
深入AQS源码阅读与强软弱虚4种引用以及ThreadLocal原理与源码
前言
今天咱们继续讲AQS的源码,在上节课我教大家怎么阅读AQS源码,跑不起来的不读、解决问题就好 —目的性、一条线索到底、无关细节略过,读源码的时候应该先读骨架,比如拿AQS来说,你需要了解AQS是这么一个数据 结构,你读源码的时候读起来就会好很多,在这里需要插一句,从第一章到本章,章章的内容都是环环相扣的,没学习前边,建议先去补习一下前面的章节。
通过ReentrantLock来解读AQS源码
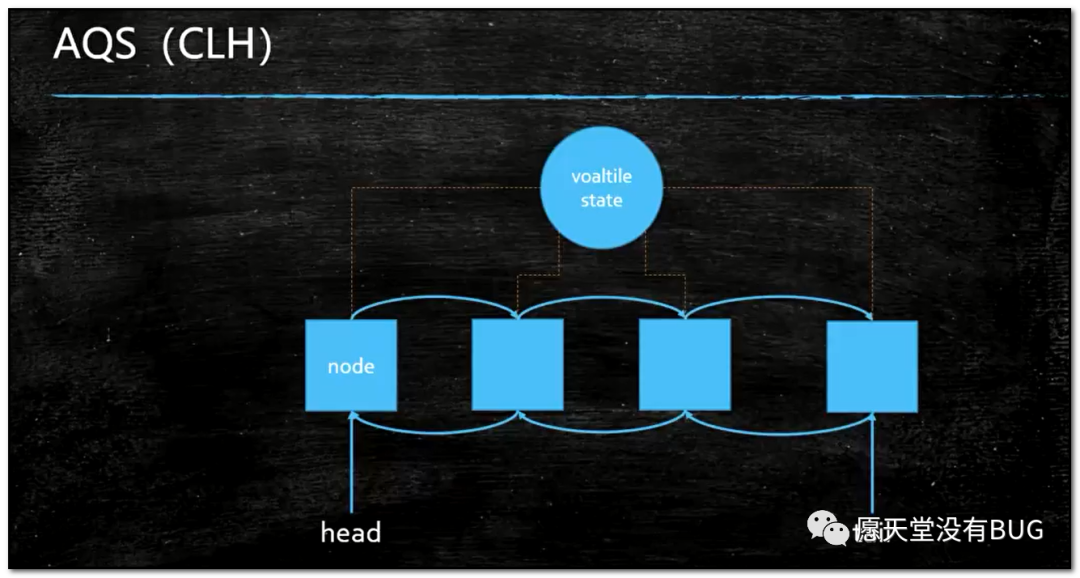
AQS大家还记得吗?最核心的是它的一个共享的int类型值叫做state,这个state用来干什么,其实主要是看他的子类是怎么实现的,比如ReentrantLock这个state是用来干什么的?拿这个state来记录这个线程到底重入了多少次,比如说有一个线程拿到state这个把锁了,state的值就从0变成了1,这个线程又重入了一次,state就变成2了,又重入一次就变成3等等,什么时候释放了呢?从3变成2变成1变成0就释放了,这个就是AQS核心的东西,一个数,这个数代表了什么要看子类怎么去实现它,那么在这个state核心上还会有一堆的线程节点,当然这个节点是node,每个node里面包含一个线程,我们称为线程节点,这么多的线程节点去争用这个state,谁拿到了state,就表示谁得到了这把锁,AQS得核心就是一个共享的数据,一堆互相抢夺竞争的线程,这个就是AQS。
我们接着上节课来讲,首先给lock()方法处打断点,然后debug运行程序,
//JDK源码public class TestReentrantLock {private static volatile int i = 0;public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();lock.lock();//synchronized (TestReentrantLock.class) {i++;//}lock.unlock();//synchronized 程序员的丽春院 JUC}
}在lock()方法里里面,我们可以读到它调用了sync.acquire(1),
//JDK源码public class ReentrantLock implements Lock, java.io.Serializable {public void lock(){
sync.acquire(1);
}
}再跟进到acquire(1)里,可以看到acquire(1)里又调用了我们自己定义自己写的那个tryAcquire(arg)
//JDK源码public abstract class AbstractQueuedSynchronizerextends AbstractOwnableSynchronizerimplements java.io.Serializable {public final void acquire(int arg){if(!tryAcquire(arg)
&& acquireQueued(addWaiter(Node.EXCLUSIVE),arg))
selfInterrupt();
}
}跟进到tryAcquire(arg)里又调用了nonfairTrytAcquire(acquires)
//JDK源码public class ReentrantLock implements Lock, java.io.Serializable {public void lock(){
sync.acquire(1);
}static final NonfairSync extends Sync{protected final boolean tryAcquire(int acquire){return nonfairTrytAcquire(acquires);
}
}
}nonfairTrytAcquire(acquires)我们读进去会发现它的里面就调用到了state这个值,到这里我们就接上了上一章讲的,nonfairTrytAcquire(acquires)里是这样的,首先拿到当前线程,拿到state的值,然后进行if判断,如果state的值为0,说明没人上锁,没人上锁怎么办呢?就给自己上锁,当前线程就拿到这把锁,拿到这个把锁的操作用到了CAS(compareAndSetState)的操作,从0让他变成1,state的值设置为1以后,设置当前线程是独一无二的拥有这把锁的线程,否则如果当前线程已经占有这把锁了,怎么办?很简单我们在原来的基础上加1就可以了,这样就能拿到这把锁了,就重入,前者是加锁后者是重入
//JDK源码public class ReentrantLock implements Lock, java.io.Serializable {public void lock(){
sync.acquire(1);
}static final NonfairSync extends Sync{protected final boolean tryAcquire(int acquire){return nonfairTrytAcquire(acquires);
}
}final boolean nonfairTrytAcquire(int acquire){//获取当前线程final Thread current = Thread.currentThread();//拿到AQS核心数值stateint c getState();//如果数值为0说明没人上锁if(c == 0){//给当线程上锁if(compareAndSetState(0,acquires)){//设置当前线程为独一无二拥有这把锁的线程setExclusiveOwnerThread(current);return true}
}//判断当前线程是否拥有这个把锁else if(current == getExclusiveOwnerThread){//设置重入int nextc = c + acquires;if(nextc < 0)throw new Error("Maximum lock count wxceeded");
setState(nextc);return true;
}return false;
}
}我们跟进到tryAcquire(arg)是拿到了这把锁以后的操作,如果拿不到呢?如果拿不到它实际上是调用了acquireQueued()方法,acquireQueued()方法里又调用了addWaiter(Node.EXCLUSIVE)然后后面写一个arg(数值1),方法结构是这样的acquireQueued(addWaiter(Node.EXCLUSIVE),arg)通过acquireQueued这个方法名字你猜一下这是干什么的,你想如果是我得到这把锁了,想一下后面的acquireQueued是不用运行的,如果没有得到这把锁,后面的acquireQueued()才需要运行,那么想一下没有得到这把锁的时候它会运行什么呢?他会运行acquireQueued,Queued队列,acquire获得,跑到队列里去获得,那意思是什么?排队去,那排队的时候需要传递两个参数,第一个参数是某个方法的返回值addWaiter(Node.EXCLUSIVE),来看这个方法的名字addWaiter,Waiter等待者,addWaiter添加一个等待者,用什么样的方式呢?Node.EXCLUSIVE排他形式,意思就是把当线程作为排他形式扔到队列里边。
//JDK源码public abstract class AbstractQueuedSynchronizerextends AbstractOwnableSynchronizerimplements java.io.Serializable {public final void acquire(int arg){//判断是否得到锁if(!tryAcquire(arg)
&& acquireQueued(addWaiter(Node.EXCLUSIVE),arg))
selfInterrupt();
}
}我们来说一下这个addWaiter()方法,这个方法意思是说你添加等待者的时候,使用的是什么类型,如果这个线程是Node.EXCLUSIVE那么就是排他锁,Node.SHARED就是共享锁,首先是获得当前要加进等待者队列的线程的节点,然后是一个死循环,这意思就是说我不干成这件事我誓不罢休,那它干了一件什么事呢?
//JDK源码public abstract class AbstractQueuedSynchronizerextends AbstractOwnableSynchronizerimplements java.io.Serializable {public final void acquire(int arg){//判断是否得到锁if(!tryAcquire(arg)
&& acquireQueued(addWaiter(Node.EXCLUSIVE),arg))
selfInterrupt();
}private Node addWaiter(Node mode){//获取当前要加进来的线程的node(节点)Node node = new Node(mode);for(;;){//回想一下AQS数据结构图Node oldTail = tail;if(oldTail != null){//把我们这个新节点的前置节点设置在等待队列的末端node.setPrevRelaved(oldTail);//CAS操作,把我们这个新节点设置为tail末端if(compareAndAetTail(oldTail,node)){
oldTail.next = node;return node;
}
}else{
initializeSuncQueue();
}
}
}
}你想想想看,我们回想一下AQS数据结构图,就是他有一个int类型的数叫state,然后在state下面排了一个队列,这个队列是个双向的链表有一个head和一个tail,现在你要往这个队列中加一个节点上来,要排队嘛,我们仔细想一下加节点的话,应该得加到这个队列的末端是不是?它是怎么做到的呢?首先把tail记录在oldTail里,oldTail指向这个tail了,如果oldTail不等于空,它会把我们这个新节点的前置节点设置在这个队列的末端,接下来再次用到CAS操作,把我们这个新的节点设置为tail,整段代码看似繁琐,其实很简单,就是要把当前要加进等待者队列的线程的节点加到等待队列的末端,这里提一点,加到末端为什么要用CAS操作呢?因为CAS效率高,这个问题关系到AQS的核心操作,理解了这一点,你就理解了AQS为什么效率高,我们接着讲源码,这个增加线程节点操作,如果没有成功,那么就会不断的试,一直试到我们的这个node节点被加到线程队列末端为止,意思就是说,其它的节点也加到线程队列末端了,我无非就是等着你其它的线程都加到末端了,我加最后一个,不管怎么样我都要加到线程末端去为止。
源码读这里我们可以总结得出,AQS(
AbstractQueuedSynchronizer)的核心就是用CAS(compareAndSet)去操作head和tail,就是说用CAS操作代替了锁整条双向链表的操作
通过AQS是如何设置链表尾巴的来理解AQS为什么效率这么高
我们的思路是什么呢?假如你要往一个链表上添加尾巴,尤其是好多线程都要往链表上添加尾巴,我们仔细想想看用普通的方法怎么做?第一点要加锁这一点是肯定的,因为多线程,你要保证线程安全,一般的情况下,我们会锁定整个链表(Sync),我们的新线程来了以后,要加到尾巴上,这样很正常,但是我们锁定整个链表的话,锁的太多太大了,现在呢它用的并不是锁定整个链表的方法,而是只观测tail这一个节点就可以了,怎么做到的呢?compareAndAetTail(oldTail,node),中oldTail是它的预期值,假如说我们想把当前线程设置为整个链表尾巴的过程中,另外一个线程来了,它插入了一个节点,那么仔细想一下Node oldTail = tail;的整个oldTail还等于整个新的Tail吗?不等于了吧,那么既然不等于了,说明中间有线程被其它线程打断了,那如果说却是还是等于原来的oldTail,这个时候就说明没有线程被打断,那我们就接着设置尾巴,只要设置成功了OK,compareAndAetTail(oldTail,node)方法中的参数node就做为新的Tail了,所以用了CAS操作就不需要把原来的整个链表上锁,这也是AQS在效率上比较高的核心。
为什么是双向链表?
其实你要添加一个线程节点的时候,需要看一下前面这个节点的状态,如果前面的节点是持有线程的过程中,这个时候你就得在后面等着,如果说前面这个节点已经取消掉了,那你就应该越过这个节点,不去考虑它的状态,所以你需要看前面节点状态的时候,就必须是双向的。
接下来我们来解读acquireQueued()这个方法,这个方法的意思是,在队列里尝试去获得锁,在队列里排队获得锁,那么它是怎么做到的呢?我们先大致走一遍这个方法,首先在for循环里获得了Node节点的前置节点,然后判断如果前置节点是头节点,并且调用tryAcquire(arg)方法尝试一下去得到这把锁,获得了头节点以后,你设置的节点就是第二个,你这个节点要去和前置节点争这把锁,这个时候前置节点释放了,如果你设置的节点拿到了这把锁,拿到以后你设置的节点也就是当前节点就被设置为前置节点,如果没有拿到这把锁,当前节点就会阻塞等着,等着什么?等着前置节点叫醒你,所以它上来之后是竞争,怎么竞争呢?如果你是最后节点,你就下别说了,你就老老实实等着,如果你的前面已经是头节点了,说明什么?说明快轮到我了,那我就跑一下,试试看能不能拿到这把锁,说不定前置节点这会儿已经释放这把锁了,如果拿不着阻塞,阻塞以后干什么?等着前置节点释放这把锁以后,叫醒队列里的线程,我想执行过程已经很明了了,打个比方,有一个人,他后面又有几个人在后面排队,这时候第一个人是获得了这把锁,永远都是第一个人获得锁,那么后边来的人干什么呢?站在队伍后面排队,然后他会探头看他前面这个人是不是往前走了一步,如果走了,他也走一步,当后来的这个人排到了队伍的第二个位置的时候,发现前面就是第一个人了,等这第一个人走了就轮到他了,他会看第一个人是不if(shouldParkAfterFailedAcquire(p,node))
interrupted |= parkAndCheckInterrupt();
}catch (Throwable t){
cancelAcquire(node);if(interrupted)
selfInterrupt();throw t;
}
}
}
}到这里AQS还有其它的一些细节我建议大家读一下,比如AQS是怎么释放锁的,释放完以后是怎么通知后置节点的,这个就比较简单了,本章不再一一赘述了,那么在你掌握了读源码的技巧,以及在前面教你了AQS大体的结构,还教了你怎么去记住这个队列,那么怎么去unlock这件事,就由大家自己去探索了。
VarHandle
我们再来讲一个细节,我们看addWaiter()这个方法里边有一个node.setPrevRelaved(oldTail),这个方法的意思是把当前节点的前置节点写成tail,进入这个方法你会看到PREV.set(this,p),那这个PREV是什么东西呢?当你真正去读这个代码,读的特别细的时候你会发现,PREV有这么一个东西叫VarHandle,这个VarHandle是什么呢?这个东西实在JDK1.9之后才有的,我们说一下这个VarHandle,Var叫变量(variable),Handle叫句柄,打个比方,比如我们写了一句话叫Object o= new Object(),我们new了一个Object,这个时候内存里有一个小的引用“O”,指向一段大的内存这个内存里是new的那个Object对象,那么这个VarHandle指什么呢?指的是这个“引用”,我们思考一下,如果VarHandle代表“引用”,那么VarHandle所代表的这个值PREV是不是也这个“引用”呢?当然是了。这个时候我们会生出一个疑问,本来已经有一个“O”指向这个Object对象了,为什么还要用另外一个引用也指向这个对象,这是为什么?
//JDK源码public abstract class AbstractQueuedSynchronizerextends AbstractOwnableSynchronizerimplements java.io.Serializable {public final void acquire(int arg){//判断是否得到锁if(!tryAcquire(arg)
&& acquireQueued(addWaiter(Node.EXCLUSIVE),arg))
selfInterrupt();
}private Node addWaiter(Node mode){//获取当前要加进来的线程的node(节点)Node node = new Node(mode);for(;;){//回想一下AQS数据结构图Node oldTail = tail;if(oldTail != null){//把我们这个新节点的前置节点设置在等待队列的末端node.setPrevRelaved(oldTail);//CAS操作,把我们这个新节点设置为tail末端if(compareAndAetTail(oldTail,node)){
oldTail.next = node;return node;
}
}else{是完事了,完事了他就变成头节点了,就是这么个意思。//JDK源码public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {public final void acquire(int arg){//判断是否得到锁if(!tryAcquire(arg)
&& acquireQueued(addWaiter(Node.EXCLUSIVE),arg))
selfInterrupt();
}final boolean acquireQueud(final Node node,int arg){
boolean interrupted = false;try{for(;;){final Node p = node.predecessor();if(p == head && tryAcquire(arg)){
setHead(node);
p.next = null;return interrupted;
}
initializeSuncQueue();
}
}
}final void setPrevRelaved(Node p){
PREV.set(this,p);
}private static final VarHandle PREV;static {try{
MethodHandles.Lookup l = MethodHandles.lookup():
PREV = l.findVarHandle(Node.class,"prev",Node.class);
}catch(ReflectiveOperationException e){throw new ExceptionInInitializerError(e);
}
}
}我们来看一个小程序,用这个小程序来理解这个VarHandle是什么意思,在这个类,我们定义了一个int类型的变量x,然后定义了一个VarHandle类型的变量handle,在静态代码块里设置了handle指向T01_HelloVarHandle类里的x变量的引用,换句话说就是通过这个handle也能找到这个x,这么说比较精确,通过这个x能找到这个x,里面装了个8,通过handle也能找到这个x,这样我们就可以通过这个handle来操作这个x的值,我们看main方法里,我们创建了T01_HelloVarHandle对象叫t,这个t对象里有一个x,里面还有个handle,这个handle也指向这个x,既然handle指向x,我当然可以(int)handle.get(t)拿到这个x的值不就是8吗?我还可以通过handle.set(t,9)来设置这个t对象的x值为9,读写操作很容易理解,因为handle指向了这个变量,但是最关键的是通过这个handle可以做什么事呢?handle.compareAndSet(t,9,10),做原子性的修改值,我通过handle.compareAndSet(t,9,10)把9改成10改成100,这是原子性的操作,你通过x=100 ,它会是原子性的吗?当然int类型是原子性的,但是long类型呢?就是说long类型连x=100都不是原子性的,所以通过这个handle可以做一些compareAndSet操作(原子操作),还可以handle.getAndAdd()操作这也是原子操作,比如说你原来写x=x+10,这肯定不是原子操作,因为当你写这句话的时候,你是需要加锁的,要做到线程安全的话是需要加锁的,但是如果通过handle是不需要的,所以这就是为什么会有VarHandle,VarHandle除了可以完成普通属性的原子操作,还可以完成原子性的线程安全的操作,这也是VarHandle的含义。
在JDK1.9之前要操作类里边的成员变量的属性,只能通过反射完成,用反射和用VarHandle的区别在于,VarHandle的效率要高的多,反射每次用之前要检查,VarHandle不需要,VarHandle可以理解为直接操纵二进制码,所以VarHandle反射高的多
//小程序public class T01_HelloVarHandle {int x = 8;private static VarHandle handle;static {try {
handle =
MethodHandles.lookup().findVarHandle(T01_HelloVarHandle.class, "x", int.class);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}public static void main(String[] args) {
T01_HelloVarHandle t = new T01_HelloVarHandle();//plain read / writeSystem.out.println((int)handle.get(t));
handle.set(t,9);
System.out.println(t.x);
handle.compareAndSet(t, 9, 10);
System.out.println(t.x);
handle.getAndAdd(t, 10);
System.out.println(t.x);
}
}ThreadLocal
首先我们来说一下ThreadLocal的含义,Thread线程,Local本地,线程本地到底是什么意思呢?我们来看下面这个小程序,我们可以看到这个小程序里定义了一个类,这个类叫Person,类里面定义了一个String类型的变量name,name的值为“zhangsan”,在ThreadLocal1这个类里,我们实例化了这个Person类,然后在main方法里我们创建了两个线程,第一个线程打印了p.name,第二个线程把p.name的值改为了“lisi”,两个线程访问了同一个对象
public class ThreadLocal1 {volatile static Person p = new Person();public static void main(String[] args) {new Thread(()->{try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(p.name);
}).start();new Thread(()->{try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
p.name = "lisi";
}).start();
}
}class Person {
String name = "zhangsan";
}这个小程序想想也知道,最后的结果肯定是打印出了“lisi”而不是“zhangsan”,因为原来的值虽然是“zhangsan”,但是有一个线程1秒终之后把它变成“lisi”了,另一个线程两秒钟之后才打印出来,那它一定是变成“lisi”了,所以这件事很正常,但是有的时候我们想让这个对象每个线程里都做到自己独有的一份,我在访问这个对象的时候,我一个线程要修改内容的时候要联想另外一个线程,怎么做呢?我们来看这个小程序,这个小程序中,我们用到了ThreadLocal,我们看main方法中第二个线程,这个线程在1秒终之后往tl对象中设置了一个Person对象,虽然我们访问的仍然是这个tl对象,第一个线程在两秒钟之后回去get获取tl对象里面的值,第二个线程是1秒钟之后往tl对象里set了一个值,从多线程普通的角度来讲,既然我一个线程往里边set了一个值,另外一个线程去get这个值的时候应该是能get到才对,但是很不幸的是,来看代码,我们1秒终的时候set了一个值,两秒钟的时候去拿这个值是拿不到的,这个小程序证明了这一点,这是为什么呢?原因是如果我们用ThreadLocal的时候,里边设置的这个值是线程独有的,线程独有的是什么意思呢?就是说这个线程里用到这个ThreadLocal的时候,只有自己去往里设置,设置的是只有自己线程里才能访问到的Person,而另外一个线程要访问的时候,设置也是自己线程才能访问到的Person,这就是ThreadLocal的含义
public class ThreadLocal2 {//volatile static Person p = new Person();static ThreadLocal tl = new ThreadLocal<>();public static void main(String[] args) {new Thread(()->{try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(tl.get());
}).start();new Thread(()->{try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
tl.set(new Person());
}).start();
}static class Person {
String name = "zhangsan";
} 讲到这里,有没有想过我就是往tl对象里设置了一个Person,但是设置好了以后,另一个线程为什么就是读取不到呢?这到底是怎么做到的呢?要想理解怎么做到的,得去读一下ThreadLocal的源码,我们尝试一下读ThreadLocal的源码
ThreadLocal源码
我们先来看一个ThreadLocal源码的set方法,ThreadLocal往里边设置值的时候是怎么设置的呢?首先拿到当前线程,这是你会发现,这个set方法里多了一个容器ThreadLocalMap,这个容器是一个map,是一个key/value对,然后再往下读你会发现,其实这个值是设置到了map里面,而且这个map是什么样的,key设置的是this,value设置的是我们想要的那个值,这个this就是当前对象ThreadLocal,value就是Person类,这么理解就行了,如果map不等于空的情况下就设置进去就行了,如果等于空呢?就创建一个map
//ThraedLocal源码public class ThreadLocal { public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);
}
}我们回过头来看这个map,ThreadLocalMap map=getMap(t),我们来看看这个map到底在哪里,我们点击到了getMap这个方法看到,它的返回值是t.threadLocals
//ThreadLocal源码public class ThreadLocal { public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);
}ThreadLocalMap getMap(Thread t){return t.threadLocals;
}
}我们进入这个t.threadLocals,你会发现ThreadLocalMap这个东西在哪里呢?居然是在Thread这个类里,所以说这个map是在Thred类里的
public class Thread implements Runnable{
ThreadLocal.ThreadLocalMap threadLocals = null;
}这个时候我们应该明白,map的set方法其实就是设置当前线程里面的map:
·set
- Thread.currentThread.map(ThreadLocal,person)
所以这个时候你会发现,原来Person类被set到了,当前线程里的某一个map里面去了,这个时候,我们是不是就能想明白了,我set了一个值以后,为什么其他线程访问不到?我们注重“当前线程”这个段话,所以个t1线程set了一个Person对象到自己的map里,t2线程去访问的也是自己的属于t2线程的map,所以是读不到值的,因此你使用ThreadLocal的时候,你用set和get就完全的把他隔离开了,就是我自己线程里面所特有的,其它的线程是没有的,以前我们的理解是都在一个map,然而并不是,所以你得读源码,读源码你就明白了
为什么要用ThreadLocal?
我们根据Spirng的声明式事务来解析,为什么要用ThreadLocal,声明式事务一般来讲我们是要通过数据库的,但是我们知道Spring结合Mybatis,我们是可以把整个事务写在配置文件中的,而这个配置文件里的事务,它实际上是管理了一系列的方法,方法1、方法2、方法3....,而这些方法里面可能写了,比方说第1个方法写了去配置文件里拿到数据库连接Connection,第2个、第3个都是一样去拿数据库连接,然后声明式事务可以把这几个方法合在一起,视为一个完整的事务,如果说在这些方法里,每一个方法拿的连接,它拿的不是同一个对象,你觉的这个东西能形成一个完整的事务吗?Connection会放到一个连接池里边,如果第1个方法拿的是第1个Connection,第2个拿的是第2个,第3个拿的是第3个,这东西能形成一个完整的事务吗?百分之一万的不可能,没听说过不同的Connection还能形成一个完整的事务的,那么怎么保证这么多Connection之间保证是同一个Connection呢?把这个Connection放到这个线程的本地对象里ThreadLocal里面,以后再拿的时候,实际上我是从ThreadLocal里拿的,第1个方法拿的时候就把Connection放到ThreadLocal里面,后面的方法要拿的时候,从ThreadLocal里直接拿,不从线程池拿。
java的四种引用:强软弱虚
其实java有4种引用,4种可分为强、软、弱、虚
gc:java的垃圾回收机制
首先明白什么是一个引用?
Object o = new Object()这就是一个引用了,一个变量指向new出来的对象,这就叫以个引用,引用这个东西,在java里面分4种,普通的引用比如Object o = new Object(),这个就叫强引用,强引用有什么特点呢?我们来看下面的小程序。
强引用
首先看到我们有一个类叫M,在这个类里我重写了一个方法叫fifinalize(),我们可以看到这个方法是已经被废弃的方法,为什么要重写他呢?主要想说明一下在垃圾回收的过程中,各种引用它不同的表现,垃圾回收的时候,它是会调用fifinalize()这个方法的,什么意思?当我们new出来一个象,在java语言里是不需要手动回收的,C和C++是需要的,在这种情况下,java的垃圾回收机制会自动的帮你回收这个对象,但是它回收对象的时候它会调用fifinalize()这个方法,我们重写这个方法之后我们能观察出来,它什么时候被垃圾回收了,什么时候被调用了,我在这里重写这个方法的含义是为了以后面试的时候方便你们造火箭,让你们观察结果用的,并不说以后在什么情况下需要重写这个方法,这个方法永远都不需要
重写,而且也不应该被重写。
public class M {@Overrideprotected void finalize() throws Throwable {
System.out.println("finalize");
}
}我们来解释一下普通的引用NormalReference,普通的引用也就是默认的引用,默认的引用就是说,只要有一个应用指向这个对象,那么垃圾回收器一定不会回收它,这就是普通的引用,也就是强引用,为什么不会回收?因为有引用指向,所以不会回收,只有没有引用指向的时候才会回收,指向谁?指向你创建的那个对象。
我们来看下面这个小程序,我new了一个m出来,然后调用了System.gc(),显式的来调用一下垃圾回收,让垃圾回收尝试一下,看能不能回收这个m,需要注意的是,要在最后阻塞住当前线程,为什么?
因为System.gc()是跑在别的线程里边的,如果main线程直接退出了,那整个程序就退出了,那gc不gc就没有什么意义了,所以你要阻塞当前线程,在这里调用了System.in.read()阻塞方法,它没有什么含义,只是阻塞当前线程的意思。
阻塞当前线程就是让当前整个程序不会停止,程序运行起来你会发现,程序永远不会输出,为什么呢?
我们想一下,这个M是有一个小引用m指向它的,那有引用指向它,它肯定不是垃圾,不是垃圾的话一定不会被回收。
public class T01_NormalReference {public static void main(String[] args) throws IOException {
M m = new M();
System.gc(); //DisableExplicitGCSystem.in.read();
}
}那你想让它显示回收,怎么做呢?我们让m=null,m=nul的意思就是不会再有引用指向这个M对象了,也就是说把m和new M()之间的引用给打断了,不再有关联了,这个时候再运行程序,你会发现,输出了:fifinalize,说明什么?说明M对象被回收了,综上所述这个就是强引用
public class T01_NormalReference {public static void main(String[] args) throws IOException {
M m = new M();
m = null;
System.gc(); //DisableExplicitGCSystem.in.read();
}
}我们来看一下什么是软引用,要声明一个软引用,要在内存里面体现一个软引用,怎么做呢?我们来看下面这个小程序SoftReference叫软引用,Soft是软的意思。
我们来分析SoftReference
软引用
我们来说一下软引用的含义,当有一个对象(字节数组)被一个软引用所指向的时候,只有系统内存不够用的时候,才会回收它(字节数组)
我们来跑一下这个程序,在程序运行的时候,我们来设置一下堆内存最大为20MB,就是说我堆内存直接给你分配20MB,你要设置一下堆内存,如果不设置它永远不会回收的,这个时候我们运行程序你会发现,第三次调用m.get()输出的时候,输出的值为null,我们来分析一下,第一次我们的堆内存这个时候最多只能放20MB,第一次创建字节数组的时候分配了10MB,这个时候堆内存是能分配下的,这个时候我调用了gc来做回收是无法回收的,因为堆内存够用,第二次创建字节数组的时候分配了15MB,这个时候对内存的内存还够15MB吗?肯定是不够的,不够了怎么办?清理,清理的时候既然内存不够用,就会把你这个软引用给干掉,然后15MB内存分配进去,所以这个时候你再去get第一个字节数组的时候它是一个null值,这是就是软引用的含义,用大腿想一想这个软引用的使用场景:做缓存用,这个东西主要做缓存用
//软引用非常适合缓存使用public class T02_SoftReference {public static void main(String[] args) {
SoftReference<byte[]> m = new SoftReference<>(new byte[1024*1024*10]);//m = null;System.out.println(m.get());
System.gc();try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(m.get());//再分配一个数组,heap将装不下,这时候系统会垃圾回收,先回收一次,如果不够,会//把软引用干掉byte[] b = new byte[1024*1024*15];
System.out.println(m.get());
}
}举个例子你从内存里边读一个大图片,特别的图片出来,然你用完了之后就没什么用了,你可以放在内存里边缓存在那里,要用的时候直接从内存里边拿,但是由于这个大图片占的空间比较大,如果不用的话,那别人也要用这块空间,那就把它干掉,这个时候就用到了软引用
再举个例子,从数据库里读一大堆的数据出来,这个数据有可能比如说你按一下back,我还可以访问到这些数据,如果内存里边有的话,我就不用从数据库里拿了,这个时候我也可以用软应用,需要新的空间你可以把我干掉,没问题我下次去数据库取就行了,但是新空间还够用的时候,我下次就不用从数据库取,直接从内存里拿就行了
弱引用
接下来我们来说一下弱引用,弱引用的意思是,只要遭遇到gc就会回收,刚才我们说到软引用的概念是,垃圾回收不一定回收它,只有空间不够了才会回收它,所以软引用的生存周期还是比较长的,我们接着说弱应用,弱引用就是说,只要垃圾回收看到这个引用是一个特别弱的引用指向的时候,就直接把它给干掉
我们来看这个小程序,WeakReference m = new WeakReference<>(new M()),这里我们new了一个对象这是第一点,这m指向的是一个弱引用,这个弱引用里边有一个引用,是弱弱的指向了new出来的另外一个M对象,然后通过m.get()来打印这个M对象,接下来gc调用垃圾回收,如果他它没有被回收,你接下来get还能拿到,反之则不能
public class T03_WeakReference {public static void main(String[] args) {
WeakReference m = new WeakReference<>(new M());
System.out.println(m.get());
System.gc();
System.out.println(m.get());
ThreadLocal tl = new ThreadLocal<>();
tl.set(new M());
tl.remove();
}
} 运行程序以后我们看到,第一次打印出来了,第二次打印之前调用了gc,所以第二次打印出了null值,那我们想这东西本来指向一个弱引用对象,小m指向这个弱引用对象,这个弱引用对象里边有一个弱弱的引用指向了另外一个大M对象,但这个大M对象垃圾回收一来就把它干掉了,那么把它创建出来有什么用呢?这个东西作用就在于,如果有另外一个强引用指向了这个弱引用之后,只要这个强引用消失掉,这个弱引用就应该去被回收,我就不用管了,只要这个强引用消失掉,我就不用管这个弱引用了,这个弱引用也一定是被回收了,这个东西用在什么地方呢?一般用在容器里
我来讲一个弱引用最典型的一个应用ThreadLocal,我们来看下面的代码,注意看我们创建了一个对象叫tl,这个tl对象的引用指向ThreadLocal对象,ThreadLocal对象里又指向了一个M对象,这是我们最直观的想法!
[05_01](C:\Users\Admin\Desktop\images\05_01.png)public class T03_WeakReference{public static void main(String[] args) {
WeakReference m = new WeakReference<>(new M());
System.out.println(m.get());
System.gc();
System.out.println(m.get());
ThreadLocal tl = new ThreadLocal<>();
tl.set(new M());
tl.remove();
}
} 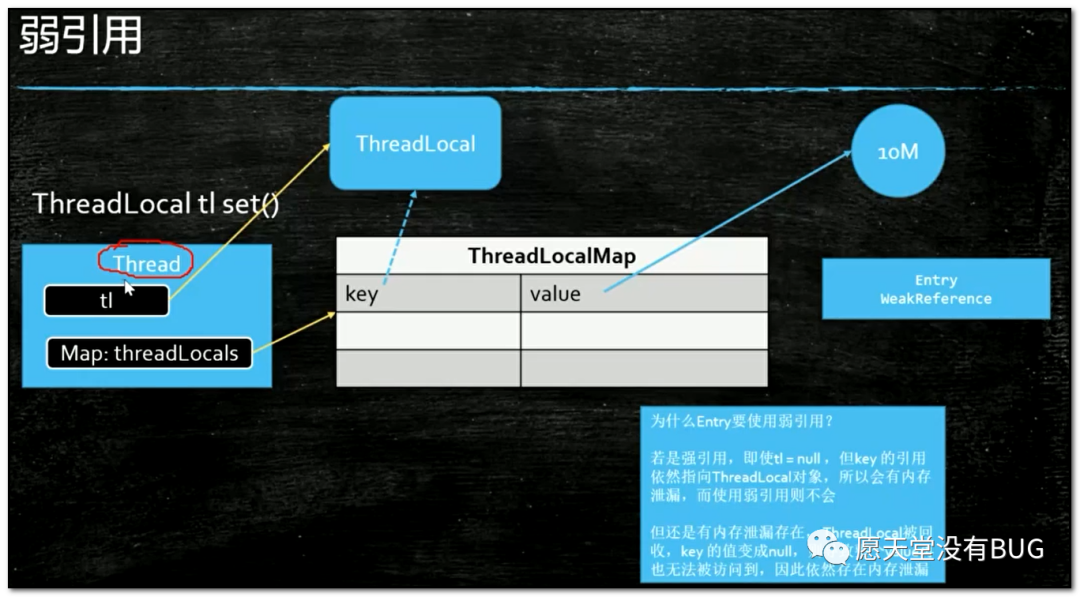
我们的想法是这么个想法,但是它里面到底执行了一个什么样的操作呢?我们来看上面的图,从左往右看,首先我们来说当前肯定是有一个线程的,任何一个方法肯定是要运行在某个线程里的,这个线程是我的主线程,在这个线程里有一个线程的局部变量叫tl,tl它new出来了一个ThreadLoal对象,这是一个强引用没问题,然后我又往ThreadLocal里放了一个对象,可是你们是不是还记得,往ThreadLocal里放对象的话,实际上是放到了当前线程的一个threadLocals变量里面,这个threadLocals变量指向的是一个Map,也就是我们把这个M对象给放到了这Map里面,它的key是我们的ThreadLocal对象,value是我们的M对象,我们来回想一下,往ThreadLocal里面set的时候,先拿到当前线程,然后拿到当前线程里面的那个Map,然后通过这个Map把ThreadLocal对象给set进去,这个map.set(this, value)方法中的this是谁?是ThreadLocal对象,set进去的时候往里面放了这么一个东西叫Entry,这个Entry又是什么呢?注意看代码,这个Entry是从弱引用WeakReference继承出来的
现在也就是说有一个Entry,它的父类是一个WeakReference,这个WeakReference里面装的是什么?
是ThreadLocal对象,也就是说这个Entry一个key一个value,而这个Entry的key的类型是ThreadLocal,这个value当然就是我们的那个M的值或者其它什么值这个不重要,这个key是ThreadLocal,而由于这个Entry是从ThreadLocal继承的,在Entry构造的时候调用了super(k),这个k指的就是ThreadLocal对象,我们想一下WeakReference不就相当于new WeakReference key吗?
//ThreadLocal源码public class ThreadLocal { public void set(T value) {//获取当前线程Thread t = Thread.currentThread();//获取当前线程的MapThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);
}ThreadLocalMap getMap(Thread t){return t.threadLocals;
}private void set(ThreadLocal key, Object value) {
Entry[] tab = table;int len = tab.length;int i = key.threadLocalHashCode & (len-1);for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal k = e.geif (k == key) {
e.value = value;return;if (k == null) {
replaceStaleEntry(key, value, i);return;
}
tab[i] = new Entry(key, value);int sz = ++size;if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}static class Entry extends WeakReference> { /** The value associated with this ThreadLocal. */Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
}我们来看下面图中从左开始看,这时候我们应该明白了,这里tl是一个强引用指向这个ThreadLocal对象,而Map里的key是通过一个弱引用指向了一个ThreadLocal对象,我们假设这是个强引用,当tl指向这个ThreadLocal对象消失的时候,tl这个东西是个局部变量,方法已结束它就消失了,当tl消失了,如果这个ThreadLocal对象还被一个强引用的key指向的时候,这个ThreadLocal对象能被回收吗?肯定不行,而且由于这个线程有很多线程是长期存在的,比如这个是一个服务器线程,7*24小时一年365天不间断运行,那么不间断运行的时候,这个tl会长期存在,这个Map会长期存在,这个Map的key也会长期存在,这个key长期存在的话,这个ThreadLocal对象永远不会被消失,所以这里是不是就会有内存泄漏,但是如果这个key是弱引用的话还会存在这个问题吗?当这个强引用消失的时候这个弱引用是不是自动就会回收了,这也是为什么用WeakReference的原因
关于ThreadLocal还有一个问题,当我们tl这个强引用消失了,key的指向也被回收了,可是很不幸的是这个key指向了一个null值,但是这个threadLocals的Map是永远存在的,相当于说key/value对,你这个key是null的,你这个value指向的东西,你的这个10MB的字节码,你还能访问到吗?访问不到了,如果这个Map越积攒越多,越来越多,它还是会内存泄漏,怎么办呢?所以必须记住这一点,使用ThreadLocal里面的对象不用了,务必要remove掉,不然还会有内存泄漏
ThradLocalM> tl = new ThreadLocal<>();
tl.set(new M());
tl.remove();虚引用
对于虚引用它就干一件事,它就是管理堆外内存的,首先第一点,这个虚引用的构造方法至少都是两个参数的,第二个参数还必须是一个队列,这个虚引用基本没用,就是说不是给你用的,那么它是给谁用的呢?是给写JVM(虚拟机)的人用的
我们来看下面的小程序,在小程序里创建了一个List集合用于模拟内存溢出,还创建了一个
ReferenceQueue(引用队列),在main方法里创建一个虚引用对象PhantomReference,这个虚引用对象指向的这个内存里是什么样子的呢?有一个phantomReference对象指向了一个new出来的
PhantomReference对象,这个对像里面可以访问两个内容,第一个内容是它又通过一个特别虚的引用指向了我们new出来的一个M对象,第二个内容它关联了一个Queue(队列),这个时候一但虚引用被回收,这个虚引用会装到这个队列里,也就是说这个队列是干什么的呢?就是垃圾回收的时候,一但把这个虚引用给回收的时候,会装到这个队列里,让你接收到一个通知,什么时候你检测到这个队列里面如果有一个引用存在了,那说明什么呢?说明这个虚引用被回收了,这个虚引用叫特别虚的引用,指向的任何一个对象,垃圾回收二话不说,上来就把这个M对象给干掉这是肯定的,只要有垃圾回收, 而且虚引用最关键的是当M对象被干掉的时候,你会收到一个通知,通知你的方式是什么呢?通知你的方式就是往这个Queue(队列)里放进一个值
那么我们这个小程序是什么意思呢?在小程序启动前先设置好了堆内存的最大值,然后看第一个线程启动以后,它会不停的往List集合里分配对象,什么时候内存占满了,触发垃圾回收的时候,另外一个线程就不断的监测这个队列里边的变动,如果有就说明这个虚引用被放进去了,就说明被回收了在第一个线程启动后我们会看到,无论我们怎么get这个phantomReference里面的值,它输出的都是空值,虚引用和弱引用的区别就在于,弱引用里边有值你get的时候还是get的到的,但是虚引用你get里边的值你是get不到的
public class T04_PhantomReference {private static final List那么我们想一下你拿不到这里边的值我用它来干什么呢?这里再强调一遍,只是为了给你一个通知,通知的时候放到队列里,这虚引用干什么用?就是写JVM的人拿来用,写JVM的人用的时候怎么用呢?他会当Queue这个值,检测到队列里边有虚引用指向这个东西被回收的时候做出相应的处理,什么时候出现相应的处理呢?
经常会有一种情况,NIO里边有一个比较新的新的Buffffer叫DirectByteBuffffer(直接内存),直接内存是不被JVM(虚拟机)直接管理的内存,被谁管理?被操作系统管理,又叫做堆外内存,这个DirectByteBuffffer是可以指向堆外内存的,那我们想一下,如果这个DirectByteBuffffer设为null,垃圾回收器能回收DirectByteBuffffer吗?它指向内存都没在堆里,你怎么回收它,所以没有办法回收,那么写虚拟机的人怎么回收DirectByteBuffffer呢?如果有一天你也用到堆外内存的时候,当这个DirectByteBuffffer被设为null的时候,你怎么回收堆外这个内存呢?你可以用虚引用,当我们检测到这个虚引用被垃圾回收器回收的时候,你做出相应处理去回收堆外内存
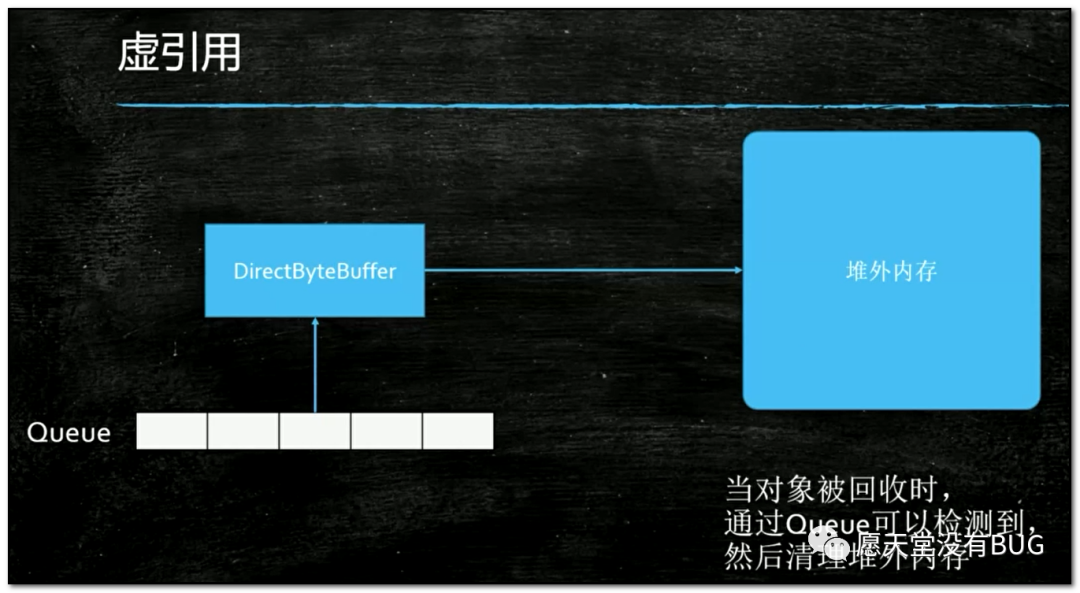
说不定将来的某一天,你写了一个Netty,然后你再Netty里边分配内存的时候,用的是堆外内存,那么堆外内存你又想做到自动的垃圾回收,你不能让人家用你API的人,让人家自己去回收对不对?所以你这个时候怎么做到自动回收呢?你可以检测虚引用里的Queue,什么时候Queue检测到DirectByteBuffffer(直接内存)被回收了,这个时候你就去清理堆外内存,堆外内存怎么回收呢?你如果是C和C++语言写的虚拟机的话,当然是del和free这个两个函数,它们也是C和C++提供的,java里面现在也提供了,堆外内存回收,这个回收的类叫Unsafe,这个类在JDK1.8的时候可以用java的反射机制来用它,但是JDK1.9以后它被加到包里了,普通人是用不了的,但JUC的一些底层有很多都用到了这个类,这个Unsafe类里面有两个方法,allocateMemory方法直接分配内存也就是分配堆外内存,freeMemory方法回收内存也就是手动回收内存,这和C/C++里边一样你直接分配内存,必须得手动回收,
今天讲的是AQS源码阅读与强软弱虚4种引用以及ThreadLocal原理与源码的内容,喜欢的朋友可以转发关注一下小编!
字节大佬,技术文章都没得的推荐呐~
本文就是愿天堂没有BUG给大家分享的内容,大家有收获的话可以分享下,想学习更多的话可以到微信公众号里找我,我等你哦。