
实现延时任务的 4 种实现方案!
一、应用场景
在需求开发过程中,我们经常会遇到一些类似下面的场景:
a. 外卖订单超过15分钟未支付,自动取消
b. 使用抢票软件订到车票后,1小时内未支付,自动取消
c. 待处理申请超时1天,通知审核人员经理,超时2天通知审核人员总监
d. 客户预定自如房子后,24小时内未支付,房源自动释放
那么针对这类场景的需求应该如果实现呢,我们最先想到的一般是启个定时任务,来扫描数据库里符合条件的数据,并对其进行更新操作。一般来说spring-quartz 、elasticjob 就可以实现,甚至自己写个 Timer 也可以。
但是这种方式有个弊端,就是需要不停的扫描数据库,如果数据量比较大,并且任务执行间隔时间比较短,对数据库会有一定的压力。另外定时任务的执行间隔时间的粒度也不太好设置,设置长会影响时效性,设置太短又会增加服务压力。我们来看一下有没有更好的实现方式。
二、JDK 延时队列实现
DelayQueue 是 JDK 中 java.util.concurrent 包下的一种无界阻塞队列,底层是优先队列 PriorityQueue。对于放到队列中的任务,可以按照到期时间进行排序,只需要取已经到期的元素处理即可。
具体的步骤是,要放入队列的元素需要实现 Delayed 接口并实现 getDelay 方法来计算到期时间,compare 方法来对比到期时间以进行排序。一个简单的使用例子如下:
package com.lyqiang.delay.jdk;
import java.time.LocalDateTime;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
/**
* @author lyqiang
*/
public class TestDelayQueue {
public static void main(String[] args) throws InterruptedException {
// 新建3个任务,并依次设置超时时间为 20s 10s 30s
DelayTask d1 = new DelayTask(1, System.currentTimeMillis() + 20000L);
DelayTask d2 = new DelayTask(2, System.currentTimeMillis() + 10000L);
DelayTask d3 = new DelayTask(3, System.currentTimeMillis() + 30000L);
DelayQueuequeue = new DelayQueue<>();
queue.add(d1);
queue.add(d2);
queue.add(d3);
int size = queue.size();
System.out.println("当前时间是:" + LocalDateTime.now());
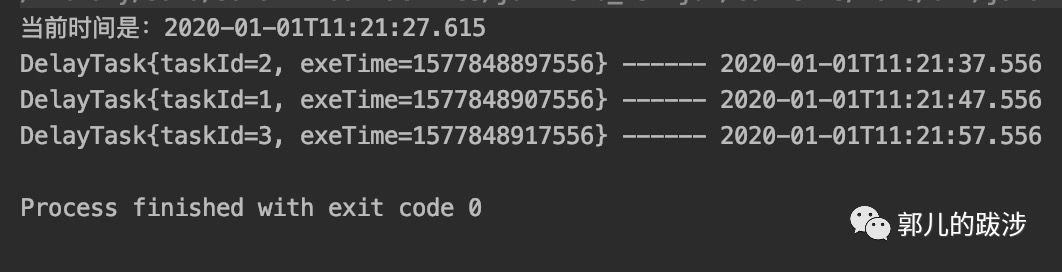
// 从延时队列中获取元素, 将输出 d2 、d1 、d3
for (int i = 0; i < size; i++) {
System.out.println(queue.take() + " ------ " + LocalDateTime.now());
}
}
}
class DelayTask implements Delayed {
private Integer taskId;
private long exeTime;
DelayTask(Integer taskId, long exeTime) {
this.taskId = taskId;
this.exeTime = exeTime;
}
@Override
public long getDelay(TimeUnit unit) {
return exeTime - System.currentTimeMillis();
}
@Override
public int compareTo(Delayed o) {
DelayTask t = (DelayTask) o;
if (this.exeTime - t.exeTime <= 0) {
return -1;
} else {
return 1;
}
}
@Override
public String toString() {
return "DelayTask{" +
"taskId=" + taskId +
", exeTime=" + exeTime +
'}';
}
}
代码的执行结果如下:
使用 DelayQueue, 只需要有一个线程不断从队列中获取数据即可,它的优点是不用引入第三方依赖,实现也很简单,缺点也很明显,它是内存存储,对分布式支持不友好,如果发生单点故障,可能会造成数据丢失,无界队列还存在 OOM 的风险。
三、时间轮算法实现
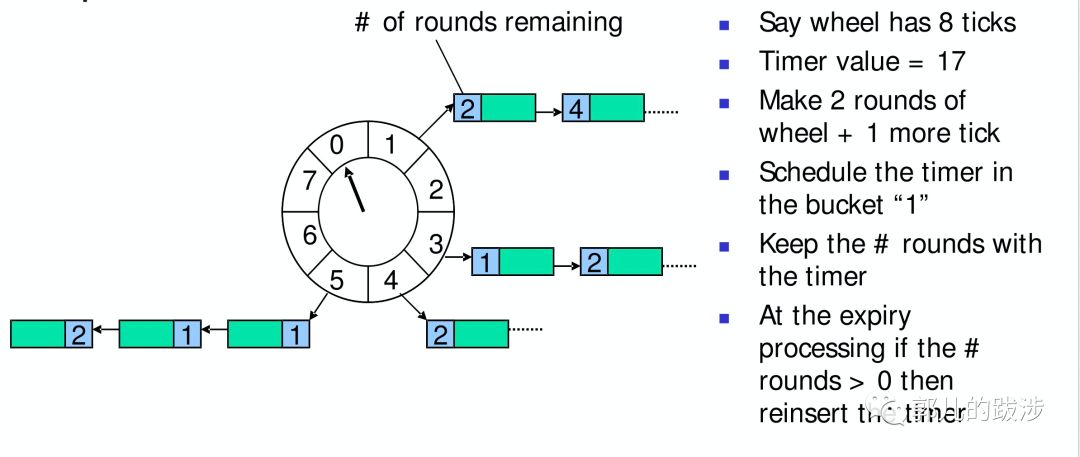
1996 年 George Varghese 和 Tony Lauck 的论文《Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facility》中提出了一种时间轮管理 Timeout 事件的方式。其设计非常巧妙,并且类似时钟的运行,如下图的原始时间轮有 8 个格子,假定指针经过每个格子花费时间是 1 个时间单位,当前指针指向 0,一个 17 个时间单位后超时的任务则需要运转 2 圈再通过一个格子后被执行,放在相同格子的任务会形成一个链表。
Netty 包里提供了一种时间轮的实现——HashedWheelTimer,其底层使用了数组+链表的数据结构,使用方式如下:
package com.lyqiang.delay.wheeltimer;
import io.netty.util.HashedWheelTimer;
import java.time.LocalDateTime;
import java.util.concurrent.TimeUnit;
/**
* @author lyqiang
*/
public class WheelTimerTest {
public static void main(String[] args) {
//设置每个格子是 100ms, 总共 256 个格子
HashedWheelTimer hashedWheelTimer = new HashedWheelTimer(100, TimeUnit.MILLISECONDS, 256);
//加入三个任务,依次设置超时时间是 10s 5s 20s
System.out.println("加入一个任务,ID = 1, time= " + LocalDateTime.now());
hashedWheelTimer.newTimeout(timeout -> {
System.out.println("执行一个任务,ID = 1, time= " + LocalDateTime.now());
}, 10, TimeUnit.SECONDS);
System.out.println("加入一个任务,ID = 2, time= " + LocalDateTime.now());
hashedWheelTimer.newTimeout(timeout -> {
System.out.println("执行一个任务,ID = 2, time= " + LocalDateTime.now());
}, 5, TimeUnit.SECONDS);
System.out.println("加入一个任务,ID = 3, time= " + LocalDateTime.now());
hashedWheelTimer.newTimeout(timeout -> {
System.out.println("执行一个任务,ID = 3, time= " + LocalDateTime.now());
}, 20, TimeUnit.SECONDS);
System.out.println("等待任务执行===========");
}
}
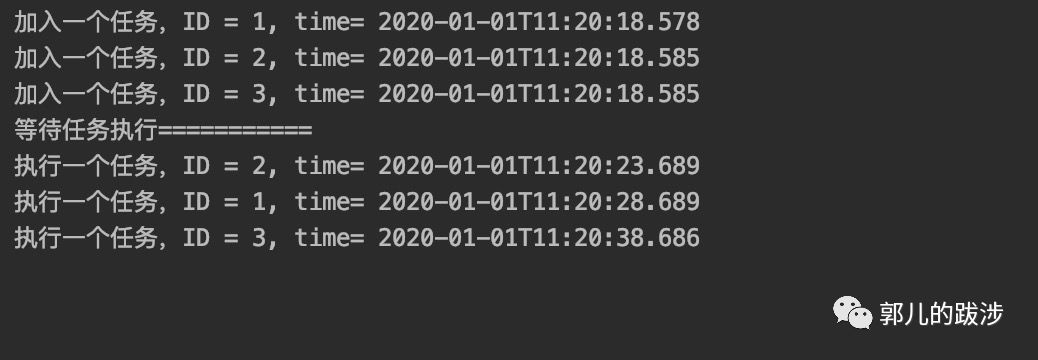
代码执行结果如下:
相比 DelayQueue 的数据结构,时间轮在算法复杂度上有一定优势,但用时间轮来实现延时任务同样避免不了单点故障。
四、Redis ZSet 实现
Redis 里有 5 种数据结构,最常用的是 String 和 Hash,而 ZSet 是一种支持按 score 排序的数据结构,每个元素都会关联一个 double 类型的分数,Redis 通过分数来为集合中的成员进行从小到大的排序,借助这个特性我们可以把超时时间作为 score 来将任务进行排序。
使用 zadd key score member 命令向 redis 中放入任务,超时时间作为 score, 任务 ID 作为 member, 使用 zrange key start stop withscores 命令从 redis 中读取任务,使用 zrem key member 命令从 redis 中删除任务。代码如下:
package com.lyqiang.delay.redis;
import java.time.LocalDateTime;
import java.util.Set;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* @author lyqiang
*/
public class TestRedisDelay {
public static void main(String[] args) {
TaskProducer taskProducer = new TaskProducer();
//创建 3个任务,并设置超时间为 10s 5s 20s
taskProducer.produce(1, System.currentTimeMillis() + 10000);
taskProducer.produce(2, System.currentTimeMillis() + 5000);
taskProducer.produce(3, System.currentTimeMillis() + 20000);
System.out.println("等待任务执行===========");
//消费端从redis中消费任务
TaskConsumer taskConsumer = new TaskConsumer();
taskConsumer.consumer();
}
}
class TaskProducer {
public void produce(Integer taskId, long exeTime) {
System.out.println("加入任务, taskId: " + taskId + ", exeTime: " + exeTime + ", 当前时间:" + LocalDateTime.now());
RedisOps.getJedis().zadd(RedisOps.key, exeTime, String.valueOf(taskId));
}
}
class TaskConsumer {
public void consumer() {
Executors.newSingleThreadExecutor().submit(new Runnable() {
@Override
public void run() {
while (true) {
SettaskIdSet = RedisOps.getJedis().zrangeByScore(RedisOps.key, 0, System.currentTimeMillis(), 0, 1);
if (taskIdSet == null || taskIdSet.isEmpty()) {
//System.out.println("没有任务");
} else {
taskIdSet.forEach(id -> {
long result = RedisOps.getJedis().zrem(RedisOps.key, id);
if (result == 1L) {
System.out.println("从延时队列中获取到任务,taskId:" + id + " , 当前时间:" + LocalDateTime.now());
}
});
}
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
}
}
执行结果如下:
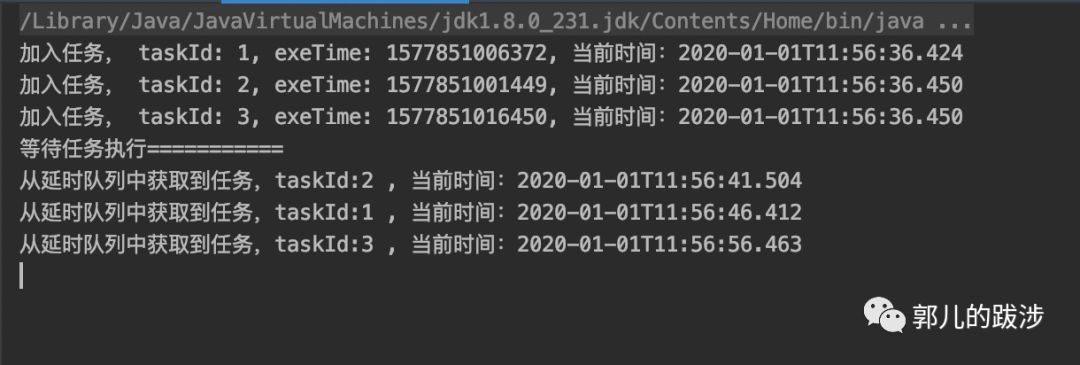
相比前两种实现方式,使用 Redis 可以将数据持久化到磁盘,规避了数据丢失的风险,并且支持分布式,避免了单点故障。
五、MQ 延时队列实现
以 RabbitMQ 为例,它本身并没有直接支持延时队列的功能,但是通过一些特性,我们可以达到实现延时队列的效果。
RabbitMQ 可以为 Queue 设置 TTL,,到了过期时间没有被消费的消息将变为死信——Dead Letter。我们还可以为Queue 设置死信转发 x-dead-letter-exchange,过期的消息可以被路由到另一个 Exchange。下图说明了这个流程,生产者通过不同的 RoutingKey 发送不同过期时间的消息,多个队列分别消费并产生死信后被路由到 exe-dead-exchange,再有一些队列绑定到这个 exchange,从而进行不同业务逻辑的消费。
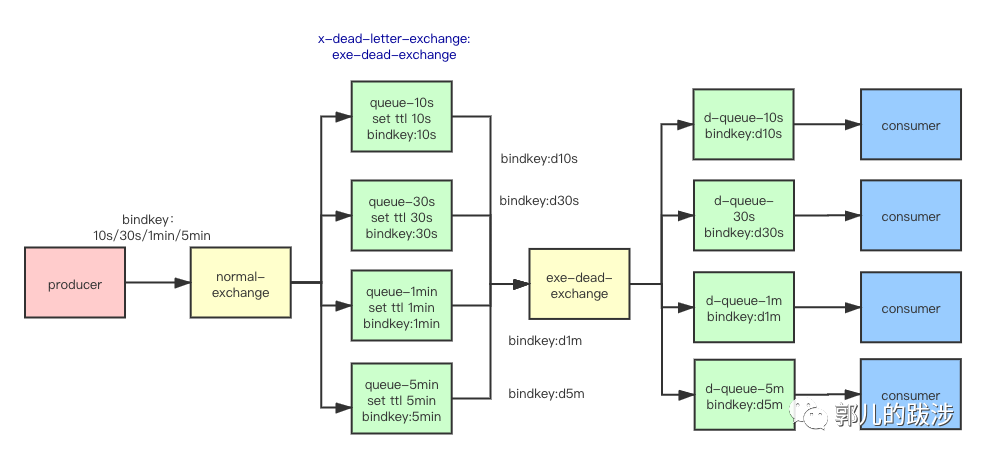
在 RabbitMQ 界面操作如下:
1、在 g_normal_exchange 发送测试消息
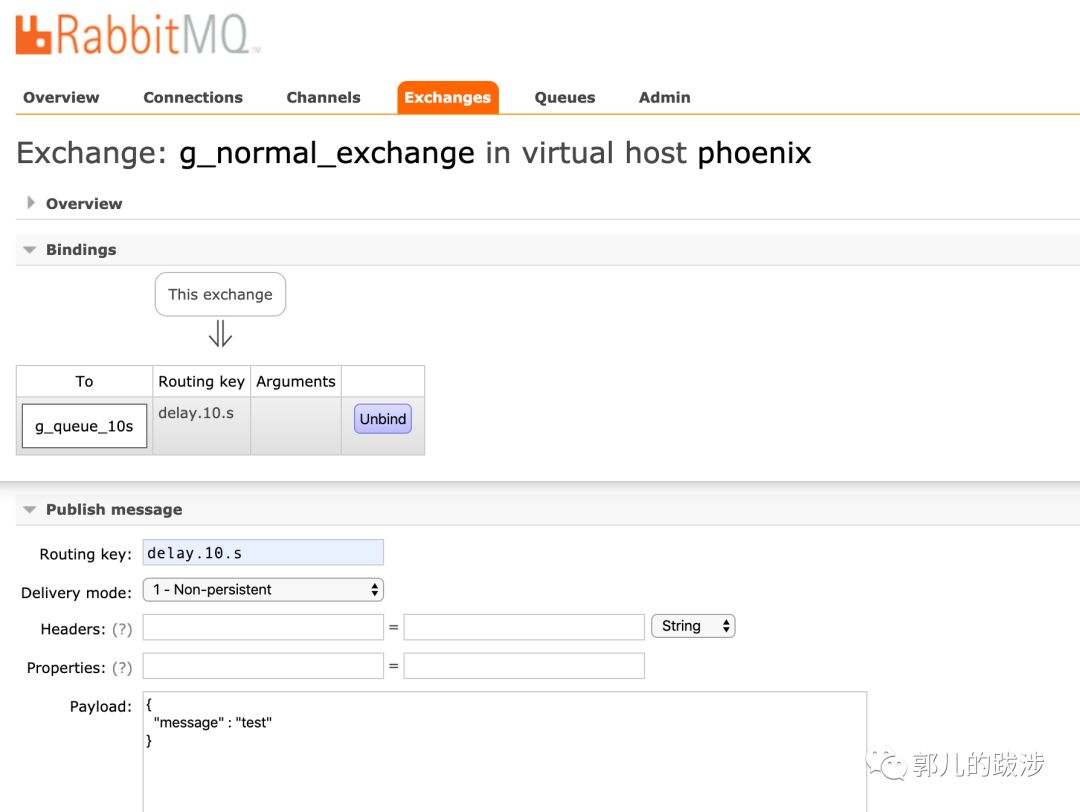
2. 队列 g_queue_10s 绑定到 g_normal_exchange,并设置 x-message-ttl 为 10s 过期,x-dead-letter-exchange 为 g_exe_dead_exchange,可以看到消息到达后,过了 10s 之后消息被路由到g_exe_dead_exchange
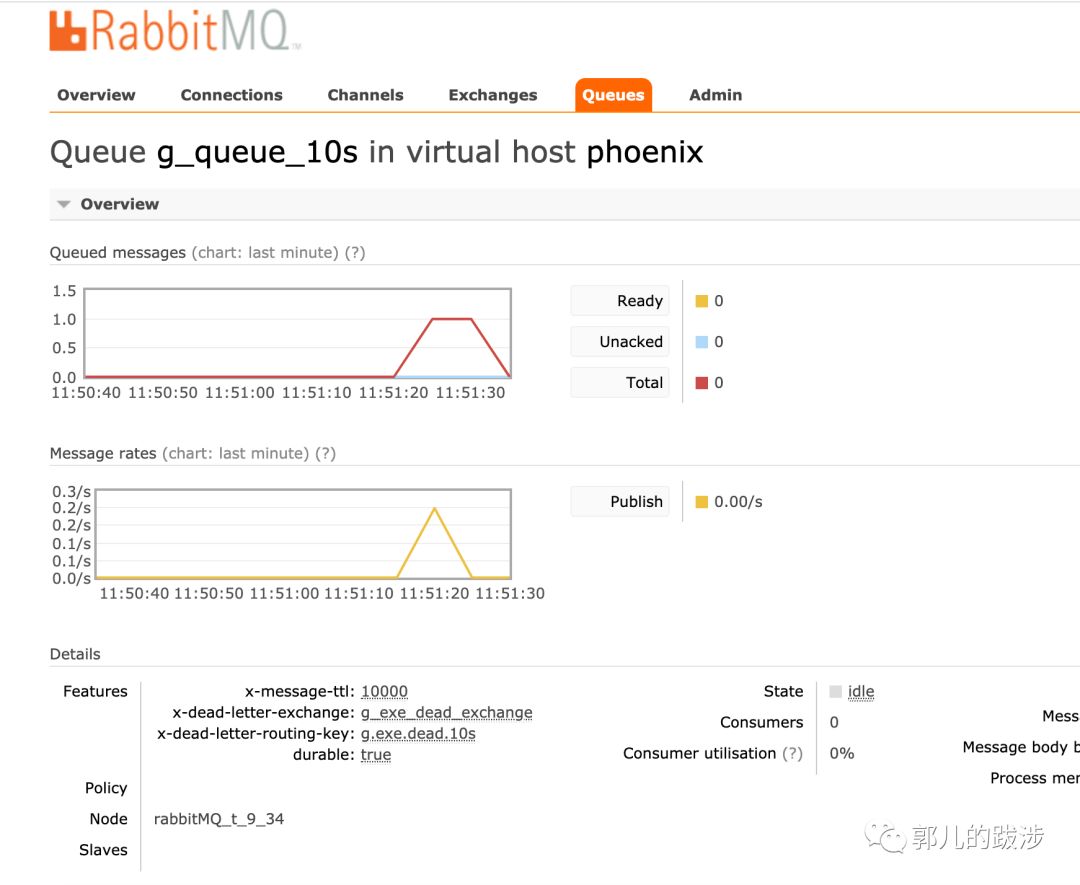
3. 绑定到 g_exe_dead_exchange 的队列 g_exe_10s_queue 消费到了这条消息
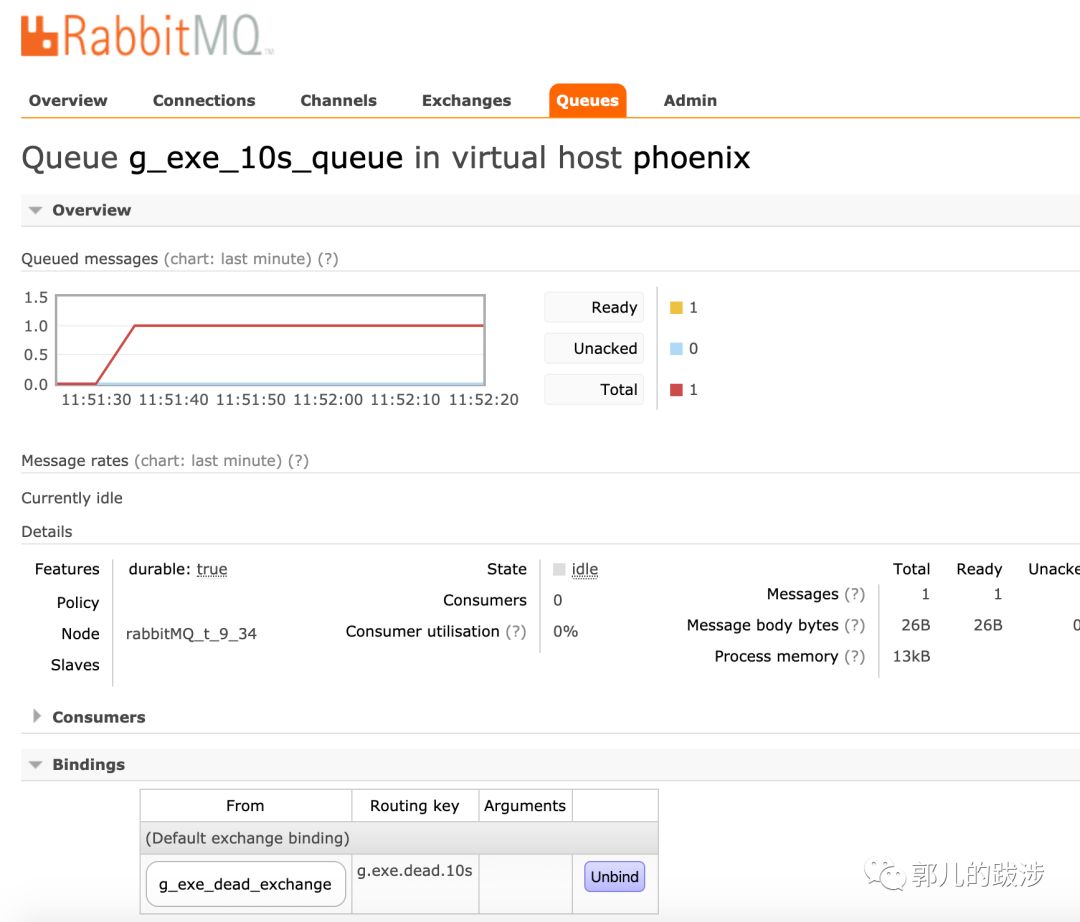
使用 MQ 实现的方式,支持分布式,并且消息支持持久化,在业内应用比较多,它的缺点是每种间隔时间的场景需要分别建立队列。
六、总结
通过上面不同实现方式的比较,可以很明显的看出各个方案的优缺点,在分布式系统中我们会优先考虑使用 Redis 和 MQ 的实现方式。
在需求开发中实现一个功能的方式多种多样,需要我们进行多维度的比较,才能选择出合理的、可靠的、高效的并且适合自己业务的解决方案。
点击「阅读原文」获取面试题大全~