
喜马拉雅自研网关架构演进过程
共 6171字,需浏览 13分钟
·
2021-03-01 12:21


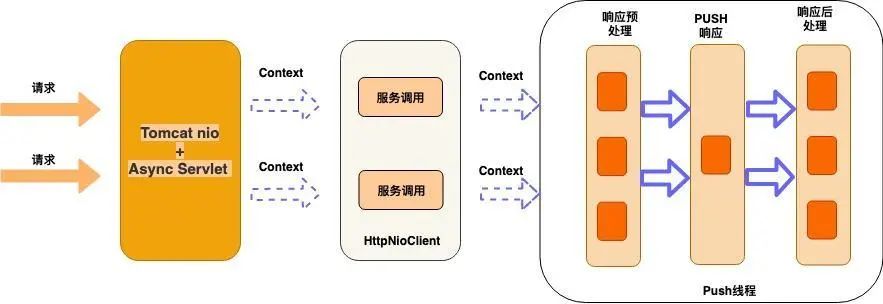
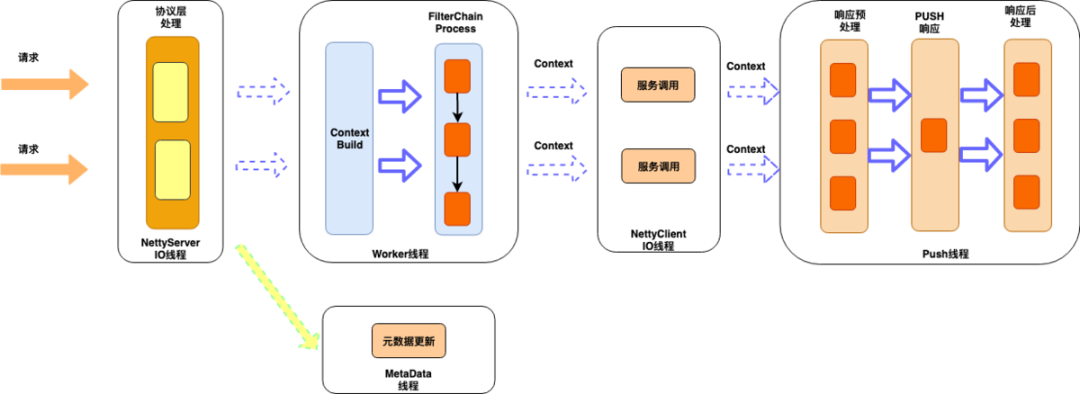
用户鉴权和登陆校验,支持接口级别配置
黑白明单,分全局和应用,以及IP维度,参数级别
流量控制,支持自动和手动,自动是对超大流量自动拦截,通过令牌桶算法实现
智能熔断,在histrix的基础上做了改进,支持自动升降级,我们是全部自动的,也支持手动配置立即熔断,就是发现服务异常比例达到阀值,就自动触发熔断
灰度发布,我对新启动的机器的流量支持类似tcp的慢启动机制,给 机器一个预热的时间窗口
统一降级,我们对所有转发失败的请求都会找统一降级的逻辑,只要业务方配了降级规则,都会降级,我们对降级规则是支持到参数级别的,包含请求头里的值,是非常细粒度的,另外我们还会和varnish打通,支持varish的优雅降级
流量调度,支持业务根据筛选规则,对流量筛选到对应的机器,也支持只让筛选的流量访问这台机器,这在查问题/新功能发布验证时非常用,可以先通过小部分流量验证再大面积发布上线
流量copy,我们支持对线上的原始请求根据规则copy一份,写入到mq或者其他的upstream,来做线上跨机房验证和压力测试
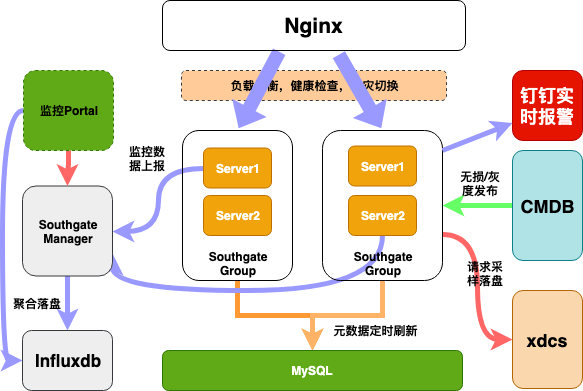
请求日志采样,我们对所有的失败的请求都会采样落盘,提供业务方排查问题支持,也支持业务方根据规则进行个性化采样,我们采样了整个生命周期的数据,包含请求和响应相关的所有数据
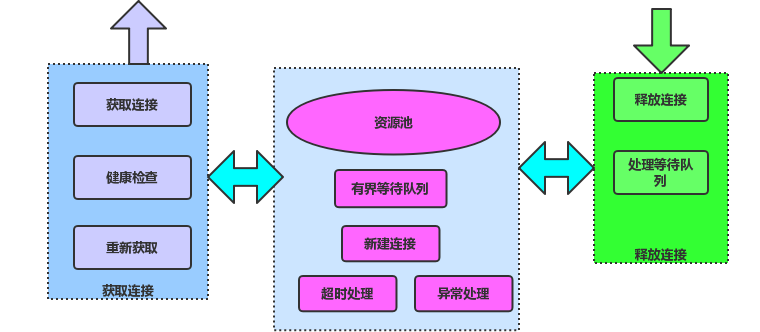
Connection:close
空闲超时,关闭链接
读超时关闭链接
写超时,关闭链接
Fin,Reset
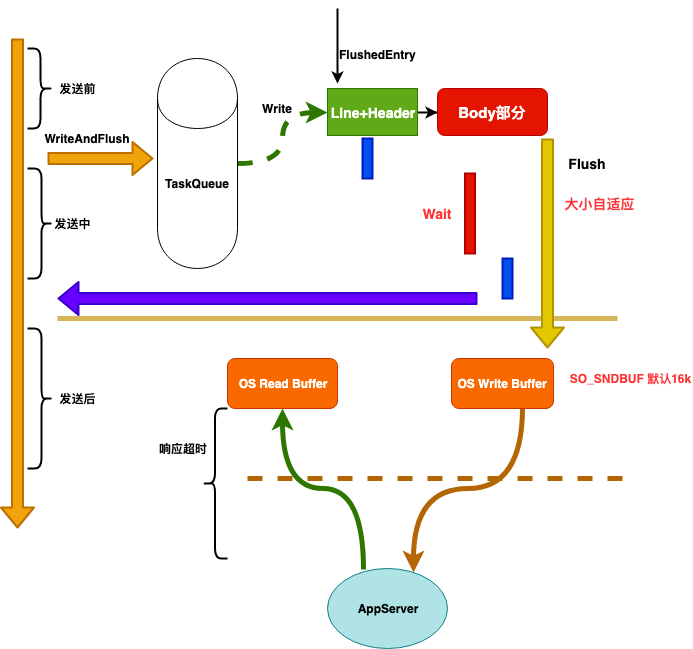
协议解析超时
等待队列超时
建链超时
等待链接超时
写前检查是否超时
写超时
响应超时
攻击性请求,只发头,不发/发部分body,采样落盘,还原现场,并报警
Line or Head or Body过大的请求,采样落盘,还原现场,并报警
耗时监控,有慢请求,超时请求,以及tp99,tp999等
QPS监控和报警
带宽监控和报警,支持对请求和响应的行,头,body单独监控。
响应码监控,特别是400和404
链接监控,我们对接入端的链接,以及和后端服务的链接,后端服务链接上待发送字节大小也都做了监控
失败请求监控
流量抖动报警,这是非常有必要的,流量抖动要么是出了问题,要么就是出问题的前兆。
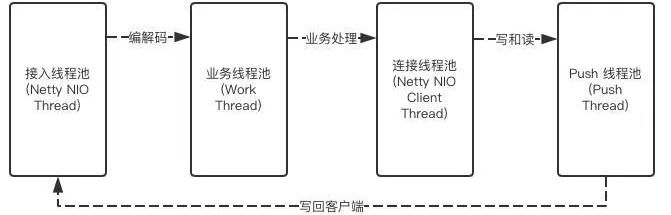
/**
* Cleans up if the user forgets to close it.
*/
protected void finalize() throws IOException {
close();
}
后台回复 学习资料 领取学习视频
如有收获,点个在看,诚挚感谢