
面试题:详细说说协同过滤的原理
七月在线实验室
共 4607字,需浏览 10分钟
·
2021-01-11 10:34
文 | 七月在线
编 | 小七
解析:
1 推荐引擎的分类
推荐引擎根据不同依据如下分类:
根据其是不是为不同的用户推荐不同的数据,分为基于大众行为(网站管理员自行推荐,或者基于系统所有用户的反馈统计计算出的当下比较流行的物品)、及个性化推荐引擎(帮你找志同道合,趣味相投的朋友,然后在此基础上实行推荐);
根据其数据源,分为基于人口统计学的(用户年龄或性别相同判定为相似用户)、基于内容的(物品具有相同关键词和Tag,没有考虑人为因素),以及基于协同过滤的推荐(发现物品,内容或用户的相关性推荐,分为三个子类,下文阐述);
根据其建立方式,分为基于物品和用户本身的(用户-物品二维矩阵描述用户喜好,聚类算法)、基于关联规则的(The Apriori algorithm算法是一种最有影响的挖掘布尔关联规则频繁项集的算法)、以及基于模型的推荐(机器学习,所谓机器学习,即让计算机像人脑一样持续学习,是人工智能领域内的一个子领域)。
关于上述第二个分类(2、根据其数据源)中的基于协同过滤的推荐:随着 Web2.0 的发展,Web 站点更加提倡用户参与和用户贡献,因此基于协同过滤的推荐机制因运而生。它的原理很简单,就是根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐。
而基于协同过滤的推荐,又分三个子类:
基于用户的推荐(通过共同口味与偏好找相似邻居用户,K-邻居算法,你朋友喜欢,你也可能喜欢),
基于项目的推荐(发现物品之间的相似度,推荐类似的物品,你喜欢物品A,C与A相似,可能也喜欢C),
基于模型的推荐(基于样本的用户喜好信息构造一个推荐模型,然后根据实时的用户喜好信息预测推荐)。
我们看到,此协同过滤算法最大限度的利用用户之间,或物品之间的相似相关性,而后基于这些信息的基础上实行推荐。下文还会具体介绍此协同过滤。
不过一般实践中,我们通常还是把推荐引擎分两类:
第一类称为协同过滤,即基于相似用户的协同过滤推荐(用户与系统或互联网交互留下的一切信息、蛛丝马迹,或用户与用户之间千丝万缕的联系),以及基于相似项目的协同过滤推荐(尽最大可能发现物品间的相似度);
第二类便是基于内容分析的推荐(调查问卷,电子邮件,或者推荐引擎对本blog内容的分析)。
2 协同过滤推荐
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering, 简称 CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友或者称之为广义上的邻居(neighborhood),看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。如下图,你能从图中看到多少信息?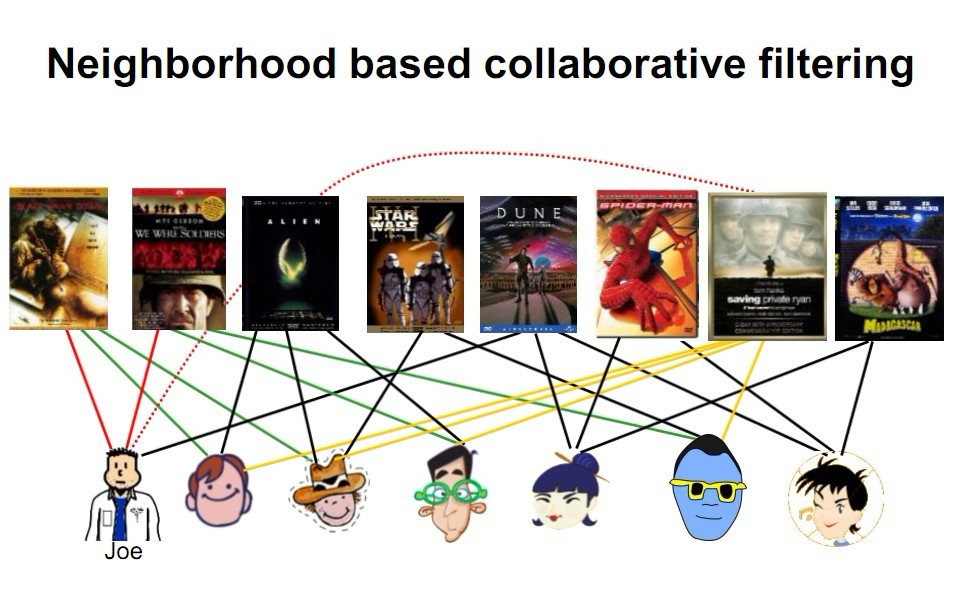
2.1 协同过滤推荐步骤
做协同过滤推荐,一般要做好以下几个步骤:
1)若要做协同过滤,那么收集用户偏好则成了关键。可以通过用户的行为诸如评分(如不同的用户对不同的作品有不同的评分,而评分接近则意味着喜好口味相近,便可判定为相似用户),投票,转发,保存,书签,标记,评论,点击流,页面停留时间,是否购买等获得。如下面第2点所述:所有这些信息都可以数字化,如一个二维矩阵表示出来。
2)收集了用户行为数据之后,我们接下来便要对数据进行减噪与归一化操作(得到一个用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值)。
下面再简单介绍下减噪和归一化操作。
所谓减噪:用户行为数据是用户在使用应用过程中产生的,它可能存在大量的噪音和用户的误操作,我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪音,这样可以是我们的分析更加精确(类似于网页的去噪处理)。
所谓归一化:将各个行为的数据统一在一个相同的取值范围中,从而使得加权求和得到的总体喜好更加精确。最简单的归一化处理,便是将各类数据除以此类中的最大值,以保证归一化后的数据取值在 [0,1] 范围中。至于所谓的加权,很好理解,因为每个人占的权值不同,类似于一场唱歌比赛中对某几个选手进行投票决定其是否晋级,观众的投票抵1分,专家评委的投票抵5分,最后得分最多的选手直接晋级。
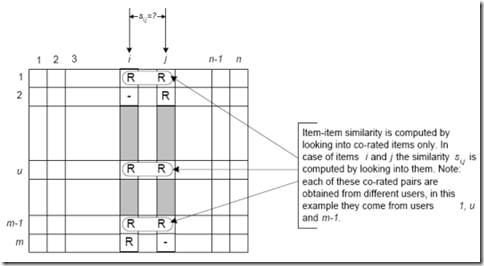
3)找到相似的用户和物品,通过什么途径找到呢?便是计算相似用户或相似物品的相似度。
4)相似度的计算有多种方法,不过都是基于向量Vector的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐中,用户-物品偏好的二维矩阵下,我们将某个或某几个用户对莫两个物品的偏好作为一个向量来计算两个物品之间的相似度,或者将两个用户对某个或某几个物品的偏好作为一个向量来计算两个用户之间的相似度。
所以说,很简单,找物品间的相似度,用户不变,找多个用户对物品的评分;找用户间的相似度,物品不变,找用户对某些个物品的评分。
5)而计算出来的这两个相似度则将作为基于用户、项目的两项协同过滤的推荐。
常见的计算相似度的方法有:欧几里德距离,皮尔逊相关系数(如两个用户对多个电影的评分,采取皮尔逊相关系数等相关计算方法,可以抉择出他们的口味和偏好是否一致),Cosine相似度,Tanimoto系数。
下面,简单介绍其中的欧几里得距离与皮尔逊相关系数:欧几里德距离(Euclidean Distance)是最初用于计算欧几里德空间中两个点的距离,假设 x,y 是 n 维空间的两个点,它们之间的欧几里德距离是:
可以看出,当 n=2 时,欧几里德距离就是平面上两个点的距离。当用欧几里德距离表示相似度,一般采用以下公式进行转换:距离越小,相似度越大(同时,避免除数为0):
余弦相似度Cosine-based Similarity两个项目 i ,j 视作为两个m维用户空间向量,相似度计算通过计算两个向量的余弦夹角,那么,对于m*n的评分矩阵,i ,j 的相似度sim( i , j ) 计算公式:
(其中 " · "记做两个向量的内积)
皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,为了使计算结果精确,需要找出共同评分的用户。记用户集U为既评论了 i 又评论了 j 的用户集,那么对应的皮尔森相关系数计算公式为:
其中Ru,i 为用户u 对项目 i 的评分,对应带横杠的为这个用户集U对项目i的评分评分。
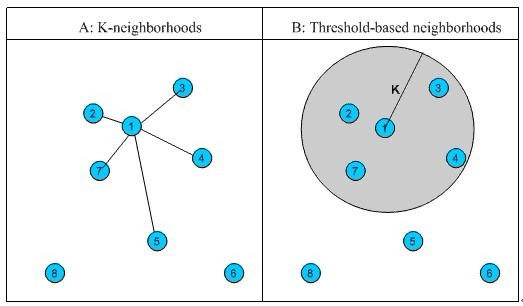
6)相似邻居计算。邻居分为两类:
1、固定数量的邻居K-neighborhoods (或Fix-size neighborhoods),不论邻居的“远近”,只取最近的 K 个,作为其邻居,如下图A部分所示;
2、基于相似度门槛的邻居,落在以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,如下图B部分所示。
再介绍一下K最近邻(k-Nearest Neighbor,KNN)分类算法:这是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
7)经过4)计算出来的基于用户的CF(基于用户推荐之用:通过共同口味与偏好找相似邻居用户,K-邻居算法,你朋友喜欢,你也可能喜欢),基于物品的CF(基于项目推荐之用:发现物品之间的相似度,推荐类似的物品,你喜欢物品A,C与A相似,那么你可能也喜欢C)。
2.2 基于基于用户相似度与项目相似度
上述3.1节中三个相似度公式是基于项目相似度场景下的,而实际上,基于用户相似度与基于项目相似度计算的一个基本的区别是,基于用户相似度是基于评分矩阵中的行向量相似度求解,基于项目相似度计算式基于评分矩阵中列向量相似度求解,然后三个公式分别都可以适用,如下图:
(其中,为0的表示未评分)
基于项目相似度计算式计算如Item3,Item4两列向量相似度;
基于用户相似度计算式计算如User3,User4量行向量相似度。
千言万语不如举个例子。我们来看一个具体的基于用户相似度计算的例子。
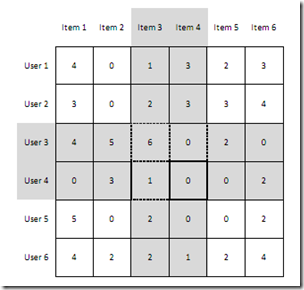
假设我们有一组用户,他们表现出了对一组图书的喜好。用户对一本图书的喜好程度越高,就会给其更高的评分。我们来通过一个矩阵来展示它,行代表用户,列代表图书。
如下图所示,所有的评分范围从1到5,5代表喜欢程度最高。第一个用户(行1)对第一本图书(列1)的评分是4,空的单元格表示用户未给图书评分。
使用基于用户的协同过滤方法,我们首先要做的是基于用户给图书做出的评价,计算用户之间的相似度。
让我们从一个单一用户的角度考虑这个问题,看图1中的第一行,要做到这一点,常见的做法是将使用包含了用户喜好项的向量(或数组)代表每一个用户。相较于使用多样化的相似度量这种做法,更直接。
在这个例子中,我们将使用余弦相似性去计算用户间的相似度。
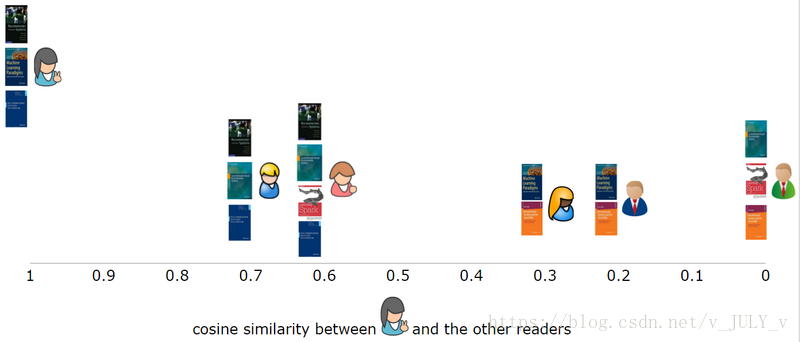
当我们把第一个用户和其他五个用户进行比较时,就能直观的看到他和其他用户的相似程度。
对于大多数相似度量,向量之间相似度越高,代表彼此更相似。本例中,第一个用户第二、第三个用户非常相似,有两本共同书籍,与第四、第五个用户的相似度低一些,只有一本共同书籍,而与最后一名用户完全不相似,因为没有一本共同书籍。
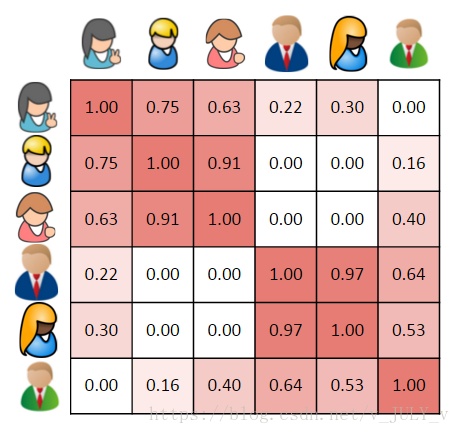
更一般的,我们可以计算出每个用户的相似性,并且在相似矩阵中表示它们。这是一个对称矩阵,单元格的背景颜色表明用户相似度的高低,更深的红色表示它们之间更相似。
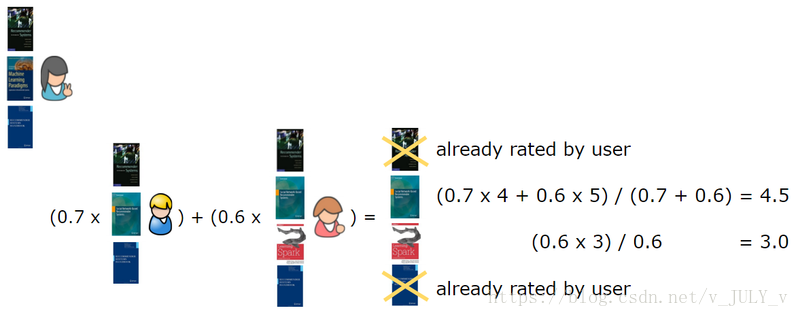
所以,我们找到了与第一个用户最相似的第二个用户,删除用户已经评价过的书籍,给最相似用户正在阅读的书籍加权,然后计算出总和。
在这种情况下,我们计算出n=2,表示为了产生推荐,需要找出与目标用户最相似的两个用户,这两个用户分别是第二个和第三个用户,然后第一个用户已经评价了第一和第五本书,故产生的推荐书是第三本(4.5分),和第四本(3分)。
此外,什么时候用item-base,什么时候用user-base呢:http://weibo.com/1580904460/zhZ9AiIkZ?mod=weibotime?
一般说来,如果item数目不多,比如不超过十万,而且不显著增长的话,就用item-based 好了。为何?如@wuzh670所说,如果item数目不多+不显著增长,说明item之间的关系在一段时间内相对稳定(对比user之间关系),对于实时更新item-similarity需求就降低很多,推荐系统效率提高很多,故用item-based会明智些。
反之,当item数目很多,建议用user-base。当然,实践中具体情况具体分析。如下图所示(摘自项亮的《推荐系统实践》一书):
3 参考文献
1 推荐引擎算法学习导论:协同过滤、聚类、分类:https://blog.csdn.net/v_july_v/article/details/7184318
2 协同过滤推荐算法和基于内容的过滤算法:https://time.geekbang.org/article/1947今日推荐:【音乐推荐系统 直播课】
实时直播,在线答疑!
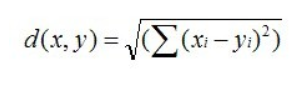
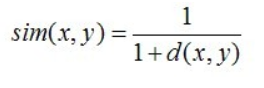
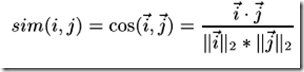
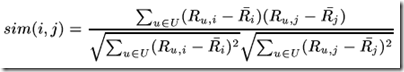



评论