
MEA:视觉无监督训练新范式
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近日,FAIR的最新论文Masked Autoencoders Are Scalable Vision Learners(何恺明一作)提出了一种更简单有效的用于ViT无监督训练的方法MAE,并在ImageNet-1K数据集上的top-1 acc达到新的SOTA:87.8%(无额外训练数据)。自从ViT火了之后,一些研究者就开始尝试研究ViT的无监督学习,比如Mocov3用对比学习的方法无监督训练ViT,此外也有一些研究开始借鉴BERT中的MLM(masked language modeling)方法,比如BEiT提出了用于图像的无监督学习方法:MIM(masked image modeling)。无疑,MAE方法也落在MIM的范畴,但整个论文会给人更震撼之感,因为MEA方法更简单有效。
NLP领域的BERT提出的预训练方法本质上也是一种masked autoencoding:去除数据的一部分然后学习恢复。这种masked autoencoding方法也很早就在图像领域应用,比如Stacked Denoising Autoencoders。但是NLP领域已经在BERT之后采用这种方法在无监督学习上取得非常大的进展,比如目前已经可以训练超过1000亿参数的大模型,但是图像领域却远远落后,而且目前主流的无监督训练还是对比学习。那么究竟是什么造成了masked autoencoding方法在NLP和CV上的差异呢?MEA论文从三个方面做了分析,这也是MEA方法的立意:
图像的主流模型是CNN,而NLP的主流模型是transformer,CNN和transformer的架构不同导致NLP的BERT很难直接迁移到CV。但是vision transformer的出现已经解决这个问题; 图像和文本的信息密度不同,文本是高语义的人工创造的符号,而图像是一种自然信号,两者采用masked autoencoding建模任务难度就不一样,从句子中预测丢失的词本身就是一种复杂的语言理解任务,但是图像存在很大的信息冗余,一个丢失的图像块很容易利用周边的图像区域进行恢复; 用于重建的decoder在图像和文本任务发挥的角色有区别,从句子中预测单词属于高语义任务,encoder和decoder的gap小,所以BERT的decoder部分微不足道(只需要一个MLP),而对图像重建像素属于低语义任务(相比图像分类),encoder需要发挥更大作用:将高语义的中间表征恢复成低语义的像素值。
基于这三个的分析,论文提出了一种用于图像领域(ViT模型)的更简单有效的无监督训练方法:MAE(masked autoencoder),随机mask掉部分patchs然后进行重建,其整体架构如下所示。MAE采用encoder-decoder结构(分析3,需要单独的decoder),但属于非对称结构,一方面decoder采用比encoder更轻量级设计,另外一方面encoder只处理一部分patchs(visible patchs,除了masked patchs之外的patchs),而encoder处理所有的patchs。一个很重要的点,MEA采用很高的masking ratio(比如75%甚至更高),这契合分析2,这样构建的学习任务大大降低了信息冗余,也使得encoder能学习到更高级的特征。由于encoder只处理visible patchs,所以很高的masking ratio可以大大降低计算量。
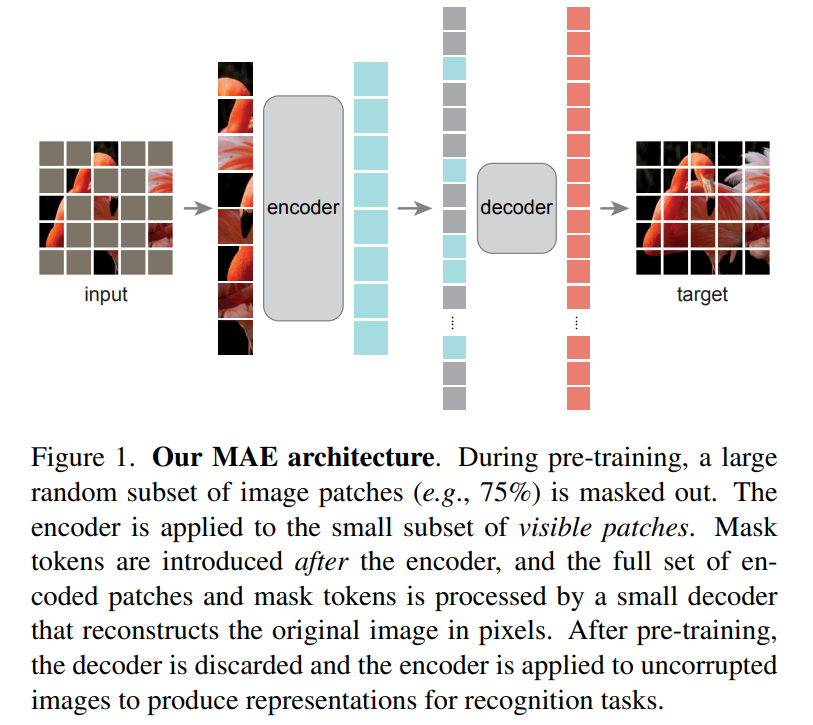
MEA采用的masking策略是简单的随机mask:基于均匀分布从图像的patchs随机抽样一部分patchs进行mask。每个被mask的patch采用mask token来替代,mask token是一个共享且可学习的向量。MEA的encoder采用ViT模型,只处理visible patchs,visible patchs通过linear projection得到patch embedding输入到ViT的transformer blocks进行处理;而decoder是一个轻量级模块,主体包含几个transformer blocks,而最后一层是一个linear层(输出是和一个patch像素数一致),用来直接预测masked patch的像素值。decoder的输入是所有的tokens:encoded visible patchs和mask tokens,它们要加上对应的positional embeddings。训练的loss采用简单的MSE:计算预测像素值和原始像素值的均方误差,不过loss只计算masked patchs。MEA的实现非常简单:首先对输入的patch进行linear projection得到patch embeddings,并加上positional embeddings(采用sine-cosine版本);然后对tokens列表进行random shuffle,根据masking ratio去掉列表中后面的一部分tokens,然后送入encoder中,这里注意ViT中需要一个class token来做图像分类,所以这里的输入也要增加一个dummy token(如果最后分类采用global avg pooling就不需要这个);encoder处理后,在tokens列表后面补足mask tokens,然后通过unshuffle来恢复tokens列表中tokens的原始位置,然后再加上positional embeddings(mask tokens本身并无位置信息,所以还要此操作)送入decoder中进行处理。
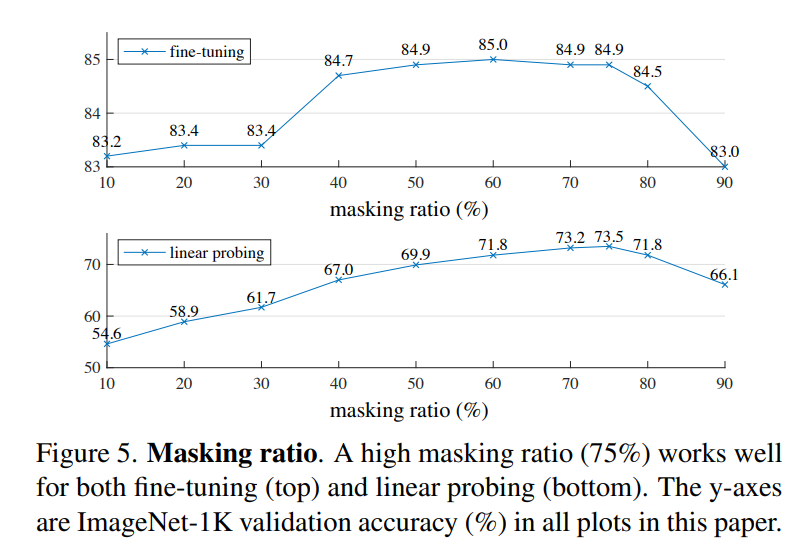
论文选择ViT-Large(ViT-L/16)作为encoder在ImageNet-1K上实验,首先进行无监督预训练,然后进行监督训练以评估encoder的表征能力,包括常用linear probing和finetune两个实验结果。下表是baseline MEA方法的实验结果,可以看到经过MEA预训练后finetune的效果要超过直接从头训练(84.9 vs 82.5):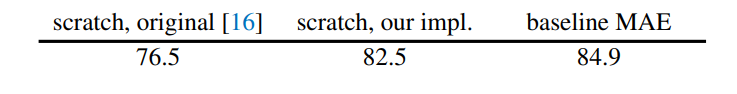 更重要的是,论文做了MEA各个部分的不同设置对比实验,这些实验能够揭示MEA更多的特性。首先是masking ratio,从下图可以看到,最优的设置是75%的masking ratio,此时linear probing和finetune效果最好,这比之前的研究要高很多,比如BEiT的masking ratio是40%。另外也可以看到linear probing和finetune的表现不一样,linear probing效果随着masking ratio的增加逐渐提高直至一个峰值后出现下降,而finetune效果在不同making ratio下差异小,masking ratio在40%~80%范围内均能表现较好。
更重要的是,论文做了MEA各个部分的不同设置对比实验,这些实验能够揭示MEA更多的特性。首先是masking ratio,从下图可以看到,最优的设置是75%的masking ratio,此时linear probing和finetune效果最好,这比之前的研究要高很多,比如BEiT的masking ratio是40%。另外也可以看到linear probing和finetune的表现不一样,linear probing效果随着masking ratio的增加逐渐提高直至一个峰值后出现下降,而finetune效果在不同making ratio下差异小,masking ratio在40%~80%范围内均能表现较好。
 这么高的masking ratio,模型到底能学习到什么?这里采用预训练好的模型在验证集进行重建,效果如下所示,可以看到decoder重建出来的图像还是比较让人惊艳的(95%的masking ratio竟然也能work!),这或许说明模型已经学习到比较好的特征。
这么高的masking ratio,模型到底能学习到什么?这里采用预训练好的模型在验证集进行重建,效果如下所示,可以看到decoder重建出来的图像还是比较让人惊艳的(95%的masking ratio竟然也能work!),这或许说明模型已经学习到比较好的特征。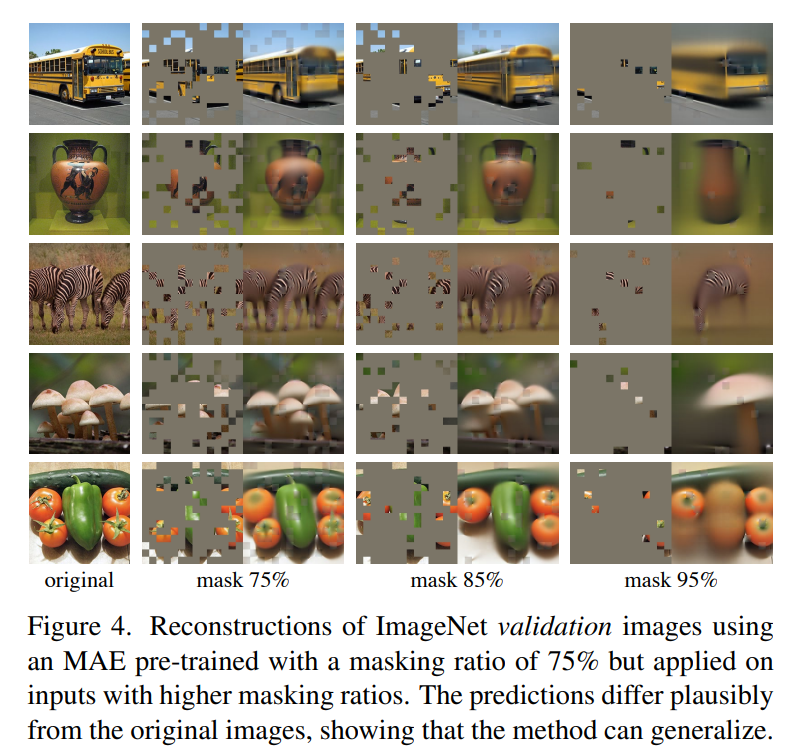 第二个是encoder的设计,这里主要探讨decoder的深度(transformer blocks数量)和宽度(channels数量)对效果的影响,实验结果如下表所示。首先,要想得到比较好的linear probing效果,就需要一个比较深的decoder,这不难理解,前面说过重建图像和图像识别两个任务的gap较大,如果decoder比较深,那么decoder就有足够的容量学习到重建能力,这样encoder可以更专注于提取特征。但是不同的深度对finetune效果影响较小,只用一个transformer block就可以work。相比之下,网络宽度对linear probing影响比网络深度要小一点。论文选择的默认设置是:8个blocks,width为512,一个token的FLOPs只有encoder的9%。
第二个是encoder的设计,这里主要探讨decoder的深度(transformer blocks数量)和宽度(channels数量)对效果的影响,实验结果如下表所示。首先,要想得到比较好的linear probing效果,就需要一个比较深的decoder,这不难理解,前面说过重建图像和图像识别两个任务的gap较大,如果decoder比较深,那么decoder就有足够的容量学习到重建能力,这样encoder可以更专注于提取特征。但是不同的深度对finetune效果影响较小,只用一个transformer block就可以work。相比之下,网络宽度对linear probing影响比网络深度要小一点。论文选择的默认设置是:8个blocks,width为512,一个token的FLOPs只有encoder的9%。 第三个是mask token,这里探讨的是encoder是否处理mask tokens带来的影响,从对比实验来看,encoder不处理mask tokens不仅效果更好而且训练更高效,首先linear probing的效果差异非常大,如果encoder也处理mask tokens,此时linear probing的效果较差,这主要是训练和测试的不一致带来的,因为测试时都是正常的图像,但经过finetune后也能得到较好的效果。最重要的是,不处理mask tokens模型的FLOPs大大降低(3.3x),而且训练也能加速2.8倍,这里也可以看到采用较小的decoder可以进一步加速训练。
第三个是mask token,这里探讨的是encoder是否处理mask tokens带来的影响,从对比实验来看,encoder不处理mask tokens不仅效果更好而且训练更高效,首先linear probing的效果差异非常大,如果encoder也处理mask tokens,此时linear probing的效果较差,这主要是训练和测试的不一致带来的,因为测试时都是正常的图像,但经过finetune后也能得到较好的效果。最重要的是,不处理mask tokens模型的FLOPs大大降低(3.3x),而且训练也能加速2.8倍,这里也可以看到采用较小的decoder可以进一步加速训练。
第四个是探讨不同的重建目标对效果的影响,从对比实验看,如果对像素值做归一化处理(用patch所有像素点的mean和std),效果有一定提升,采用PCA处理效果无提升。这里也实验了BEiT采用的dVAE tokenizer,此时训练loss是交叉熵,从效果上看比baseline有一定提升(finetune有提升,但是linear probing下降),但不如归一化处理的结果。注意的是dVAE tokenizer需要非常大的数据来单独训练,这是非常不方便的。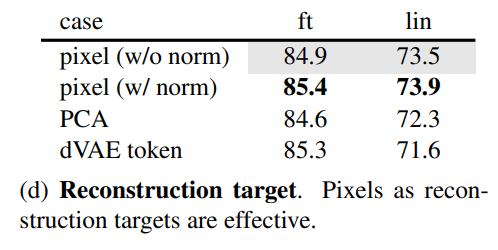 第五个是数据增强的影响,这里让人惊奇的是MEA在无数据增强下(center crop)依然可以表现出好的效果,如果采用random crop(固定size或随机size)+random horizontal flipping(其实也属于轻量级)效果有微弱的提升,但加上color jit效果反而有所下降。相比之下,对比学习往往需要非常heavy的数据增强。这差异的背后主要是因为MEA采用的random mask patch已经起到了数据增强的效果。
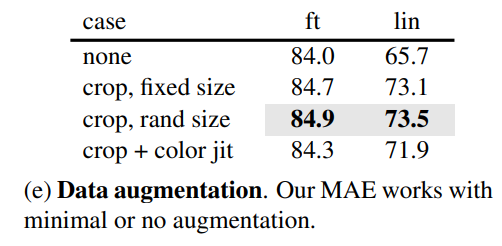
第五个是数据增强的影响,这里让人惊奇的是MEA在无数据增强下(center crop)依然可以表现出好的效果,如果采用random crop(固定size或随机size)+random horizontal flipping(其实也属于轻量级)效果有微弱的提升,但加上color jit效果反而有所下降。相比之下,对比学习往往需要非常heavy的数据增强。这差异的背后主要是因为MEA采用的random mask patch已经起到了数据增强的效果。
 第六个是mask sampling策略的影响,相比BEiT采用的block-wise或grid-wise方式,random sampling效果最好。
第六个是mask sampling策略的影响,相比BEiT采用的block-wise或grid-wise方式,random sampling效果最好。
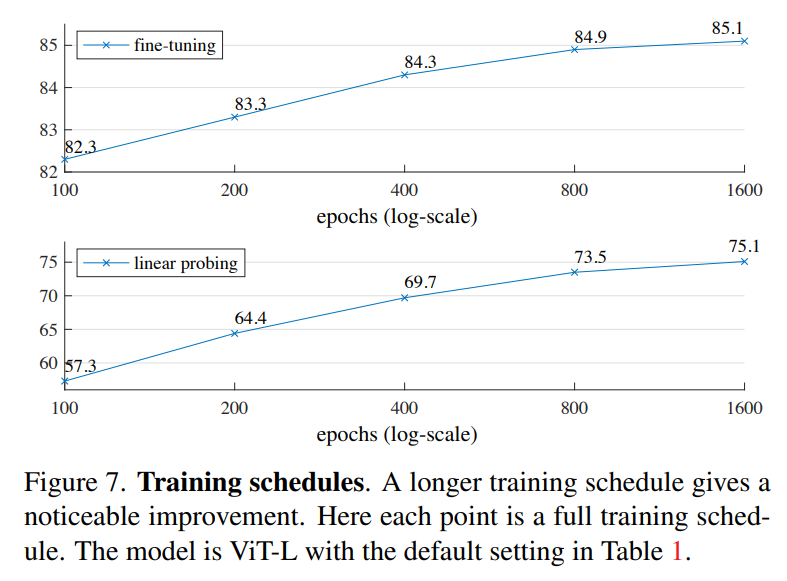
另外,论文也发现MEA和对比学习方法在training schedule上也存在差异,之前的实验都是基于800 epoch的训练时长,而实验发现训练到更长的epoch(1600 epoch+),模型的linear probing性能依然还在上升,而MoCoV3在300 epoch后就饱和了。不过,MEA在75%的masking ratio下每个epoch其实只相当于见了25%的数据,而对比学习往往学习two-crop和multi-crop,每个epoch见到的数据在200%以上,这也意味着MEA可以训练更多的epoch。虽然MEA训练更长,但是由于其特殊的设置,基于ViT-L的MEA训练1600 epoch的时长比MoCoV3训练300 epoch还要短(31h vs 36h)。
MEA与其它无监督方法的对比如下所示,可以看到在同样条件下MEA要比BEiT更好,而且也超过有监督训练,其中ViT-H在448大小finetune后在ImageNet上达到了87.8%的top1 acc。不过MEA的效果还是比谷歌采用JFT300M训练的ViT要差一些,这说明训练数据量可能是一个瓶颈。 同时,论文也对比了MEA训练的encoder在下游任务(检测和分割)的迁移能力,同等条件下,MEA均能超过有监督训练或者其它无监督训练方法:
同时,论文也对比了MEA训练的encoder在下游任务(检测和分割)的迁移能力,同等条件下,MEA均能超过有监督训练或者其它无监督训练方法:
论文最后还有一个额外的部分,那就是对linear probing评估方式的讨论。从前面的实验我们看到,虽然MEA训练的encoder在finetune下能取得比较SOTA的结果,但是其linear probing和finetune效果存在不小的差异,单从linear probing效果来看,MEA并不比MoCoV3要好(ViT-L:73.5 vs 77.6)。虽然linear probing一直是无监督训练的最常用的评估方法,但是它追求的是encoder提取特征的线性可分能力,这不并能成为唯一的一个评价指标,而且linear probing也不能很好地和下游任务迁移能力关联起来。所以论文额外做了partial fine-tuning的实验,这里可以看到如果仅对encoder的最后一个block进行finetune的话,MAE就能达到和MoCoV3一样的效果,如果finetune更多的blocks,MAE就会超过MoCoV3。这说明虽然MAE得到的特征线性可分能力差了点,但是它其实是更强的非线性特征。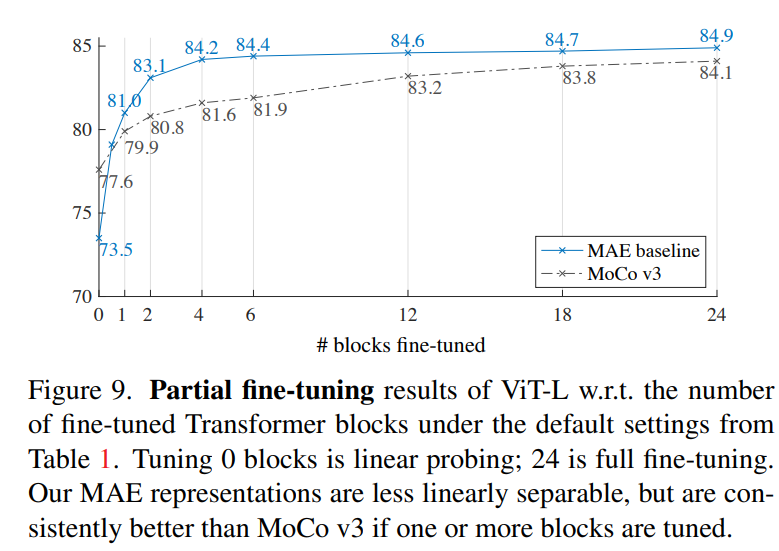
最后谈一点自己对MEA的认识:首先MEA并不是第一个基于MIM方法做无监督训练,之前微软的BEiT基于MIM也取得了很好的效果,还有MST和iBOT等工作。但是MEA让人看起来更简单有效,比如BEiT需要单独训练的tokenizer,而其它的一些工作往往引入了对比学习的类似设计。对于MEA的成功,我觉得是一些突破常规的设计,比如很高的masking ratio,这是很难想象会work的,但MEA却证明了这是成功的关键。
参考
Mocov3: An Empirical Study of Training Self-Supervised Vision Transformers DINO: Emerging Properties in Self-Supervised Vision Transformers MST: Masked Self-Supervised Transformer for Visual Representation BEiT: BERT Pre-Training of Image Transformers EsViT: Efficient Self-supervised Vision Transformers for Representation Learning Image BERT Pre-training with Online Tokenizer Masked Autoencoders Are Scalable Vision Learners
推荐阅读
PyTorch1.10发布:ZeroRedundancyOptimizer和Join
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
