
深度解析:会用Excel,还有必要学Python吗?
在看到知乎上有个问题:
我都会用Excel了,还有必要学Python吗?

这个问题大概率可以说明问这个问题的这位同学目前还没有遇到非Python不可的场景,之所以产生了学Python的念头是因为这两年Python实在是太火了,如果自己不学总觉得差点什么。但是学了一点以后又发现Python做的那些事情,我Excel也可以做,既然如此,我为什么还要费这么大劲去学Python呢?
为什么要学Python
大家在学一个工具或者一项知识的时候,一定不要为了学而学,这样不仅学起来很痛苦,而且很难坚持下去的。
那既然如此,是不是我们就可以不学Python了?不是的,你想想为什么现在几乎所有的招聘要求上都会要求掌握Python技能?

原因主要有两个:
1、有些事情虽然Excel也能做,但是用Python效率会更高
2、有些事情是只有Python可以做,而Excel是做不了的
综合这两个原因,就要求你必须掌握Python技能,虽然不一定100%的工作都用Python,但是不得不用Python的时候你得会。
Excel和Python在不同场景下的异同
接下来我们就围绕一名数据从业者在工作中可能会涉及到的工作内容进行展开,看看不同工作内容下,Excel和Python的异同。主要从以下几方面进行展开:
数据处理与运算 报表自动化 图表可视化 统计检验 机器学习算法
数据处理与运算
数据处理与运算这部分工作是我们工作中的大头,我们先来看下关于数据处理与运算中比较高频的一些内容:
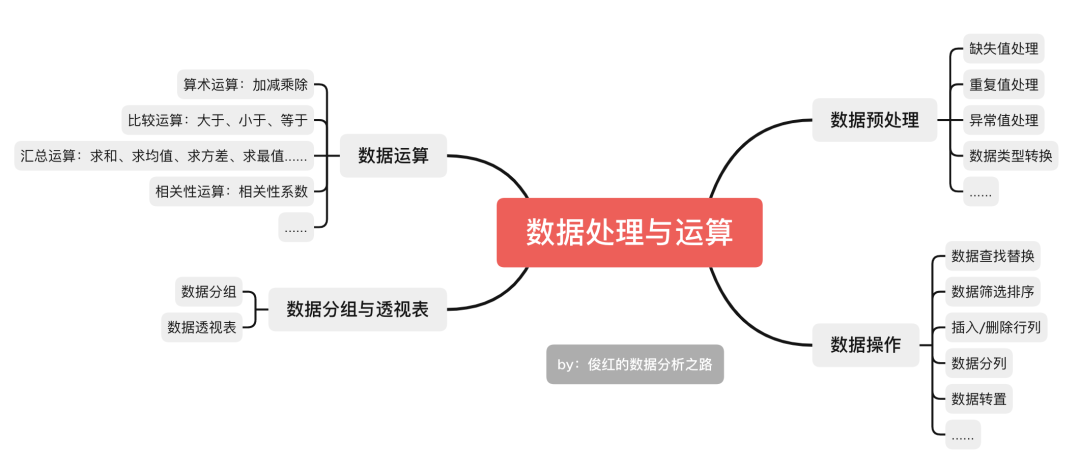
学过Excel的同学对这些应该都不陌生,这些内容在Excel是完全可以实现,在Python中也是可以实现的,那我们应该如何选呢?
原则就是哪个方便用哪个,如果你现在只有100行数据,你现在要对这100行数据进行降序排列,这个时候肯定用Excel效率更高,你用Python的话还需要先把数据导入到Python中以后再做处理,相对来说更麻烦一些。
但如果你的数据条数超过10万行,你试着用Excel执行一下删除重复值的操作,几乎会瞬间无响应,然后Excel就闪退了,很多人又没有及时保存文件的习惯,闪退会导致之前做的工作白做了。如果你用Python的话,首先Python处理几十万条数据的时候,速度还是可以的,即使速度慢一点,大多数时候是不会出现软件闪退的,而且即使闪退了,之前的代码是有的,只需要把之前的代码重新运行一遍就好了,不需要重头再做。
如果你的数据超过100万行,那么就只能用Python了,因为Excel的最大行数为1048576行。
需要声明的是,不管是Excel还是Python,数据处理速度会跟电脑自身的性能有很大关系。
综上,如果你平常接触的数据都是10万以内的小数量级,那么其实是可以不学Python的,但如果需要经常处理大数量级的数据,还是有必要学一学Python的。
报表自动化
报表是作为一个数据从业者不得不做的一件事,常见的报表就是日报、周报、月报这些,这些报表有一个好处就是格式比较固定,只有固定的内容我们就可以进行自动化。而所谓的自动化就是让机器代替人工做事情的过程。
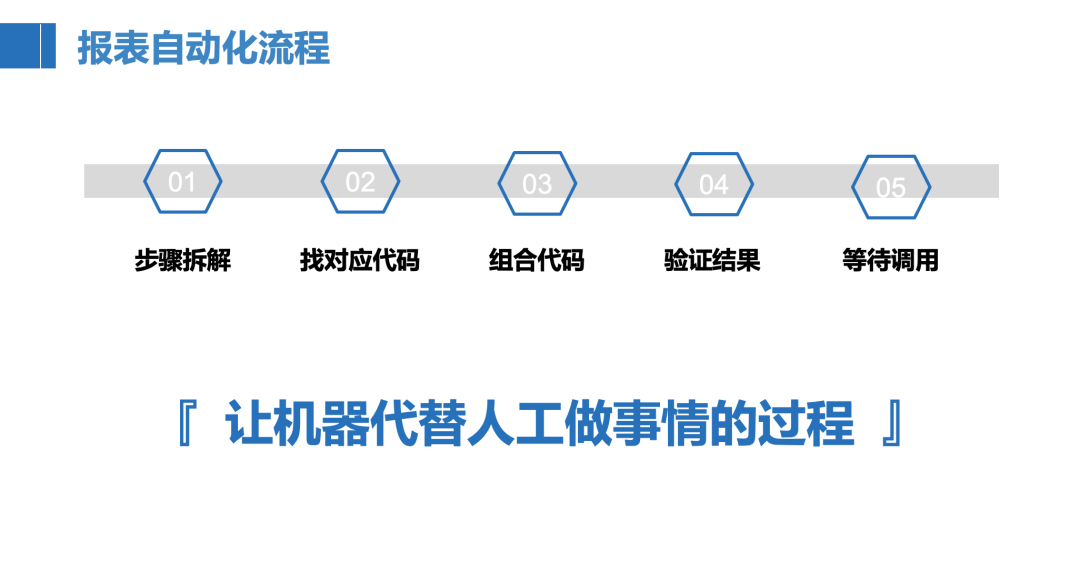
下图是我列的常规报表自动化的流程,主要分为5个步骤,核心在于前两个步骤,先对整个报表制作流程进行拆解,拆解成若干个小的步骤,然后再找每个步骤对应的代码是什么,最后把小步骤的代码合并起来就是整个报表制作的代码,我们每次只需要把写好的代码运行一遍,结果就自动出来了,也就达到了报表自动化的目的。
运行效率:
在代码这一块我们既可以用Excel中的VBA,也可以用Python。那我们应该如何选呢?首先看效率问题,有个博主专门测试过Python和VBA逐行读取同一个文件,Python耗时0.639秒,VBA耗时2.855秒,两者相差4.x多倍。
博文链接:
https://www.cnblogs.com/metree/p/3477351.html
书写效率:
除了执行效率方面以外,还有就是代码书写效率,下面截图是从网上找的一个关于读取txt文件的VBA代码:

文档链接:
https://blog.csdn.net/weixin_42578747/article/details/90111536
下面是用Python读取txt文件时的代码:
import pandas as pd
pd.read_table('file_name.txt')
是不是明显Python的代码要更简洁,而且更容易理解,read_table就是读取文件,多直观。
综上,如果是平常有大量工作需要自动化的话,也还是有必要学习Python的。
图表可视化
效率方面:
图表可视化也是我们日常工作中比较使用比较高频一部分,图表除了传递信息以外,还要尽可能的美观,让看表的人视觉体验更好。
下图中左半图时Excel默认的折线图样式,右半图时Python中Seaborn库中默认的折线图样式,很明显右图要比左图观看体验上更好一些。
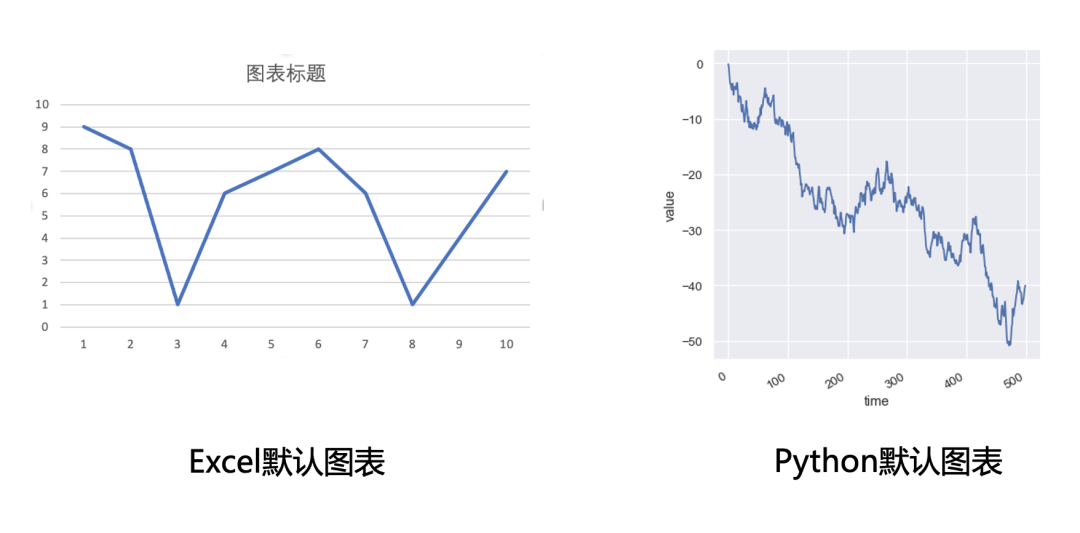
虽然Excel图表在进行专门的样式设置以后也能达到比较好看的效果,但是进行样式设置很耗费时间的,我们还是希望用更少的时间得到稍微不那么丑的图表。
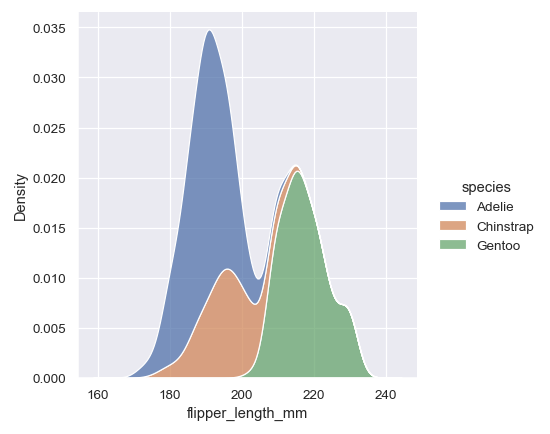
再比如绘制统计学中的核密度图,虽然Excel中也可以通过复杂的操作实现,但是Python中只需要如下一行代码就可以绘制出比较好看的核密度图:
sns.displot(penguins, x="flipper_length_mm", hue="species", kind="kde", multiple="stack")
图表全面性:
上面是看了Excel和Python的在效率方面的差异,接下来我们看下在图表全面性方面两者的差别。
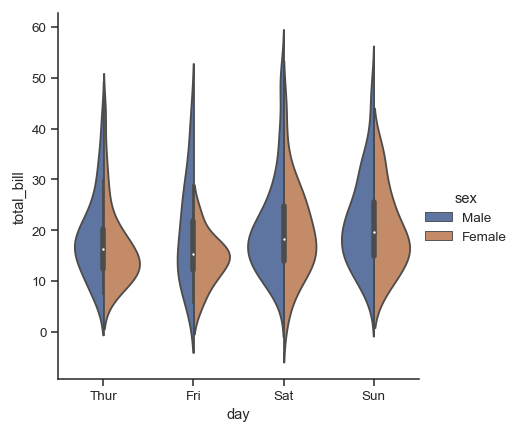
折线图、柱状图是比较常见的一些图表,除了这些比较常规的图表以外,我们有的时候我们还会去绘制一些比较专业图表,比如小提琴图,在Excel里面就不太好去实现,而在Python里面也只需要如下一行代码就可以轻松实现:
sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", split=True, data=tips)
在图表可视化方面,Python中有很多的库可以供我们使用,下面是一些比较常用的库的官网,我们只需要根据具体场景选择适合自己的就好了。
matplotlib官网:https://matplotlib.org/
pyecharts官网:https://pyecharts.org/#/
seaborn官网:https://seaborn.pydata.org/index.html
plotly官网:https://chart-studio.plotly.com/feed/#/
Boken官网:https://docs.bokeh.org/en/latest/
综上,如果平常工作中对图表的视觉体验没太多要求,而且也涉及到一些高级的统计图表的话,Excel就用了。如果要是对效率和图表的全面性都有要求的话,还是有必要学Python的。
统计学检验
我们在平常工作中会做很多AB测试,而AB测试的核心就是背后的统计学检验,我们看下Excel和Python在统计检验方面有啥区别。
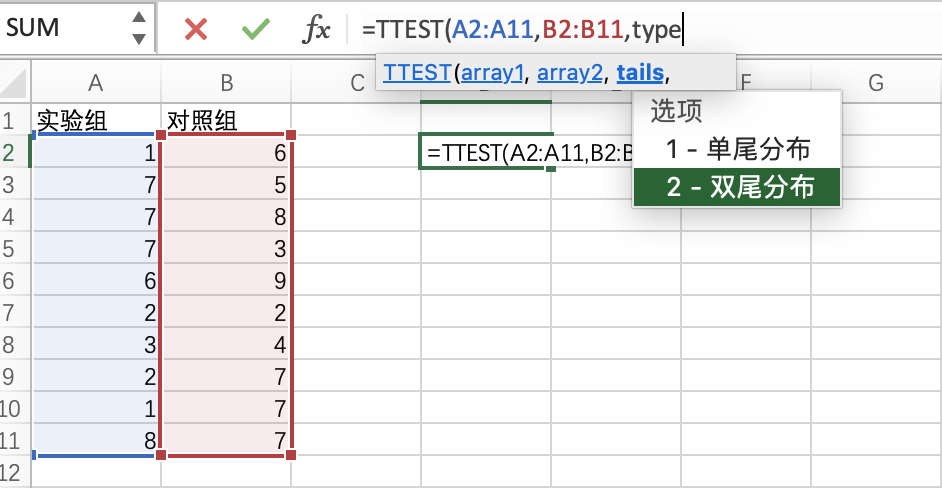
统计检验中比较基础的检验就是T检验。
在Excel中进行T检验时,使用的TTEST()函数,在该函数中指明要检验的两组数据核检验分布即可,也比较简单:
在Python中进行T检验时,使用的代码如下:
stats.ttest_ind(treat_data, control_data)
从简单的T检验来看的话,两者基本没啥差别。
稍微高级一点的就是多重检验,就是用来检验多组内任意两组之间的差异情况,此时如果在Excel中需要用到人工进行两两比较,而在Python中只需要下面一行代码即可得出两两之间的检验结果。
MultiComparison(data, groups)
综上,一些简单的检验的话,Excel和Python是没啥区别的,而一些稍微复杂的检验的话,Python里面都会把复杂的步骤封装好,使用起来会更方便。
机器学习算法
作为一名数据分析师,虽然日常工作中的主要工作不是做算法,但是还是需要对一些常见算法的原理和实现是了解的。
机器学习领域比较知名的库就是Sklearn,用这个库可以让你很轻松的就能够实现一个机器学习算法。
算法里面最基础的就是线性回归了,运行如下代码就可以求取出线性回归的各项系数:
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
reg.coef_
Sklearn库中不仅包含了常见的分类和回归算法,还包含了特征工程等部分,让你轻松掌握机器学习。
Sklearn官网:https://scikit-learn.org/stable/index.html
而Excel中是没有这种条件的。
上面从各个方面介绍了在不同场景下Excel和Python的异同,相信大家对于自己到底要不要学Python应该比较清楚了。那如果想学,我们应该怎么学呢?
怎么学
学习Python首先要明白两句核心内容,只要真正理解了这两句话,那你学起来会很快的:
1、不管Excel还是Python,这些都是实现工具而已,背后的理论原理是都一样的;2、常用的功能大概占全部功能的20%,刚开始学,要抓主要矛盾,学主要内容,等把主要内容学会以后,再学次要内容就容易很多了。
对比学习法
Excel中的数据透视表大家应该都比较熟悉,核心就是下面这四个框,只需要把不同的字段拖到对应的框里面就行。

如果现在我让你用Python对一个数据表做一个数据透视表,你肯定会一脸懵,Excel中都是鼠标拖拽的,Python要怎么实现呢?
其实也简单,在Python中做数据透视表需要用到pivot_table()函数,该函数的关键参数如下:
pd.pivot_table(data,values=None,index=None,columns=None,aggfunc='mean')
看到这里应该还不太明白,我们再往下看:

看到这张图是不是就差不多理解了,不同的参数其实就代表Excel中不同的框,在Excel中是用鼠标把字段拖到框里面,在Python中是将字段名赋值给相应的参数。
pivot_table()函数中的data参数表示要做数据透视表的整个表,aggfunc表示对values的进行什么样的运算。
数据透视表不是Excel所独有的,在不同工具里面的实现逻辑是一样的,只不过具体的实现方式会不一样,但是只要我们把背后的逻辑掌握了,然后借助于我们现有的、比较熟悉的Excel去学习和理解Python的实现方式,这样学起来就会轻松很多。

其实不仅是透视表这个案例,我们所用到的很多知识都是可以按照这种思路去学习的,我们把这种学习方法称为对比学习法。
我的《对比Excel》系列三本书:《对比Excel,轻松学习Python数据分析》、《对比Excel,轻松学习SQL数据分析》、《对比Excel,轻松学习Python报表自动化》均是采用了这种思想进行写作的。
先解决主要矛盾
很多Python的书和课程会追求大而全,会讲很多又难但又使用频率不那么高的知识点,比如面向对象编程,很多学了几年的人也没学会,新手一学更是懵逼。这些知识点会把很多新人劝退的,真正的做到了从入门到放弃。

我们在刚开始学的时候,尽量去学那些主要的知识点,学完之后马上逼自己把学到的应用到实际工作中,当你看到学有所用的时候,大脑会形成正向反馈,越学越有劲,很快就学会了。




