
盘点一个Python自动化办公的实战案例(word文件处理)
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
一、前言
前几天在Python铂金交流群【Jethro Shen】问了一个Python自动化办公的问题,提问截图如下:
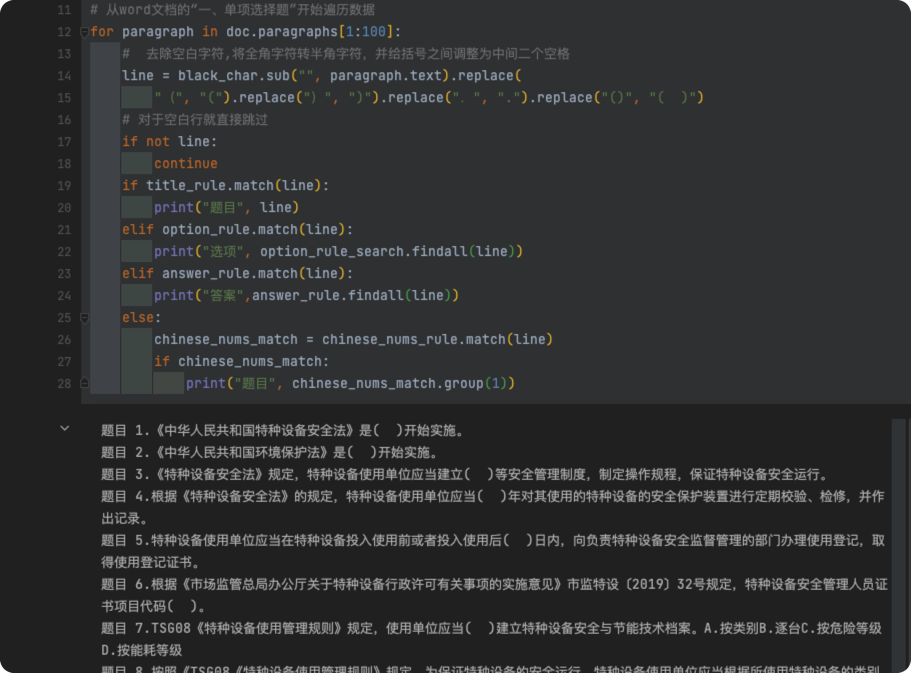
代码运行后的结果:
他预期的效果是选项和答案部分也需要显示出来,目前看上去还是没有显示出来。
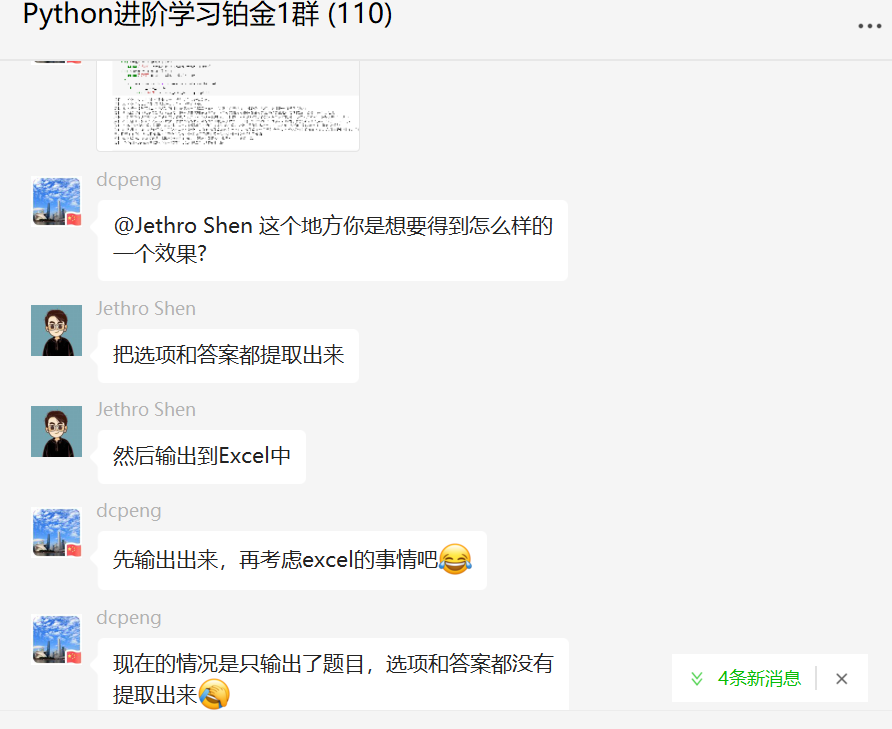
他的原始代码如下:
import re
black_char = re.compile("[\s\u3000\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\(")
title_rule = re.compile("\d+.")
option_rule = re.compile("\([ABCDEF]\)")
option_rule_search = re.compile("\([ABCDEF]\)[^(]+")
answer_rule = re.compile("\([ABCDEF]\)")
# 从word文档的“一、单项选择题”开始遍历数据
for paragraph in doc.paragraphs[1:100]:
# 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间二个空格
line = black_char.sub("", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )").replace("【", "").replace("】", "")
# 对于空白行就直接跳过
if not line:
continue
if title_rule.search(line):
print("题目", line)
elif option_rule.search(line):
print("选项", option_rule_search.findall(line))
elif answer_rule.search(line):
print("答案",answer_rule.findall(line))
else:
chinese_nums_match = chinese_nums_rule.search(line)
if chinese_nums_match:
print("题目", chinese_nums_match.group(1))
二、实现过程
这里【瑜亮老师】指出是正则表达式的问题,没匹配到,自然就出不来结果。后来【不上班能干啥!】给了一份代码,如下所示:
import re
black_char = re.compile("[\s\u3000\xa0]+")
chinese_nums_rule = re.compile("[一二三四]、(.+?)\(")
title_rule = re.compile("\d+.")
option_rule = re.compile("([A-F]\..+?)\s")
# option_rule_search = re.compile("\([A-F]\)[^(]+")
answer_rule = re.compile("【答案】([A-F])")
# 从word文档的“一、单项选择题”开始遍历数据
for paragraph in doc.paragraphs[1:100]:
# 去除空白字符,将全角字符转半角字符,并给括号之间调整为中间二个空格
line = black_char.sub(" ", paragraph.text).replace(
"(", "(").replace(")", ")").replace(".", ".").replace("()", "( )") + " "
# 对于空白行就直接跳过
if not line:
continue
if title_rule.match(line):
print("题目", line)
elif option_rule.match(line):
print("选项", option_rule.findall(line))
if '【答案】' in line and answer_rule.search(line):
print("答案",answer_rule.findall(line))
elif answer_rule.match(line):
print("答案",answer_rule.findall(line))
else:
chinese_nums_match = chinese_nums_rule.match(line)
if chinese_nums_match:
print("题目", chinese_nums_match.group(1))
运行之后,可以得到预期发效果:

归根结底,还是正则表达式的问题。
后来【甯同学】使用 openpyxl库,也给了一份代码,如下所示:
from docx import Document
import openpyxl
wb = openpyxl.Workbook()
ws = wb.active
ws.append(['题目','选项1','选项2','选项3','选项4','答案'])
doc = Document("题库.docx")
all_runs = doc.paragraphs
rows = []
for run in all_runs[1:]:
print([run.text])
if '【答案】' in run.text:
text_list= run.text.replace('\n ','\t\t').replace('【答案】','').split('\t\t')
rows += text_list
ws.append(rows)
rows = []
continue
text_list= run.text.replace('\n ','\t\t').split('\t\t')
rows += text_list
wb.save('1.xlsx')
可以得到预期的效果,如下图所示: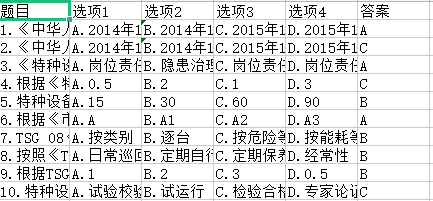
效果还是不错的!

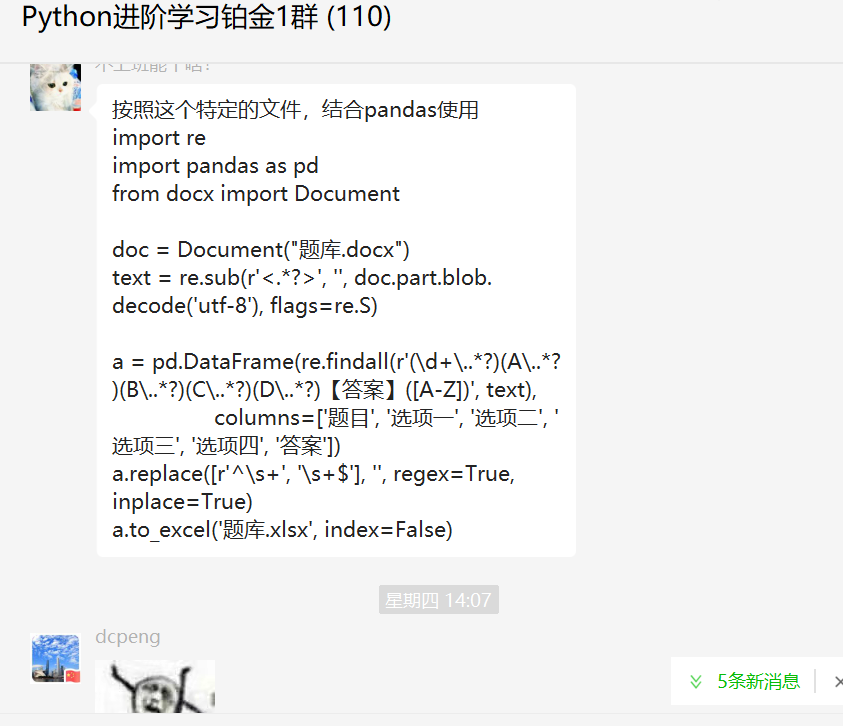
后来【不上班能干啥!】还结合Pandas给了一份代码,如下所示:
import re
import pandas as pd
from docx import Document
doc = Document("题库.docx")
text = re.sub(r'<.*?>', '', doc.part.blob.decode('utf-8'), flags=re.S)
a = pd.DataFrame(re.findall(r'(\d+\..*?)(A\..*?)(B\..*?)(C\..*?)(D\..*?)【答案】([A-Z])', text),
columns=['题目', '选项一', '选项二', '选项三', '选项四', '答案'])
a.replace([r'^\s+', '\s+$'], '', regex=True, inplace=True)
a.to_excel('题库.xlsx', index=False)
这个Pandas功力已经到炉火纯青的地步了!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python自动化办公的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【WYM】提问,感谢【dcpeng】、【瑜亮老师】、【不上班能干啥!】、【甯同学】给出的思路和代码解析,感谢【水方人子】、【D I Y】、【冫马讠成】、【猫药师Kelly】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~