
技术 | 热数据探测技术及架构设计
共 5652字,需浏览 12分钟
·
2020-12-07 13:54

高并发实现思路
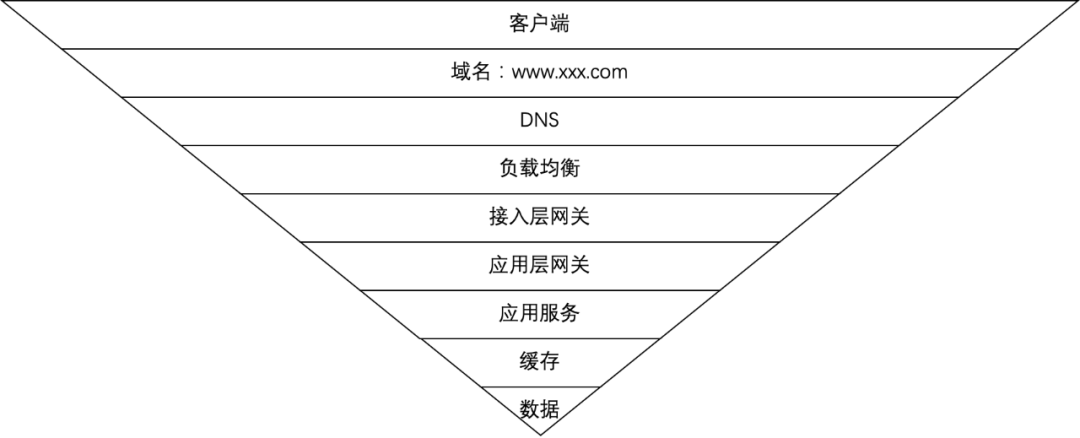 互联网流量漏斗图
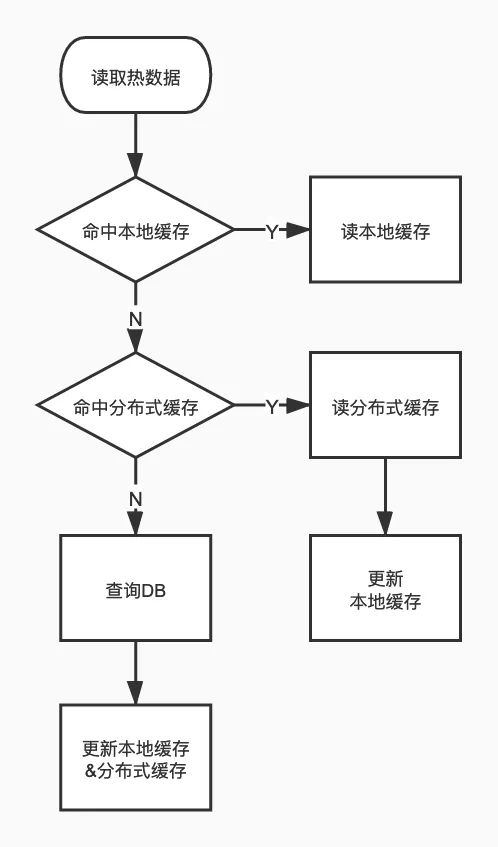
互联网流量漏斗图首先,用户在客户端(前端)发起抢购请求。为防止流量过大,可以使用有损服务随机拒绝部分请求,或者采用业务限流(比如加验证码,随机等待) 请求域名被DNS解析成IP或CNAME(CDN + 静态化) 请求发送至解析到的负载均衡机器(L5、LVS等) 请求被负载均衡器转发至接入层网关(Nginx、HAProxy等) 请求被转发至应用服务器实例(如果底层是微服务,可能还有一层应用层网关,比如Zuul),应用服务负责读取数据、执行业务逻辑。在服务中耗时的操作可以采用消息队列进行异步化。qps过高时,可采用服务熔断和降级。 服务先从缓存层(如redis集群)中读取数据,如果命中缓存,直接读取缓存 没命中缓存,则查询数据库

热数据探测技术
什么是热数据??
有预期:比如大促活动中某些网红代言的爆款商品 无预期:比如恶意攻击、爬虫、突然火爆的商品
MySQL等数据库中被频繁访问的数据,如爆款商品的skuId KV缓存系统中经常被访问的key 机器人、爬虫、刷子用户,如用户的userId、uuid、ip等 某接口地址,如商品查询/sku/query 统计用户访问某个接口的频率,如userId + /sku/query 统计某台服务器某个接口被访问的频率,如ip + /sku/query 统计某用户访问某个商品的频率,如userId + /sku/query + skuId
为什么要检测热数据?
我们检测热数据的原因很简单:
1. 提升性能
缓存级数越多,意味着更新操作越复杂,数据不一致的风险越大。
2. 规避风险
对数据层的风险 正常情况下,Redis缓存单机可支持十万左右qps,并可通过集群增大并发度。并发量一般的系统,用Redis做缓存就足够了。但是如果有一个商品突然爆火,或者收到恶意请求,对该数据key的访问qps可能飙升到百万、千万量级,在redis单线程的工作方式下,会导致正常的请求排队,无法及时响应,严重时会导致整个分片集群瘫痪。 还有一种情况,某热点key突然过期,直接导致大量请求砸向DB,直接导致DB挂掉! 对应用服务的风险 我们的应用单位时间所能接受和处理的请求量是有限的,如果受到恶意请求(爬虫等),某个恶意用户独自占用大量请求处理资源,会导致其他正常用户的请求无法及时响应。 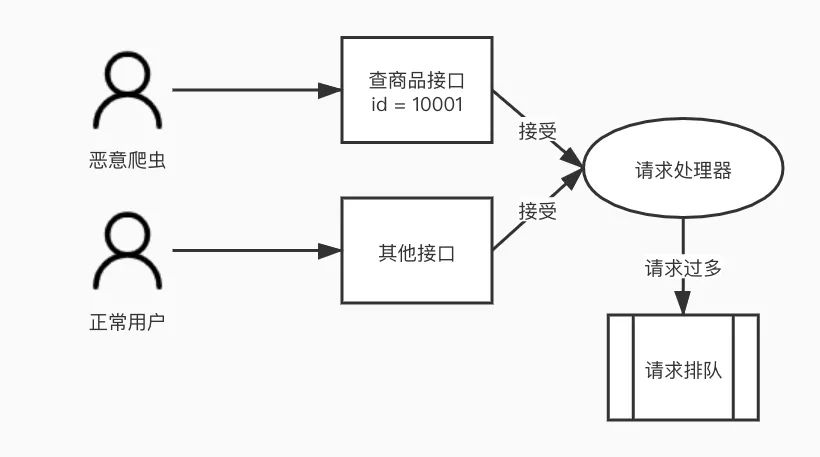
恶意请求导致的请求排队
如何检测热数据?
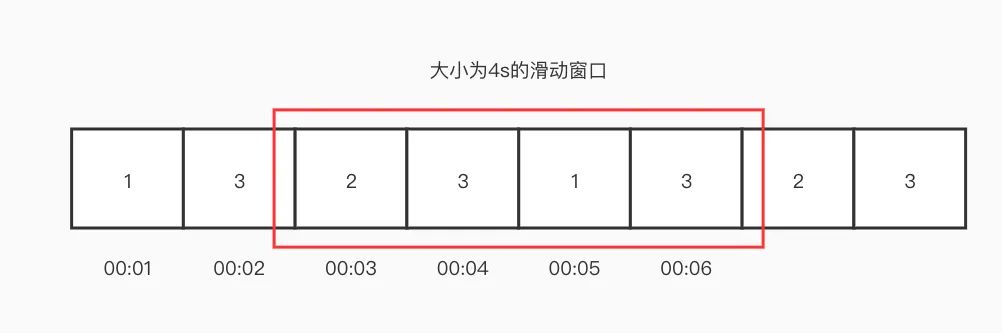 滑动窗口
滑动窗口配置规则:指定热key的上报条件 热key上报:各应用实例上报访问到的key至集中计算单元 热key统计:收集各应用实例上报的信息,使用滑动窗口算法计算key的热度 热key推送:当key的热度达到设定值时,推送热key信息至所有应用实例,各应用实例将key值进行本地缓存
实时性:考虑到热key的突发性,必须能够实时发现热key并推送 高性能:框架应保持轻量且高性能,能够有效降低成本 准确性:精准探测符合规则的热key,不漏报,不误报 一致性:保证应用实例本地缓存的热key一致,否则可能出现数据错误 可扩展:要计算的key数量级很大时,集中计算集群应便于扩展
其实通过Redis本身也可以实现热key探测功能,比如用monitor命令监控key的访问并进行统计,或者利用v4.0.3后redis-cli自带的-hotkeys选项查看热key。但是这两个命令在key较多时,执行缓慢,且会降低redis的性能。因此,自实现热key探测框架是必要的。
京东毫秒级热key探测框架分析
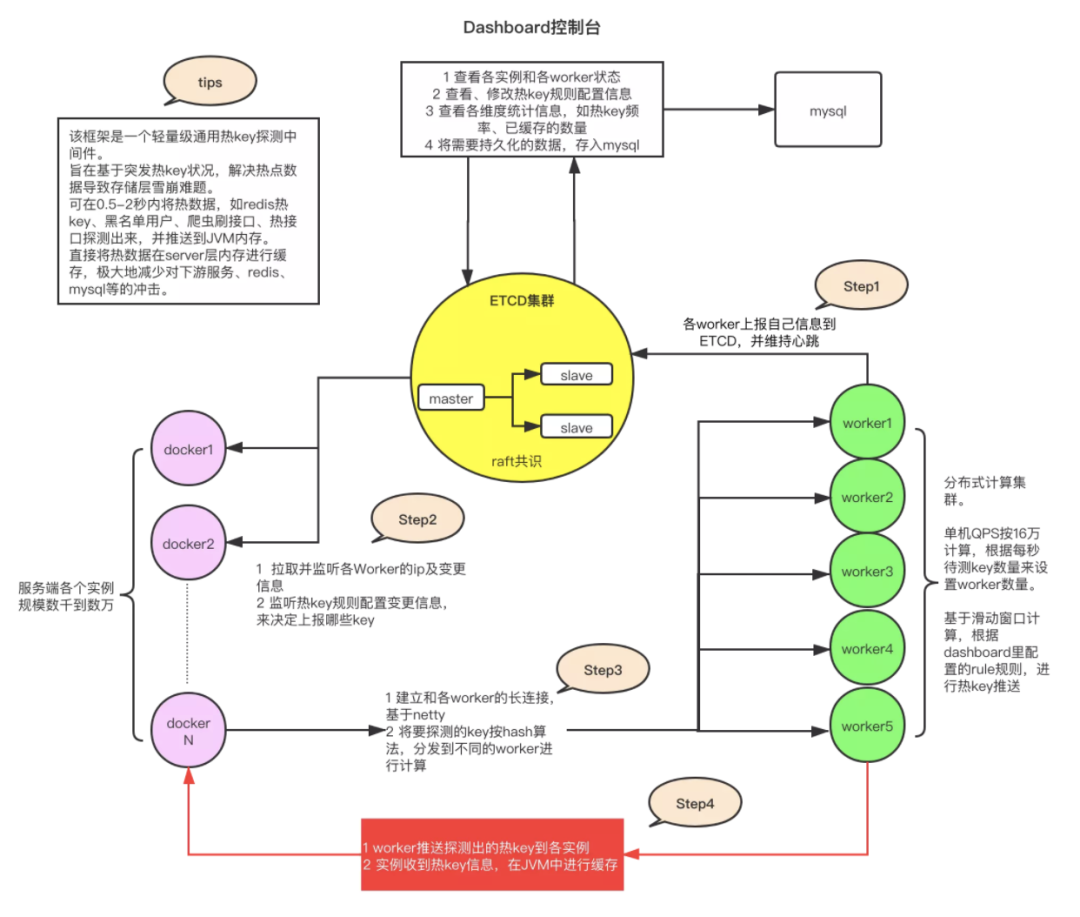 JdHotkey架构图
JdHotkey架构图Etcd集群:高可用强一致的 Key/Value 存储系统,主要用于共享配置和服务发现。此处存放计算集群(worker)的地址、热key规则、已检测出的热key等。 Worker计算集群:用java实现的计算程序,通过Etcd供客户端发现并建立连接,主要负责收集和计算热key的访问频率,并且将符合规则的热key推送至客户端。 客户端:引入jar包,负责与Worker建立链接并上报key(先在本地累加,周期性批量上报)、监听key上报规则、缓存热key。 Dashboard控制台:通过读写Etcd集群完成对Worker、Client、配置规则、热Key的监控,并支持持久化数据至MySQL。
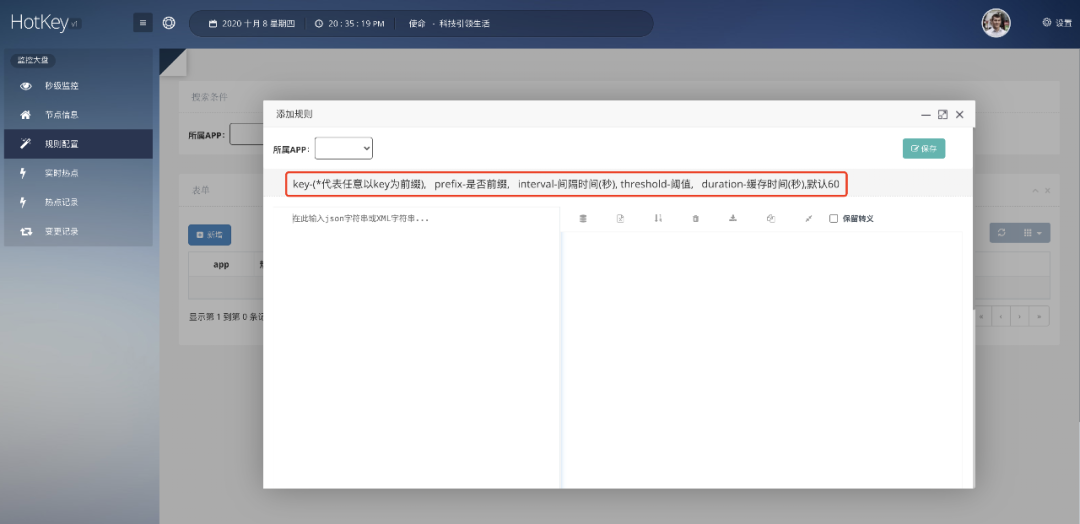 通过Dashboard配置规则
通过Dashboard配置规则Dashboard体验地址:http://hotkey.tianyalei.com:9001/
2. 启动Worker集群,与Etcd建立连接,Worker将自身信息上报至Etcd并拉取热key规则,维持心跳
3. 客户端与Etcd建立连接,发现Worker并拉取Key上报规则
4. 客户端与Worker建立长连接并上报符合规则的key,通过hash算法决定上报至哪台Worker
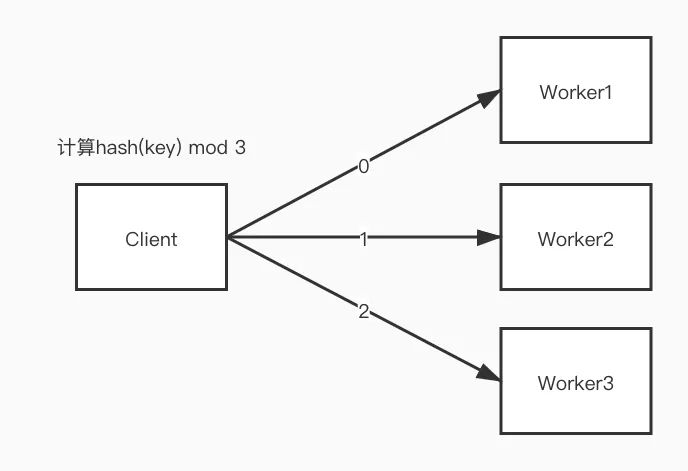 通过hash将key上报至不同Worker
通过hash将key上报至不同Worker滑动窗口源码 使用 AtomicInteger[] 循环队列实现,感兴趣的同学可以看下。
7. 可以通过Dashboard更改Etcd中存储的key规则,Worker和Client通过Etcd提供的watch api监听到规则的改变。
有赞TMC
 TMC本地缓存架构
TMC本地缓存架构
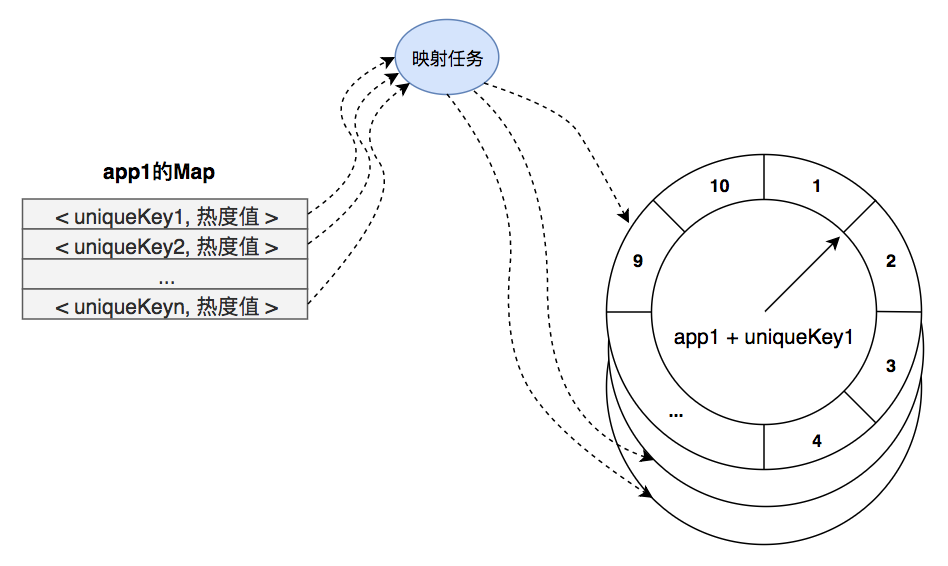
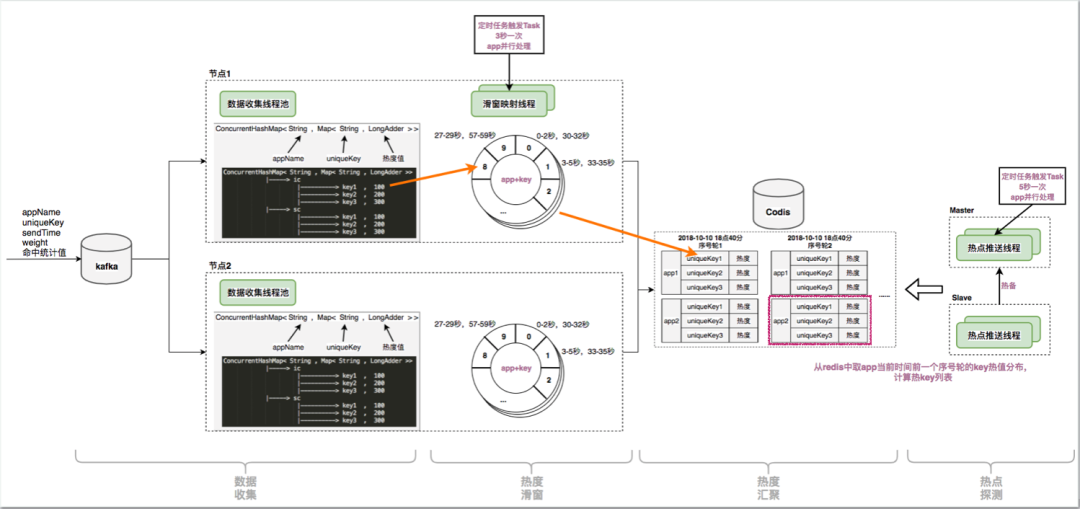
热度统计过程中的时间轮
3. Etcd集群负责存储热key,客户端通过监听Etcd集群实现热key的发现和失效。
热key发现完整步骤
JdHotkey设计思考
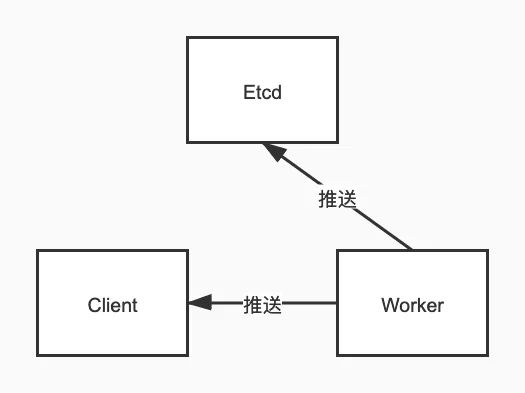
Worker推送热key至Client和Etcd
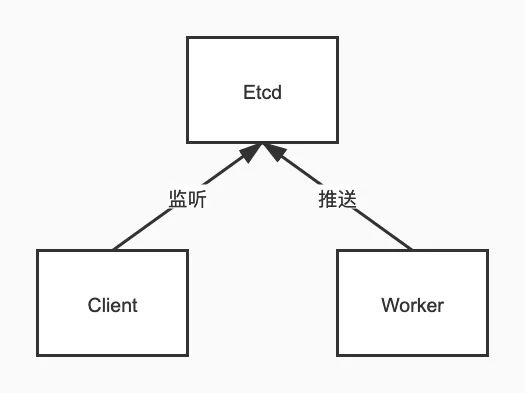
Worker推送热key,Client监听Etcd获取热key
worker和client是长连接,产生热key后,直接推送过去,链路短,耗时少。如果是发到etcd,客户端再通过etcd获取,多了一层中转,耗时明显增加。 etcd性能不够,存在单点风险。譬如我有5000台client,每秒产生100个热key,那么每秒就对应50万次推送。我用2台worker即可轻松完成,随着worker的横向扩展,每秒的推送上限线性增加。但无论是etcd、redis等等任何组件,都不可能做到1秒50万次拉取或推送,会瞬间cpu爆满卡死。因为worker是各自隔离的,而etcd是单点的。实际情况下,也不止5000台client,每秒也不止100个热key,只有当前的架构能支撑。虽然可以扩容Etcd集群,但同样会增加成本。对于watch Api,还要考虑对内存的占用。
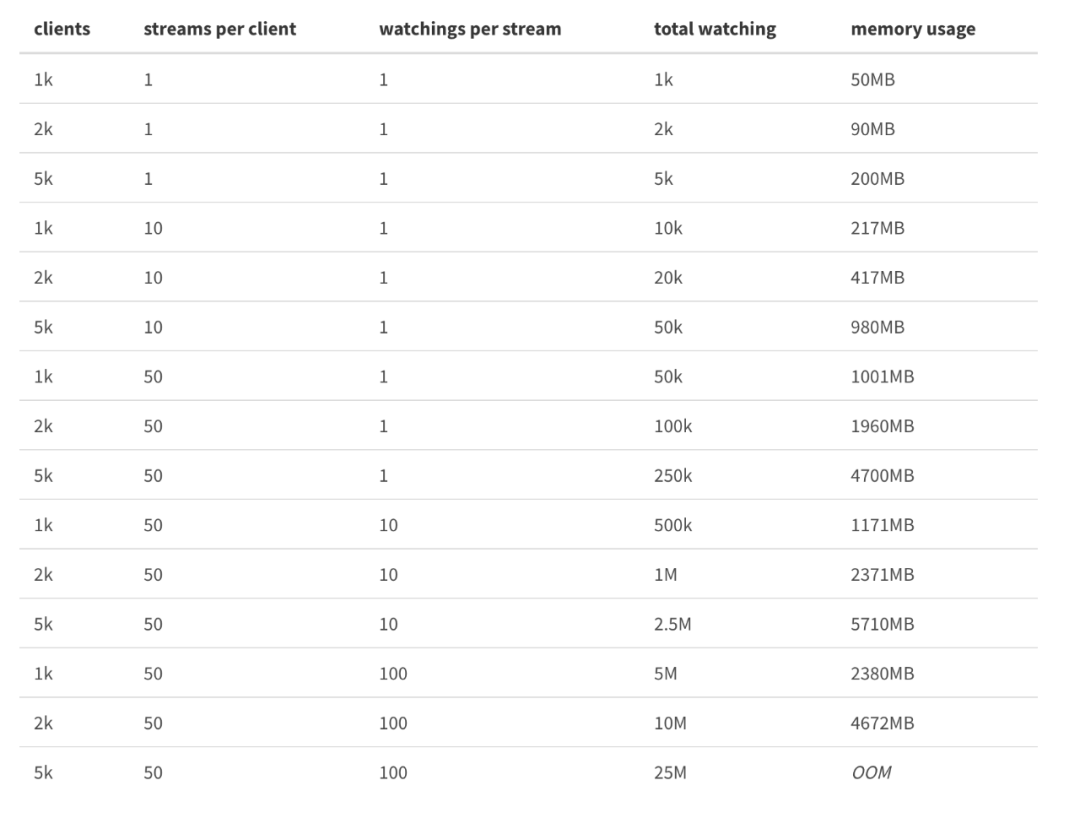 Etcdv3 watch 内存占用官方压测
Etcdv3 watch 内存占用官方压测
但多学习一些思路总是好的~
参考资源
1. 京东毫秒级热key探测框架设计与实践
2. 有赞透明多级缓存解决方案(TMC)
3. 京东 hotkey 源码
4. redis4.0之基于LFU的热点key发现机制
—————END—————
喜欢本文的朋友,欢迎关注公众号 程序员哆啦A梦,收看更多精彩内容
点个[在看],是对小达最大的支持!
