
【数据竞赛】kaggle竞赛宝典-样本组织篇!
样本筛选、样本组织之样本组织部分
1. kaggle竞赛宝典-竞赛框架篇!
4.1 kaggle竞赛宝典-样本筛选篇!

样本组织,乍一看这个词可能会有些许陌生,我们举一个销量预估的例子,就很容易理解了:
我们希望预测未来两周商店每一天的商品销量,这样可以方便商家进货,降低预估不准带来的货物囤积或者缺货供应不足而带来的损失,现在呢,我们的商家有着历史上过去两年每一天的各个商品的销量信息,那么该如何建模呢?
因为我们无法拿到除了星期节假日等信息外无法获取更多的未来两周的信息,那么这个时候我们就只能基于过往预测将来。这个时候数据样本的组织就会显得非常重要。我们需要思考标签数据如何进行构建,特征从哪些数据中进行构建。
这个时候大家再看欺诈反欺诈,图像分类,文本分类等的问题,就会发现这两类问题存在非常大的区别,后者的样本和数据已经准备就绪了,我们不需要再去思考标签如何进行构建,原始特征数据如何设计等问题。
涉及到样本组织的问题最为常见的就是与时间序列建模相关的问题,例如各大电商或者视频网站的搜索与推荐等问题,商店的销量预测,股价的预测等。那么如何进行样本的组织呢?
1. 基于最小单位的滑动建模
什么是最小单位呢?此处我们将其与预测问题相关联:
如果我们的预测问题是预测未来N天商店每一天的销量,那么这边最小的单位就是1天的销量; 如果我们的预测问题是预测未来N个月店铺每个月的销售额,那么这边最小的单位就是1个月的销售额; 如果我们的预测问题是预测未来N个小时每个小时的人流量,那么这部最小单位就是1个小时的人流量;
也就是说我们把给定的问题划分为了N个小问题,这样我们每次建模的时候就仅仅只需要拿出最小单位的数据来当做标签。例如,我们预测未来N天的每一天的销量,下面每个小的圆圈表示一天的情况,我们再预测未来第二天的销量的时候,样本的组织形式就可以按照下面的形式进行:
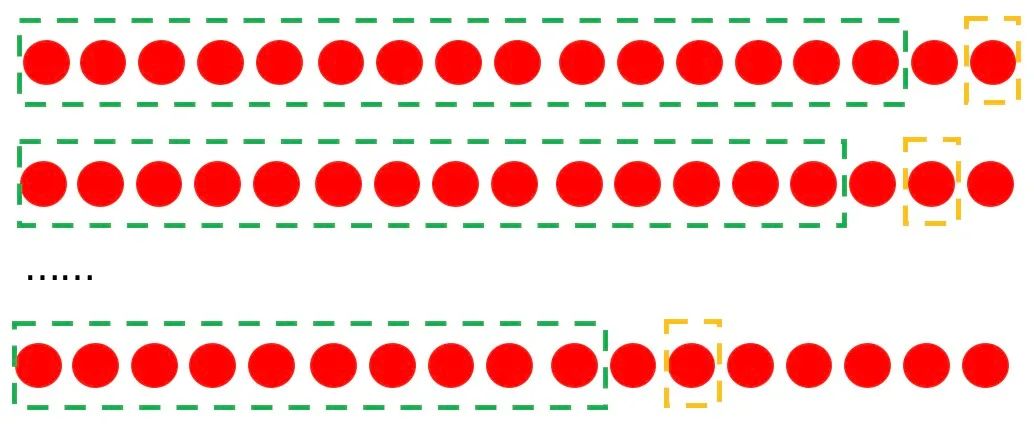
使用第的数据作为标签,使用的数据进行特征的构建; 使用第的数据作为标签,使用的数据进行特征的构建; 使用第的数据作为标签,使用的数据进行特征的构建; 依次类推;
这种建模是非常通用的,基本所有的问题都可以按此类方式进行建模。但问题也较为明显,我们需要构建多个模型进行训练和预测,会非常耗时。
2. 基于测试组的滑动建模
什么是测试组?我们举几个例子:
如果我们的预测问题是预测未来N天商店每一天的销量,那么这边测试组就是N天商店每一天的销量; 如果我们的预测问题是预测未来N个月店铺每个月的销售额,那么这边测试组就是N个月的每个月销售额; 如果我们的预测问题是预测未来N个小时每个小时的人流量,那么这部测试组就是N个小时每个小时人流量;
和基于最小单位的滑动建模不同,我们把给定的问题划分为了一个问题,如下图所示,我们预测未来3天的每一天的销量,下面每个小的圆圈表示一天的情况,我们再预测未来第N+1到第N+3天的每一天销量的时候,样本的组织形式就可以按照下面的形式进行:
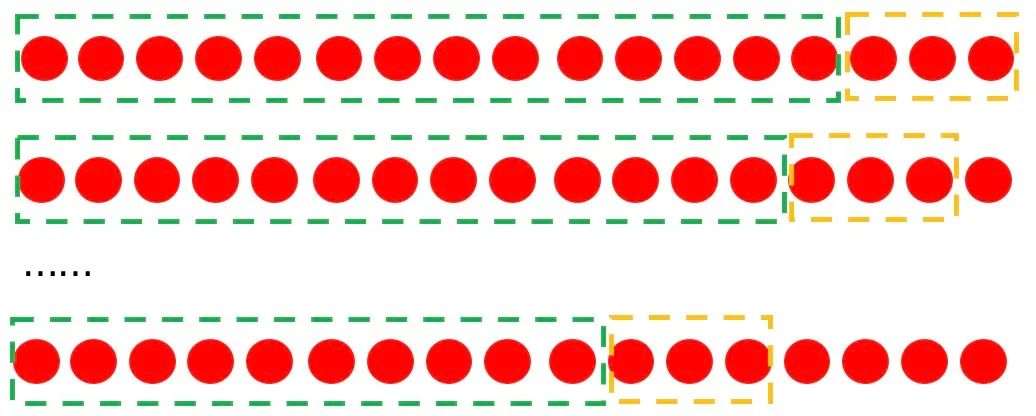
使用第天的数据作为标签,使用的数据进行特征的构建; 使用第天的数据作为标签,使用的数据进行特征的构建; 使用第的数据作为标签,使用的数据进行特征的构建; 依次类推;
这种建模也是非常通用的,基本所有的问题也都可以按此类方式进行建模。这么做我们只需要训练一个模型,相较于基于最小单位的滑动建模,这种样本组织的方式会更为通用一些,但是也存在些许问题,因为我们每次训练的样本会成倍变多,所以需要耗费更多的存储资源。
3. 基于周期形式的建模
上面两种形式的建模很多时候可以拿到不错的效果,但也存在一些问题,它们都忽略了周期性,比如我们预测的是本周三到下周三每天商店的销量,而我们在使用上面的方式进行样本组织的时候则往往会很随意的将某个周四到下个周四的数据当做标签去训练,这么做在预测的时候会带来较差的效果,尤其是在数据集的周期性较为显著的情况下。那么这个时候,我们基于周期形式的建模则往往可以帮助我们解决此类问题。
如下图所示,我们预测未来一周中每一天的销量,下面每个小的圆圈表示一天的情况,我们再预测未来第N+1到第N+7天的每一天销量的时候,样本的组织形式就可以按照下面的形式进行:
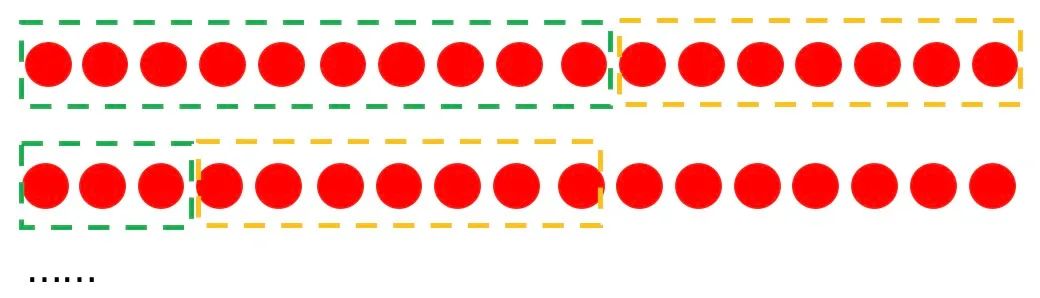
使用第天的数据作为标签,使用的数据进行特征的构建; 使用第天的数据作为标签,使用的数据进行特征的构建; 使用第的数据作为标签,使用的数据进行特征的构建; 依次类推;
这种建模可以很好地考数据集合中存在的周期性,在过往的诸多竞赛中也都取得了不俗的效果,比上面的两种策略都要好出很多,在天池的地铁赛建模中这种样本组织方式也取得了不俗的效果。
大家也发现了,基于周期形式的建模也可以融入基于最小单位的滑动建模以及基于测试组的滑动建模这两种样本组织的思想,形成两种新的样本组织形式。
4. 其它注意事项
大家如果仔细阅读过往几年的相关的涉及到样本组织的竞赛就可以发现,基本90%左右的获奖方案都可以划分为上面介绍的三种形式中的某一种或者几种的组合。此处给出一些需要注意的事项或者上分的细节。
一定要考虑周期性!例如预测未来一周每个小时的地铁流量,那么建模的时候最好是做好标签的对应,预测星期三早上8点的地铁流量,那么建模的时候将每周三早上8点的数据作为标签;
尽可能不浪费数据:有的时候我们的任务是预测未来8天的销量,那么建模的时候我们会习惯性地以7天为一个周期进行建模,有的时候我们发现训练集最后6天的数据无法形成一个周期,这个时候就会将这些数据丢弃,这么做就浪费了数据,这个时候可以将最后6天也作为标签,不需要追求完整的一周数据;
未来数据也并不是全都不可以获取:样本组织的时候,我们都习惯性地尽可能不考虑未来的数据,但诸如星期,节假日等信息都是非常明确的,还有距离当前的时间等信息都非常有价值;
在涉及到时间相关的问题中,样本组织的好坏对于模型带来的影响是巨大的,本小节我们介绍了样本组织的三种常见的实用的样本组织策略,以及很多需要注意的细节。
往期精彩回顾
本站qq群704220115,加入微信群请扫码: