
三天刷完《深入JVM虚拟机 第三版》是什么感觉
好久没有写过原创了,这篇是2021的第一篇原创,最近也比较忙,项目上线,需求有非常的赶,经历了一次C端、pc端、B端三端从需求到上线不到一个月的时间,现在c端也在试运营的期间,项目上线后就稍微没那么忙,bug比较少就会轻松一点,所以又开始自己的原创之路了。
今天分享一个最近刷完的一本书《深入JVM虚拟机 第三版》,一共花了三天的时间刷完,我相信应该很多人还没看过,毕竟七百多页,坚持看完真不容易,在这里分享一下自己刷完的一些经验,以及怎么去刷这本书。
其实在刷这本书之前其实对于这本书的很多内容都已经学过了,所以再来刷这本书算是知识点的回顾吧,看的也比较快,更有目的性,在此之前对于JVM的学习,我还专门的做了自己的学习和总结了自己的思维导图:
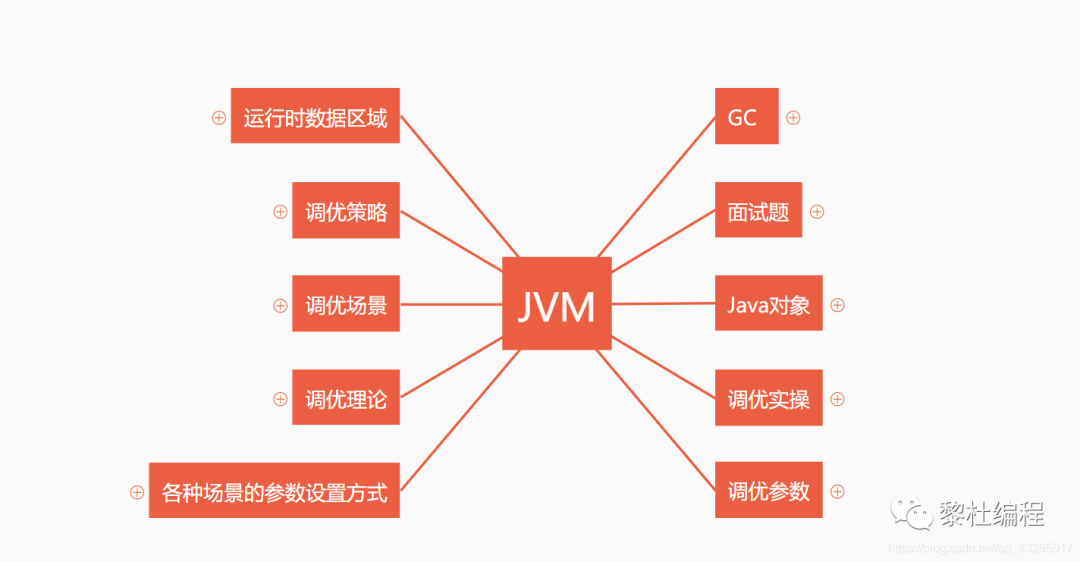
我个人的自我学习和总结都是围着调优的目的去的,所以再刷这本书的目的就是很简单:让自己对JVM的调优有更深的理解。
这个思维导图也积累了非常久,大概一年多的时间吧,我还记得我第一看 《深入JVM虚拟机》 的时候,都是蒙蒙的,第一次也是没有看完。
后来因为工作需要零零散散的学了很多关于JVM的知识点,并且把它记录下来,这就成了我最后的这个思维导图,我感觉对于调优方面的话算是比较全的了。
下面我们开始我们的刷书之旅,先来看看这本书的总的目录,一共五大部分,首先第一大部门直接可以略过,是不是贼开心,一秒间就少了一大部分:
还有就是第五部分,因为这部分属于并发编程的内容,而且里面的内容基本我以前的原创博文都写过,所以这部分的内容我是之间花了一小时的时间看完。
这部分内容其实可以不用看的,在《并发编程实战》这本书里面都会有,我下一本就是打算刷《并发编程实战》,大家也可以直接略过,这不又少了一部分。
还有就是第四部分,这部分应该是选看,我个人主要关注的是即时编译器,因为即时编译器还是挺重要的,有些面试也会被问到,其他部分我都是草草的看一下大致的内容,也并不是自己想要的,因为你去看,你也记不住,并且实际中也用不到,至少是现在阶段用不到,面试被问几乎为0。

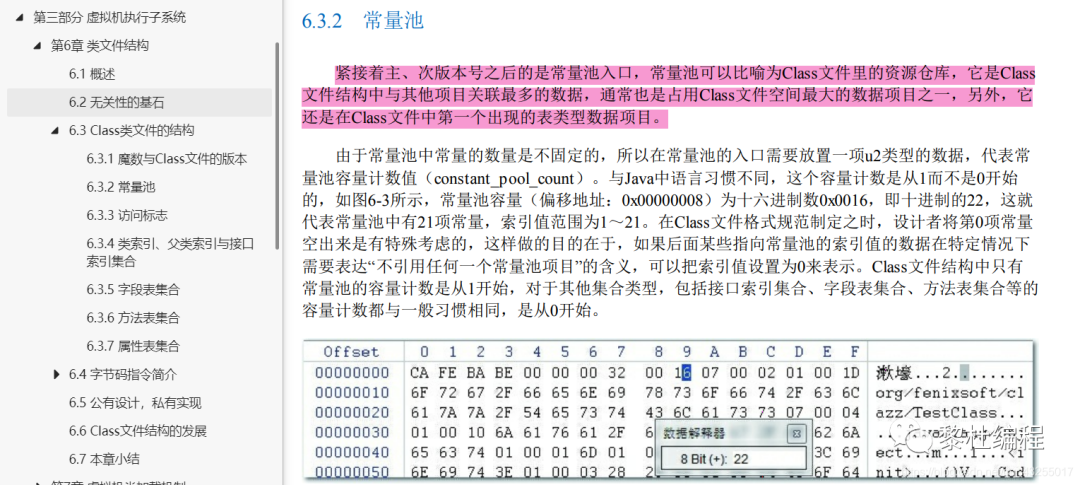
还有就是第三部分,第三部分也是选看,例如第三部分的第六章,他讲的是一个class文件的结构,,从二进制给你讲起,你记得住吗,完全记不住啊,还有各种字节码指令,这不影响你看书的心情和信心嘛。

举个例子,下图是第三部分第六章的内容,他会带你一个一个去看class文件,每一个位置分别表示什么意思,你觉得你看完这个你能记住多少,不出一天全归零,所以这部分直接就可以略过。
但是第三部分的类加载子系统就是非常重要的,包括里面的类加载过程,典型的三层类加载器、自定义类加载器、双亲委派机制,这是我们需要关注的,我之前面试字节的时候,一面就被问到类加载过程以及双亲委派机制,这个肯定也是重点。

但是,如果大家伙的目和我的目的一样的话关注点是在调优,其实你的重点就是在第二部分,这部分是要你摸透的。
接下来,我们来看第二部分就是JVM的内存管理,也就是内存模型、运行时数据区的内容,还有就是用于观察JVM内存的监控工具,其实这部分的内存模型应该是很多技术博主,都写过的博文,所以感觉大家看这部分内容应该算是只是的回顾了:

第二章内容重点是讲解Java的运行时数据区、Java对象、OOM异常,其中运行时数据区大家都很熟悉了,就是这几部分:
程序计数器 Java虚拟机栈 本地方法栈 Java堆 方法区 运行时常量池 直接内存
这里要掌握的就是这几个区域的含义,哪些是线程私有的,哪些是线程共有的,哪些会导致OOM异常出现,带着这几个问题去看基本没什么太大问题。
直接内存可能是有些人会比较陌生,直接内存并不是虚拟机的一部分,他是本地内存,按照常理来说他的大小和出现OOM问题之和本地内存有关,你也可以通过 -XX:MaxDirectMemorySize 参数来设置它的大小。
与这部分内存有关系的Java框架之一就是Netty,因为Netty的底层使用的是NIO,是给予通道和缓冲区的IO方式,它通过一个DirectByteBuffer 对象来对这块内存进行操作。

接下来就是对象的创建、对象内存布局、对象的访问三部分,神奇的Java是怎么通过一个new关键字,把对象创建出来的,在对象的创建部分,主要涉及到这几个概念:指针碰撞、本地线程分配缓冲(Thread Local AllocationBuffer,TLAB)。
对象是怎么分配内存的?怎么避免多线程时内存资源的争抢?在哪里分配内存(堆、栈)?这块的内容基本就是围绕这几个问题讲解。
对象创建出来后并且分配内存后,对象在内存中又是怎么布局的,我相信大家可能之前看过一篇文章说:XX大厂XX面,面试官:你知道Java中对象有多大吗?
一个对象分为几部分(对象头(Header)、实例 数据(Instance Data)和对齐填充(Padding)),以及对象头(Mark Word)里面又包含那些内容等等诸如此类的问题,你都可以这部分找到答案。
最后就是对象的访问:句柄、直接指针。这两种方式有什么区别?分别有什么缺点和优点?搞懂这几个问题,就算是掌握了90%以上了。
以上的内容都是偏理论的,理论总是为实战服务的,后面的OOM异常就是偏实战的,前面介绍的几个运行时数据区除了程序计数器不会出现OOM,其他的部分都有可能会出现OOM。
而除了程序计数器不用考虑外(以下调优可以直接忽略程序计数器),在JVM中Java堆是调优的最重要也是最难的一部分,基本上JVM中的调优参数复杂的都是偏向于Java堆,对于除了Java堆其它的运行时数据期出现OOM的解决办法是啥?最有效的办法就是适当的增大内存。
而Java堆的调优就不是偏偏的增大内存那么简单,有时Java堆增大堆存,反而会适得其反,因为虽然内存大了,可能新生代的可分配的对象数量也增多了,但是单次GC的回收时间也变得长了,这样会导致系统卡顿时间增长。
对于那些用户交互时间频繁,要求响应时间短的应用,就不能接受了,可能老板就是找你:兔崽子,上次是不是你调优的JVM,现在卡顿的时间又更长了,用户每天投诉,你今晚必须搞定,不然明天别来了。
所以Java堆也是调优一块的重点和难点,首先在这部分先了解和熟悉分别各个区域出现OOM异常后,打印出来的堆栈信息一般都是怎么样的,比如堆OOM就如下所示:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid3404.hprof ...
Heap dump file created [22045981 bytes in 0.663 secs]
在堆栈信息中都能看到“Java heap space”这个名称,还有就是那些场景会导致这几部分的内存溢出呢?这个也是比较重要的,比如递归深度过大、方法过长,程序中出现大对象,内存泄露,线程池数量设置不合理,过度使用代理、常量数量过多过大、Class信息过多等都会分别导致那些区域OOM呢?
其实对于调优之前还有要说清楚的就是,可能百分之七八十的问题,都可以通过代码优化来解决,比如方法过长,方法拆一下不就行了嘛,出现大对象,创建小一点的对象不就行了嘛。
但是,有时候有些问题你就有可能忽略掉,比如大对象(有可能是同一时间内多对象),尽管你在开发中都非常的小心翼翼了,对象已经控制的非常小了,在生产中流量一上来的就出现OOM了,只有生产的流量才有可能验证你的某一些被忽略的功能。
举个例子,在PC端都有会有一个导出的功能,有当前页的导出以及全部的导出,特别是这个全部的导出,数据量小的时候就没啥问题,要是数据量一大,以及流量一上来,那同一时间内创建的Excell对象就非常的多,一不小心就出现OOM了。
再比如,面向用户的C端首页,一般C端首页为了提高用户的体验度都会进行缓存,那么当缓存的数量过大,同一时间从缓存里面获取的对象就会过多或者对象过大的问题。
对于这部分的内容,我之前的思维导图,也是做了非常详细的总结,以下只是其中的一部分,大家可以作为参看,对于大家思考也是非常重要的。

接下来第三章就是围绕着GC来讲解,针对调优的区域就是Java堆,包括怎么判断对象是否存活(引用计数法、可达性分析算法),三种基本的垃圾收集算法(标记-清楚、复制算法、标记-整理),分代模型理论(新生代、老年代),以及常用的经典垃圾收集器、搭配,适用场景。搞懂这些问题,你就无敌了,这部分的内容你就吃透了

其中经典垃圾收集器大家是比较陌生的,其他部分像垃圾收集算法、分代模型理论、判断对象是否存活,很多技术博主都有写过,垃圾收集算法我之前也写过一篇原创,大家可以参考一下。
我们重点来关注一下垃圾收集器,随着jdk的不断发展,版本的不断升级,服务器由单核演变多核,内存的变大,垃圾收集器也变得越来越智能,每种垃圾收集器都有自己的适用场景。
这几种垃圾收集器比较常见的搭配如下图所示:
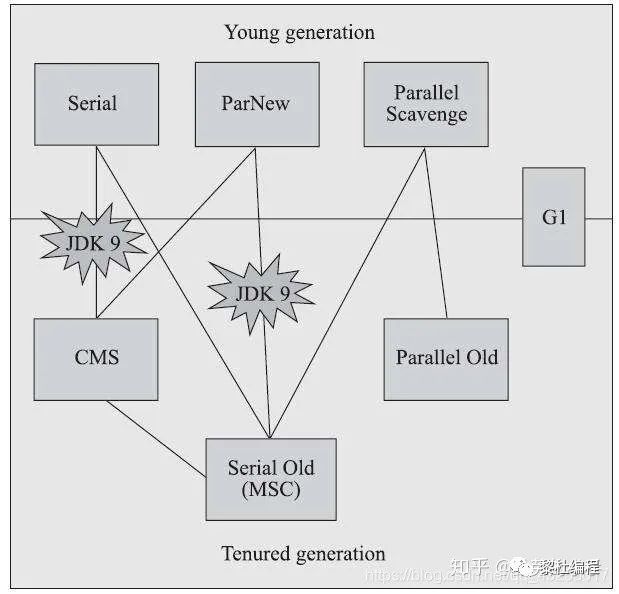
我个人记忆比较深的搭配就是:
Serial和Serial Old PS和PO ParNew和CMS G1
每种垃圾收集器都有自己的使用场景,优点和缺点,所以再看这部分的内容就带着这几个问题去看就行了:
年轻代和老年代分别的垃圾收集器是什么? 每种垃圾收集器的优点和缺点? 每种垃圾收集器的使用场景? 每种垃圾收集器的原理? 每种垃圾收集器的JVM的相关设置参数是啥?
把这几个问题搞懂基本也就摸透了,比如在适用于单核时代的Serial收集器它的主要问题一个就是造成了STW的问题,以及单线程的垃圾回收效率问题,但是对于单核的服务器,它无疑是最佳的选择。
以及后面发展到多线程时代PS和PO,由原来的的单线程收集,现在编程了多线程收集,肯定是比原来垃圾收集的时间效率提高了,但是对于多线程又有设置回收垃圾的线程数是多少,书中都有给出建议的。
后面比较经典的就是CMS,CMS有分为四个阶段初始标记、并发标记、重新标记、并发清理。

这四个阶段的原理又是啥,那些阶段的与用户线程并发操作的,CMS又是怎么最大程度减少STW问题的,CMS一般适用于的堆大小范围是多少等等。
对于这些问题的答案相应的部分都说的明明白白的,大家可以仔细研究,后面一个就是G1,前面经典的垃圾收集器都是给予分代模型的。
但是,分代模型又是有自己存在的问题,比如经典的分代垃圾收集器相对应的都是整个堆大小的收集,随着服务器性能的提高,服务器的内存也会越来越大,现在动不动就好几个g或者10几个g的大小,那么这样就会导致单次的垃圾收集时间越来越长,停顿的时间也会相应变长,因为STW现在位置是没办法消除的,只能尽可能的减少。
这也就是后面出现了G1,G1弱化了分代理论模型的垃圾收集,改为整个堆划分为一个一个Region,每个Region都不是固定的哪一个代(新生代、老年代),在发生垃圾回收的时候,G1会对每一个Region的回收耗时做记录,这样就可以统计出要回收的成本,所以G1做到了在用户可接受的停顿时间(STW,一般100-300毫秒)的时间范围进行垃圾收集,不用针对整个堆。
以上就是G1来带来的优势,解决传统的垃圾收集器出现的问题,但是G1本身自己还存在问题,比如会产生浮动垃圾,这个是G1至今未解决的问题,还有G1在极端的情况下可能会造成系统假死的现象。
这也是为什么现在垃圾默认的垃圾收集器还不是G1的一些原因,这些问题都可以在文中找到,这部分的内容一定要细细的品,仔细的琢磨。
其中还有两款面向低延时的收集器是,我们现在阶段暂时用不到,你去看一下它使用的场景就知道了,以及适用于Java堆大小,所以大家可以忽略:

当然你有兴趣的话,也可以细细品读,毕竟是大佬写出来的东西,吸收了就都是精华。
熟悉和精通上面集中垃圾收集的原理后,下面就是实战了,我这边我在我的思维导图里面总解决常用的JVM调优参数:

当然书籍里面也有,不过比较零散,我这边基本都已经总结好了。
接下来就是实战部分包括一些场景和原则:对象内存的分配原则、大对象、长期存活的对象、对象年龄、空间的分配担保,这部分的内容也一定要细细的品,肯定是精华。

第四章的就是调优的工具了,对于工具,我自己使用的是jdk自带的VisualVM,它可以配置到idea中,并且可以安装GC插件和其他的插件,非常的方便,不过他一般是本地或者测试环境使用,像线上的工具我推荐的是使用阿里的Arthas工具,百度有一堆的教程。
还有就是比较原始的排查方法,使用linux命令,例如jps、jstat、jinfo、jmap、jstack,这部分在书上有详细的讲解:

对于这些原始命令的使用,主要有两个考点,也是两个实战点,分别是:分析cpu飙高的问题、分析OOM的问题。还有另一个就是分析内存不足的问题,这个就比较简单。
假如你都能够使用上面的原始命令和分析工具对以上问题能够自己独立分析,那你就是无敌了,调优高手啊,老板还不得花重金请你。
大家也可以参考一下我自己的思维导图,方式都差不多,大差不差,但还不完整,因为有些还没整理:

第五章部分,我感觉大家可以略过,可能是大佬的经历和我们不一样,实战的场景,很少遇见过,我是直接跳过的。
到这里要是以上的内容都吃透的话,后面的内容基本就是纯理论的东西,对你来说也不难:
第三部分就直接看虚拟机的加载机制,包括类加载过程、经典的三层加载器、自定义类加载器、双亲委派等,这些就是这部分的重点。

这部分搞懂了可以写写代码怎么去实现自己的类加载器,加载自己的类,怎么去破坏双亲委派模型,诸如此类的问题,文章里面都有讲解。
好了到这里基本我个人需要的内容已经吸收的差不多了,我就是带着调优的目的去看这本书的,这里澄清一下不是说不看的内容说写的不好,不是这样的,只是我们是带着目的去学习的,书里的内容很详细,但是并不是所有的东西都是我们需要的,至少是现阶段,我只是帮大家把我们需要的内容提取出来,然后分享自己刷这本书的目的以及经验。
限于篇幅,后面会继续分享自己对于JVM虚拟机的深入的学习和了解,有需要 《深入JVM虚拟机第三版》 电子书可以添加我微信:abc730500468,那本书重点的部分我都打上了标记,便于你们刷,以及刷的过程有技术可以相互讨论,好了我是黎杜,我们下一期见。
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。