
工具介绍:使用 Optuna 进行超参数调优

在机器学习中,除了一般可学习的参数外,还有一些参数需要预先设置,称为超参数。
超参数的值对于模型的性能至关重要,寻找在验证集上性能最佳的超参数称为超参数优化,然而这并不是一项简单的任务。
可以通过搜索方法来选择比较好的超参数。比如,Grid Search 和 Random Search 之类的方法。后者貌似带有一定随机性,但往往表现得比前者好。因为它以不均匀的间隔搜索超参数空间,避免了 Grid Search 的很多冗余操作。
除了这种搜索方式,我们还可以使用像 Optuna 这样的更加灵活强大的工具来应对这项任务。先安装它,
pip install optuna
1流程及简例
一个典型的 Optuna 的优化程序中只有三个最核心的概念,
objective,负责定义待优化的目标函数并指定参数的范围。trial,对应目标函数objective的单次试验。study,负责管理整个优化过程,决定优化的方式、总试验的次数、试验结果的记录等功能。
.简例 .
例如,在定义域
我们就用这个例子来练练手,代码如下。
import optuna
def objective(trial):
x = trial.suggest_uniform('x', 0, 1)
y = trial.suggest_uniform('y', 0, 1)
return (x + y) ** 2
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=100)
print(study.best_params)
print(study.best_value)
{'x': 0.00136012038661543, 'y': 0.0003168904600867363}
2.8123653799567168e-06
首先,定义一个
objective函数,即,其参数 和 采样自两个均匀分布。 然后,
Optuna创建了一个study,指定了优化的方式为最小化并且最大实验次数为100,然后将目标函数传入其中,开始优化过程。最后,输出在
100次试验中找到的最佳参数组合。
注意,上面例子是拿来演示它的使用流程,并不是拿它去解一般的最优化问题。
.可视化 .
等 study 结束,下一步就是查看结果,可以使用 Optuna 的内置可视化函数来查看 study 的各项进度。
下面用 plotly 来作多个方式的可视化。如果没有安装过,则安装它 pip install plotly。
下图显示了模型在多次迭代中的性能演化。预期的行为是模型性能随着搜索次数的增加而提高。
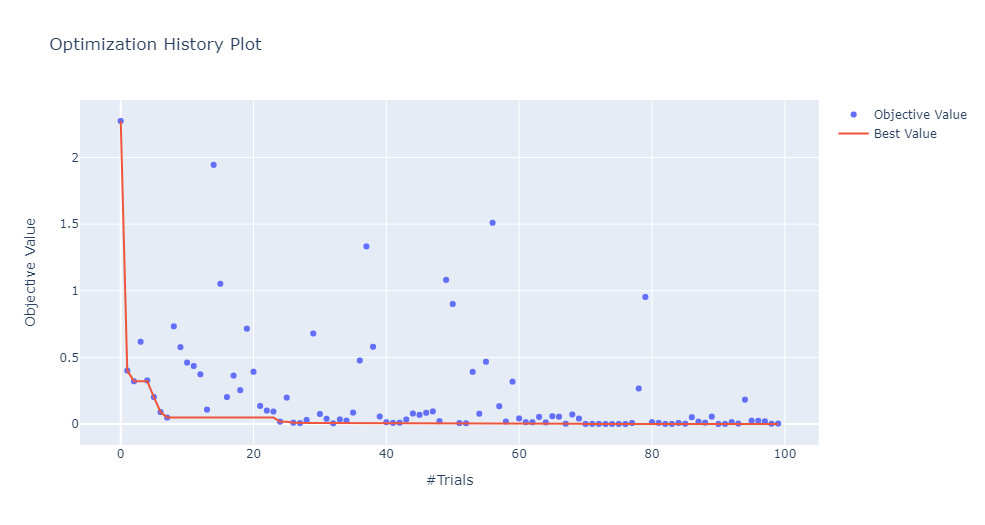
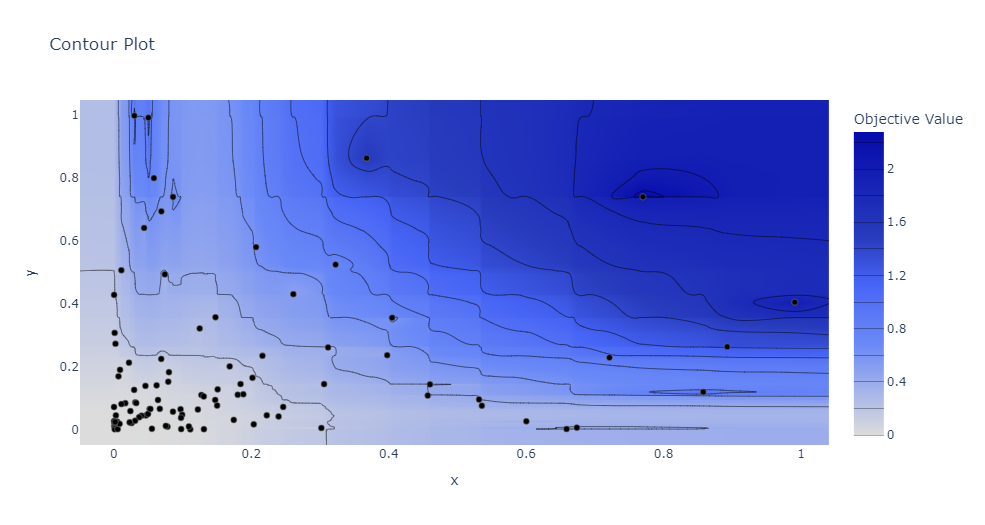
在 study.optimize 执行结束以后,调用 plot_contour,并将 study 和需要可视化的参数传入该方法,Optuna 将返回一张等高线图。
例如,当在上面的例子中,我们想要查看参数
optuna.visualization.plot_contour(study, params=['x', 'y'])
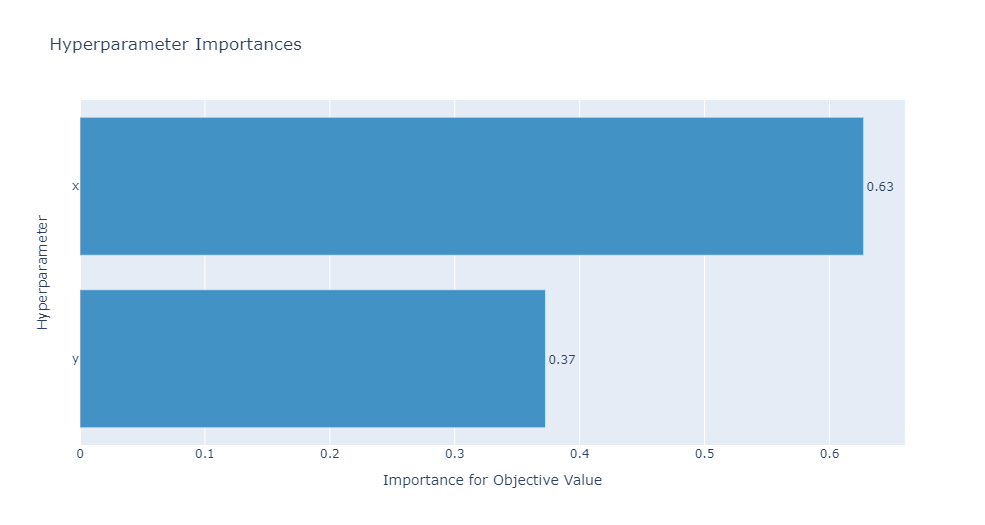
还有其他形式的一些图,如通过展示超参数重要性可以了解到哪些超参数对模型的性能影响较大。
optuna.visualization.plot_param_importances(study)
2CNN 超参数优化例子
本文接下来结合 PyTorch 和 Optuna,来实验 CNN 模型在 MNIST 数据集上的超参数优化。
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader,TensorDataset,random_split,SubsetRandomSampler, ConcatDataset
from torch.nn import functional as F
import torchvision
from torchvision import datasets,transforms
import torchvision.transforms as transforms
import optuna
import os
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
CLASSES = 10
DIR = os.getcwd()
EPOCHS = 10
LOG_INTERVAL = 10
train_dataset = torchvision.datasets.MNIST('classifier_data', train=True, download=True)
m=len(train_dataset)
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_dataset.transform=transform
定义具体的卷积神经网络,并增加参数 trial 来设置要采样的超参数。
class ConvNet(nn.Module):
def __init__(self, trial):
# We optimize dropout rate in a convolutional neural network.
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2)
dropout_rate = trial.suggest_float("dropout_rate", 0, 0.5,step=0.1)
self.drop1=nn.Dropout2d(p=dropout_rate)
fc2_input_dim = trial.suggest_int("fc2_input_dim", 32, 128,32)
self.fc1 = nn.Linear(32 7 7, fc2_input_dim)
dropout_rate2 = trial.suggest_float("dropout_rate2", 0, 0.3,step=0.1)
self.drop2=nn.Dropout2d(p=dropout_rate2)
self.fc2 = nn.Linear(fc2_input_dim, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x),kernel_size = 2))
x = F.relu(F.max_pool2d(self.conv2(x),kernel_size = 2))
x = self.drop1(x)
x = x.view(x.size(0),-1)
x = F.relu(self.fc1(x))
x = self.drop2(x)
x = self.fc2(x)
return x
定义函数来获取训练集中不同 batch_size 大小的批次数据。它将 train_dataset 和 batch_size 作为输入,并返回训练和验证数据加载器对象。
def get_mnist(train_dataset,batch_size):
train_data, val_data = random_split(train_dataset, [int(m-m0.2), int(m0.2)])
# The dataloaders handle shuffling, batching, etc...
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size)
valid_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size)
return train_loader, valid_loader
接下来是定义目标函数,它通过采样程序来选择每次试验的超参数值,并返回在该试验中验证集上的准确度。
def objective(trial):
# Generate the model.
model = ConvNet(trial).to(DEVICE)
# Generate the optimizers.
# try RMSprop and SGD
'''
optimizer_name = trial.suggest_categorical("optimizer", ["RMSprop", "SGD"])
momentum = trial.suggest_float("momentum", 0.0, 1.0)
lr = trial.suggest_float("lr", 1e-5, 1e-1, log=True)
optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr,momentum=momentum)
'''
#try Adam, AdaDelta adn Adagrad
optimizer_name = trial.suggest_categorical("optimizer", ["Adam", "Adadelta","Adagrad"])
lr = trial.suggest_float("lr", 1e-5, 1e-1,log=True)
optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr)
batch_size=trial.suggest_int("batch_size", 64, 256,step=64)
criterion=nn.CrossEntropyLoss()
# Get the MNIST imagesset.
train_loader, valid_loader = get_mnist(train_dataset,batch_size)
# Training of the model.
for epoch in range(EPOCHS):
model.train()
for batch_idx, (images, labels) in enumerate(train_loader):
# Limiting training images for faster epochs.
#if batch_idx * BATCHSIZE >= N_TRAIN_EXAMPLES:
# break
images, labels = images.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
output = model(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
# Validation of the model.
model.eval()
correct = 0
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(valid_loader):
# Limiting validation images.
# if batch_idx * BATCHSIZE >= N_VALID_EXAMPLES:
# break
images, labels = images.to(DEVICE), labels.to(DEVICE)
output = model(images)
# Get the index of the max log-probability.
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(labels.view_as(pred)).sum().item()
accuracy = correct / len(valid_loader.dataset)
trial.report(accuracy, epoch)
# Handle pruning based on the intermediate value.
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return accuracy
接着,创建一个 study 对象来最大化目标函数,然后使用 optimize 来展开试验,实验次数设为 20 次。
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=20)
trial = study.best_trial
print('Accuracy: {}'.format(trial.value))
print("Best hyperparameters: {}".format(trial.params))
Accuracy: 0.98925
Best hyperparameters: {'dropout_rate': 0.0, 'fc2_input_dim': 64, 'dropout_rate2': 0.1, 'optimizer': 'Adam', 'lr': 0.006891576863485639, 'batch_size': 256}
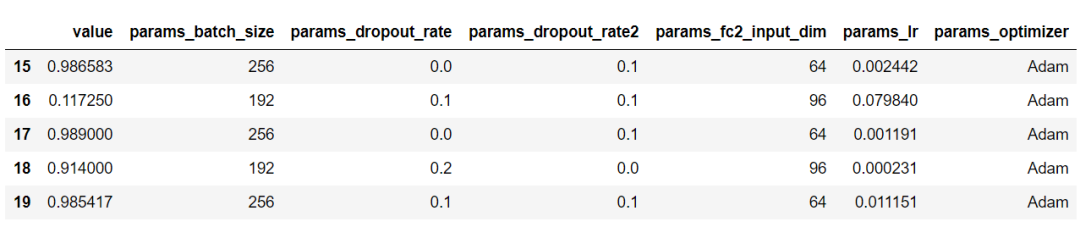
df = study.trials_dataframe().drop(['state','datetime_start','datetime_complete','duration','number'], axis=1)
df.tail(5)
3可视化 study
先通过下面代码看一下各超参数的总体优化进展情况。
optuna.visualization.plot_optimization_history(study)
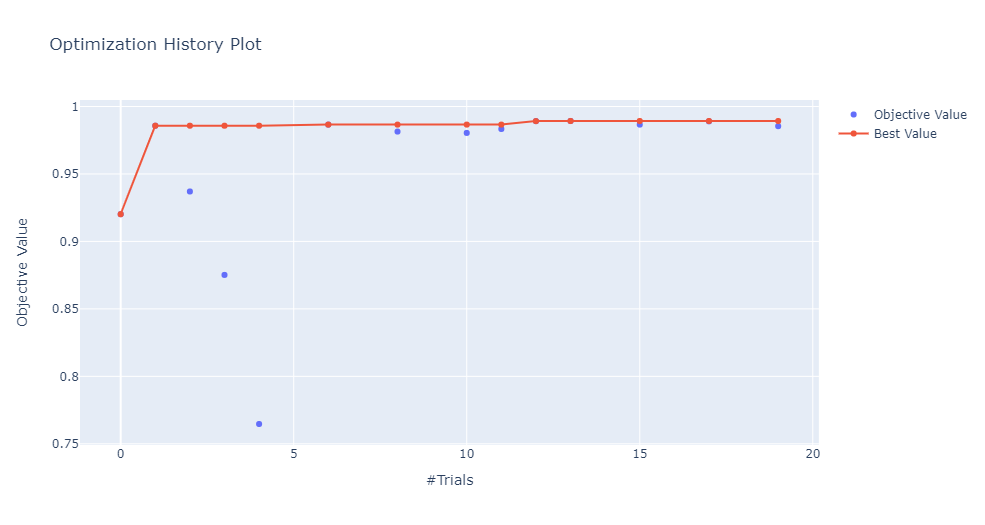
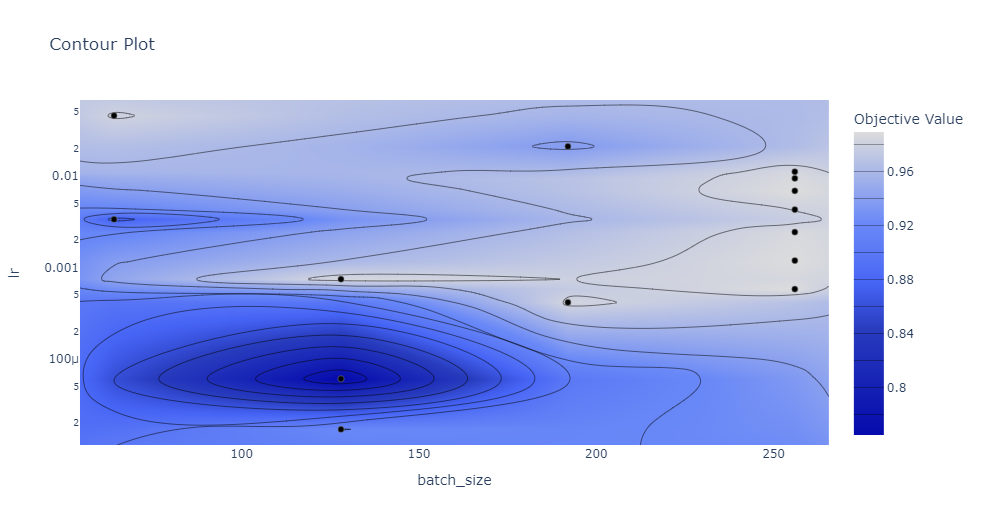
以及还可以查看不同超参数组合的等值线图,下图中只关注批次大小和学习率。
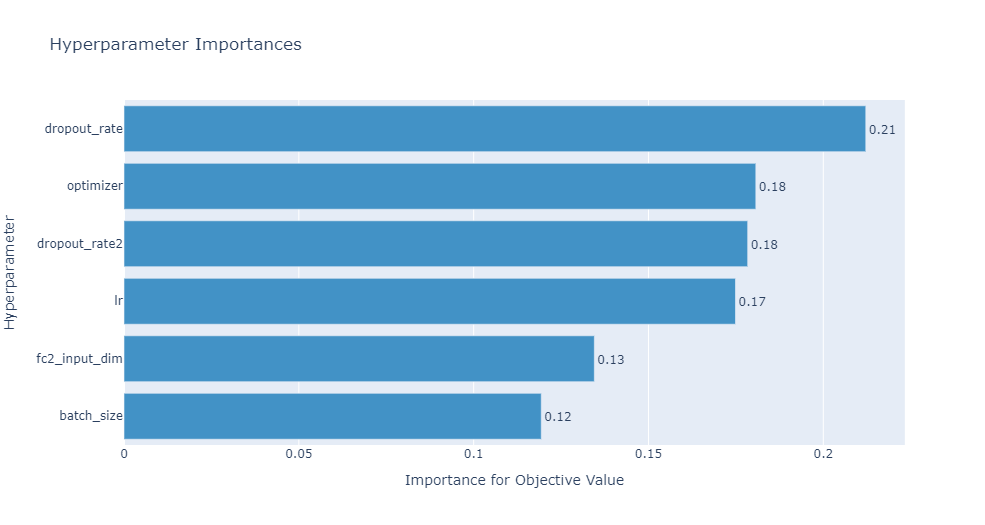
.超参数重要性 .
查看各个超参数对目标值的影响大小。
optuna.visualization.plot_param_importances(study)
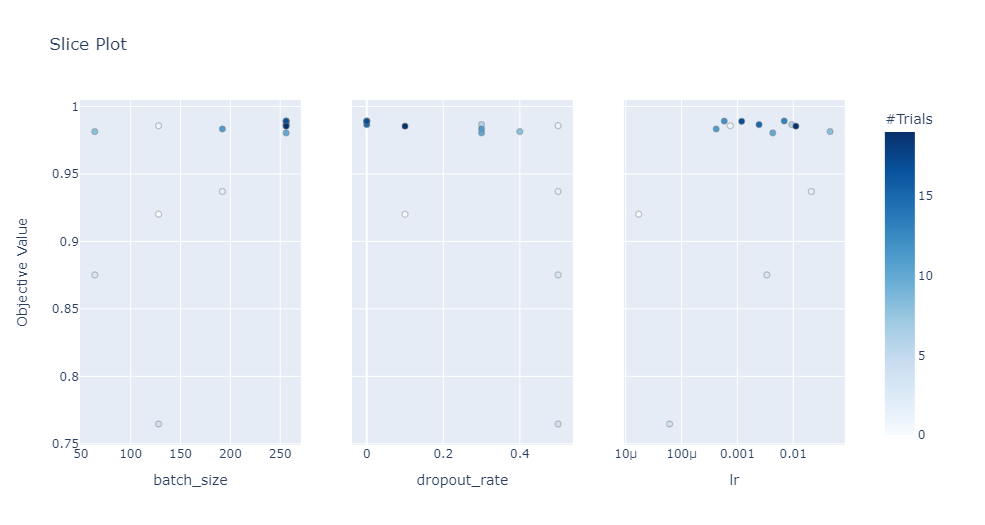
.单个超参数切片 .
查看不同的单个超参数在多次试验中的变化情况,颜色对应试验次数。
optuna.visualization.plot_slice(study, params=['dropout_rate', 'batch_size', 'lr'])
4小结
参考资料
