
CVPR2020 | PV-RCNN: 3D目标检测
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
本文转载自知乎,仅用于学术分享。如有侵权,请联系删除。原文链接:
https://zhuanlan.zhihu.com/p/148942116
本文简单介绍一下我们关于点云3D物体检测方向的最新算法:PV-RCNN (Point-Voxel Feature Set Abstraction for 3D Object Detection)。
我们的算法在仅使用LiDAR传感器的setting下,在自动驾驶领域Waymo Open Challenge点云挑战赛中取得了(所有不限传感器算法榜单)三项亚军、Lidar单模态算法三项第一的成绩,以及在KITTI Benchmark上保持总榜第一的成绩超过半年。
(顺带聊一下我对现在LiDAR点云3D检测方向的一些看法)
论文链接 (代码链接在最后):https://arxiv.org/abs/1912.13192

我们先看看PV-RCNN 3D检测框架的性能如何。说到底,做high-level的,大多数还得硬碰硬 (不然难免故事吹的天花乱坠,一跑AP只有0.5。。
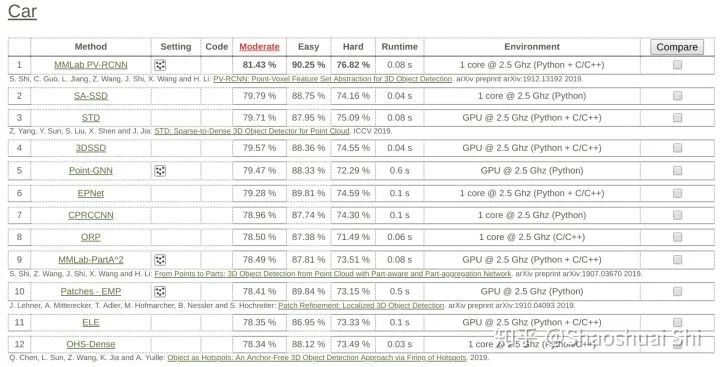
1. 到目前为止,3D检测算法上竞争最激烈的莫过于KITTI榜单了(近两年每次DDL都能涌现很多新方法。。
我们是去年11月提交的PV-RCNN结果,大幅领先之前的SoTA算法,且保持第一大半年一直到现在(最近出现很多新方法,估计也该被别人挤下去了。。
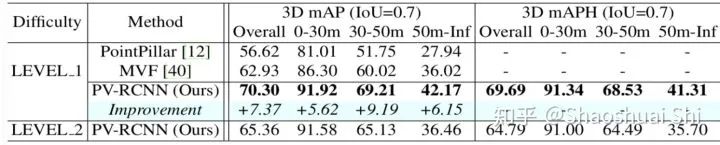
2. 除了KITTI以外,自动驾驶业界巨头Waymo也在去年release了超大的点云数据集Waymo Open Dataset。据我们所知,除了Waymo/Google以外,我们应该是最早在Waymo数据集训练+测试的论文(之一),同样大幅领先了Waymo论文的算法:
3. 此外,Waymo还于CVPR2020举办了点云3D物体检测等比赛,因为我们刚好有去年投稿PV-RCNN时准备的各种现成Waymo代码(以及觊觎其丰厚的奖金233),所以就直接跑了一下。由于实验室机器有限,我们并没有太多资源(与时间)投入到比赛中,我们提交的方法基本就是裸的论文原版PV-RCNN+一些简单trick,在仅使用LiDAR点云作为输入的情况下,我们最终取得了3D Detection、3D Tracking、Domain Adaptation三项比赛中单模态算法三项第一,所有(不限传感器)算法三项第二。
在KITTI/Waymo上的出色性能,证明了我们PV-RCNN 3D检测框架的有效性,接下来简单介绍一些我们是怎么做的,以及为什么要这么做。
点云数据的稀疏性与不规则性,以及如何从点云数据中提取特征
众所周知,相比图像,点云数据的不规则性和稀疏性需要我们设计更特殊的网络结构去点云中提取特征。我们一般采用下面两种方式提取点云特征,一个是PointNet++[1]中提出的point-based Set Abstraction (以及各种魔改版本SA),另一个是转化为规则voxel以后的voxel-based Sparse Convolution [2]。
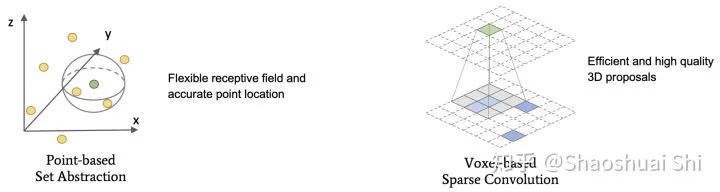
这两种方式各有各的优点:
(1) SA在原始点云上做,保留了准确的位置信息,且通过自定义球的半径使得感受野更为灵活。
(2) Sparse conv在voxel上做,速度往往更快,并且在自动驾驶场景下结合anchor可以产生更高质量的3D Proposal (室内场景一般来讲通过PointRCNN[3]中提出的anchor-free策略提Proposal更为高效且直观)。
为了综合利用上面两种特征提取操作各自的优势,我们就在考虑怎么能将这两种点云特征提取算法深度结合到一个网络中,提升网络的结构多样性以及表征能力。从另一个方面讲,我们之前一直专注于二阶段的高性能3D网络检测框架(PointRCNN[3], PartA2-Net[4]),经验告诉我们,在point上进行3D RoI pooling比BEV map上效果更好(保留更精细的特征)。所以,怎么得到表征能力更强的point-wise特征,也是我们需要做的。
因此,我们接着考虑,怎么能将整个场景编码到少量的keypoint上,用这些point-wise的keypoint特征来做第二阶段的RoIPooling,也就是将其作为桥梁,来连接检测框架的两个阶段。
然后我们就自然而然的关注到了Set Abstraction这个操作上了。在Set Abstraction的原本设计中,球中心的点是从整个点云中采样出来的,其与周围的点同宗同源,中心点的特征即通过球内周围点的特征聚合而来。然而,我们发现,其实球中心点无需与周围的点同宗同源,球中心点是可以任意给定的。所以,Set Abstraction本身就可以作为一个很好的操作,来结合上面两种点云特征提取操作(球中心与周围点可以分别来自于point与voxel)。
有了上面的思路,还需要一些具体实现的设计。简单来讲:
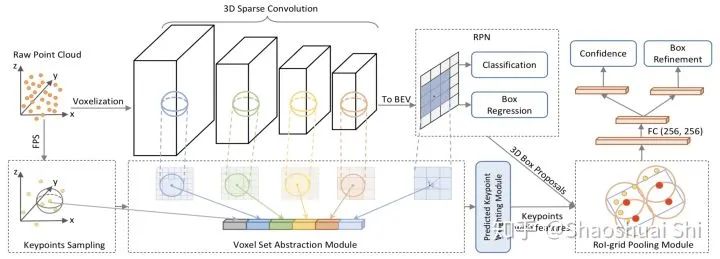
(1) 我们提出了Voxel Set Abstraction操作,将Sparse Convolution主干网络中多个scale的sparse voxel及其特征投影回原始3D空间,然后将少量的keypoint (从点云中sample而来) 作为球中心,在每个scale上去聚合周围的voxel-wise的特征。这个过程实际上结合了point-based和voxel-based两种点云特征提取的结构,同时将整个场景的multi-scale的信息聚合到了少量的关键点特征中,以便下一步的RoI-pooling。
(2) 我们提出了Predicted Keypoint Weighting模块,通过从3D标注框中获取的免费点云分割标注,来更加凸显前景关键点的特征,削弱背景关键点的特征。
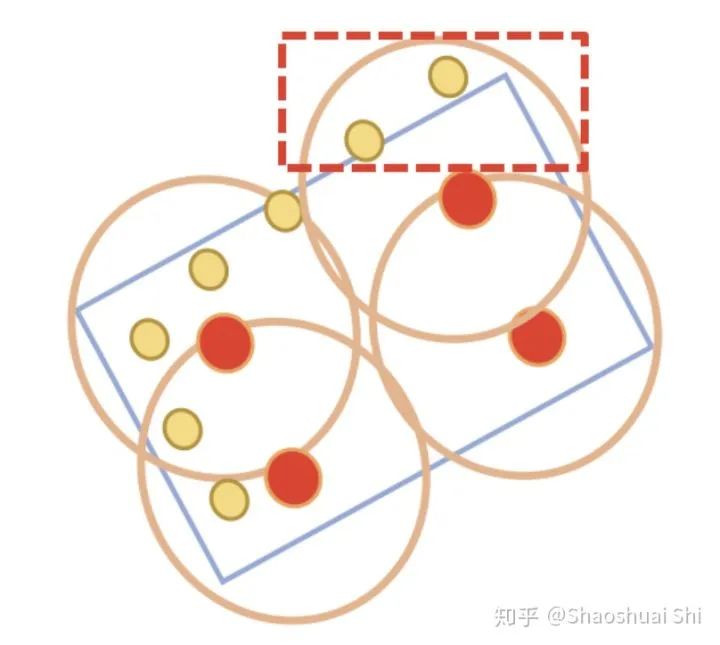
(3) 进一步,我们设计了更强的点云3D RoI Pooling操作,也就是我们提出的RoI-grid Pooling: 与前面不同,这次我们在每个RoI里面均匀的sample一些grid point,然后将grid point当做球中心,去聚合周围的keypoint的特征。这样做的好处有两个:
(1) 球半径灵活,甚至可以包括proposal框外围的关键点,从而获取更多有效特征。
(2) 球互相覆盖,每个keypoint可以被多个grid point使用,从而得到更紧密的RoI特征表达。另一方面,这其实也是另一个point (keypoint)与voxel (grid point)特征交互的过程。
通过Voxel-to-keypoint与keypoint-to-grid这两个point-voxel特征交互的过程,显著增强了PV-RCNN的结构多样性,使其可以从点云数据中学习更多样性的特征,来提升最终的3D检测性能。
前段时间我们release了一个通用3D检测代码库,PCDet:https://github.com/sshaoshuai/PCDet
最近我们正在重新整理PCDet代码库,方便更好的进行排列组合,同时包含更多的model与dataset。我们的PV-RCNN代码也将于近期整合到PCDet中,敬请关注。
最后简单聊一下我觉得点云3D检测还有哪些方向可以试一下。随着越来越多优秀的人涌入做基于点云的3D物体检测,以及越来越多的开源codebase和数据集(KITTI, NuScenes, Waymo等),3D物体检测的性能在短短两三年间已经被提升了好几个档次。
从目前的情况来看,由于多sensor的同步等问题,纯LiDAR的3D检测算法受到追捧,且达到了媲美多sensor甚至更强的性能。但我们都知道点云3D物体检测算法最大的应用场景就是自动驾驶,其对可靠性要求很高。而LiDAR捕获的点云场景包含更多的几何信息,其语义信息远不如图像,这使得纯LiDAR感知算法经常出现奇怪的误检,且由于点云的稀疏性导致纯LiDAR检测器能识别的类别有限。所以多模态的LiDAR+RGB结合的检测算法从长远来看还是有很大的发展空间的。
而大部分人之所以醉心于纯LiDAR 3D物体检测,是因为基于LiDAR+RGB的3D物体检测算法面临一些问题:
(1) 比如LiDAR点云和RGB图像是来自于不同view的场景表征,如何融合两者的特征?融合了特征又如何做检测?之前也有一些方法探索了这个问题,但还没看到比较优雅的解决方案。
(2) 另一个问题是纯LiDAR的3D物体感知可以做各种各样的数据增强,比如将一个场景中的GT "copy"到另一个场景。而如果结合RGB图像,"copy"的GT在RGB图像上的特征如何处理,也是一个难解的问题。
另一方面,随着Waymo等大规模的点云数据集的发布(Waymo Open Dataset的每个scene的检测范围已经比最早的KITTI大了近4倍),以及自动驾驶车上的时延需求,我们期待出现更高效的3D物体检测框架。同时随着LiDAR传感器的发展,如何更高效的检测更大范围的点云场景(更密的点+更大的范围),也是一个值得探索的方向。
本文仅做学术分享,如有侵权,请联系删文。