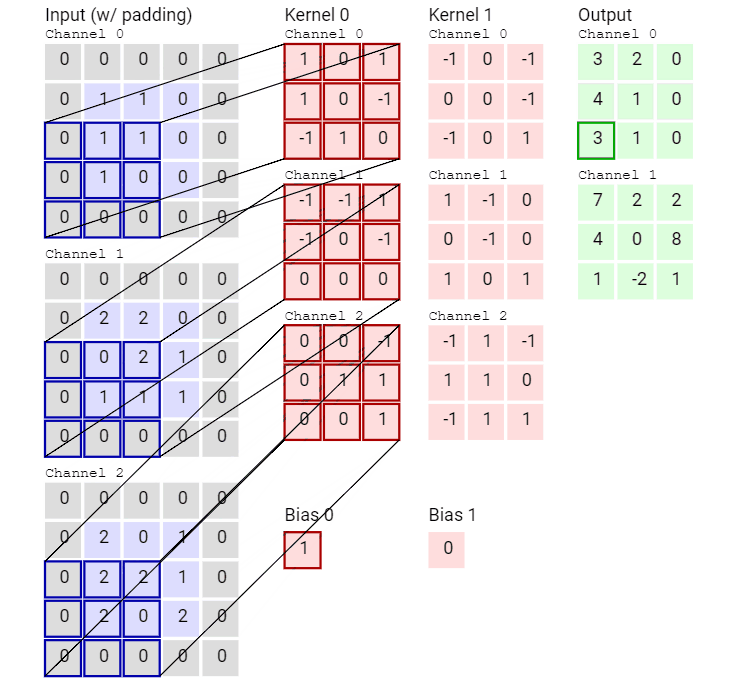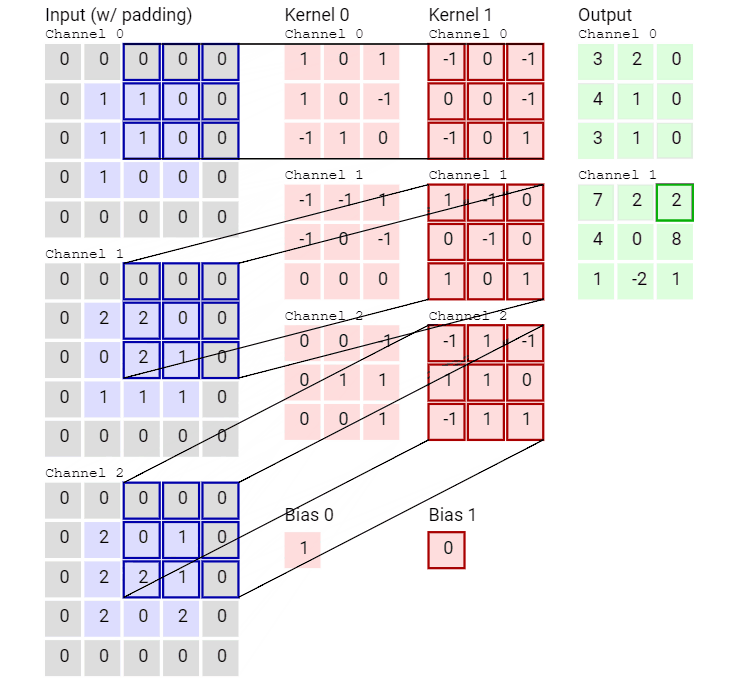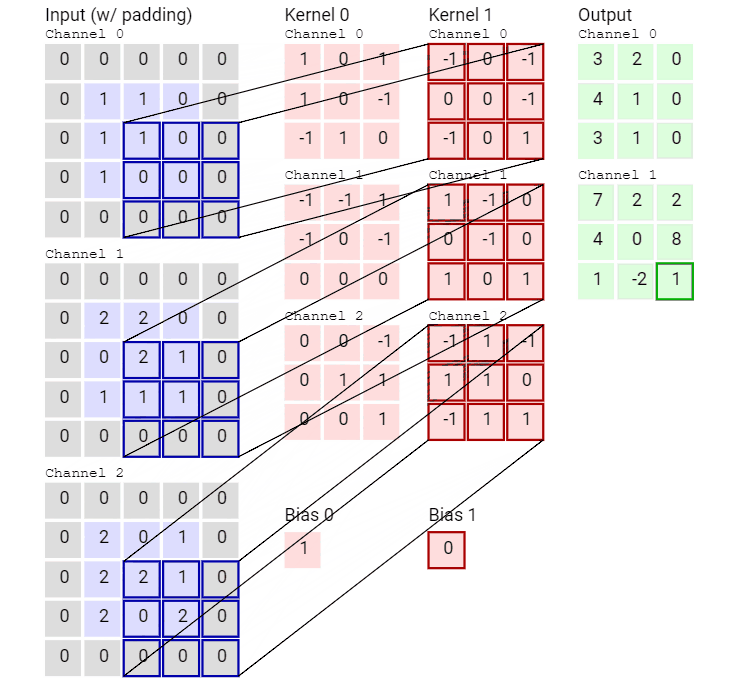
可以看到,这个卷积运算每次都涉及空间三个维度。
好了,看过动画应该就很清楚传统卷积是怎么运算的了,接下进入静态模式。
假设输入层为一个大小为 5 × 5 像素、三通道彩色图片。经过一个包含 4 个 filter 的卷积层,最终输出 4 个 feature Map。如果使用 padding='same' 来填充,则尺寸与输入层相同 5 × 5,如果没有则尺寸缩小为 3 × 3。这个过程可以用下图来可视化,
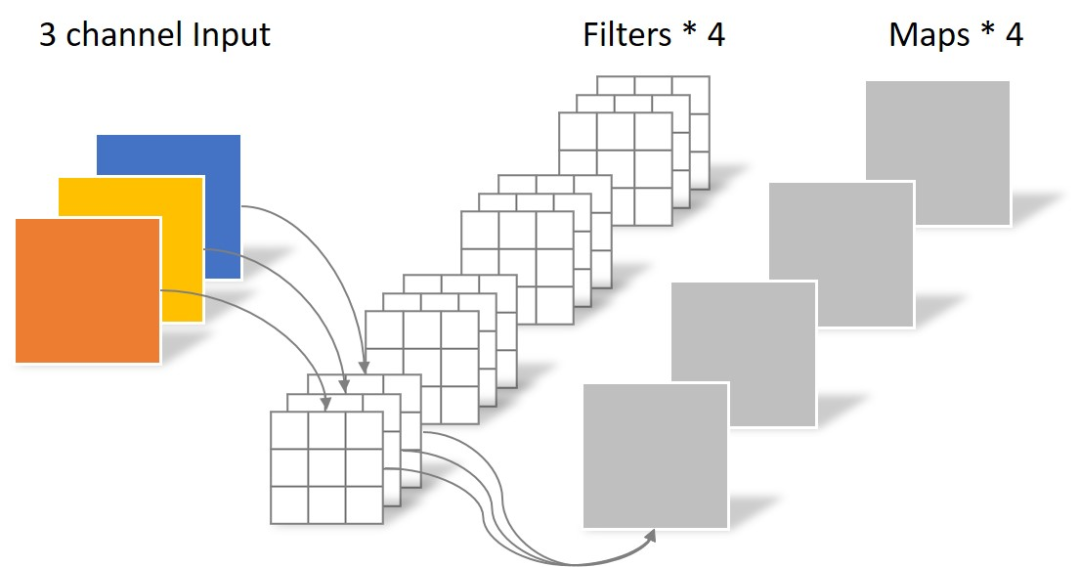
此时,卷积层共 4 个 filter,每个 filter 包含了 3 个 kernel,每个 kernel 的大小为 3 × 3。因此该卷积层的参数数量为4 × 3 × 3 × 3。
传统卷积运算的特点是将通道内和通道间同时卷积,一次性抓取特征的空间结构。
+Depthwise Convolution
还是上述例子,大小为 5 × 5 像素、三通道彩色图片首先经过第一次卷积运算,不同之处在于此次的卷积完全是在单个通道内进行,且 filter 的数量与上一层的 depth 相同。
因此,一个三通道的图像经过运算后生成了 3 个 feature map,如下图所示。
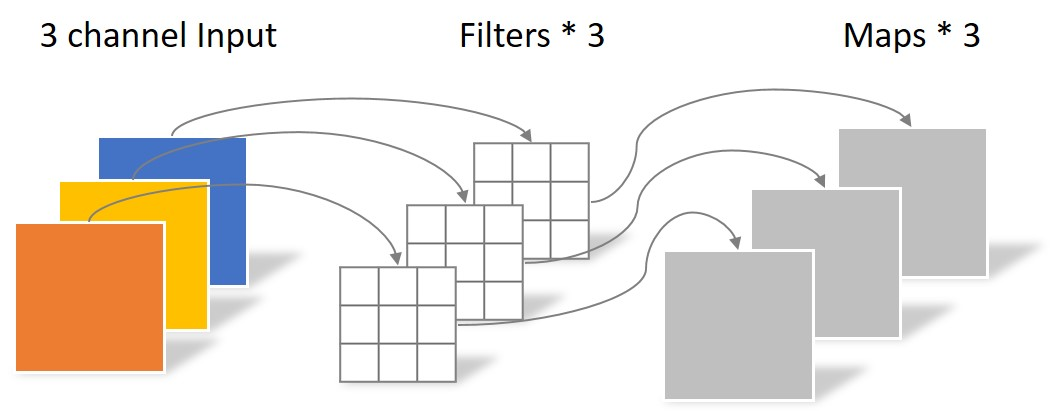
其中一个 filter 只包含一个大小为 3 × 3 的 kernel,卷积部分的参数个数为 3 × 3 × 3 。
Depthwise convolution 完成后的 feature map 数量与输入层的 depth(通道数)相同。
该卷积操作并没有利用不同通道在相同空间位置上的结构。因此还需要将这些 feature map 进行组合生成新的 feature map,即下面的 Pointwise convolution。
+Pointwise Convolution
Pointwise convolution 的卷积核尺寸为 1 × 1 × M,M 为上一层 feature map 的通道数。所以这里的卷积运算会将上一步的 map 在不同通道间进行加权,生成新的 feature map。
有几个 filter 就有几个 feature map,如下图所示,
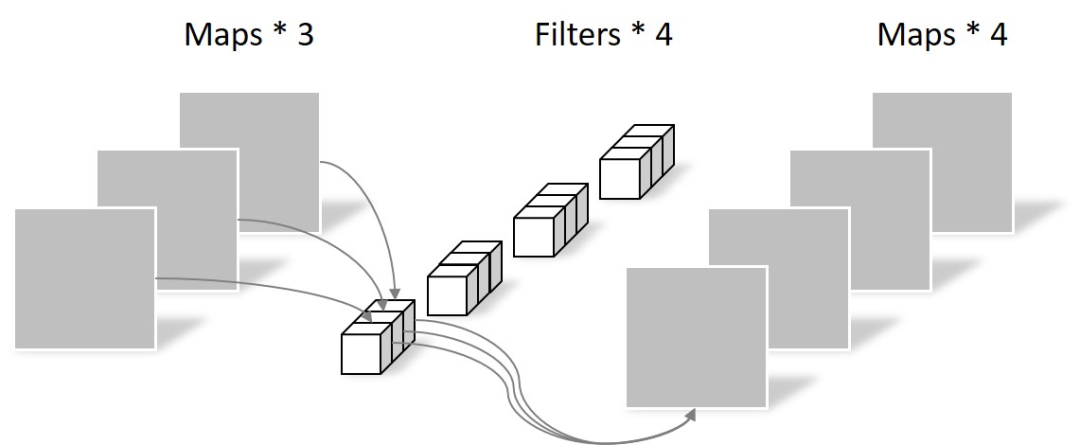
由于采用的是 1×1 卷积的方式,此步中卷积涉及到的参数个数为 1 × 1 × 3 × 4。
经过 Pointwise convolution 之后,同样输出了 4 张 feature map,与传统卷积的输出维度相同。
我们把上面两种卷积放在一张图里,
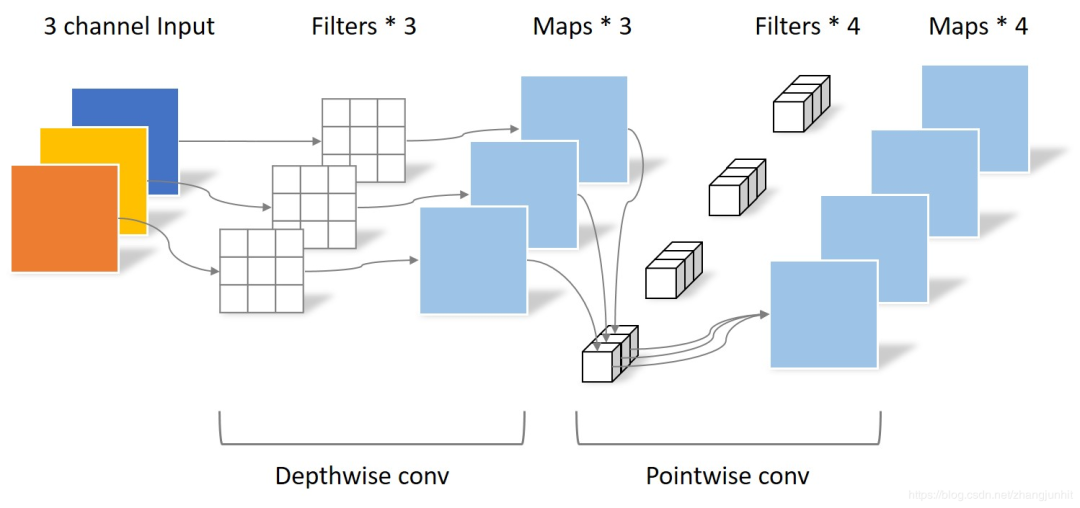
+参数对比
回顾一下,传统卷积的参数个数为 4 × 3 × 3 × 3;而 Separable convolution 的参数个数为 3 × 3 × 3 + 1 × 1 × 3 × 4。
输入相同,输出也是 4 张 feature map,而 Separable convolution 的参数个数大大少于常规卷积。因此,假设参数量相同,那么采用 Separable convolution 的神经网络可以具有更深的层次。
这里通过一个简单例子介绍了 Depthwise 和 Pointwise 两个卷积运算以及与传统卷积运算的关系。如果之前对这些概念不了解的童鞋可以再回过头去看 ConvMixer 了。