
如何在12个小时,搞定日志监控?
共 4493字,需浏览 9分钟
·
2020-12-01 14:16
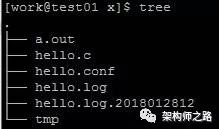
fatal.log
error.log
info.log
debug.log
…
daojia.log.2018012800
daojia.log.2018012801
…
daojia.log.2018012823
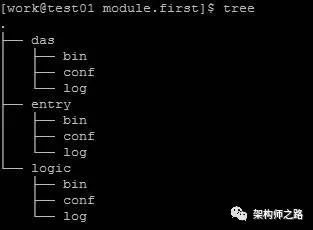
[daojia_main]
ip.list : ip1, ip2, ip3
log.path : /home/work/log/daojia_main/
owner.list : shenjian, zhangsan
[daojia_user]
ip.list : ip4, ip5, ip6
log.path : /home/work/log/daojia_user/
owner.list : shenjian
[shenjian]
email : XX@XX.com
phone :15912345678
[zhangsan]
email : YY@YY.com
phone :18611220099
[log.monitor.item]
cluster.name : daojia_main
# error日志监控,每分钟超过此阈值就告警
error.log. threshold : 10
# 异常关键字监控,日志出现这些关键字就告警
bad.key : exeption | timeout | coredump
# 正常关键字监控,日志每分钟不出现这些关键字就告警
good.key : login | user | click
[log.monitor.item]
cluster.name : daojia_user
error.log.threshold : 10
Array[log-monitor] A1= Parse(log.monitor.config);
Array[cluster-info] A2= Parse(cluster.info.config);
Array[owner-info] A3= Parse(owner.info.config);
// 遍历所有监控项
for(each item in A1){
//取出监控项的集群名,阈值,异常/正常关键词
clusterName= item.clusterName;
threshold= item.threshold;
badKey= item.badkey;
goodKey= item.goodkey;
//由集群名,获取集群信息
clusterInfo= A2[clusterName];
//获取日志目录,集群ip列表,集群负责人列表
logPath= clusterInfo.path;
List
List
//集群内的每一个ip实例,都需要日志监控
for(each ip in ips){
//登录到这一台机器
ssh $ip
//跳到相关的目录下
cd $logPath
//查看近一分钟error日志数量
$count= `grep $time error.log | wc -l`
//查看badkey与goodkey
$boolBad= `grep $badkey *`
$boolGood= `grep $goodkey *`
if($count< threshold &&
$boolBad==NO &&
$boolGood==YES){
//正常,继续监控
continue;
}
// 否则,对所有集群负责人发送告警
for(each owner in owners){
// 略…
}
}
}
架构师之路-分享技术思路
思路比结论更重要,希望大家有收获。