
保姆级随机森林算法Python教学
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
摘要
机器学习算法是数据挖掘、数据能力分析和数学建模必不可少的一部分,而随机森林算法和决策树算法是其中较为常用的两种算法,本文将会对随机森林算法的Python实现进行保姆级教学。
0 绪论
数据挖掘和数学建模等比赛中,除了算法的实现,还需要对数据进行较为合理的预处理,包括缺失值处理、异常值处理、特征值的特征编码等等,本文默认读者的数据均已完成数据预处理,如有需要,后续会将数据预处理的方法也进行发布。
一、材料准备
Python编译器:Pycharm社区版或个人版等
训练数据集:此处使用2022年数维杯国际大学生数学建模竞赛C题的附件数据为例。
数据处理:经过初步数据清洗和相关性分析得到初步的特征,并利用决策树进行特征重要性分析,完成二次特征降维,得到'CDRSB_bl', 'PIB_bl', 'FBB_bl'三个自变量特征,DX_bl为分类特征。
二、算法原理
随机森林算法是一种机器学习算法,它通过构建多棵决策树并将它们的预测结果结合起来来预测目标变量。
随机森林是一种典型的Bagging模型,是基于多种决策树的分类智能算法。首先,在处理后的数据集中进行随机抽样,形成n种不同的样本数据集。
然后,根据数据集构建不同的决策树模型,再将测试集代入决策树中,得到分类结果,最后通过投票进行预测分类,具体的流程图如下图1所示:
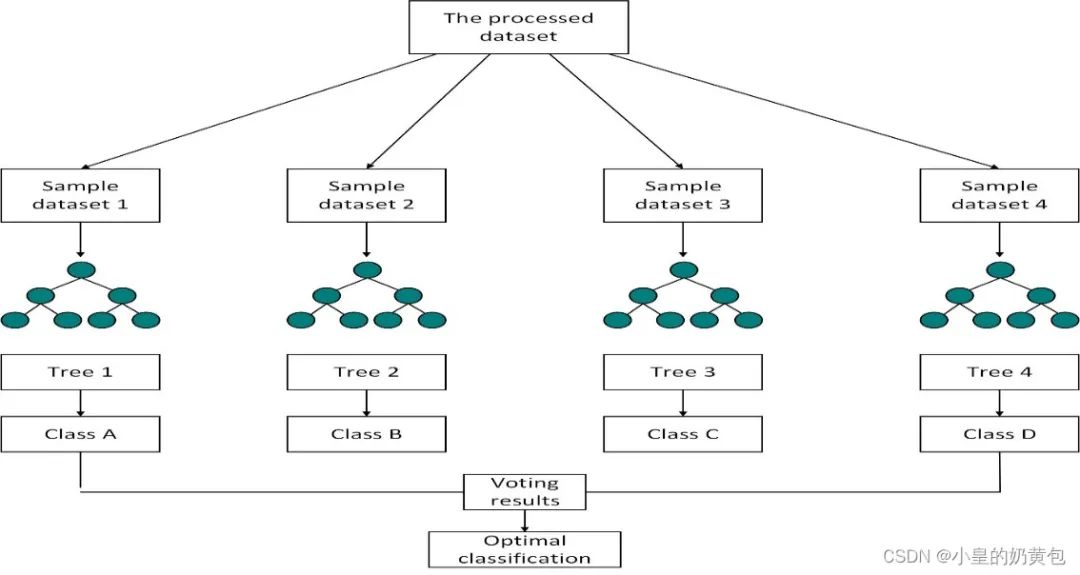
Figure 1 随机森林分类流程图
三、算法Python实现
3.1 数据加载
import pandas as pd# 加载数据X = pd.DataFrame(pd.read_excel('DataX.xlsx')).values # 输入特征y = pd.DataFrame(pd.read_excel('DataY.xlsx')).values # 目标变量
此处将自变量存放在DataX中,因变量存放在DataY中,如需进行样本预测,可另存一个文件(格式与DataX一致),在后文predict中进行替换。
3.2 创建随机森林分类器
from sklearn.ensemble import RandomForestClassifier# 创建随机森林分类器clf = RandomForestClassifier(n_estimators=100)
本文将迭代次数设为100
3.3 创建ShuffleSplit对象,用于执行自动洗牌
from sklearn.model_selection import ShuffleSplit# 创建ShuffleSplit对象,用于执行自动洗牌ss = ShuffleSplit(n_splits=1, train_size=0.7, test_size=0.3, random_state=0)
此处使用70%的样本数据作为训练集,30%的样本数据作为测试集,如果在国际比赛中,可通过调整其测试训练比,来进行模型的敏感性和稳定性分析。
3.4 循环遍历每个拆分,并使用随机森林分类器对每个拆分进行训练和评估
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score# 循环遍历每个拆分,并使用随机森林分类器对每个拆分进行训练和评估for train_index, test_index in ss.split(X, y):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print("Confusion Matrix:")print(confusion_matrix(y_test, y_pred)) # 输出分类结果矩阵print("Classification Report:")print(classification_report(y_test, y_pred)) # 输出混淆矩阵print("Accuracy:")print(accuracy_score(y_test, y_pred))print(clf.predict(X_train)) # 此处用作预测,预测数据可以用另一个文件导入,格式与DataX相同print(clf.score(X_test, y_test))
一个分类器的好坏、是否适用,离不开模型的评估,常用的方法就是混淆矩阵和F1-Score,博主建议直接使用F1-Score即可,如果时间充足,可以使用多种机器学习算法的对比,说明你选择随机森林或者其他机器学习算法的原因,这是加分项。
此处将结果矩阵、分类的准确性、F1-Score值均输出,可适当采用,建议弄成表格放进论文里。
3.5 计算特征重要性
# 计算特征重要性importances = clf.feature_importances_print(importances)
如何判断选择的特征是否需要再次降维,得到的特征重要性非常低,即说明这个指标在该算法分类中不起明显作用,可将该特征进行删除。
3.6 将特征重要性可视化
import matplotlib.pyplot as plt# 画条形图plt.barh(range(len(importances)), importances)# 添加标题plt.title("Feature Importances")feature_names = ['CDRSB_bl', 'PIB_bl', 'FBB_bl']# 添加特征名称plt.yticks(range(len(importances)), feature_names)# 显示图像plt.savefig('feature_importance.png')
对特征重要性进行可视化,可以提高论文的辨识度,也算是加分项,比单纯弄成表格的要好。
3.7 生成决策树可视化图形
from sklearn.tree import export_graphvizimport graphviz# 使用 export_graphviz 函数将决策树保存为 dot 文件dot_data = export_graphviz(clf.estimators_[0], out_file=None,feature_names=['CDRSB_bl', 'PIB_bl','FBB_bl'])# 使用 graphviz 库读取 dot 文件并生成决策树可视化图形graph = graphviz.Source(dot_data)graph.render('decision_tree')
这里将随机森林的算法过程进行可视化,一般来说很长,图片不美观,可以不放进论文里,简单说明即可。
3.8 完整实现代码
from sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import confusion_matrix, classification_report, accuracy_scorefrom sklearn.model_selection import ShuffleSplitimport pandas as pdfrom sklearn.tree import export_graphvizimport graphvizimport matplotlib.pyplot as plt# 加载数据X = pd.DataFrame(pd.read_excel('DataX.xlsx')).values # 输入特征y = pd.DataFrame(pd.read_excel('DataY.xlsx')).values # 目标变量# 创建随机森林分类器clf = RandomForestClassifier(n_estimators=100)# 创建ShuffleSplit对象,用于执行自动洗牌ss = ShuffleSplit(n_splits=1, train_size=0.7, test_size=0.3, random_state=0)# 循环遍历每个拆分,并使用随机森林分类器对每个拆分进行训练和评估for train_index, test_index in ss.split(X, y):X_train, X_test = X[train_index], X[test_index]y_train, y_test = y[train_index], y[test_index]clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print("Confusion Matrix:")print(confusion_matrix(y_test, y_pred)) # 输出分类结果矩阵print("Classification Report:")print(classification_report(y_test, y_pred)) # 输出混淆矩阵print("Accuracy:")print(accuracy_score(y_test, y_pred))print(clf.predict(X_train)) # 此处用作预测,预测数据可以用另一个文件导入,格式与DataX相同print(clf.score(X_test, y_test))importances = clf.feature_importances_ # 计算特征重要性print(importances)# 画条形图plt.barh(range(len(importances)), importances)# 添加标题plt.title("Feature Importances")feature_names = ['CDRSB_bl', 'PIB_bl', 'FBB_bl']# 添加特征名称plt.yticks(range(len(importances)), feature_names)# 显示图像plt.savefig('feature_importance.png')# 使用 export_graphviz 函数将决策树保存为 dot 文件dot_data = export_graphviz(clf.estimators_[0], out_file=None,feature_names=['CDRSB_bl', 'PIB_bl','FBB_bl'])# 使用 graphviz 库读取 dot 文件并生成决策树可视化图形graph = graphviz.Source(dot_data)graph.render('decision_tree')
四、 结论
对随机森林进行Python的实现,并计算了结果矩阵、评估矩阵和准确率,可支持对模型的准确性、适用性、敏感性和稳定性进行分析。
并通过对特征重要性和随机森林算法实现过程的可视化,很好地完成了一趟完整的随机森林算法的演示。
版权声明:本文为CSDN博主「小皇的奶黄包」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/m0_61399808/article/details/128251196
声明:部分内容来源于网络,仅供读者学习、交流之目的文章版权归原作者所有。如有不妥,请联系删除。