
万能 Transformer,你应该知道的一切
共 15304字,需浏览 31分钟
·
2021-01-05 16:55

极市导读
本文详细介绍了Transformer结构(Encoder/Decoder)、Efficient Transformers、Language models以及Transformer预训练技术等。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面:自 2017 年 Transformer 技术出现以来,便在 NLP、CV、语音、生物、化学等领域引起了诸多进展。知源月旦团队期望通过“Transformer+X” 梳理清 Transformer 技术的发展脉络,以及其在各领域中的应用进展,以期推动 Transformer 技术在更多领域中的应用。限于篇幅,在这篇推文中,我们先介绍 Transformer 的基本知识,以及其在 NLP 领域的研究进展;后续我们将介绍 Transformer + CV / 语音/生物/化学等的研究。
01
1.1 Transformer 结构
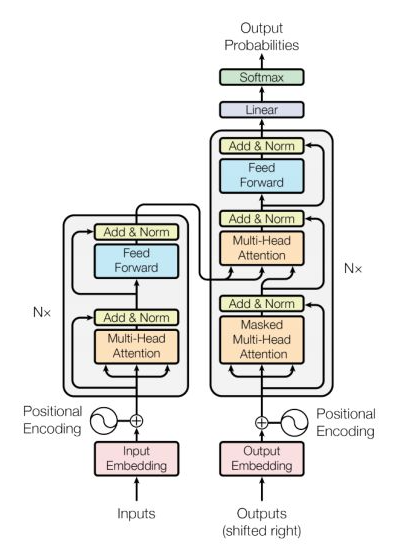
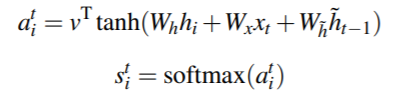

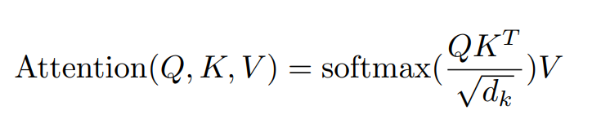

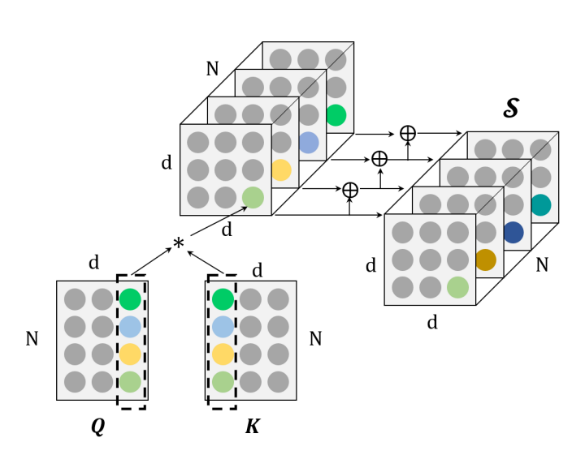
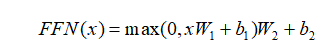
 ],同一个 Encoder 或者 Decoder 中的不同x共享
],同一个 Encoder 或者 Decoder 中的不同x共享  ,
,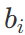 ,不同 Encoder 和 Decoder 之间不共享参数。
,不同 Encoder 和 Decoder 之间不共享参数。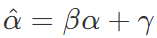 ,转换成
,转换成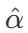 ,这样进入激活函数的输入将不受内部协变量影响,加快了模型训练的收敛速度[11]。
,这样进入激活函数的输入将不受内部协变量影响,加快了模型训练的收敛速度[11]。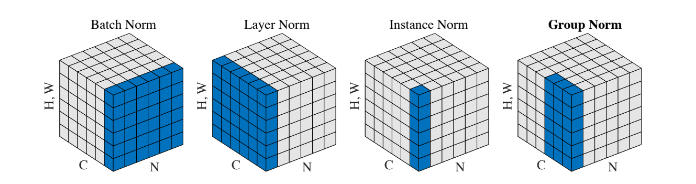
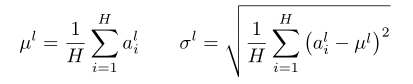
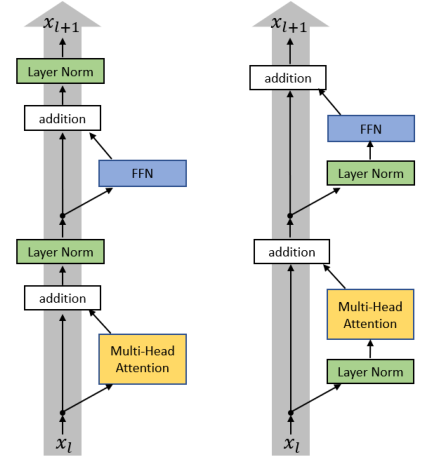
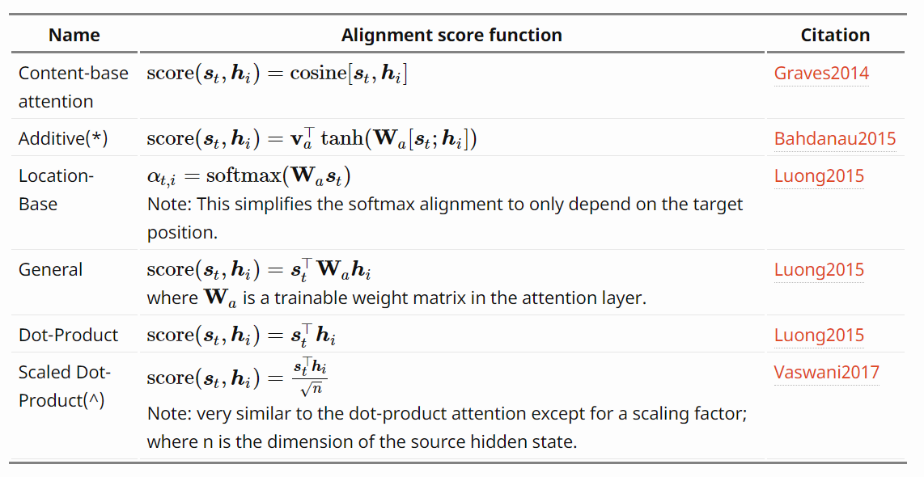
1.2 Efficient Transformers


1.3 Language models
02
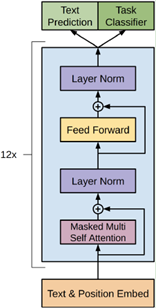
2.1 预训练技术
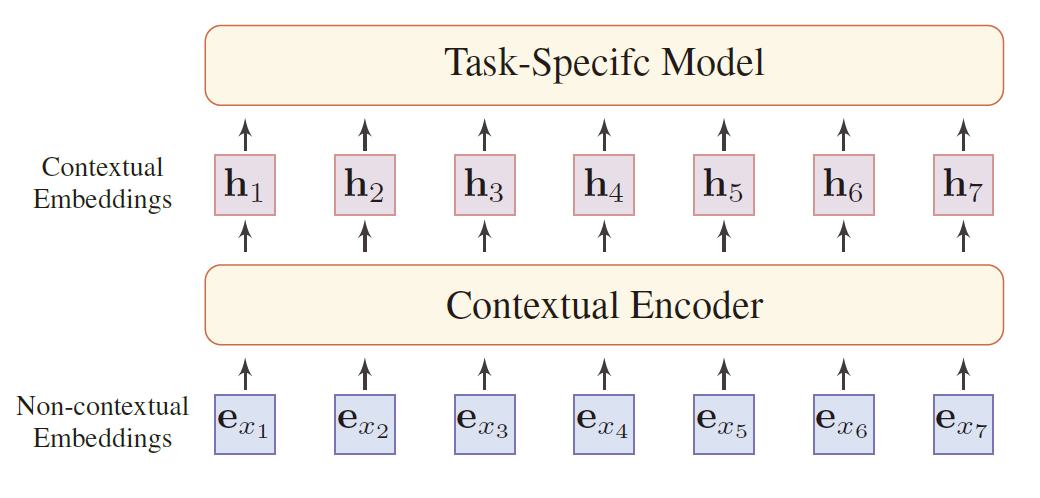
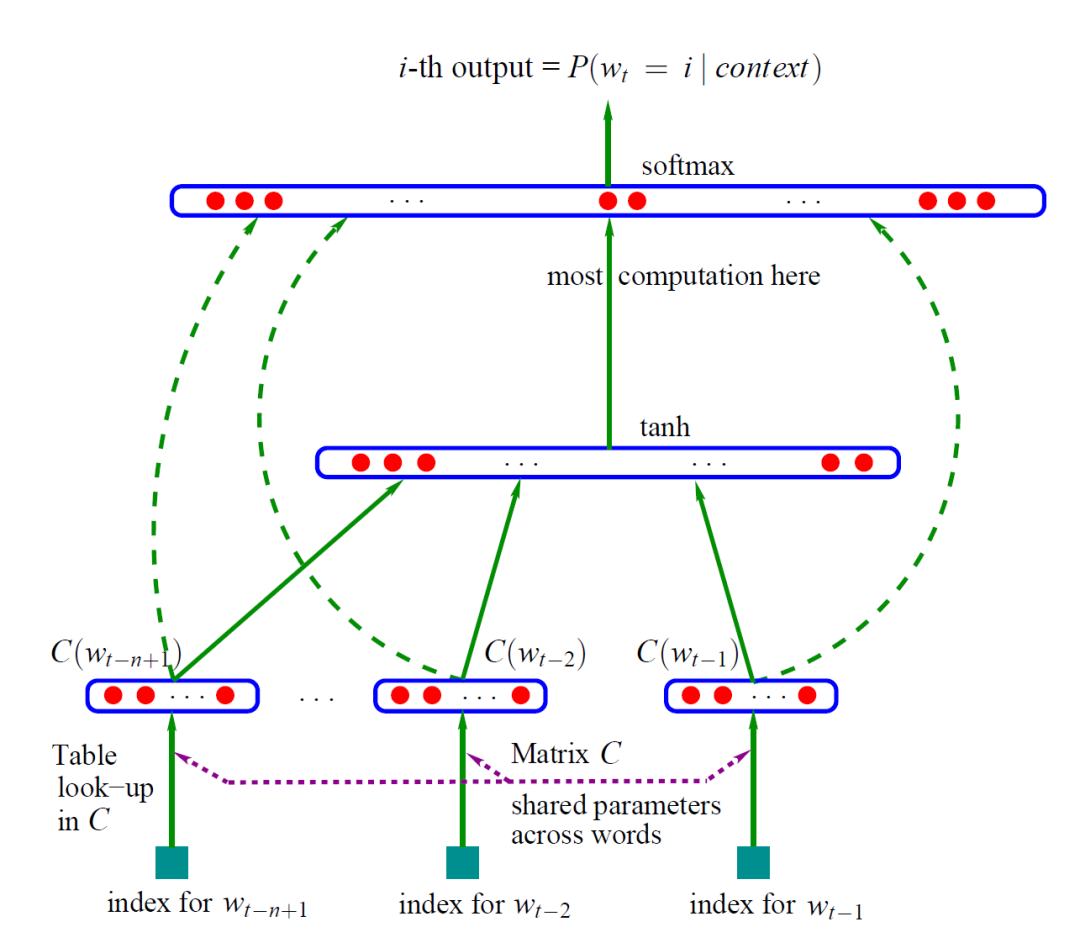
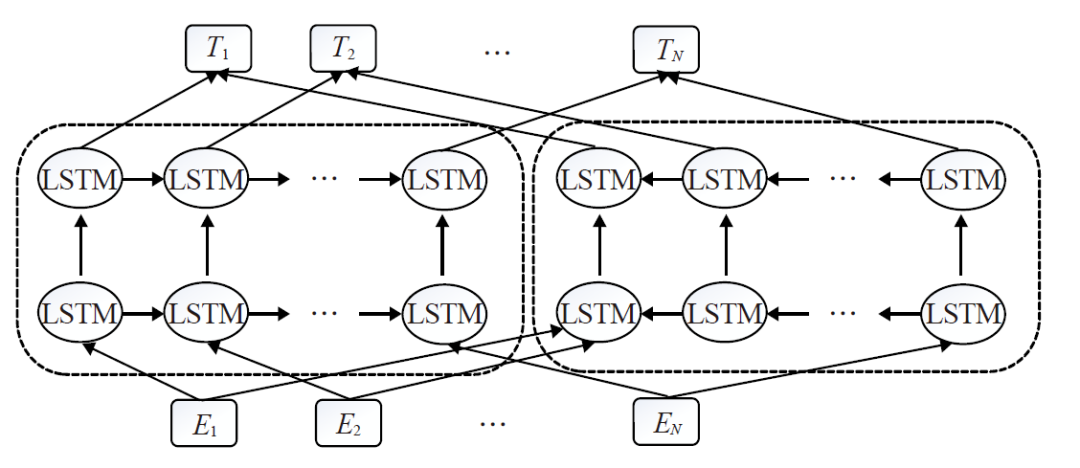
2.2 方法介绍
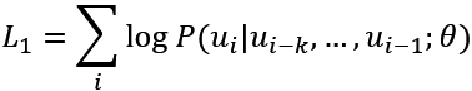
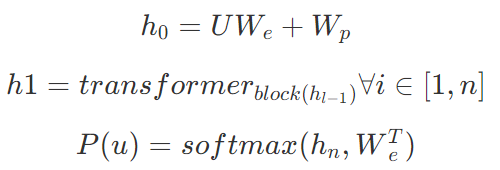
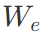 表示词嵌入矩阵,
表示词嵌入矩阵,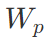 表示位置嵌入矩阵。
表示位置嵌入矩阵。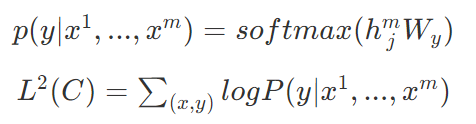
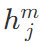 为预训练阶段最后一个词的输出 。
为预训练阶段最后一个词的输出 。
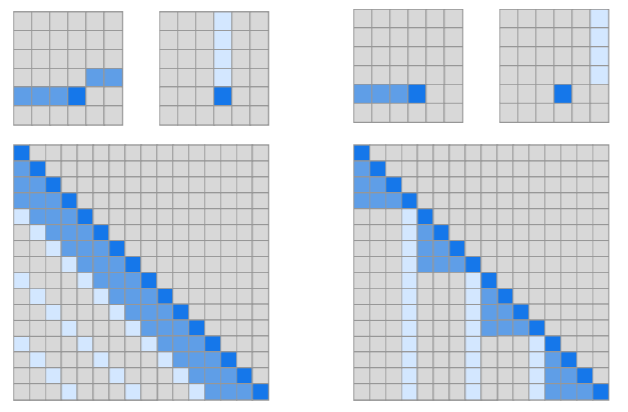
Fixed Patterns(固定模式):将视野限定为固定的预定义模式,例如局部窗口、固定步幅块,用于简化注意力矩阵;
Combination of Patterns(组合模式):通过组合两个或多个不同的模式来提高效率;
Learnable Patterns(可学习模式):以数据驱动的方式学习访问模式,关键在于确定 Token 相关性。
Memory(内存):利用可以一次访问多个 Token 的内存模块,例如全局存储器。
Low Rank(低秩):通过利用自注意力矩阵的低秩近似,来提高效率。
Kernels(内核):通过内核化的方式提高效率,其中核是注意力矩阵的近似,可视为低秩方法的一种。
Recurrence(递归):利用递归,连接矩阵分块法中的各个块,最终提高效率。
推荐阅读
搞懂Transformer结构,看这篇PyTorch实现就够了
2020 谷歌最新研究综述:Efficient Transformers: A Survey
3W字长文带你轻松入门视觉Transformer
