
Transformers是一种图神经网络
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Chaitanya Joshi
编译:ronghuaiyang
这个观点的目的是构建Transformer结构背后的NLP上的直觉,以及与图神经网络的联系。

工程师朋友经常问我:“图深度学习”听起来很厉害,但有什么大的商业成功的故事吗?它有没有被部署在实际app中?
除了Pinterest、阿里巴巴和Twitter的推荐系统外,一个非常小的成功就是Transformer结构,这个结构带来了NLP的风暴。
通过这篇文章,我想在Graph Neural Networks (GNNs)和transformer之间建立联系。我会讨论NLP和GNN社区中,模型架构背后的直觉,使用方程和图把这两者建立联系,并讨论如何把这两个放到一起工作来得到进展。
让我们先谈谈模型架构的目的 —— 表示学习。
NLP的表示学习
在较高的层次上,所有的神经网络架构都将输入数据构建为向量/嵌入的“表示”,它们编码和数据有关的有用的统计和语义信息。这些潜在的或隐藏的表示可以用于执行一些有用的操作,比如对图像进行分类或翻译句子。神经网络通过接收反馈(通常是通过误差/损失函数)来“学习”,建立越来越好的表示。
对于自然语言处理(NLP),通常,递归神经网络(RNNs)以顺序的方式构建句子中每个单词的表示,即,一次一个单词。直观地说,我们可以把RNN层想象成一条传送带,上面的文字从左到右进行递归处理。最后,我们得到了句子中每个单词的隐藏特征,我们将其传递给下一个RNN层或用于我们的NLP任务。
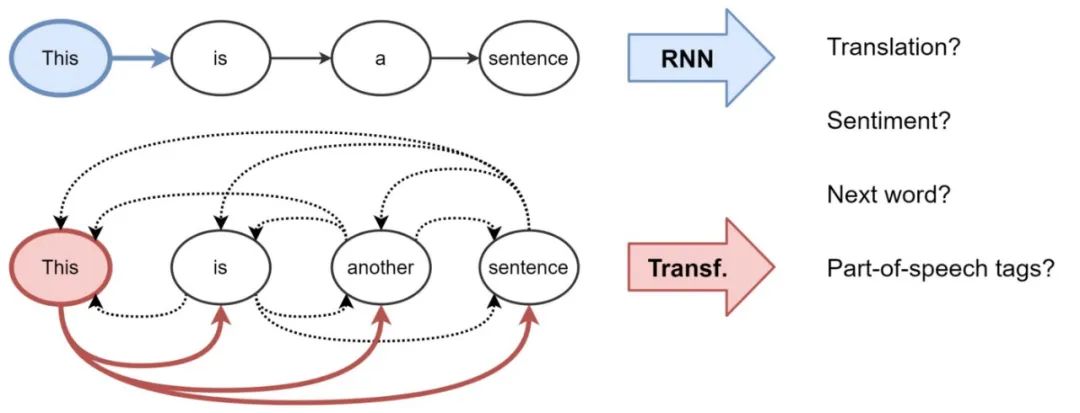
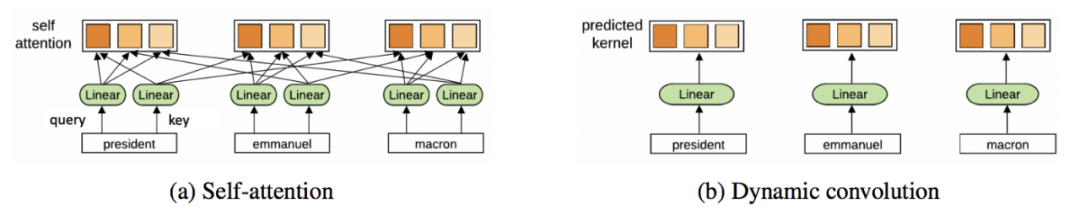
Transformers最初是为机器翻译而引入的,现在已经逐渐取代了主流NLP中的RNNs。这个架构使用了一种全新的方式来进行表示学习:不需要进行递归,Transformers使用注意力机制构建每个单词的特征,找出句子中的其他词对于前面之前的词的重要程度。知道了这一点,单词的特征更新就是所有其他单词特征的线性变换的总和,并根据它们的重要性进行加权。
拆解Transformer
让我们通过将前一段翻译成数学符号和向量的语言来发展关于架构的直觉。我们在句子S中从第l层到第l+1层更新第i个单词的隐藏特征h:
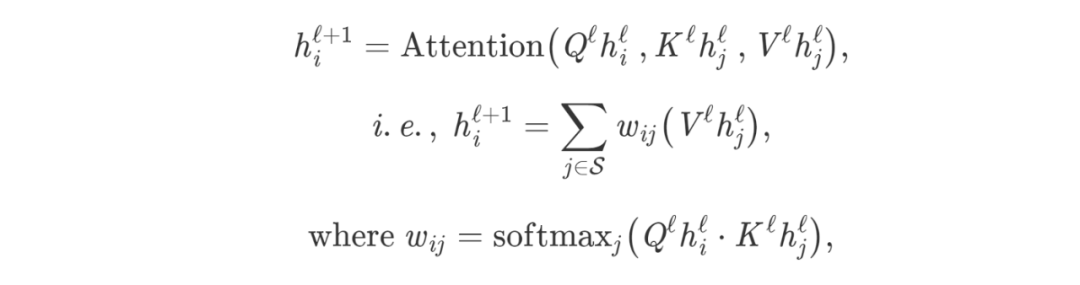
其中j∈S表示句子中的词集,Q、K、V为可学习的线性权值(分别表示注意力计算的Query、Key和V值)。对于Transformers,注意力机制是对句子中的每个单词并行执行的,RNNs是一个词一个词的进行更新。
通过以下pipeline,我们可以更好地了解注意力机制:
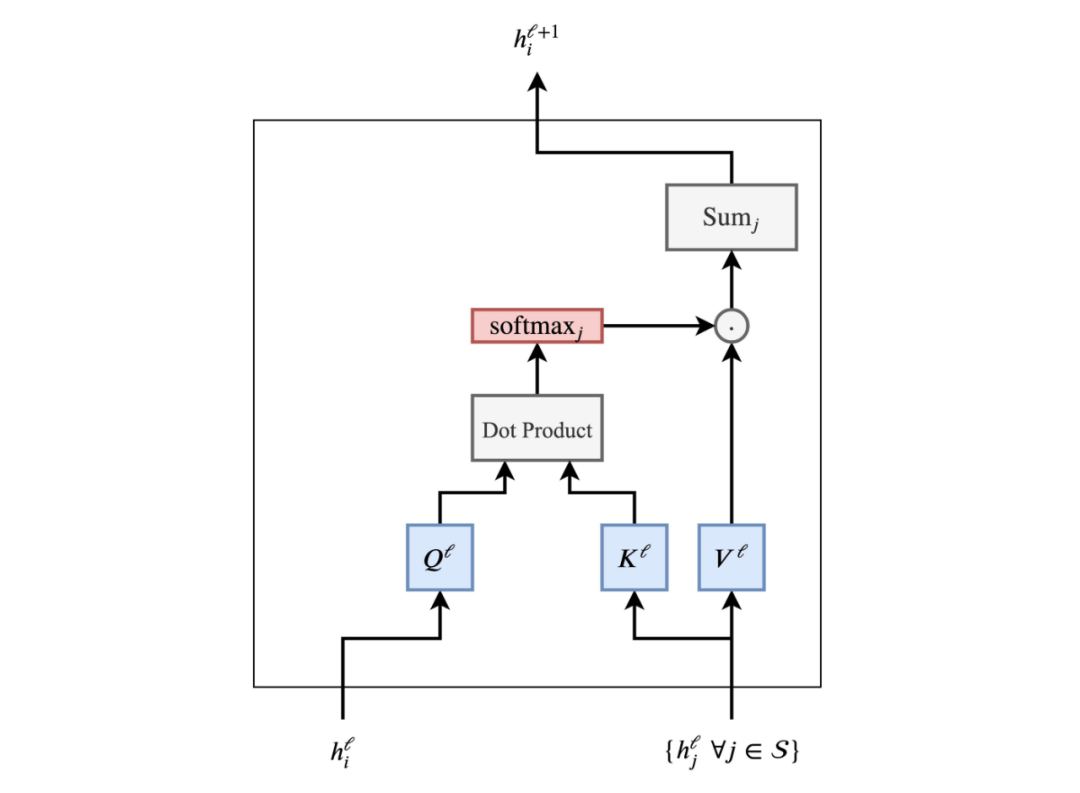
用这个词的特征h_i ^ℓ^和句子中的其他的词的特征h_j ^ℓ^,∀j∈S,我们通过点积为每一对(i, j)计算注意力权重w~ij~,然后对所有的j计算softmax。最后,对所有的h_j ^ℓ^进行加权求和,产生更新的词的特征h_i ^{ℓ+ 1}。句子中的每个词都并行地经历同一个pipeline,以更新其特征。
多头注意力机制
要让这种点积注意力机制发挥作用是很棘手的,因为随机初始化会破坏学习过程的稳定性。我们可以通过并行地执行多个“头”的注意力,并连接结果来克服这个问题(现在每个头都有独立的可学习的权重):
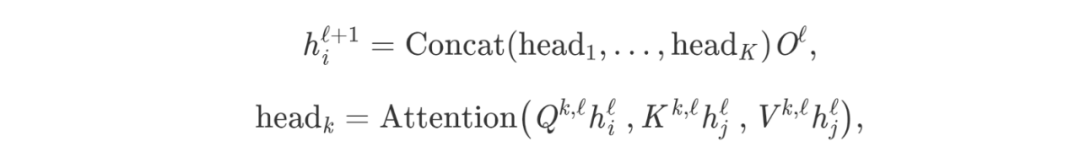
其中,Q^k^,K^k^,V^k^是第k个注意力头的可学习的权重,O是降维投影,为了匹配特征的维度。
多个头可以让注意力机制从本质上“对冲赌注”,观察前一层隐藏特征的不同的转换或不同的方面。我们稍后会详细讨论。
尺度问题以及前馈层
Transformer架构的一个关键问题是,词的特征在注意力机制之后可能是不同尺度,(1)这是由于当对其他的单词特征进行求和的时候,这些单词的权重可能有非常shape的分布。(2)在个体的特征向量层面上,拼接多个注意力头可能输出不同的尺度的值,导致最后的值具有很宽的动态范围。照传统的ML的经验,在pipeline中添加一归一化层似乎是合理的。
Transformer通过LayerNorm克服了问题,它在特征级别归一化和学习仿射变换。此外,通过特征维度的平方根来缩放点积注意力有助于抵消问题(1)。
最后,作者提出了另一个控制尺度问题的“技巧”:一个position-wise的2层MLP。多头的注意力之后,通过一个可学习的权重,他们把向量*h_i ^{ℓ+ 1}*投影到更高的维度上,然后通过ReLU再投影回原来的尺寸,再接另一个归一化:

老实说,我不确定这个过于参数化的前馈子层背后的确切直觉是什么,而且似乎也没有人对它提出问题!我认为LayerNorm和缩放的点积并没有完全解决这个问题,所以大的MLP是一种独立地重新缩放特征向量的hack。
Transformer层的最终看起来是这样的:
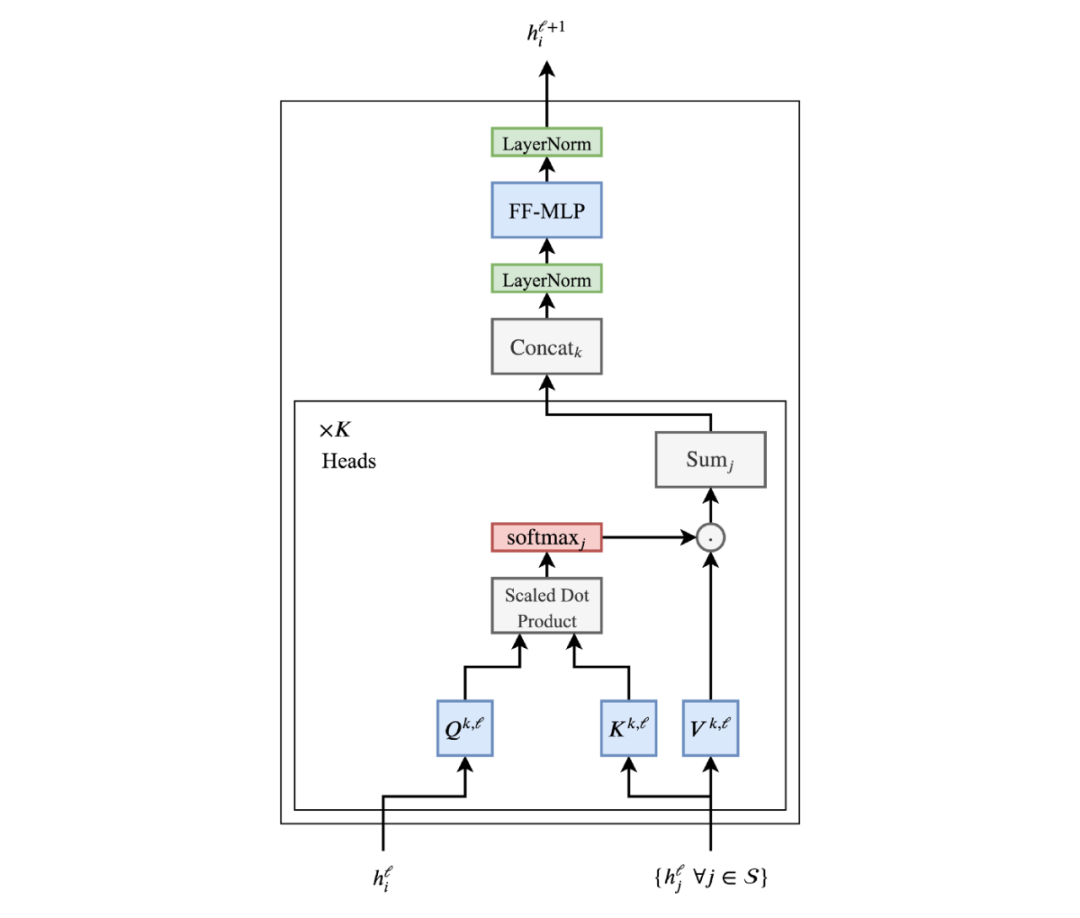
Transformer架构也非常适合深度网络,使得NLP社区在模型参数和数据方面都能进行扩展。每个多头注意子层和前馈子层的输入和输出之间的残差连接是叠加Transformer层的关键(但为了清楚起见在图中省略)。
用GNNs构建图的表示
让我们暂时离开NLP。
图神经网络(GNNs)或图卷积网络(GCNs)构建图数据中的节点和边的表示。它们通过邻域聚合(或消息传递)来实现,其中每个节点从其邻域收集特征,以更新其周围的局部的图结构的表示。堆叠几个GNN层使模型能够在整个图中传播每个节点的特征 —— 从它的邻居传播到邻居的邻居,等等。
在其最基本的形式中,GNN在第ℓ层通过对节点自身的特征和邻居节点的特征非线性变换的方式进行聚合,更新节点i的隐藏特征h:
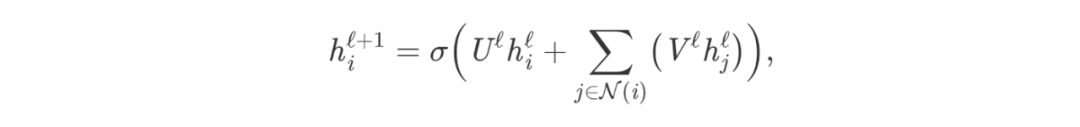
其中U、V为GNN层的可学习权重矩阵,σ为ReLU等非线性变换。
邻居节点的总和*j∈N(i)*可以被其他输入大小不变的聚合函数代替,比如简单的mean/max,或者更强大的函数,比如通过注意力机制的加权和。
听起来耳熟吗?
也许一个pipeline有助于建立联系:
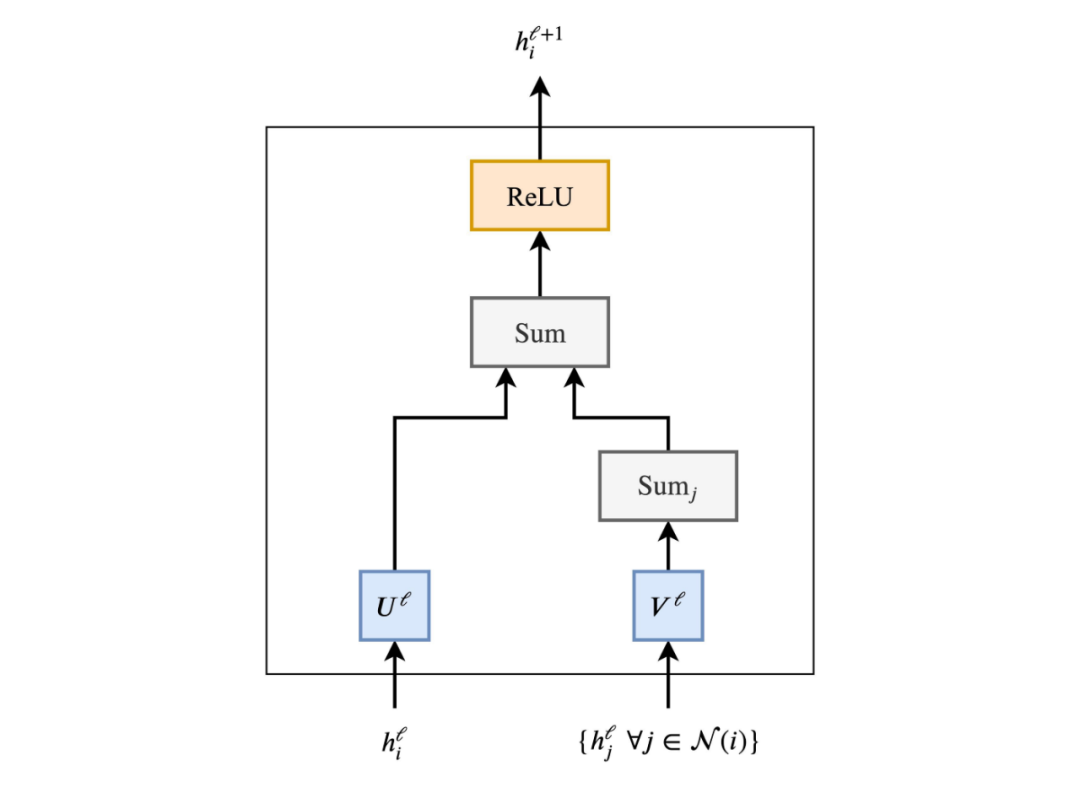
如果我们将多个并行的邻域头进行聚合,并将邻域j的求和替换为注意力机制,即加权和,我们就得到图注意力网络 (GAT)。加上归一化和前馈MLP,看,我们得到一个图Transformer!
句子是完全联通的词图
为了使这种联系更加明确,可以把一个句子看作是一个完全连通的图,其中每个单词都与其他单词相连。现在,我们可以使用GNN为图(句子)中的每个节点(单词)构建特征,然后我们可以使用它执行NLP任务。
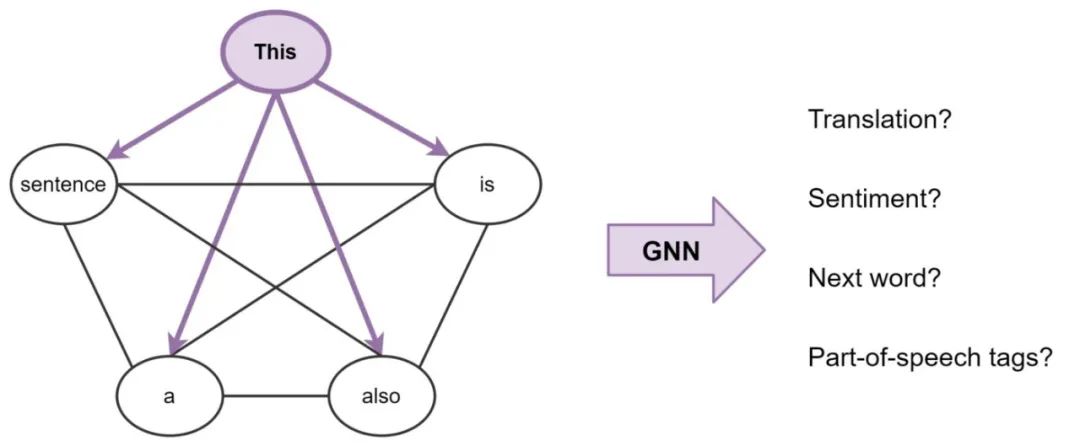
广义上说,这就是Transformers 正在做的事情:它们是带有多头注意力的GNN,作为邻居的聚合函数。标准的GNNs从其局部邻居节点j∈N(i)中聚合特征,而NLP的Transformers将整个句子S作为局部邻居,从每一层的每个单词j∈S中聚合特征。
重要的是,各种针对特定问题的技巧 —— 比如位置编码、因果/隐藏聚合、学习率策略和预训练 ——对Transformers 的成功至关重要,但很少在GNN社区中出现。同时,从GNN的角度来看Transformers可以让我们摆脱架构中的许多花哨的东西。
我们可以相互学到点什么?
现在我们已经在Transformers和GNN之间建立了联系,让我来谈谈……
全连通图是NLP的最佳输入格式吗?
在统计NLP和ML之前,像Noam Chomsky这样的语言学家专注于发展语言结构的正式理论,比如语法树/图。Tree LSTMs已经尝试过了,但是也许transformer/GNNs是更好的架构,可以让语言理论和统计NLP的世界更靠近?
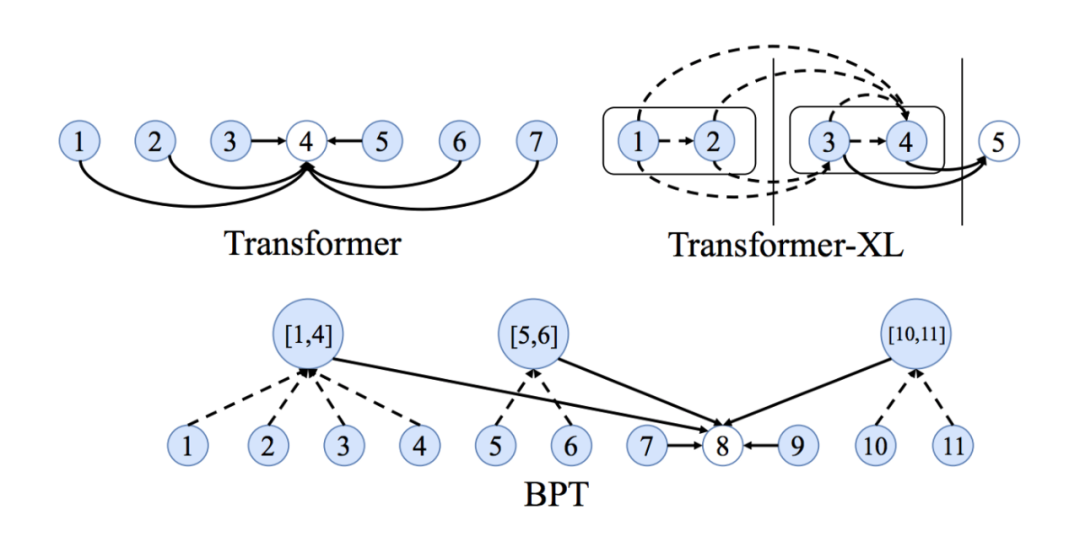
如何学习长期的依赖?
完全连通图的另一个问题是,它们让学习单词之间的长期依赖关系变得很困难。这仅仅是因为图中的边的数量是如何随着节点的数量以平方量级增长的。在一个有n个单词的句子中,一个Transformer/GNN将对n^2^个单词对进行计算。对于非常大的n,就没办法处理了。
NLP社区对长序列和依赖问题的看法很有趣:让注意力力机制变得稀疏或者可以自适应输入的大小,对每一层添加递归或压缩,使用局部敏感哈希来获得有效的注意力,都是改善Transformer的有前途的新想法。
看到来自GNN社区的想法加入其中将是很有趣的,例如使用划分二部图的方式用于句子图稀疏化似乎是另一种令人兴奋的方法。
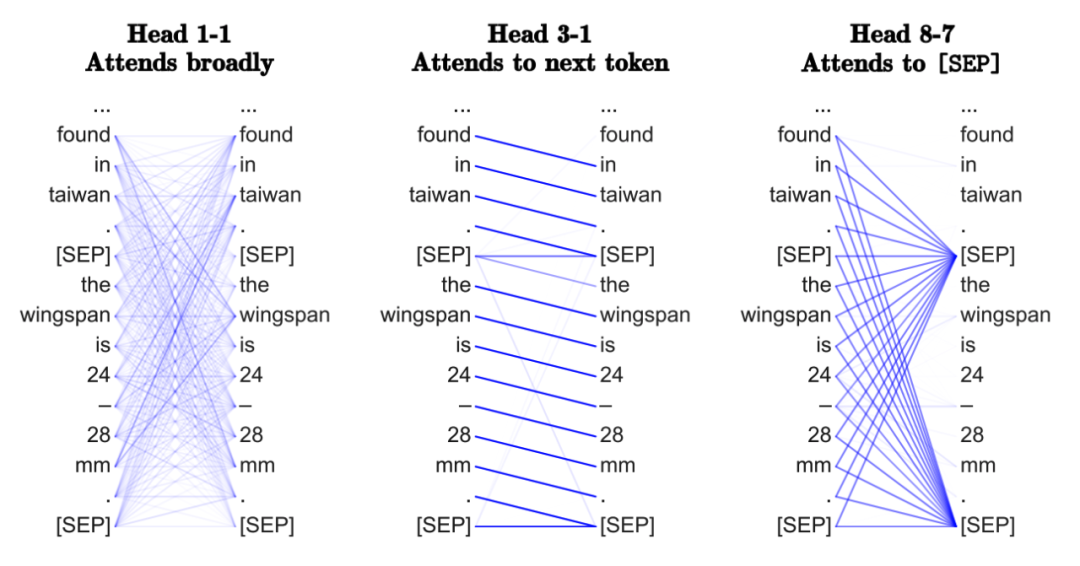
Transformers在学习“神经语法吗” ?
有几个有趣的文章来自NLP社区,是有关Transformers可能正在学习的内容。它的基本前提是,对句子中的所有词进行关注,以确定对哪些词最感兴趣,从而使“Transformers”能够学习一些类似于特定任务语法的东西。在多头注意力中,不同的头也可能“看”不同的句法属性。
用图的术语来说,通过在全图上使用GNN,我们能从GNN如何在每一层执行邻居的聚合来恢复最重要的边缘(以及它们可能包含的内容)吗?对于这个观点,我并不那么信服。
为什是多头注意力?为什么是注意力?
我更赞同多头机制的优化视图 —— 拥有多个注意力头改进了学习并克服了错误的随机初始化。例如,这些论文表明Transformer 头可以在训练被“修剪”或删除,而不会对性能产生显著影响。
多头邻居聚合机制在GNNs中也被证明是有效的,例如,GAT使用相同的多头注意力和MoNet使用多个高斯核聚合特征。虽然是为了稳定注意力机制而发明的,但是多头机制会成为压榨模型性能的标准操作吗?
相反,具有简单聚合函数(如sum或max)的GNN不需要多个聚合头进行稳定的训练。如果我们不需要计算句子中每个词对之间的配对兼容性,对Transformers来说不是很好吗?
Transformers能从完全摆脱注意力中获益吗?Yann Dauphin和合作者的最近工作提出了一种替代的ConvNet的架构。Transformers也可能最终会做一些类似的事情。
为什么训练Transformers 这么难?
阅读Transformer的新论文让我觉得,在确定最佳学习率策略、热身策略和衰变设置时,训练这些模型需要类似于“黑魔法”的东西。这可能只是因为模型太大了,而NLP的研究任务太具有挑战性了。
最近的研究结果认为,也可能是因为归一化的具体排列和架构内的残差连接的原因。
在这一点上,我很愤怒,但这让我怀疑:我们真的需要多个头的昂贵的两两的注意力吗,过分参数化的MLP层,和复杂的学习率策略吗?
我们真的需要拥有这么大的模型吗?
对于手头的任务来说,具有良好的归纳偏差的架构不应该更容易训练吗?
进一步的阅读
这个博客并不是第一个将GNNs和Transformers联系起来的博客:以下是Arthur Szlam关于注意力/记忆网络、GNNs和Transformers之间的历史和联系的精彩演讲:https://ipam.wistia.com/medias/1zgl4lq6nh。同样,DeepMind的明星云集的position paper引入了图网络框架,统一了所有这些想法。DGL团队有一个关于把seq2seq问题转化为GNN的很好的教程:https://docs.dgl.ai/en/latest/tutorials/models/4_old_wines/7_transformer.html

英文原文:https://towardsdatascience.com/transformers-are-graph-neural-networks-bca9f75412aa