
ShuffleNetV2:轻量级CNN网络中的桂冠
作者:叶 虎
编辑:田 旭
近来,深度CNN网络如ResNet和DenseNet,已经极大地提高了图像分类的准确度。但是除了准确度外,计算复杂度也是CNN网络要考虑的重要指标,过复杂的网络可能速度很慢,一些特定场景如无人车领域需要低延迟。另外移动端设备也需要既准确又快的小模型。为了满足这些需求,一些轻量级的CNN网络如MobileNet和ShuffleNet被提出,它们在速度和准确度之间做了很好地平衡。今天我们要讲的是ShuffleNetv2,它是旷视最近提出的ShuffleNet升级版本,并被ECCV2018收录。在同等复杂度下,ShuffleNetv2比ShuffleNet和MobileNetv2更准确。

图1:ShuffleNetv2与其它算法在不同平台下的复杂度、速度以及准确度对比
01
设计理念
目前衡量模型复杂度的一个通用指标是FLOPs,具体指的是multiply-add数量,但是这却是一个间接指标,因为它不完全等同于速度。如图1中的(c)和(d),可以看到相同FLOPs的两个模型,其速度却存在差异。这种不一致主要归结为两个原因,首先影响速度的不仅仅是FLOPs,如内存使用量(memory access cost, MAC),这不能忽略,对于GPUs来说可能会是瓶颈。另外模型的并行程度也影响速度,并行度高的模型速度相对更快。另外一个原因,模型在不同平台上的运行速度是有差异的,如GPU和ARM,而且采用不同的库也会有影响。

图2:不同模型的运行时间分解
据此,作者在特定的平台下研究ShuffleNetv1和MobileNetv2的运行时间,并结合理论与实验得到了4条实用的指导原则:
(G1)同等通道大小最小化内存访问量
对于轻量级CNN网络,常采用深度可分割卷积(depthwise separable convolutions),其中点卷积( pointwise convolution)即1x1卷积复杂度最大。这里假定输入和输出特征的通道数分别为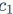 和
和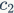 ,特征图的空间大小为
,特征图的空间大小为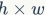 ,那么1x1卷积的FLOPs为
,那么1x1卷积的FLOPs为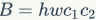 。对应的MAC为(这里假定内存足够)
。对应的MAC为(这里假定内存足够)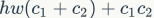 ,根据均值不等式,固定时,MAC存在下限(令
,根据均值不等式,固定时,MAC存在下限(令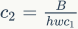 ):
):
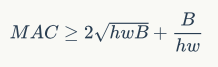
仅当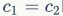 时,MAC取最小值,这个理论分析也通过实验得到证实,如表1所示,通道比为1:1时速度更快。
时,MAC取最小值,这个理论分析也通过实验得到证实,如表1所示,通道比为1:1时速度更快。
表1:G1的实验验证

(G2)过量使用组卷积会增加MAC
组卷积(group convolution)是常用的设计组件,因为它可以减少复杂度却不损失模型容量。但是这里发现,分组过多会增加MAC。对于组卷积,FLOPs为(其中是组数) ,而对应的MAC为
,而对应的MAC为 。如果固定输入
。如果固定输入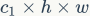 以及B,那么MAC为:
以及B,那么MAC为:
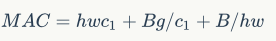
可以看到,当g增加时,MAC会同时增加。这点也通过实验证实,所以明智之举是不要使用太大g的组卷积。
(G3)网络碎片化会降低并行度
一些网络如Inception,以及Auto ML自动产生的网络NASNET-A,它们倾向于采用“多路”结构,即存在一个lock中很多不同的小卷积或者pooling,这很容易造成网络碎片化,减低模型的并行度,相应速度会慢,这也可以通过实验得到证明。
(G4)不能忽略元素级操作
对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC。这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。
上面4条指导准则总结如下:
1x1卷积进行平衡输入和输出的通道大小;
组卷积要谨慎使用,注意分组数;
避免网络的碎片化;
减少元素级运算。
02
网络结构
根据前面的4条准则,作者分析了ShuffleNetv1设计的不足,并在此基础上改进得到了ShuffleNetv2,两者模块上的对比如图3所示:

图3:ShuffleNet两个版本结构上的对比
在ShuffleNetv1的模块中,大量使用了1x1组卷积,这违背了G2原则,另外v1采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同,这违背了G1原则。同时使用过多的组,也违背了G3原则。短路连接中存在大量的元素级Add运算,这违背了G4原则。
为了改善v1的缺陷,v2版本引入了一种新的运算:channel split。具体来说,在开始时先将输入特征图在通道维度分成两个分支:通道数分别为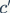 和
和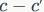 ,实际实现时
,实际实现时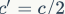 。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
对于下采样模块,不再有channel split,而是每个分支都是直接copy一份输入,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。
ShuffleNetv2的整体结构如表2所示,基本与v1类似,其中设定每个block的channel数,如0.5x,1x,可以调整模型的复杂度。
表2:ShuffleNetv2的整体结构

值得注意的一点是,v2在全局pooling之前增加了个conv5卷积,这是与v1的一个区别。最终的模型在ImageNet上的分类效果如表3所示:
表3:ShuffleNetv2在ImageNet上分类效果

可以看到,在同等条件下,ShuffleNetv2相比其他模型速度稍快,而且准确度也稍好一点。同时作者还设计了大的ShuffleNetv2网络,相比ResNet结构,其效果照样具有竞争力。
从一定程度上说,ShuffleNetv2借鉴了DenseNet网络,把shortcut结构从Add换成了Concat,这实现了特征重用。但是不同于DenseNet,v2并不是密集地concat,而且concat之后有channel shuffle以混合特征,这或许是v2即快又好的一个重要原因。
03
TensorFlow上的实现
目前ShuffleNetv2没有看到官方开源实现,这里参考tensorpack中的复现(其中Top1 acc基本接近paper),给出v2在TensorFlow上实现。我们使用TensorFlow中[tf.keras.Model来实现ShuffleNetv2。
首先我们先定义网络中最基本的单元:Conv2D->BN->ReLU和DepthwiseConv2D->BN:
class Conv2D_BN_ReLU(tf.keras.Model):
"""Conv2D -> BN -> ReLU"""
def __init__(self, channel, kernel_size=1, stride=1):
super(Conv2D_BN_ReLU, self).__init__()
self.conv = Conv2D(channel, kernel_size, strides=stride,
padding="SAME", use_bias=False)
self.bn = BatchNormalization(axis=-1, momentum=0.9, epsilon=1e-5)
self.relu = Activation("relu")
def call(self, inputs, training=True):
x = self.conv(inputs)
x = self.bn(x, training=training)
x = self.relu(x)
return x
class DepthwiseConv2D_BN(tf.keras.Model):
"""DepthwiseConv2D -> BN"""
def __init__(self, kernel_size=3, stride=1):
super(DepthwiseConv2D_BN, self).__init__()
self.dconv = DepthwiseConv2D(kernel_size, strides=stride,
depth_multiplier=1,
padding="SAME", use_bias=False)
self.bn = BatchNormalization(axis=-1, momentum=0.9, epsilon=1e-5)
def call(self, inputs, training=True):
x = self.dconv(inputs)
x = self.bn(x, training=training)对于channel shuffle,只需要通过reshape操作即可:
def channle_shuffle(inputs, group):
"""Shuffle the channel
Args:
inputs: 4D Tensor
group: int, number of groups
Returns:
Shuffled 4D Tensor
"""
in_shape = inputs.get_shape().as_list()
h, w, in_channel = in_shape[1:]
assert in_channel % group == 0
l = tf.reshape(inputs, [-1, h, w, in_channel // group, group])
l = tf.transpose(l, [0, 1, 2, 4, 3])
l = tf.reshape(l, [-1, h, w, in_channel])
return l下面,定义v2中的基本模块,先定义stride=1的模块:
class ShufflenetUnit1(tf.keras.Model):
def __init__(self, out_channel):
"""The unit of shufflenetv2 for stride=1
Args:
out_channel: int, number of channels
"""
super(ShufflenetUnit1, self).__init__()
assert out_channel % 2 == 0
self.out_channel = out_channel
self.conv1_bn_relu = Conv2D_BN_ReLU(out_channel // 2, 1, 1)
self.dconv_bn = DepthwiseConv2D_BN(3, 1)
self.conv2_bn_relu = Conv2D_BN_ReLU(out_channel // 2, 1, 1)
def call(self, inputs, training=False):
# split the channel
shortcut, x = tf.split(inputs, 2, axis=3)
x = self.conv1_bn_relu(x, training=training)
x = self.dconv_bn(x, training=training)
x = self.conv2_bn_relu(x, training=training)
x = tf.concat([shortcut, x], axis=3)
x = channle_shuffle(x, 2)
return xclass ShufflenetUnit2(tf.keras.Model):
"""The unit of shufflenetv2 for stride=2"""
def __init__(self, in_channel, out_channel):
super(ShufflenetUnit2, self).__init__()
assert out_channel % 2 == 0
self.in_channel = in_channel
self.out_channel = out_channel
self.conv1_bn_relu = Conv2D_BN_ReLU(out_channel // 2, 1, 1)
self.dconv_bn = DepthwiseConv2D_BN(3, 2)
self.conv2_bn_relu = Conv2D_BN_ReLU(out_channel - in_channel, 1, 1)
# for shortcut
self.shortcut_dconv_bn = DepthwiseConv2D_BN(3, 2)
self.shortcut_conv_bn_relu = Conv2D_BN_ReLU(in_channel, 1, 1)
def call(self, inputs, training=False):
shortcut, x = inputs, inputs
x = self.conv1_bn_relu(x, training=training)
x = self.dconv_bn(x, training=training)
x = self.conv2_bn_relu(x, training=training)
shortcut = self.shortcut_dconv_bn(shortcut, training=training)
shortcut = self.shortcut_conv_bn_relu(shortcut, training=training)
x = tf.concat([shortcut, x], axis=3)
x = channle_shuffle(x, 2)
return x根据定义的两个模块,我们可以实现stage的整合:
class ShufflenetStage(tf.keras.Model):
"""The stage of shufflenet"""
def __init__(self, in_channel, out_channel, num_blocks):
super(ShufflenetStage, self).__init__()
self.in_channel = in_channel
self.out_channel = out_channel
self.ops = []
for i in range(num_blocks):
if i == 0:
op = ShufflenetUnit2(in_channel, out_channel)
else:
op = ShufflenetUnit1(out_channel)
self.ops.append(op)
def call(self, inputs, training=False):
x = inputs
for op in self.ops:
x = op(x, training=training)
return x建立所有准备模块后,我们可以很快递地实现ShuffleNetv2,这里实现1x模型:
class ShuffleNetv2(tf.keras.Model):
"""Shufflenetv2"""
def __init__(self, num_classes, first_channel=24, channels_per_stage=(116, 232, 464)):
super(ShuffleNetv2, self).__init__()
self.num_classes = num_classes
self.conv1_bn_relu = Conv2D_BN_ReLU(first_channel, 3, 2)
self.pool1 = MaxPool2D(3, strides=2, padding="SAME")
self.stage2 = ShufflenetStage(first_channel, channels_per_stage[0], 4)
self.stage3 = ShufflenetStage(channels_per_stage[0], channels_per_stage[1], 8)
self.stage4 = ShufflenetStage(channels_per_stage[1], channels_per_stage[2], 4)
self.conv5_bn_relu = Conv2D_BN_ReLU(1024, 1, 1)
self.gap = GlobalAveragePooling2D()
self.linear = Dense(num_classes)
def call(self, inputs, training=False):
x = self.conv1_bn_relu(inputs, training=training)
x = self.pool1(x)
x = self.stage2(x, training=training)
x = self.stage3(x, training=training)
x = self.stage4(x, training=training)
x = self.conv5_bn_relu(x, training=training)
x = self.gap(x)
x = self.linear(x)
return x我从tensorpack已训练好的权重文件迁移到上面实现的模型,然后就可以测试模型效果:
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.densenet import preprocess_input, decode_predictions
img_path = './images/cat.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
inputs = tf.placeholder(tf.float32, [None, 224, 224, 3])
model = ShuffleNetv2(1000)
outputs = model(inputs, training=False)
outputs = tf.nn.softmax(outputs)
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, "./models/shufflene_v2_1.0.ckpt")
preds = sess.run(outputs, feed_dict={inputs: x})
print(decode_predictions(preds, top=3)[0])感兴趣的话,可以访问我的GitHub-xiaohu2015/DeepLearning_tutorials,欢迎star。
参考
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design.
tensorpack/examples
pretrained weights

END
往期回顾之作者叶虎
【2】七夕节最好的礼物:生成对抗网络的tensorflow实现
【3】基于深度学习的图像语义分割算法综述
机器学习算法工程师
一个用心的公众号
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助