
System.currentTimeMillis的性能真有如此不堪吗?
上一篇:0.2秒居然复制了100G文件?

疑惑,System.currentTimeMillis真有性能问题?
/*** 弱精度的计时器,考虑性能不使用同步策略。** @author mycat*/public class TimeUtil {//当前毫秒数的缓存private static volatile long CURRENT_TIME = System.currentTimeMillis();public static final long currentTimeMillis() { return CURRENT_TIME; }public static final long currentTimeNanos() { return System.nanoTime(); }//更新缓存public static final void update() { CURRENT_TIME = System.currentTimeMillis(); }}//使用定时任务调度线程池,定期(每1s)调用update方法更新缓存时钟heartbeatScheduler.scheduleAtFixedRate(processorCheck(), 0L, 1000, TimeUnit.MILLISECONDS);
思索,System.currentTimeMillis有什么性能问题
System.currentTimeMillis要访问系统时钟,这属于临界区资源,并发情况下必然导致多线程的争用 System.currentTimeMillis()之所以慢是因为去跟系统打了一次交道 我有测试记录,并发耗时就是比单线程高250倍!
但我细品一番,发现这些观点充满了漏洞:
大家可以把顺序锁当成是解决了“ABA问题”的CompareAndSwap锁。对于一个临界区资源(这里是xtime),有一个操作序列号,写操作会使序列号+1,读操作则不会。 写操作:CAS使序列号+1 读操作:先获取序列号,读取数据,再获取一次序列号,前后两次获取的序列号相同,则证明进行读操作时没有写操作干扰,那么这次读是有效的,返回数据,否则说明读的时侯可能数据被更改了,这次读无效,重新做读操作。 大家可能有个疑问:读xtime的时候数据可能被更改吗?难度读操作不是原子性的吗?这是因为xtime是64位的,对于32位机器是需要分两次读的,而64位机器不会产生这个并发的问题。
2.跟系统打了一次交道,确实,用户进程必须进入内核态才能访问系统资源,但是,new一个对象,分配内存也属于系统调用,也要进内核态跟系统打交道,难道只是读一下系统的墙上时间,会比移动内存指针,初始化内存的耗时还要高100倍吗?匪夷所思
3.至于所谓的测试记录,给大家看一下他的测试代码:
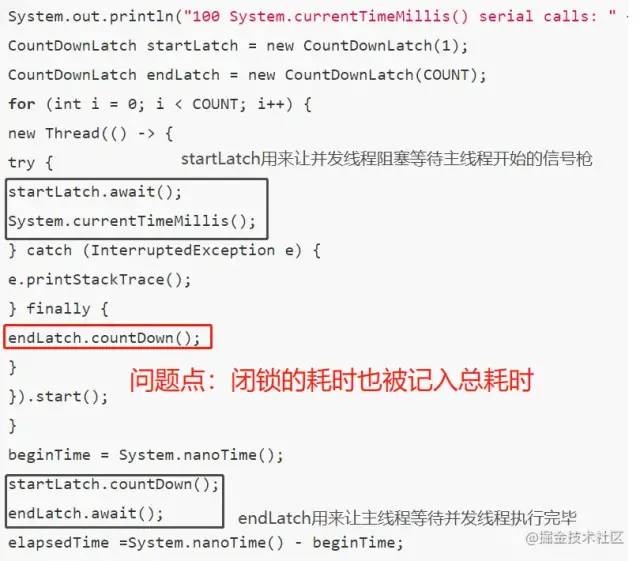
long begin = System.nanoTime();//单次调用System.currrentTimeMillis()long end = System.nanoTime();sum += end - begin;
记录每次调用的总耗时,这种方法虽然会把System.nanoTime()也算进总耗时里,但因为不论并发测试还是单线程测试都会记录System.nanoTime(),不会导致测试的不公平
数据说话,System.currentTimeMillis的性能没有问题
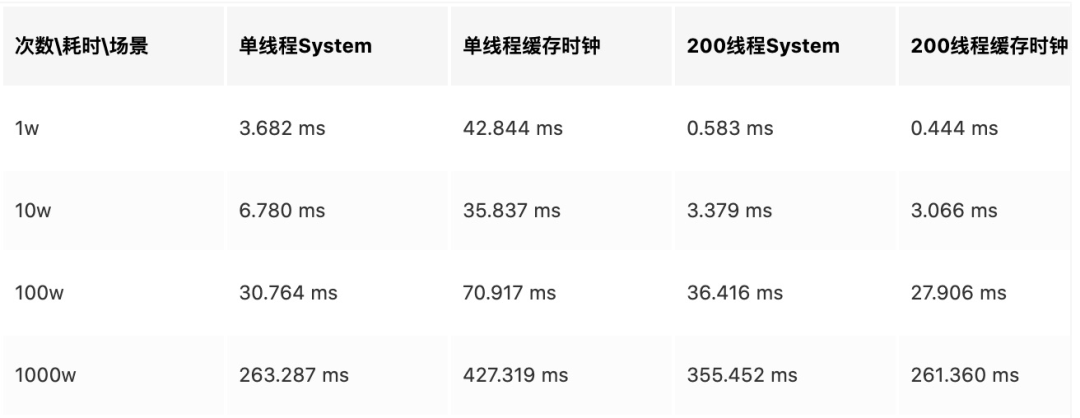
System代表 System.currentTimeMillis
使用JMH(Java基准测试框架)的测试结果

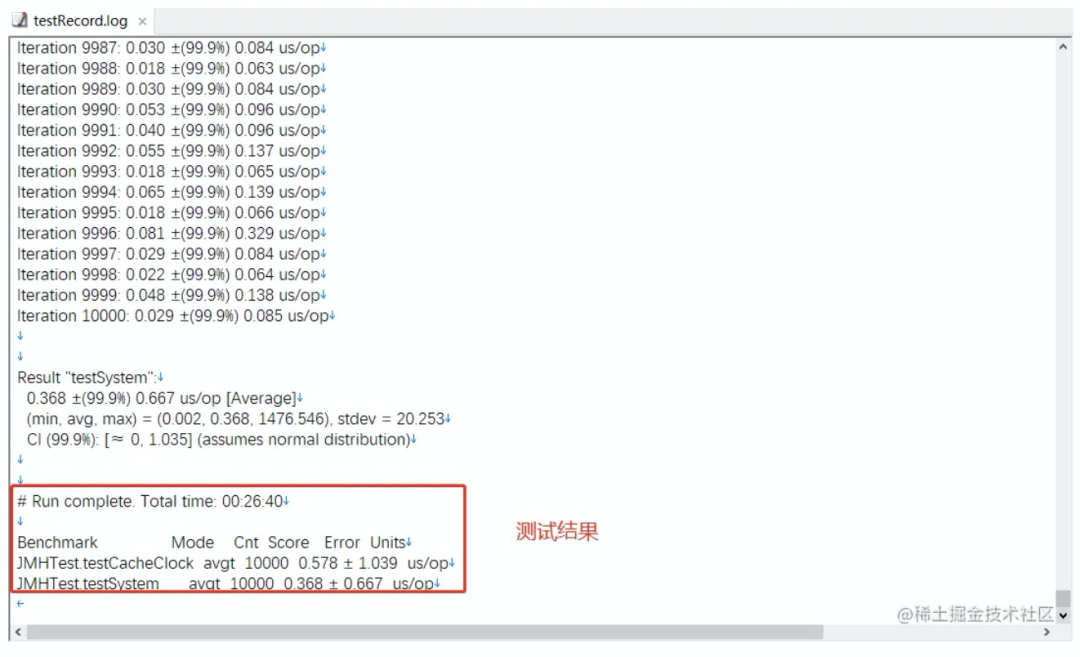
测试结果分析
可以看到System.currentTimeMillis并发性能并不算差,在次数较少(短期并发调用)的情况下甚至比单线程要强很多,而在单线程调用时效率也要比缓存时钟要高一倍左右。实际环境中几乎是达不到上述测试中的多线程长时间并发调用System.currentTimeMillis这样的情况的,因而我认为没有必要对System.currentTimeMillis做所谓的“优化”。
这里没有做“new一个对象”的测试,是因为并不是代码里写了new Object(),JVM就会真的会给你在堆内存里new一个对象。这是JVM的一个编译优化——逃逸分析:先分析要创建的对象的作用域,如果这个对象只在一个method里有效(局部变量对象),则属于未 方法逃逸,不去实际创建对象,而是你在method里调了对象的哪个方法,就把这个方法的代码块内联进来。只在线程内有效则属于未 线程逃逸,会创建对象,但会自动消除我们做的无用的同步措施。
最后
想要学习JMH,请跟着GitHub官方文档走,别人的博客可能跑不通就搬上去了,笔者也是刚刚踩过了这个坑
测试代码:
public class CurrentTimeMillisTest {public static void main(String[] args) {int num = 10000000;System.out.print("单线程"+num+"次System.currentTimeMillis调用总耗时:");System.out.println(singleThreadTest(() -> {long l = System.currentTimeMillis();},num));System.out.print("单线程"+num+"次CacheClock.currentTimeMillis调用总耗时:");System.out.println(singleThreadTest(() -> {long l = CacheClock.currentTimeMillis();},num));System.out.print("并发"+num+"次System.currentTimeMillis调用总耗时:");System.out.println(concurrentTest(() -> {long l = System.currentTimeMillis();},num));System.out.print("并发"+num+"次CacheClock.currentTimeMillis调用总耗时:");System.out.println(concurrentTest(() -> {long l = CacheClock.currentTimeMillis();},num));}/*** 单线程测试* @return*/private static long singleThreadTest(Runnable runnable,int num) {long sum = 0;for (int i = 0; i < num; i++) {long begin = System.nanoTime();runnable.run();long end = System.nanoTime();sum += end - begin;}return sum;}/*** 并发测试* @return*/private static long concurrentTest(Runnable runnable,int num) {ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(200,200,60, TimeUnit.SECONDS,new LinkedBlockingQueue<>(num));long[] sum = new long[]{0};//闭锁基于CAS实现,并不适合当前的计算密集型场景,可能导致等待时间较长CountDownLatch countDownLatch = new CountDownLatch(num);for (int i = 0; i < num; i++) {threadPoolExecutor.submit(() -> {long begin = System.nanoTime();runnable.run();long end = System.nanoTime();//计算复杂型场景更适合使用悲观锁synchronized(CurrentTimeMillisTest.class) {sum[0] += end - begin;}countDownLatch.countDown();});}try {countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}return sum[0];}/*** 缓存时钟,缓存System.currentTimeMillis()的值,每隔20ms更新一次*/public static class CacheClock{//定时任务调度线程池private static ScheduledExecutorService timer = new ScheduledThreadPoolExecutor(1);//毫秒缓存private static volatile long timeMilis;static {//每秒更新毫秒缓存timer.scheduleAtFixedRate(new Runnable() {@Overridepublic void run() {timeMilis = System.currentTimeMillis();}},0,1000,TimeUnit.MILLISECONDS);}public static long currentTimeMillis() {return timeMilis;}}}
使用JMH的测试代码:
(Mode.AverageTime)(TimeUnit.MICROSECONDS)//120轮预热,充分利用JIT的编译优化技术(iterations = 120,time = 1,timeUnit = TimeUnit.MILLISECONDS)(time = 1,timeUnit = TimeUnit.MICROSECONDS)//线程数:CPU*2(计算复杂型,也有CPU+1的说法)(8)(1)(Scope.Benchmark)public class JMHTest {public static void main(String[] args) throws RunnerException {testNTime(10000);}private static void testNTime(int num) throws RunnerException {Options options = new OptionsBuilder().include(JMHTest.class.getSimpleName()).measurementIterations(num).output("E://testRecord.log").build();new Runner(options).run();}/*** System.currentMillisTime测试* @return 将结果返回是为了防止死码消除(编译器将 无引用的变量 当成无用代码优化掉)*/public long testSystem() {return System.currentTimeMillis();}/*** 缓存时钟测试* @return*/public long testCacheClock() {return JMHTest.CacheClock.currentTimeMillis();}/*** 缓存时钟,缓存System.currentTimeMillis()的值,每隔1s更新一次*/public static class CacheClock{private static ScheduledExecutorService timer = new ScheduledThreadPoolExecutor(1);private static volatile long timeMilis;static {timer.scheduleAtFixedRate(new Runnable() {public void run() {timeMilis = System.currentTimeMillis();}},0,1000,TimeUnit.MILLISECONDS);}public static long currentTimeMillis() {return timeMilis;}}}
感谢您的阅读,也欢迎您发表关于这篇文章的任何建议,关注我,技术不迷茫!小编到你上高速。
正文结束
1.不认命,从10年流水线工人,到谷歌上班的程序媛,一位湖南妹子的励志故事
5.37岁程序员被裁,120天没找到工作,无奈去小公司,结果懵了...
