
10分钟带你深入理解Transformer原理及实现
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|深度学习这件小事
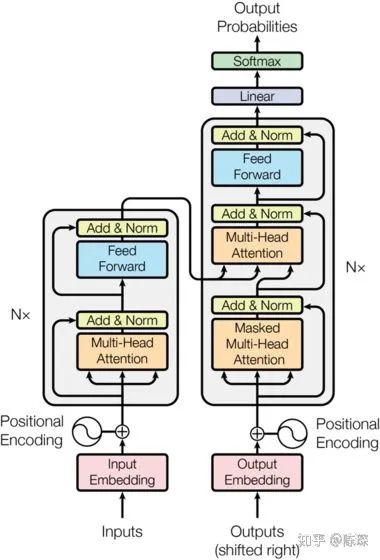
整体架构描述
Input & Output Embedding
OneHot Encoding
Word Embedding
Positional Embedding
Input short summary
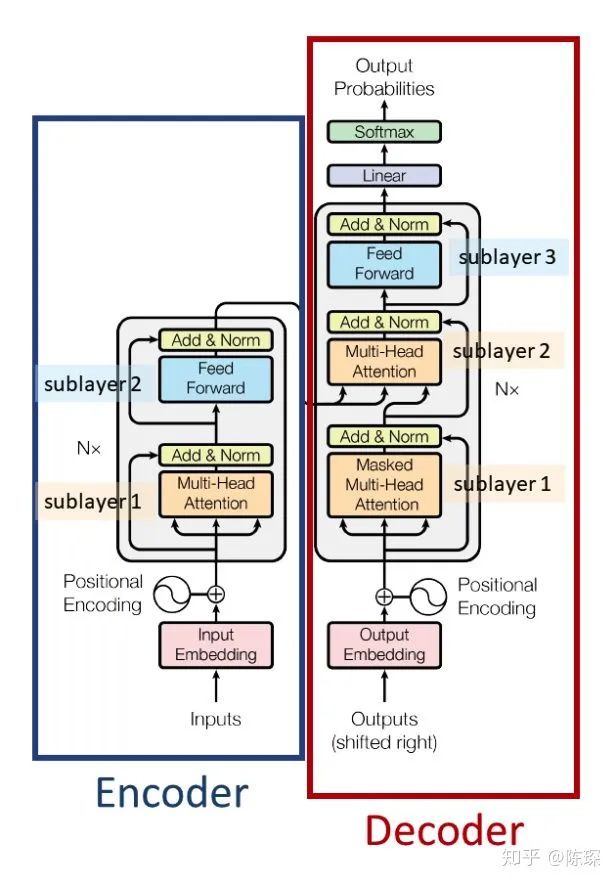
Encoder
Encoder Sub-layer 1: Multi-Head Attention Mechanism
Step 1
Step 2
Step 3
Encoder Sub-layer 2: Position-Wise fully connected feed-forward
Encoder short summary
Decoder
Diff_1:“masked” Multi-Headed Attention
Diff_2:encoder-decoder multi-head attention
Diff_3:Linear and Softmax to Produce Output Probabilities
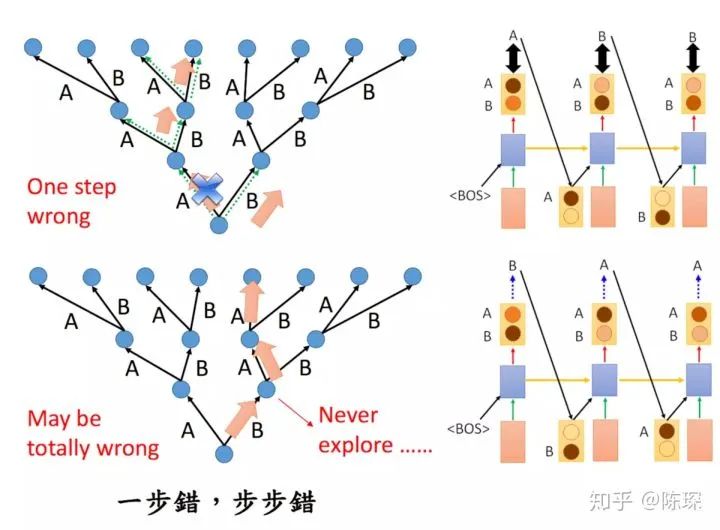
greedy search
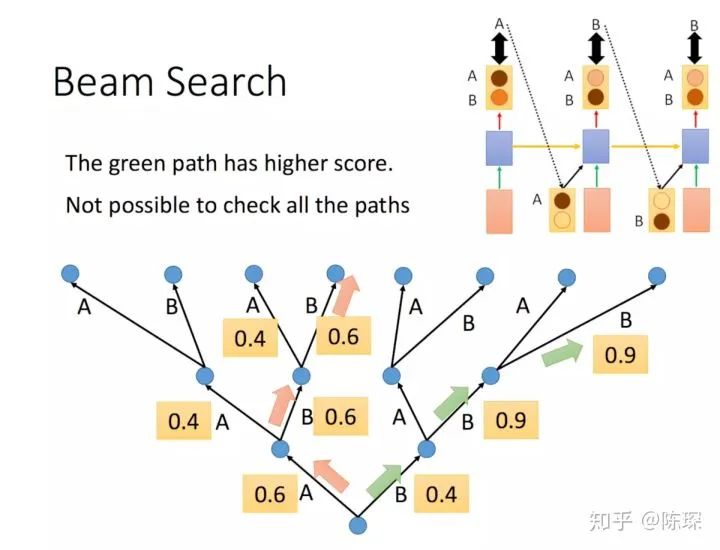
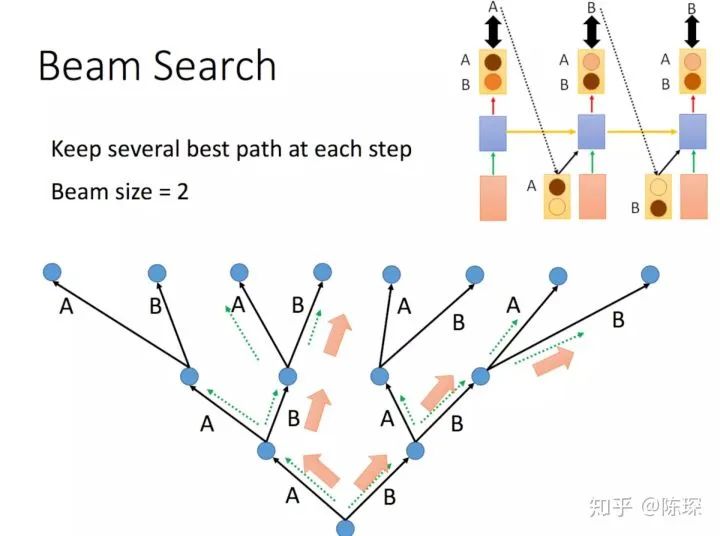
beam search
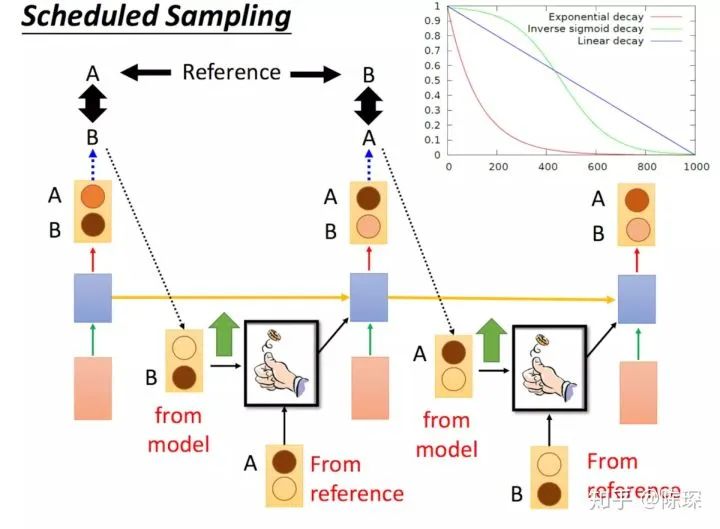
Scheduled Sampling
0.模型架构
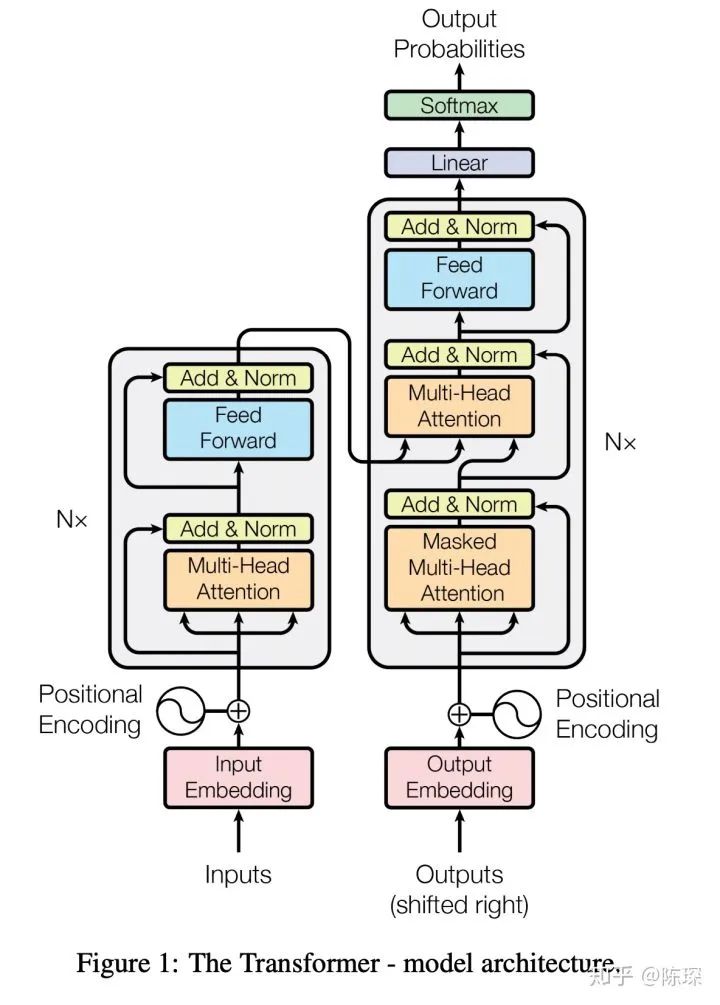

Embedding 部分
Encoder 部分
Decoder 部分
1. 对 Input 和 Output 进行 representation
1.1 对 Input 的 represent
1.2 word embedding
使用 pre-trained 的 embeddings 并固化,这种情况下实际就是一个 lookup table。
对其进行随机初始化(当然也可以选择 pre-trained 的结果),但设为 trainable。这样在 training 过程中不断地对 embeddings 进行改进。
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
1.3 Positional Embedding
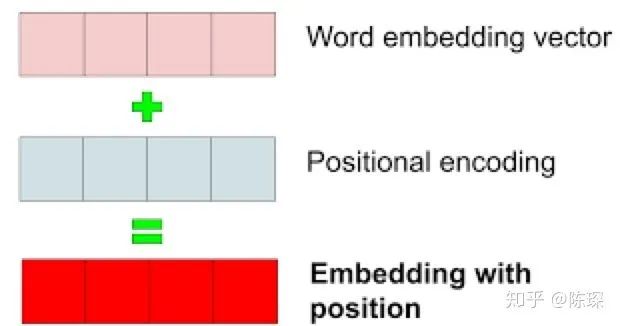
通过训练学习 positional encoding 向量
使用公式来计算 positional encoding向量
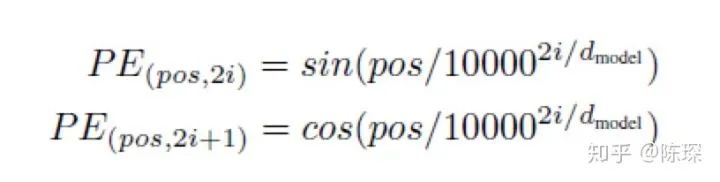
pos 指的是这个 word 在这个句子中的位置
i指的是 embedding 维度。比如选择 d_model=512,那么i就从1数到512

class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],requires_grad=False)
return self.dropout(x)
1.4 Input 小总结
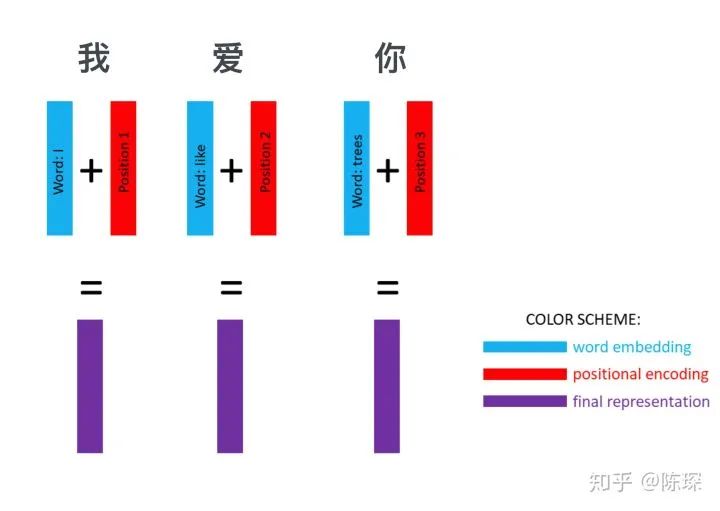
nbatches 指的是定义的 batch_size
L 指的是 sequence 的长度,(比如“我爱你”,L = 3)
512 指的是 embedding 的 dimension
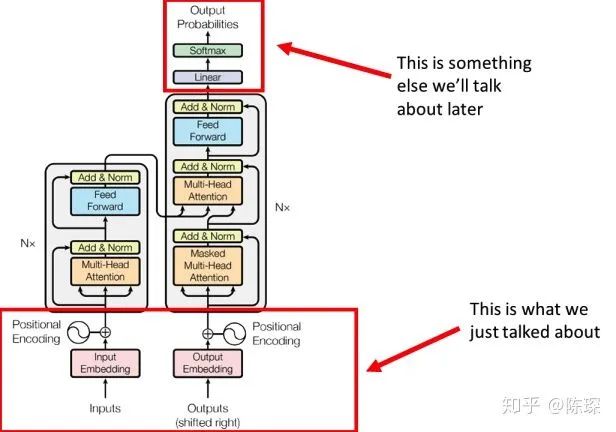
2. Encoder
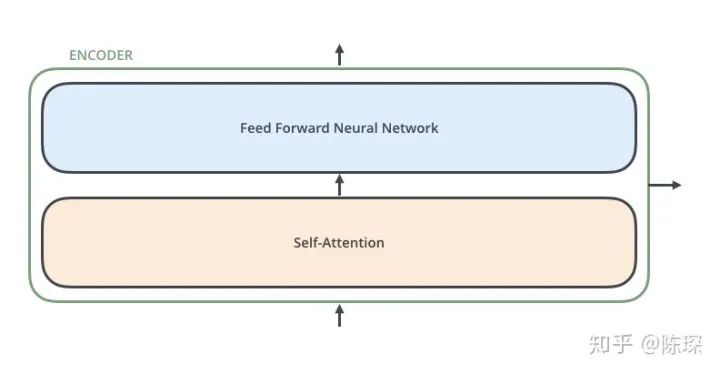
第一个是 ”multi-head self-attention mechanism“
第二个是 ”simple,position-wise fully connected feed-forward network“
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
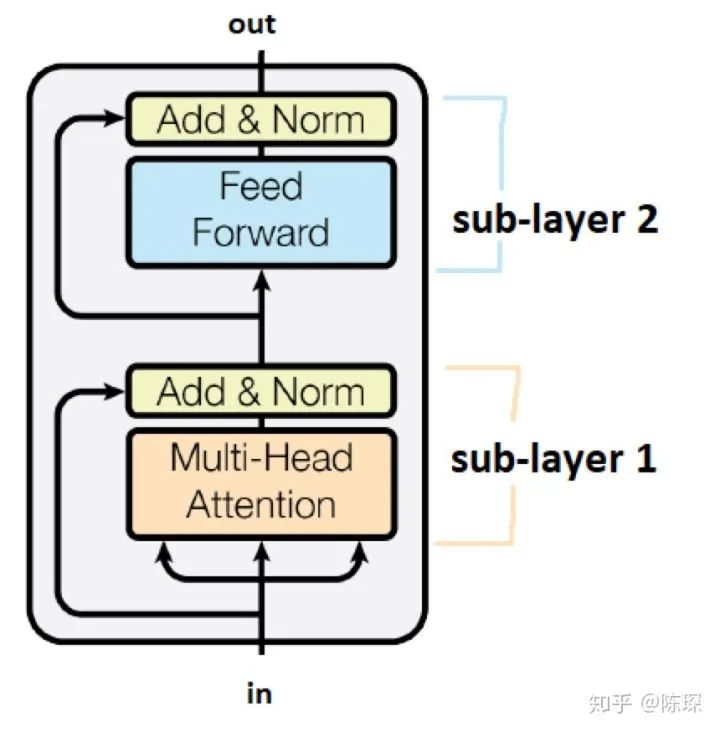
class “Encoder” 将 <layer> 堆叠N次。是 class “EncoderLayer” 的实例。
“EncoderLayer” 初始化需要指定<size>,<self_attn>,<feed_forward>,<dropout>:
<size> 对应 d_model,论文中为512
<self_attn> 是 class MultiHeadedAttention 的实例,对应sub-layer 1
<feed_forward> 是 class PositionwiseFeedForward 的实例,对应sub-layer 2
<dropout> 对应 dropout rate
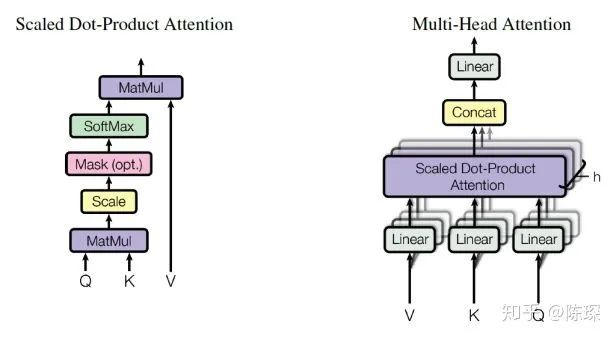
2.1 Encoder Sub-layer 1: Multi-Head Attention Mechanism
我们把 attention 机制的输入定义为 x。x 在 Encoder 的不同位置,含义有所不同。在 Encoder 的开始,x 的含义是句子的 representation。在 EncoderLayer 的各层中间,x 代表前一层 EncoderLayer 的输出。
key = linear_k(x)
query = linear_q(x)
value = linear_v(x)
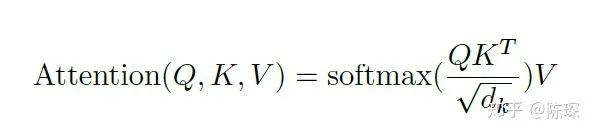
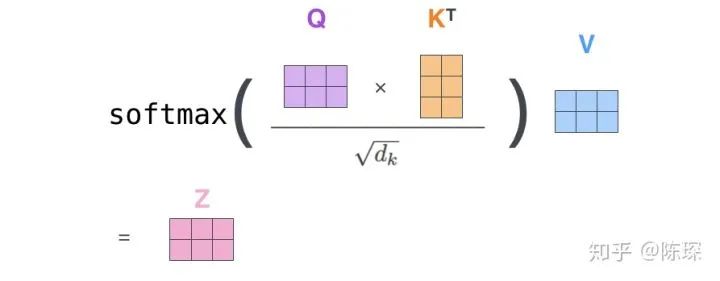
 增大时,
增大时,
 点积值过大,所以用
点积值过大,所以用
 对其进行缩放。引用一下原文”We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients” 对
对其进行缩放。引用一下原文”We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients” 对
 取 softmax 之后值都介于0到1之间,可以理解成得到了 attention weights。然后基于这个 attention weights 对 V 求 weighted sum 值 Attention(Q, K, V)。
取 softmax 之后值都介于0到1之间,可以理解成得到了 attention weights。然后基于这个 attention weights 对 V 求 weighted sum 值 Attention(Q, K, V)。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
<h> = 8,即 “heads” 的数目。在 Transformer 的 base model 中有8 heads
<d_model> = 512
<dropout> = dropout rate = 0.1
 计算来的。在上面的例子中 d_k = 512 / 8 = 64。
计算来的。在上面的例子中 d_k = 512 / 8 = 64。

nbatches 对应 batch size
L 对应 sequence length ,512 对应 d_mode
“key” 和 “value” 的 shape 也为 [nbatches, L, 512]
对 “query”,“key”和“value”进行 linear transform ,他们的 shape 依然是[nbatches, L, 512]。
对其通过 view() 进行 reshape,shape 变成 [nbatches, L, 8, 64]。这里的h=8对应 heads 的数目,d_k=64 是 key 的维度。
transpose 交换 dimension1和2,shape 变成 [nbatches, 8, L 64]。
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
2.2 Encoder Sub-layer 2: Position-Wise fully connected feed-forward network
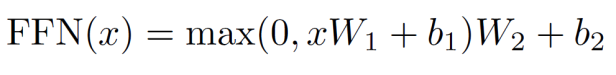
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
2.3 Encoder short summary
SubLayer-1 做 Multi-Headed Attention
SubLayer-2 做 feedforward neural network
3. The Decoder
Diff_1:Decoder SubLayer-1 使用的是 “masked” Multi-Headed Attention 机制,防止为了模型看到要预测的数据,防止泄露。
Diff_2:SubLayer-2 是一个 encoder-decoder multi-head attention。
Diff_3:LinearLayer 和 SoftmaxLayer 作用于 SubLayer-3 的输出后面,来预测对应的 word 的 probabilities 。
3.1 Diff_1 : “masked” Multi-Headed Attention
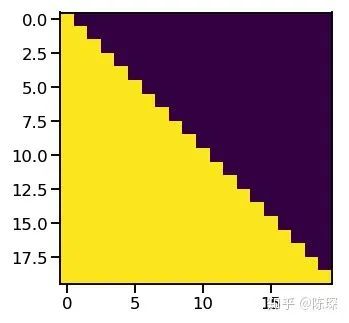
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
3.2 Diff_2 : encoder-decoder multi-head attention
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)

3.3 Diff_3 : Linear and Softmax to Produce Output Probabilities
给 decoder 输入 encoder 对整个句子 embedding 的结果 和一个特殊的开始符号 </s>。decoder 将产生预测,在我们的例子中应该是 ”I”。
给 decoder 输入 encoder 的 embedding 结果和 “</s>I”,在这一步 decoder 应该产生预测 “Love”。
给 decoder 输入 encoder 的 embedding 结果和 “</s>I Love”,在这一步 decoder 应该产生预测 “China”。
给 decoder 输入 encoder 的 embedding 结果和 “</s>I Love China”, decoder应该生成句子结尾的标记,decoder 应该输出 ”</eos>”。
然后 decoder 生成了 </eos>,翻译完成。
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
—完—
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~