
Python正则表达式,看完这篇文章就够了!
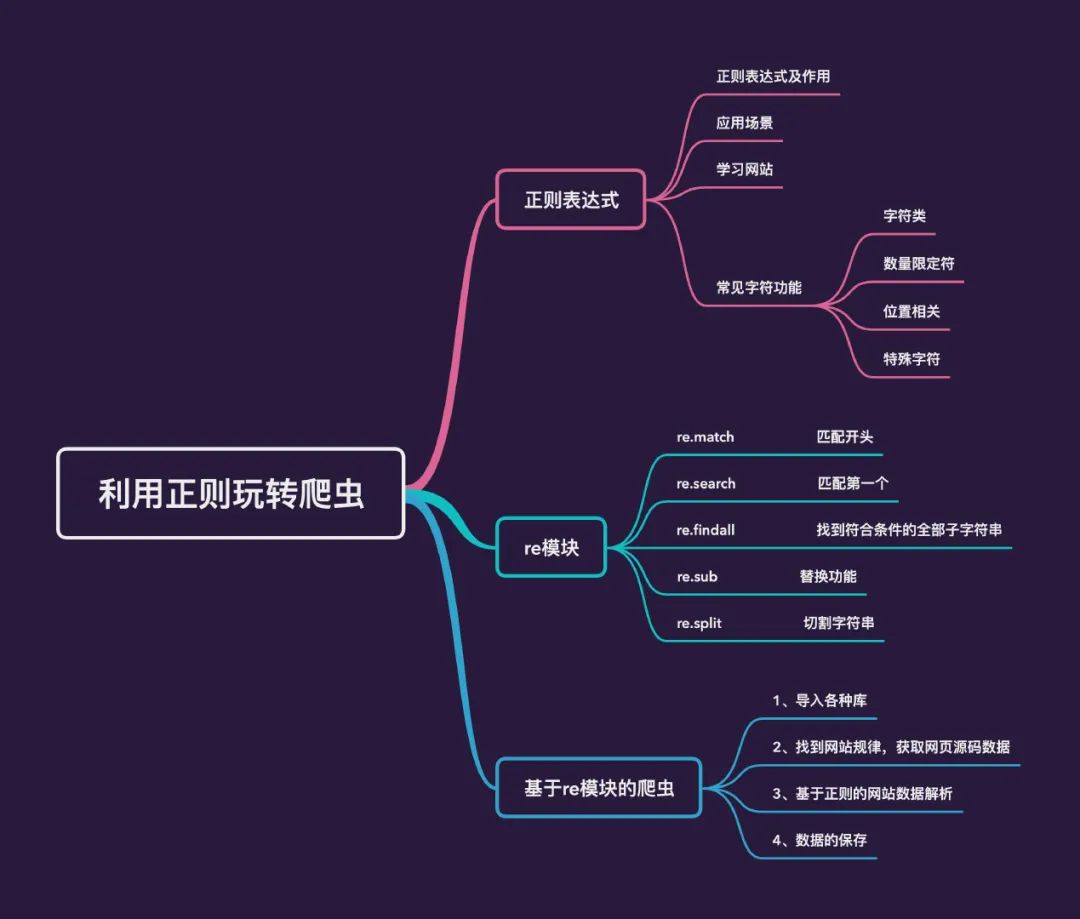
玩转正则表达式
本文中介绍的是主要是 3 个知识点:
正则表达式的相关知识 Python的中re模块,主要是用来处理正则表达式一个利用 re模块通过正则表达式来进行网页数据的爬取和存储
使用的系统 Python 版本和其他环境分别如下:
npython 3.7.5 MacOS jupyter notebook re # re 模块 requests 2.23.0 # 发送请求
1、正则表达式
1.1 正则表达式及作用
正则表达式的英文是 regular expression,通常简写为 regex、regexp 或者RE,属于计算机领域的一个概念。
正则表达式的主要作用是被用来进行文本的检索、替换或者是从一个串中提取出符合我们指定条件的子串,它描述了一种字符串匹配的模式 pattern 。
目前正则表达式已经被集成到了各种文本编辑器和文本处理工具中。
1.2 应用场景
验证:比如在网站中进行表单提交时,进行用户名及密码的验证
查找:从给定的文本信息中进行快速高效地查找与分析字符串
替换:将我们指定格式的文本进行查找,然后将指定的内容进行替换
1.3 网站
在这里介绍几个用来学习和测试正则表达式的网站:
菜鸟教程-正则表达式
https://www.runoob.com/regexp/regexp-tutorial.html
正则表达式在线测试工具
https://tool.oschina.net/regex/
GoRegex.cn
https://goregex.cn/
官方re模块学习
https://docs.python.org/zh-cn/3/library/re.html
正则表达式30分钟入门教程
https://deerchao.cn/tutorials/regex/regex.htm#mission
1.4 常用字符功能
先介绍常用正则表达式中几种特殊字符的功能:
字符类
| 字符 | 含义 | 例子 |
|---|---|---|
| . | 匹配任意一个字符 | ab.可以匹配abc或者abd |
| [ ] | 匹配括号中的任意1个字符 | [abcd]可以匹配ab、bc、cd |
| - | 在[ ]内表示的字符范围内进行匹配 | [0-9a-fA-F]可以匹配任意一个16进制的数字 |
| ^ | 位于[ ]括号内的开头,匹配除括号中的字符之外的任意1个字符 | [^xy]匹配xy之外的任意一个字符,比如[^xy]1可以匹配A1、B1但是不能匹配x1、y1 |
数量限定符
| 字符 | 含义 | 例子 |
|---|---|---|
| ? | 匹配前面紧跟字符的0次或者1次 | [0-9]?,匹配1、2、3 |
| + | 匹配前面紧跟字符的1次或者多次 | [0-9]+,匹配1、12、123等 |
| * | 匹配前面紧跟字符的0次或者多次 | [0-9]*,不匹配或者12、123 |
| {N} | 匹配前面紧跟字符精确到N次 | [1-9][0-9]{2},匹配100到999的整数,{2}表示[0-9]匹配两个数字 |
| {,M} | 匹配前面紧跟字符最多M次 | [0-9]{,1},指的是最多匹配0-9之间的1个整数,相当于是0次或者1次,等价于[0-9]? |
| {N,M} | 匹配前面紧跟字符的至少N次,最多M次 | [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3},匹配IP地址,其中.号是特殊字符,需要使用转义字符\ |
位置相关
| 字符 | 含义 | 例子 | |
|---|---|---|---|
| ^ | 匹配开头的位置;通过\A | ^hello 匹配hello开头的字符内容 | |
| $ | 匹配结束的位置同\Z | ;$ 匹配一行结尾的;符号 ^$匹配空行 | |
| < | 匹配单词开头的位置 | ||
| > | 匹配单词结尾的位置 | p> 匹配leap等,但是不能匹配parent、sleepy等不是p结尾的单词 | |
| \b | 匹配单词开头或结尾的位置 | \bat 匹配…at…,但是不能匹配cat、atexit、batch(非at开头) | |
| \B | 匹配非单词开头或者结尾的单词 | \Bat匹配battery,但是不能匹配attend/hat等以at开头的单词 |
特殊字符
| 字符 | 含义 | 例子 |
|---|---|---|
| \ | 转义字符,保持后面字符的原义,使其不被转义 | \. 输出. |
| ( ) | 将表达式的一部分括起来,可以对整个单元使用数量限定符,匹配括号中的内容 | ([0-9]{1,3}\.){3}[0-9]{1,3}表示将括号内的内容匹配3次 |
| | | 连接两个子表达式,相当于或的关系 | n(o|either)匹配no或者neither |
| \d | 数字字符 | 相当于是[0-9] |
| \D | 非数字字符 | 相当于是[^0-9] |
| \w | 数字字母下划线 | [a-zA-Z0-9_] |
| \W | 非数字字母下划线,匹配特殊字符 | [^\w] |
| \s | 空白区域 | [\r\t\n\f]表格、换行等空白区域 |
| \S | [^\s] | 非空白区域 |
2、re 模块
2.1 re 模块简介
在 Python 中主要是利用 re 模块进行正则表达式的处理,涉及到 4 个常用的方法:
re.match() re.search() re.findall() re.sub() re.split()
5 个方法的基本使用语法是:
import re # 使用之前先进行导入re模块
re.match(pattern, string, flags) # match方法为例
上面参数的说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
2.2 标志位 flags
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志,如 re.I | re.M 被同时设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 忽略大小写(常用) |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予更灵活的格式,以便将正则表达式写得更易于理解。 |
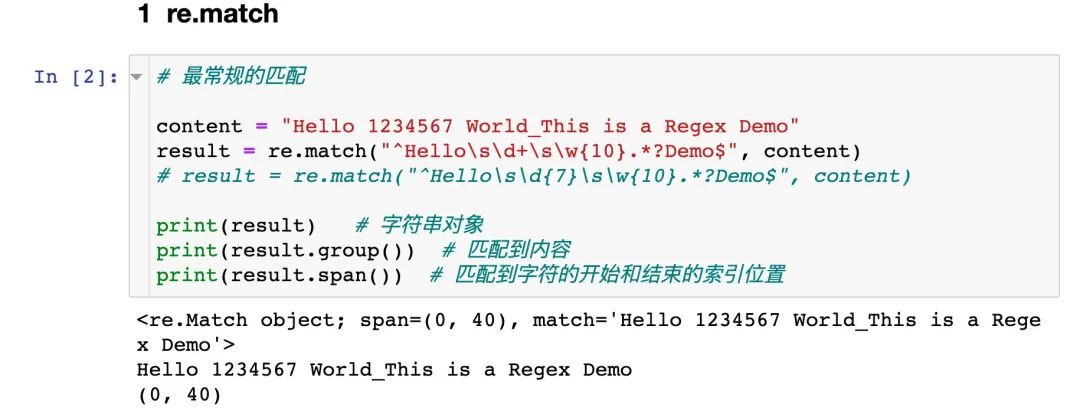
2.3 match
从指定字符串的开始位置进行匹配。开始位置匹配成功则继续匹配,否则输出None。
该方法的结果是返回一个正则匹配对象,通过两个方法获取相关内容:
通过 group()来获取内容通过 span()来获取范围:匹配到字符的开始和结束的索引位置
开始位置没有匹配成功,返回 None:

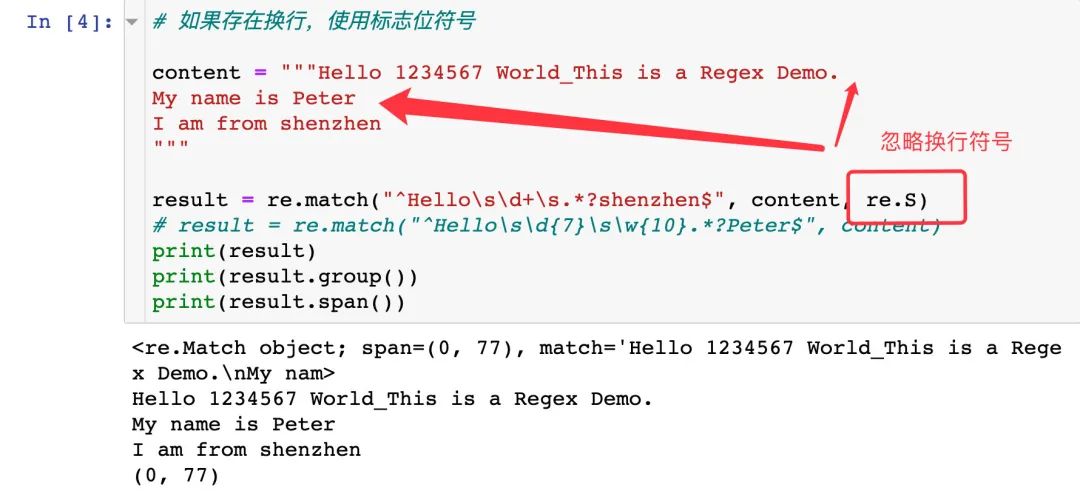
存在换行的字符串内容,使用 re.S:
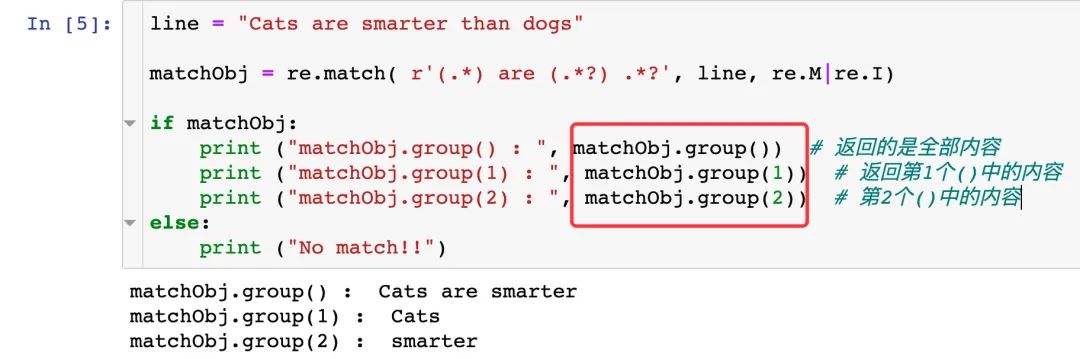
group() 方法获取内容的时候,索引符号从 1 开始:
2.4 search
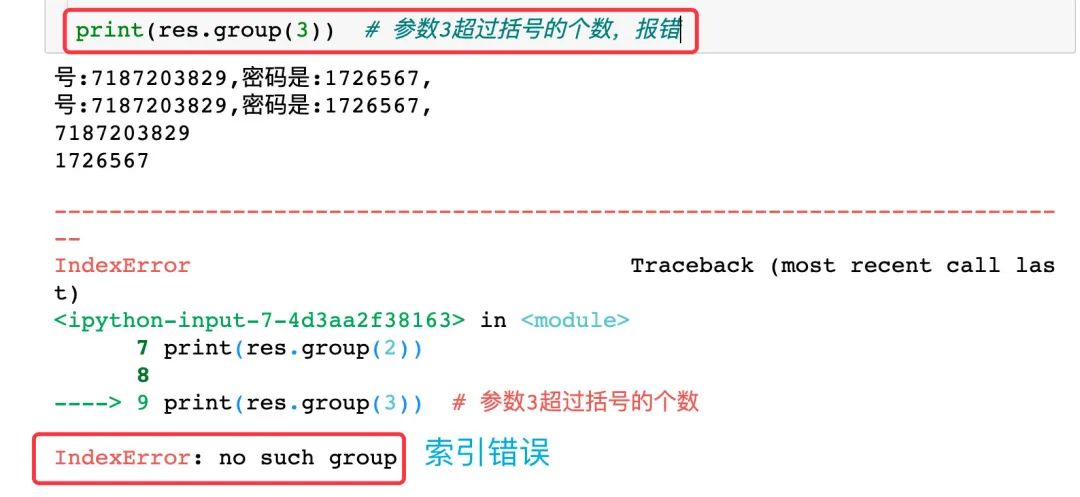
re.search 方法扫描整个字符串,返回的是第一个成功匹配的字符串,否则就返回 None


group(N) 中的参数N不能超过正则表达式中括号的个数,若超过则报错:
2.5 findall
re.findall() 是扫描整个字符串,通过列表形式返回所有符合的字符串
注意:
re.search是返回第一个符合要求的字符

如果存在多个 .*? ,则返回的内容中使用列表中嵌套元组的形式:

2.6 sub
re.sub 方法是用来替换字符串中的某些内容
直接替换 通过函数替换
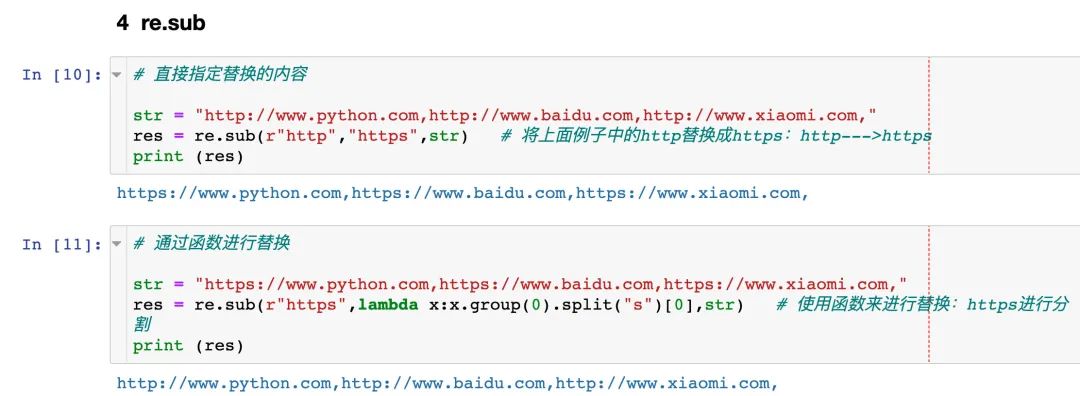
指定具体的替换内容:将空格替换成短横线

略微复杂的替换

2.7 split
用法
主要适用于将字符串进行分割:
re.split(pattern, string,maxsplit=0,flags=0)
用 pattern 分开 string 。如果在 pattern 中捕获到括号,那么所有的组里的文字也会包含在列表里。
如果 maxsplit 非零, 最多进行 maxsplit 次分隔, 剩下的字符全部返回到列表的最后一个元素。

如何理解是否保留匹配项

第二种写法就是保留了匹配项
2.8 贪婪模式与非贪婪模式
贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为。
贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配;而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配
我们在正则表达式中经常会使用 3 个符号:
点 .:表示匹配的是除去换行符之外的任意字符问号 ?:表示匹配 0 个或者 1 个星号 *:表示匹配 0 个或者任意个字符
贪婪模式与非贪婪模式:
.*?非贪婪模式.*贪婪模式
看一个例子来比较 re 模块中两种匹配方式的不同:

在上面的非贪婪模式中,使用了问号 ?,当匹配到aaaacb已经达到了要求,停止第一次匹配;接下来再开始匹配到ab;再匹配到adceb;所以存在多个匹配结果在贪婪模式中,程序会找到最长的那个符合要求的字符串
关于正则表达式中贪婪和非贪婪模式的详解,请参考文章 https://www.cnblogs.com/520yang/articles/7473596.html,写的非常清楚。
3、基于正则的爬虫
字符串是在我们编程中涉及最多的一种数据结构,对字符串进行操作的需求几乎无处不在。
比如我们编写好了爬虫程序,在得到了网页的源码之后,怎么从茫茫数据中提取出来我们指定的数据?这个通过正则表达式提取就是其中的方法之一。
接下来讲解的通过 re 模块来爬取某个网站的内容。
3.1 网页结构
分析的网页结构和源码的相关对应信息:
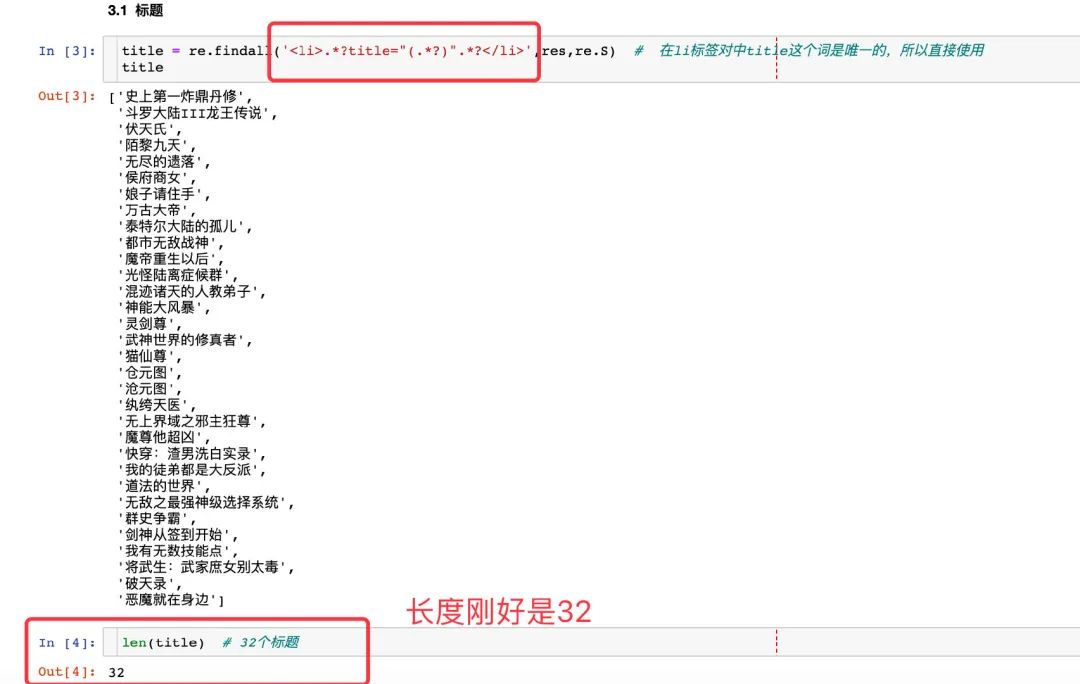
在每个网页中有 32 篇小说

这 32 篇小说的信息存在于 32 个 对中:
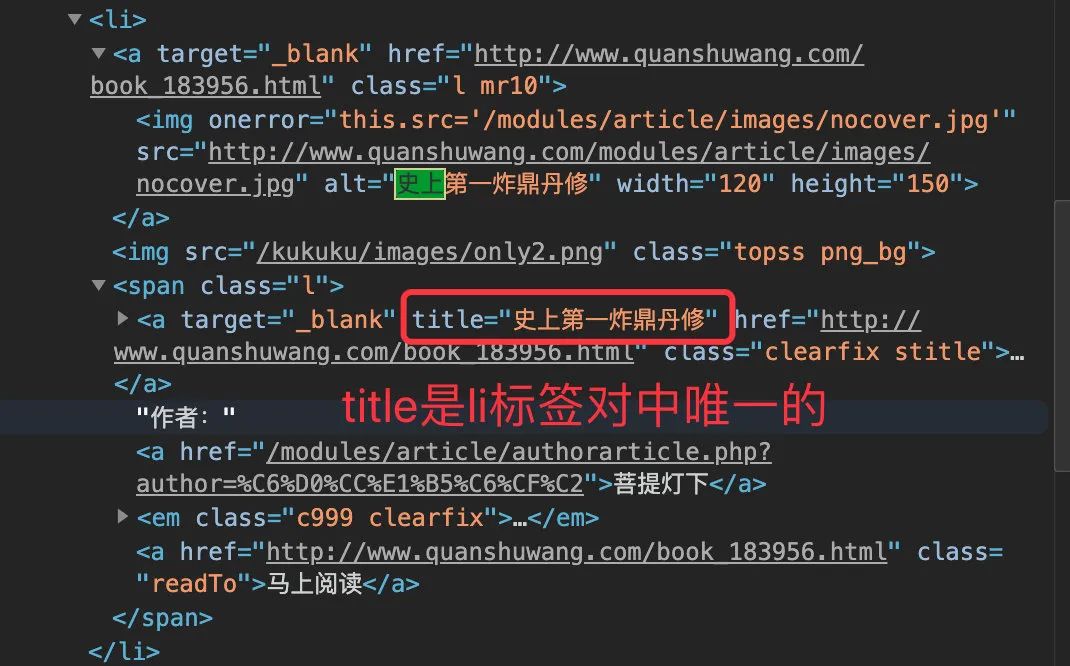
每篇信息存在一个 li中,比如第一篇:
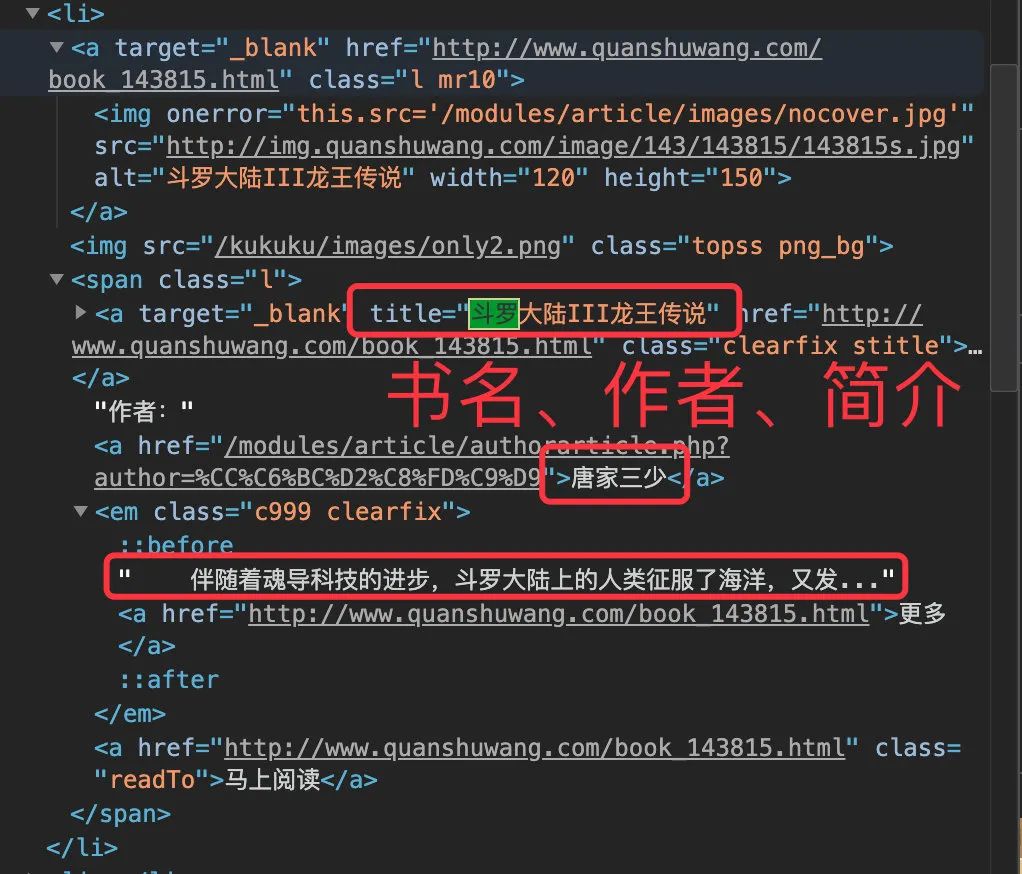
源码和网页中的对应位置

3.2 网页地址
第一页的地址是 http://www.quanshuwang.com/list/1_1.html ,第二页是 http://www.quanshuwang.com/list/1_2.html ,网页地址的规律
for i in range(1, 1156): # 总共1155页
url = "http://www.quanshuwang.com/list/1_{}.html".format(i)
3.3 爬取信息
导入库爬虫中需要的库
import re # 解析数据
import requests # 发送请求
import csv # 存入数据
import pandas as pd
爬取第一页
爬取第一页的内容进行测试
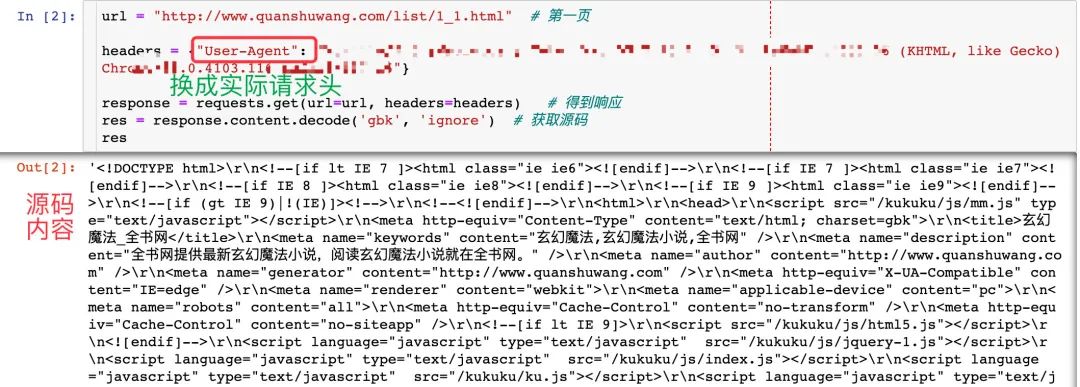
url = "http://www.quanshuwang.com/list/1_1.html" # 第一页
headers = {"User-Agent": "自己的请求头"}
response = requests.get(url=url, headers=headers) # 得到响应
res = response.content.decode('gbk', 'ignore') # 获取源码,实际编码是gbk
res
下面进行 3 个字段信息的爬取:
标题title
title 是 li 标签对中唯一的,所以可以直接获取双引号中的内容,最后检验下长度刚好是 32 :
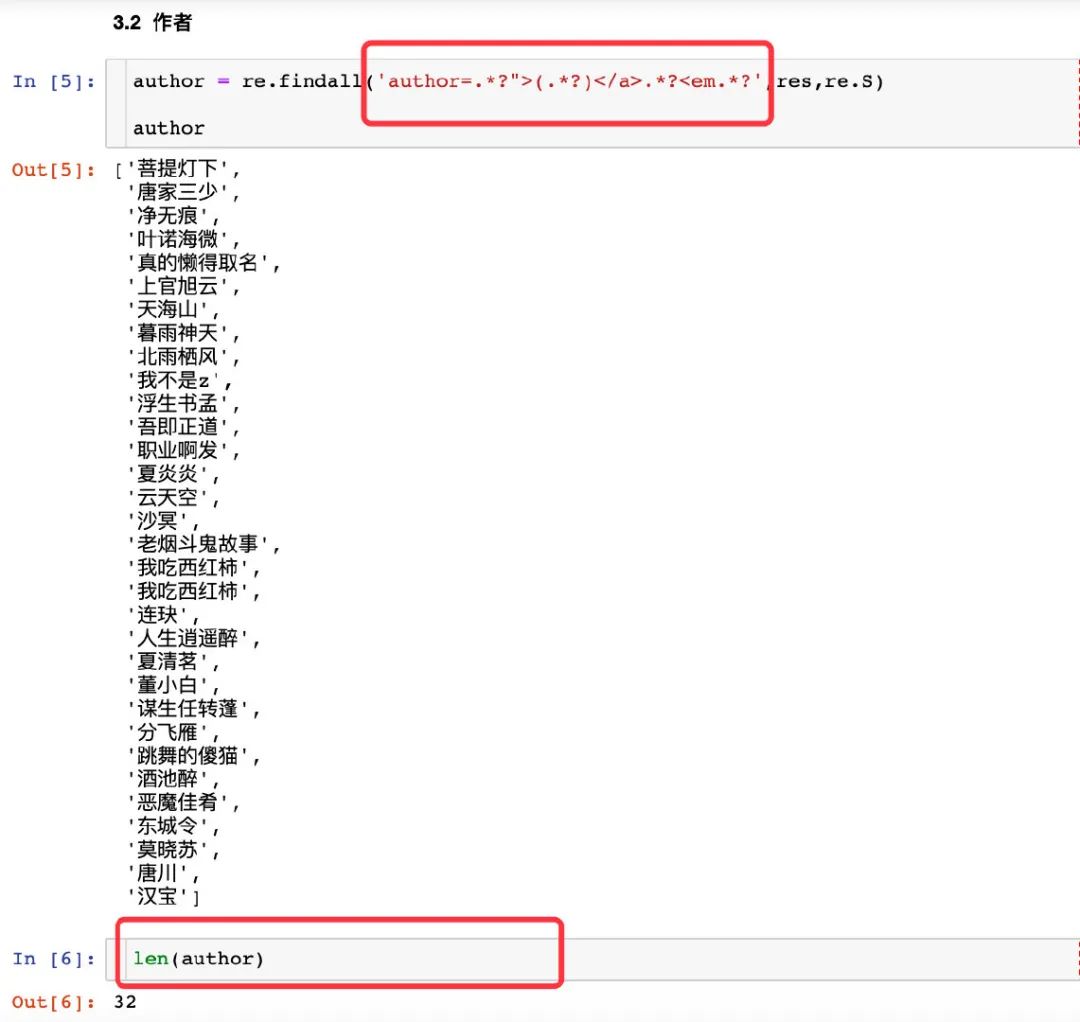
作者 author
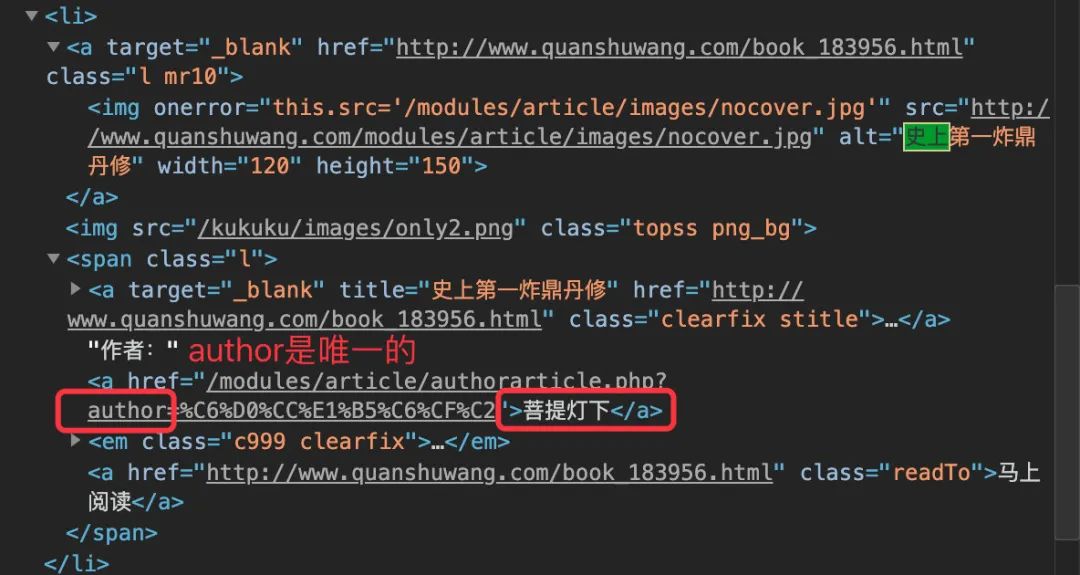
author 是源码中唯一的内容,直接通过 author 后面的内容进行获取,检验长度也是 32
在 author 和 em 标签中进行限制来获取内容
简介 substract
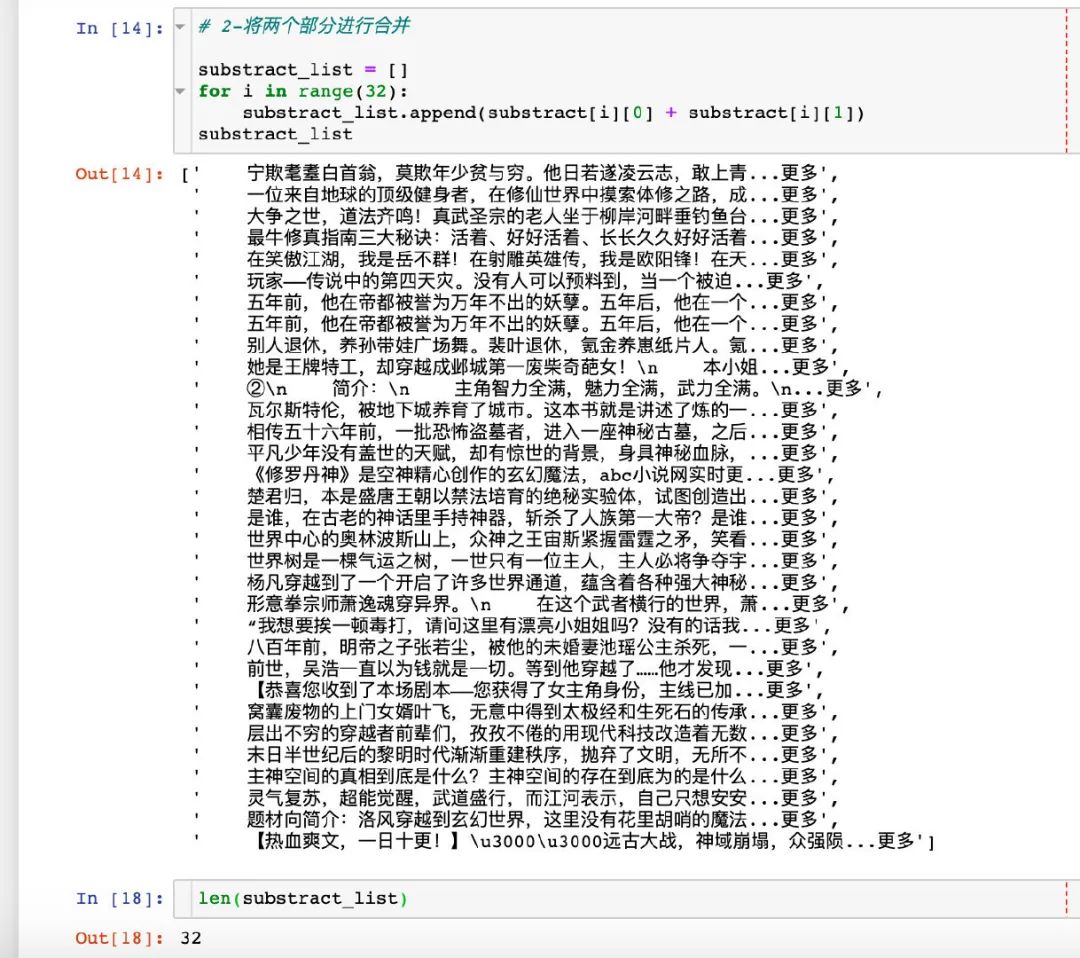
对简介的提取分为两个部分:正文部分+更多。因为有些小说没有简介,只有更多 2 个字,所以需要特殊下
通过元组的形式单独提取出两个信息

将两个信息进行合并,放到一个大列表中,同时检验长度仍然是 32
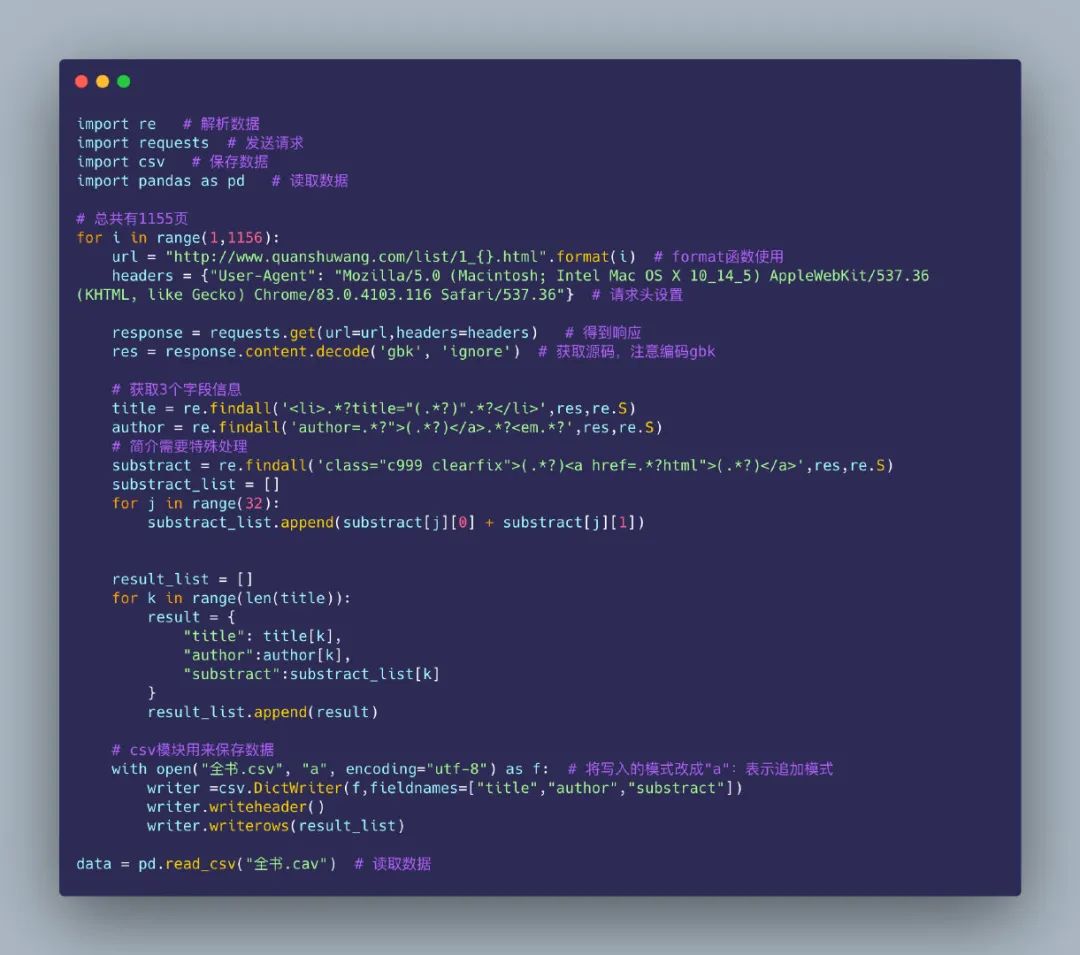
3.4 完整代码
下面是完整的源码,包含:
访问链接获取源码数据 利用 re 模块解析数据 利用 csv 模块保存数据 读取数据
万水千山总是情,点个 👍 行不行。
菜鸟编程大本营,现已正式上线!
接下来我们将会在该公众号上,专注为大家分享Python,Java,Go,前端开发等优质的学习资源和技术,分享一些程序员圈的新鲜趣事。
爆款文案
关注菜鸟编程本营,从菜鸟进阶高手
点这里,获取新手福利

