
90后华人教授夫妇斩获IEEE最佳论文和ACM Demo冠军!团队1年连发4篇Nature子刊
共 3515字,需浏览 8分钟
·
2021-12-23 22:03

新智元报道
新智元报道
编辑:好困 LRS
【新智元导读】由圣母大学史弋宇教授和匹兹堡大学胡京通教授领衔的90后华人伉俪,姜炜文博士与杨蕾博士两年前的研究如今修成正果,斩获IEEE TCAD的最佳和DAC的University Demo双项冠军,可以说是理论和实践两开花!并且这篇论文也是开创了NAS的一个新领域,拉开了神经网络与硬件协同搜索的新时代。
开发AI模型就像一个堆积木的过程,通过组合各种可以用到的网络层来找到一个性能更强的网络。
后来研究人员发现这个搜索过程其实也可以自动化完成。
神经架构搜索(Neural Architecture Search,NAS)的出现极大推进了AI向各行业进军的速度,甚至在某些任务上已经能够媲美人类专家了,并且还能发现一些人类之前未曾提出过的网络结构,可以说是极大提升了神经网络的使用和设计效率。
但神经网络的训练、推理和部署从来都不只是软件工程师的事,哪有什么岁月静好,只是各位硬件设计师一直在默默负重前行。

训练好的神经网络模型有可能部署在各种各样的硬件架构上,而硬件的架构反过来也会影响着模型的性能、吞吐量等等。
两年前,就算考虑了硬件的NAS研究,也都只是在固定硬件架构的情况下琢磨如何提高性能,直到这篇论文的出现。

https://arxiv.org/pdf/1907.04650.pdf
这篇论文提出了一个全新的NAS框架,同时考虑了神经架构搜索空间(neural architecture search space)和硬件设计空间(hard design space)来找到和硬件匹配的最佳网络架构,这种方式能够最大限度地提高模型的性能和运行效率。
在ImageNet上的实验也证明了采用协同搜索的NAS可以在精度不变的情况下,吞吐量提高35.24%,能量效率提高54.05%。

论文的成果经过两年时间的检验后,最近获得两项大奖。一项是代表理论的TCAD最佳论文奖,另一项是代表应用研究的University Demo冠军,击败了来自MIT, University of Virginia等10所高校。可以说是文体两开花了。
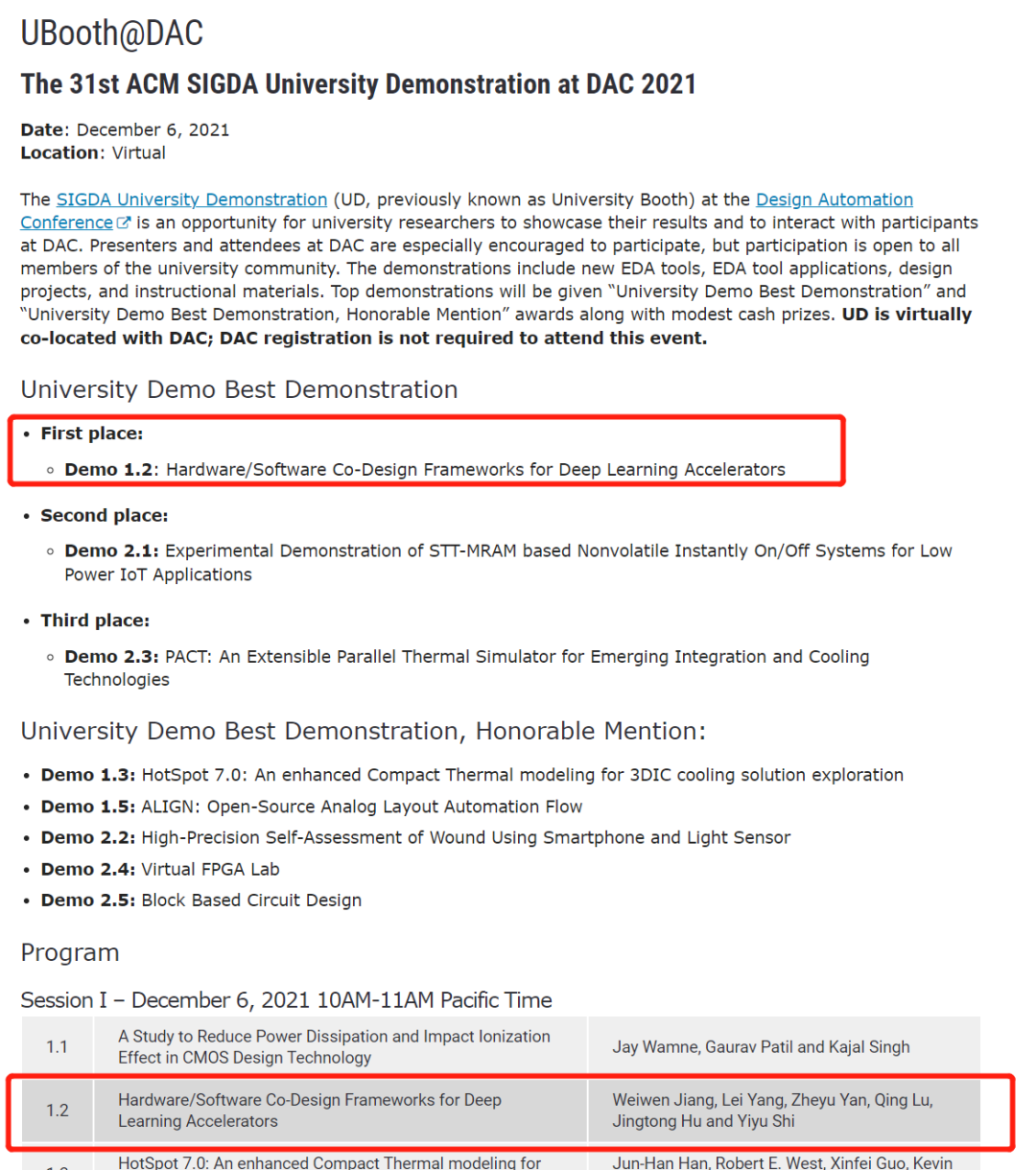
论文由重庆大学博士伉俪姜炜文和杨蕾在圣母大学史弋宇教授和匹兹堡大学胡京通教授指导下完成。

第一作者姜炜文博士是乔治梅森大学助理教授,除了NAS领域,他还建立了第一个神经网络/量子计算协同设计框架QuantumFlow,证明了在量子计算机上设计神经网络的量子优势,2021年也是一口气在Nature子刊上发了三篇论文。
对于此次拿奖,姜炜文博士表示:「该获奖工作是我们一些列软硬协同神经网络加速工作的基础,这些工作先后在DAC,CODES+ISSS,ASP-DAC会议上获得多次提名最佳论文,这次终于修成正果。」
杨蕾博士是新墨西哥大学助理教授,目前主要从事系统级自动化机器学习应用的工作。
史弋宇博士于2021年在圣母大学晋升为终身正教授,其带领团队在过去1年发表了4篇Nature子刊。
胡京通博士于2020年在匹兹堡大学晋升终身副教授,并于2021年获得William Kepler Whiteford Faculty Fellow。
史弋宇教授表示:「我们软硬协同神经网络加速的工作除了TCAD的best paper以外,具体在实际产品上的应用还在DAC的University Demo拿了first place。希望这方面接下来还能有所突破。」
经典回顾
尽管NAS在各种任务,包括图像分类、图像分割和语言建模的模型架构设计中取得了巨大成功,但除了准确性之外,我们也应该考虑推理的时间性能(如延迟或吞吐量)。
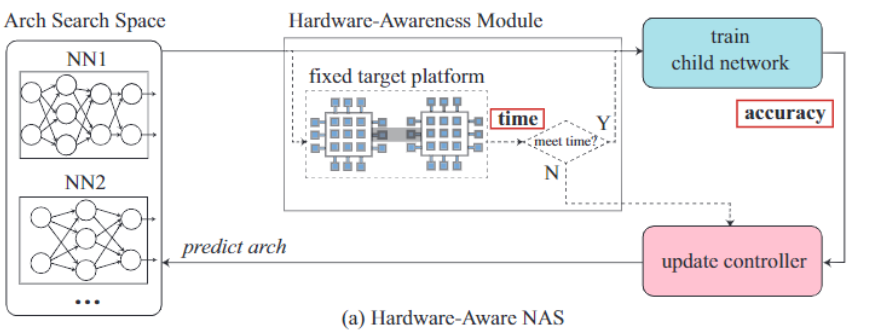
随着AI的发展,大量云计算平台和边缘计算设备都能够采用能自由设计硬件的FPGA,相比传统的专用专用集成电路ASIC,FPGA能够极大提升电路的硬件设计空间,从而找到一个能让神经网络发挥最佳性能的硬件电路。
所以如果有一个模型能够同时设计神经网络架构和FPGA硬件架构,那性能岂不是更强?
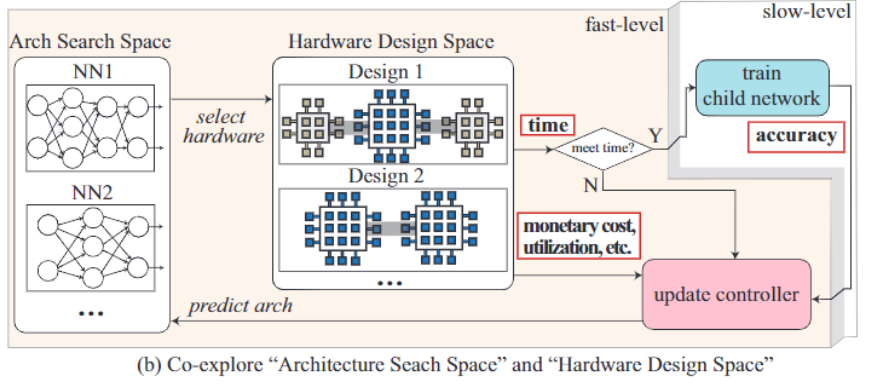
文中提出的HW/SW 协同搜索的框架包含一个基于RNN的控制器和两个层次的搜索,其中子网络中的每个RNN的单元在面对不同的优化目标时都会被重组(reorganized)。
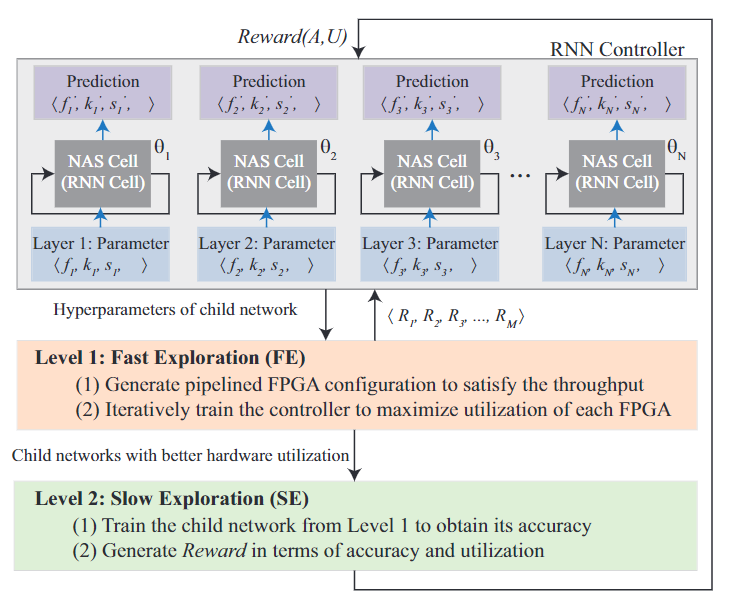
在第一层的快速搜索中主要包含四步:
1、以概率p预测一个模型架构
2、在满足吞吐量限制条件的情况下,搜索设计空间来生成一个pipelined FPGA系统
3、根据流水线的结构,重组控制器中的RNN单元
4、使用强化学习最大化pipeline的效率来更新控制器参数
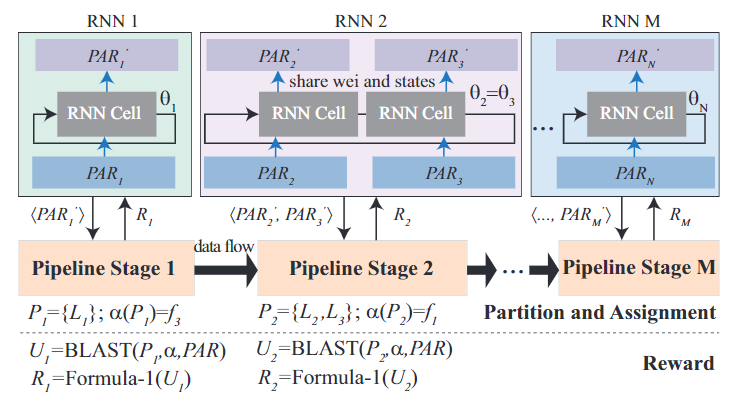
在重组和更新控制器时,由于我们的生成目标是找到更高硬件利用率的子网络,所以采用的策略是最大化平均硬件利用率。
最大化平均硬件利用率和最大化每个硬件的利用率之间就是全局和局部的区别,如果要找到全局最优解,那所搜索的设计空间要比局部空间更大,基本是指数级的。
所以为了有效地搜索设计空间,研究人员选择了局部策略,最大化不同流水线阶段的硬件利用率,并且根据确定的pipeline结构重组控制器中的RNN单元。
对于一个pipeline的多个层,RNN单元的权重和状态都是共享的,所以N个pipeline只需要N个RNN单元就可以最大限度地提高每个FPGA pipeline阶段的硬件利用率。
在第二层时,研究人员对对第一层得到的子网络进行训练,训练数据中保留一部分作为验证集。在训练完毕后将根据生成模型的准确率和pipeline效率作为评价标准生成一个奖励来更新RNN控制器。如果第一层生成的子网络都不符合吞吐量的要求,将会产生一个负奖励。
在第二层预测后,控制器将会在架构搜索空间中预测一个新的子网络,用于下一次的快速搜索。
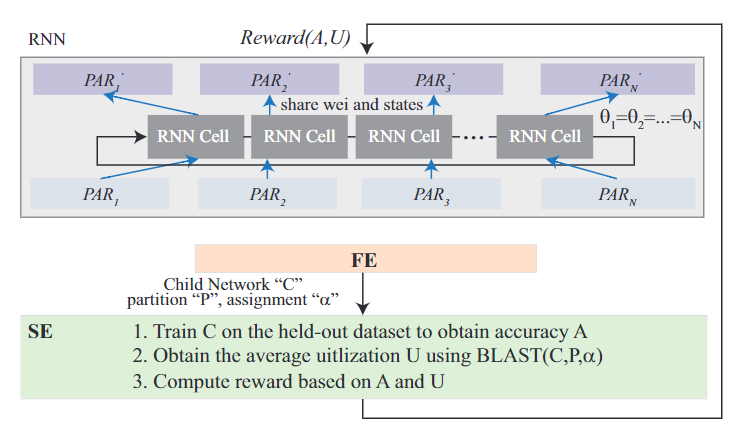
在第一层更新控制器中的RNN单元之前,需要对所有RNN单元权重进行快照保存。根据确定的pipeline结构,RNN单元再被重组,以便为之前获得的硬件设计(即pipeline结构)生成更好的子网络。
在进入慢速搜索层后,控制器中的RNN单元将使用先前保存的权重快照进行恢复。然后以准确度为目标来训练子网络,然后利用奖励函数更新恢复RNN。通过这种迭代方式,准确率将会不断提升,并且找到一个最佳的硬件设计。
和以往的研究不同的是,文中提出的RNN控制器集成了多个RNN单元,能够同时对两个层进行优化,在效率和准确率之间更好地权衡和优化。
总的来说,在第一层中,RNN只对给定的模型架构进行优化;而在第二层的时候RNN将会确定模型的骨架网络和pipeline结构。
结果分析
由于硬件容量的限制,所有架构的参数都少于100万个,这不可避免地导致了准确性的损失。
但是依然可以看到,OptSW搜索的架构在CIFAR-10上仍可以达到85.19%的测试准确率,并在ImageNet上达到70.24%的top-1准确率。这些结果证明了协同搜索方法在资源有限的情况下的有效性。
此外,OptSW优于硬件感知NAS,在CIFAR-10和ImageNet上分别取得了54.37%和35.24%的吞吐量,以及56.02%和54.05%的能效。
与顺序优化相比,OptSW在CIFAR-10上的吞吐量和能效分别提高了16.34%和28.79%;在ImageNet上,它也能略微提高吞吐量,并实现37.84%的能效提高。
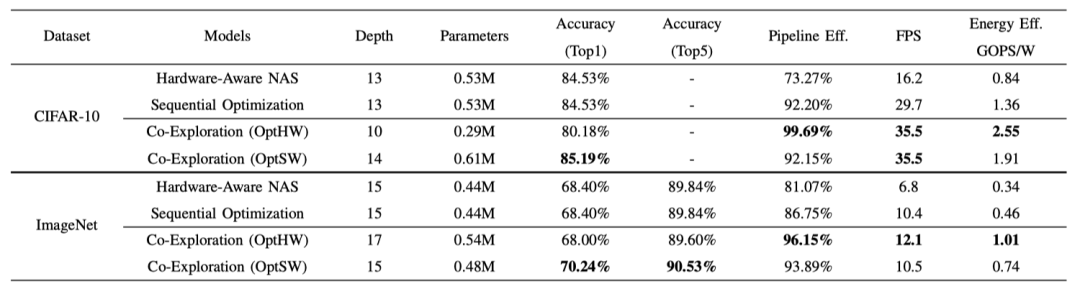
在CIFAR-10和ImageNet上的准确性、pipeline效率、吞吐量和能效的对比
通过在快速搜索层面进行有效的早期阶段修剪,协同搜索可以极大地加快搜索的过程,并在CIFAR-10和ImageNet上分别实现了159倍和136倍的速度。
与传统的控制器中只有一个RNN的硬件感知NAS相比,具有多个RNN的协同搜索框架可以将设计空间从O(∏i Di)大幅缩小到O(∑i Di),其中Di是第i个管道阶段的设计空间大小。
从表中「训练架构」中可以看到,协同搜索与硬件感知NAS相比,训练的架构要少得多。由于需要训练的架构数量与设计空间的大小成正比,因此协同搜索也实现了显著的速度提升。
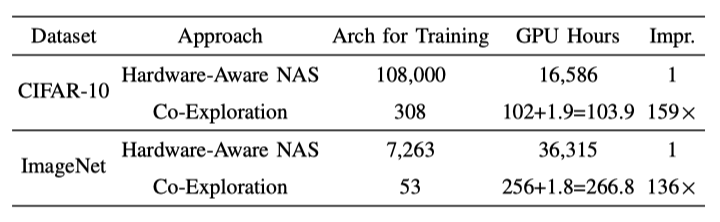
硬件感知NAS和协同搜索的归一化搜索时间的对比
参考资料:
https://ieee-ceda.org/awards/ieee-transactions-computer-aided-design-donald-o-pederson-best-paper-award
https://www.sigda.org/sigda-events/ubooth/
