
斯坦福𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩,迭代生成草图
【新智元导读】有了𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩,不是艺术家,也成艺术家。
只需随笔一画,高清画作就来了。
比如,画一个中世纪城堡,简单画个门,画条路,一座美丽的城堡出现了。

带邮箱的霍比特人房子

海洋边缘的灯塔(PS:有点像海底星空)

来自斯坦福的研究人员提出了𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩,一个能够将草图变成画作的模型。

甚至,𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩可将生成的图像,转换成完整的草图,还能为下一步的绘画提供建议。
那么,它具体是如何工作的呢?
草图,还能再编辑
现有的草图控制图像生成方法包括ControlNet、Sketch-Guided Diffusion,以及DiffSketching。
虽然现有的草图到图像方法有着很大优势,但它们有一个关键缺陷:被训练来处理完成的草图。
然而,典型的草图工作流程是一个迭代的进行中的工作!
艺术家逐步添加或删除线条,有时在深入到更精细的细节之前构建基本结构,有时在移动到另一个区域之前专注于图像的一个区域。
因此,我们需要在草图绘制过程的阶段,实现草图到图像的功能。
在Sketch-a-Sketch中,研究人员引入了一个ControlNet模型,该模型生成以部分草图为条件的图像。
有了ControlNet,Sketch-a-Sketch可以:
1)在草图过程的各个阶段生成与草图相对应的图像
2)利用这些图像生成有助于指导艺术过程的建议草图

问题:现有方法不适用于部分草图
以前的研究是在图像和完成草图的配对数据集上训练的。
在尝试根据部分草图生成图像时,这些方法会将草图视为已完成的草图。
因此草图其余部分的空白会被视为一个指标,表明图像不应包含通常与输入草图中的笔画相对应的内容。
例如,给定房子的前几条线,ControlNet无法在绘制线的区域之外生成重要的细节:


在这些草图中,与线条相对应的特征出现在生成的图像中:支撑屋顶的柱子、栏杆的顶部、门廊的底部等。
然而,在草图仅包含空白的区域,也存在大量主要的图像特征。
训练数据:通过随机删除线条制作部分草图
Photo-Sketch 是现有的最大数据集,其中包含文本描述图像,与部分完成阶段的草图配对的数据集。
然而,该数据集存在以下不足:
1)仅限于 1000 张图片的草图;
2)所有图片均为室外场景(缺乏多样性,无法生成一般的文本条件);
3)通过对现有图片进行描摹来构建(强加了笔画顺序,可能与许多艺术家的画图过程不符)。
因此,我们以编程方式构建了自己的数据集,其中包含与部分草图配对的带描述图像。
斯坦福研究人员的方法是:1)使用HED将图像转换为光栅化边缘图;2)将边缘图矢量化为笔画集合;3)随机删除部分笔画。
通过以任意顺序删除笔画,我们还能以任意顺序绘制的笔画为条件生成图像,从而适应各种草图风格。
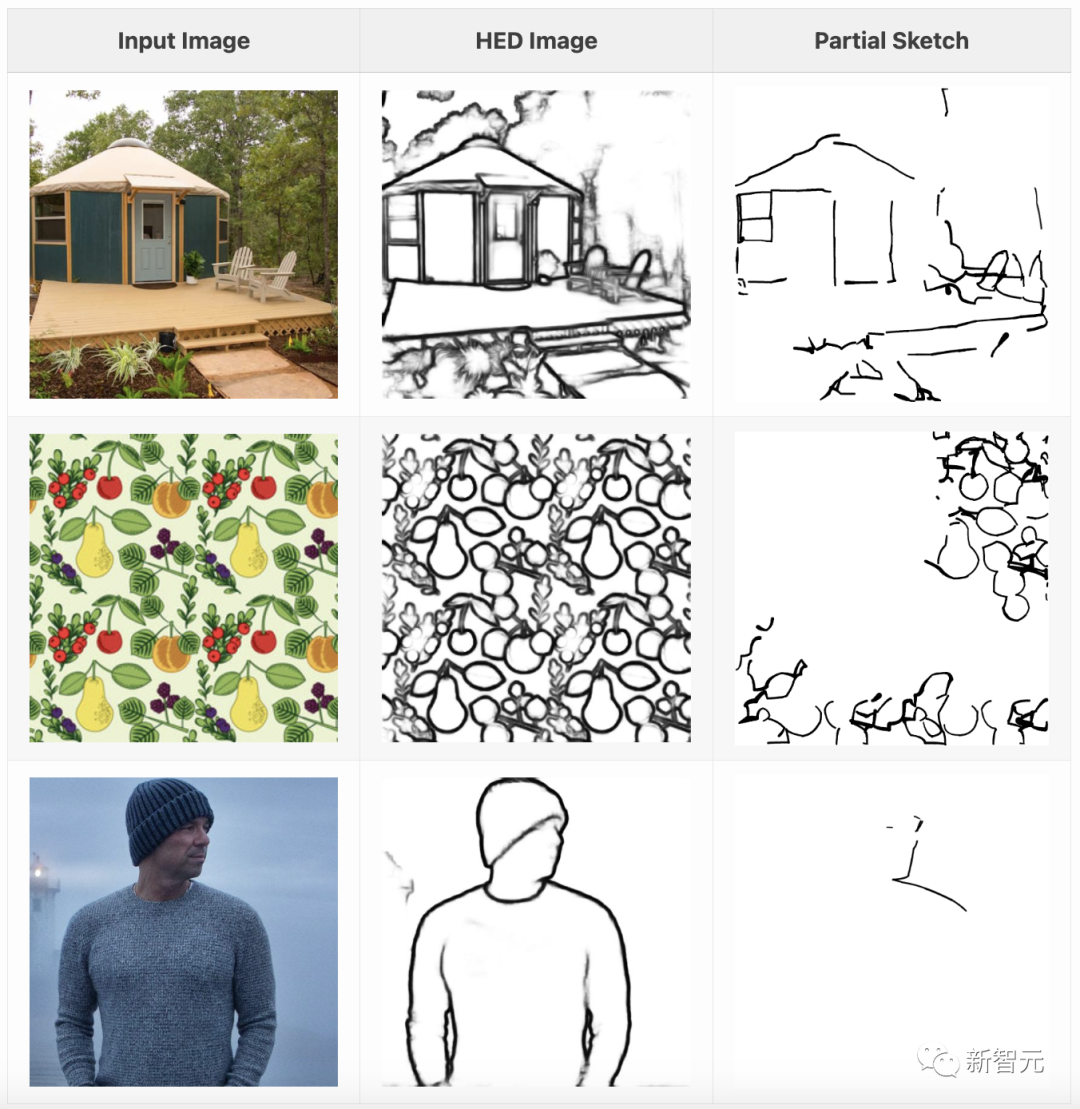
研究人员使用来自LAION Art的45000张图片构建了配对数据集,并对ControlNet模型进行了训练,以便在图片-草图配对上调节Stable Diffusion 1.5。
训练好的模型将文字说明和部分草图作为输入,并输出与可能完成的草图相对应的生成图像。
需要注意的是,通过对许多不同完整程度的随机部分草图进行训练,模型学会了将任何完整程度的草图转换成最终图像。
这就意味着,模型并不假定你绘制线条的顺序。
你可以按照任何顺序绘制线条,𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩仍会根据草图的当前状态生成图像。
生成你想要的图像
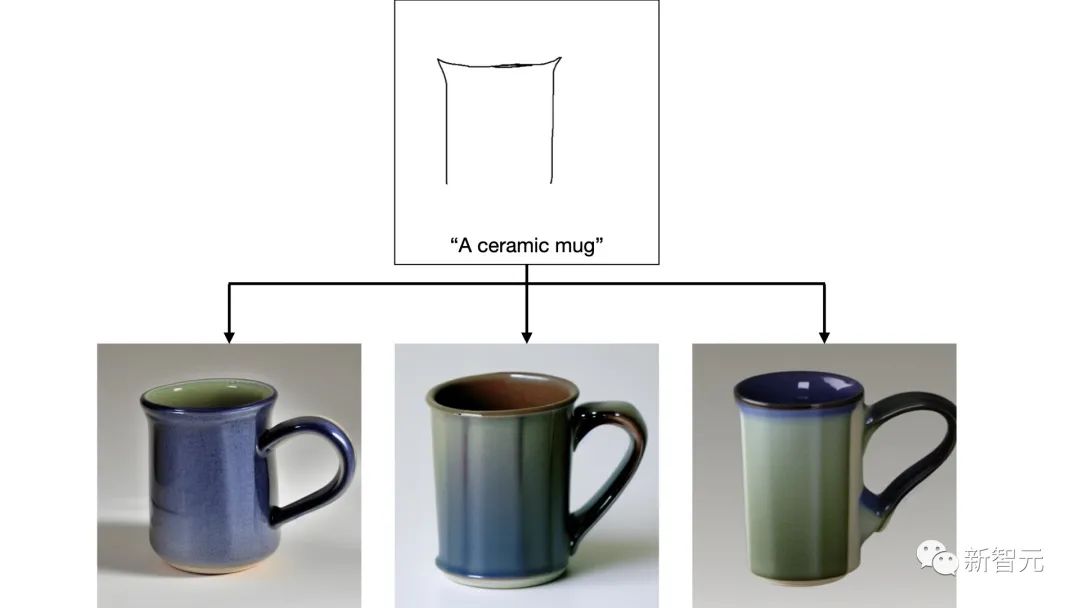
当艺术家不太确定他们想如何绘制图像的一部分时,可以根据绘制的线条生成各种图像完成。
比如,不太确定他们想如何绘制杯子的把手,所以𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩生成了3张图像:
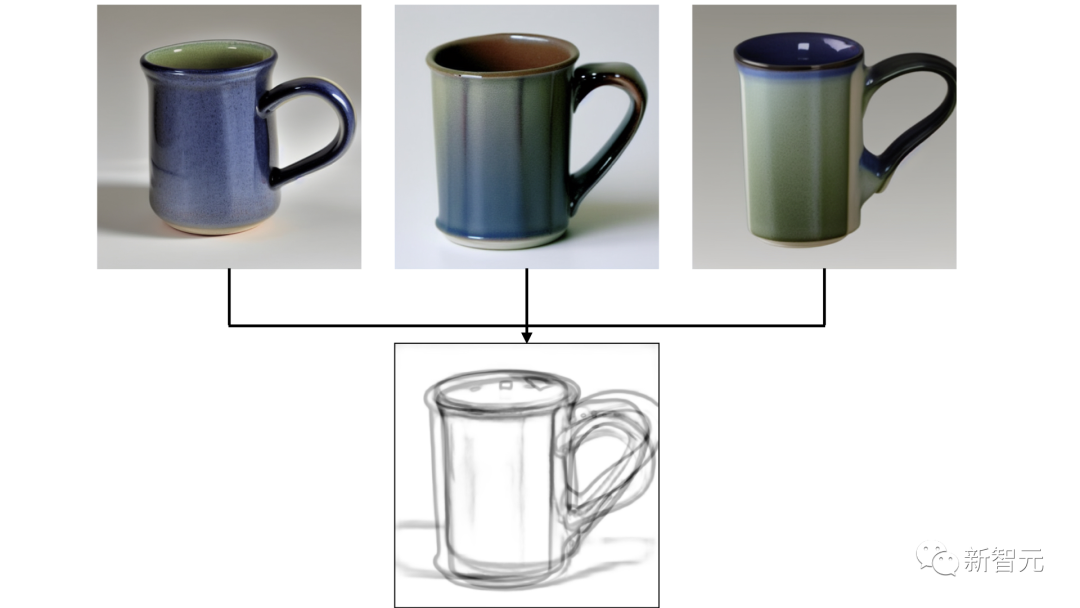
有了这些生成的图像,Sketch-a-Sketch可以为潜在的绘制线条提供建议。
通过在生成的图像上运行HED,来生成现有绘图的潜在补全,然后就可以获得建议线条的图像:
风格可控
图像说明和底层扩散骨架会对图像可视化和建议线条产生重大影响。
与其他文本控制扩散应用一样,𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩可以通过提示来修改生成图像的风格或内容。
在下面的图中,可以通过更改一个单词来控制一辆跑车的可视化风格:
提示:跑车,逼真

提示:跑车,卡通

提示:跑车,阴影

提示:跑车,生锈

之前已经看到过,在一个骨干网(Stable Diffusion 1.5)上训练过的ControlNet在该骨干网的微调版本上仍然有效。
这一特性同样适用于部分草图ControlNet模型,使Sketch-a-Sketch能够从针对特定领域进行微调的模型中生成建议。
例如,我们可以使用吉卜力扩散生成吉卜力风格的角色:

作者介绍
Vishnu Sarukkai
Vishnu Sarukkai是斯坦福大学的博士生,导师是Chris Ré和Kayvon Fatahalian。他曾在斯坦福大学获得了计算机学士学位。
他的研究兴趣包括机器学习和计算机图形学,最近的研究主要集中在可控扩散模型上。
Christopher Ré
斯坦福人工智能实验室(SAIL)、基础模型研究中心(CRFM)和机器学习小组(生物)的副教授。

Kayvon Fatahalian
Kayvon Fatahalian的团队创建了支持高级计算机图形和视频理解应用程序的计算系统(通常是高性能和并行的)。最近的研究工作包括,用于「AI训练」的虚拟环境的高性能模拟。

关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!