
Flink 维表 Join 实践|附四种方式的源码
常见的维表Join方式有四种:
预加载维表 热存储维表 广播维表 Temporal table function join
下面分别使用这四种方式来实现一个join的需求,这个需求是:一个主流中数据是用户信息,字段包括用户姓名、城市id;维表是城市数据,字段包括城市ID、城市名称。要求用户表与城市表关联,输出为:用户名称、城市ID、城市名称。
用户表表结构如下:

城市维表表结构如下:

1、 预加载维表
通过定义一个类实现RichMapFunction,在open()中读取维表数据加载到内存中,在probe流map()方法中与维表数据进行关联。
RichMapFunction中open方法里加载维表数据到内存的方式特点如下:
优点:实现简单 缺点:因为数据存于内存,所以只适合小数据量并且维表数据更新频率不高的情况下。虽然可以在open中定义一个定时器定时更新维表,但是还是存在维表更新不及时的情况。
下面是一个例子:
package join;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.HashMap;
import java.util.Map;
/**
* Create By 鸣宇淳 on 2020/6/1
* 这个例子是从socket中读取的流,数据为用户名称和城市id,维表是城市id、城市名称,
* 主流和维表关联,得到用户名称、城市id、城市名称
* 这个例子采用在RichMapfunction类的open方法中将维表数据加载到内存
**/
public class JoinDemo1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> textStream = env.socketTextStream("localhost", 9000, "\n")
.map(p -> {
//输入格式为:user,1000,分别是用户名称和城市编号
String[] list = p.split(",");
return new Tuple2<String, Integer>(list[0], Integer.valueOf(list[1]));
})
.returns(new TypeHint<Tuple2<String, Integer>>() {
});
DataStream<Tuple3<String, Integer, String>> result = textStream.map(new MapJoinDemo1());
result.print();
env.execute("joinDemo1");
}
static class MapJoinDemo1 extends RichMapFunction<Tuple2<String, Integer>, Tuple3<String, Integer, String>> {
//定义一个变量,用于保存维表数据在内存
Map<Integer, String> dim;
@Override
public void open(Configuration parameters) throws Exception {
//在open方法中读取维表数据,可以从数据中读取、文件中读取、接口中读取等等。
dim = new HashMap<>();
dim.put(1001, "beijing");
dim.put(1002, "shanghai");
dim.put(1003, "wuhan");
dim.put(1004, "changsha");
}
@Override
public Tuple3<String, Integer, String> map(Tuple2<String, Integer> value) throws Exception {
//在map方法中进行主流和维表的关联
String cityName = "";
if (dim.containsKey(value.f1)) {
cityName = dim.get(value.f1);
}
return new Tuple3<>(value.f0, value.f1, cityName);
}
}
}
2、 热存储维表
这种方式是将维表数据存储在Redis、HBase、MySQL等外部存储中,实时流在关联维表数据的时候实时去外部存储中查询,这种方式特点如下:
优点:维度数据量不受内存限制,可以存储很大的数据量。 缺点:因为维表数据在外部存储中,读取速度受制于外部存储的读取速度;另外维表的同步也有延迟。
(1) 使用cache来减轻访问压力
可以使用缓存来存储一部分常访问的维表数据,以减少访问外部系统的次数,比如使用guava Cache。
下面是一个例子:
package join;
import com.google.common.cache.*;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* Create By 鸣宇淳 on 2020/6/1
**/
public class JoinDemo2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> textStream = env.socketTextStream("localhost", 9000, "\n")
.map(p -> {
//输入格式为:user,1000,分别是用户名称和城市编号
String[] list = p.split(",");
return new Tuple2<String, Integer>(list[0], Integer.valueOf(list[1]));
})
.returns(new TypeHint<Tuple2<String, Integer>>() {
});
DataStream<Tuple3<String, Integer, String>> result = textStream.map(new MapJoinDemo1());
result.print();
env.execute("joinDemo1");
}
static class MapJoinDemo1 extends RichMapFunction<Tuple2<String, Integer>, Tuple3<String, Integer, String>> {
LoadingCache<Integer, String> dim;
@Override
public void open(Configuration parameters) throws Exception {
//使用google LoadingCache来进行缓存
dim = CacheBuilder.newBuilder()
//最多缓存个数,超过了就根据最近最少使用算法来移除缓存
.maximumSize(1000)
//在更新后的指定时间后就回收
.expireAfterWrite(10, TimeUnit.MINUTES)
//指定移除通知
.removalListener(new RemovalListener<Integer, String>() {
@Override
public void onRemoval(RemovalNotification<Integer, String> removalNotification) {
System.out.println(removalNotification.getKey() + "被移除了,值为:" + removalNotification.getValue());
}
})
.build(
//指定加载缓存的逻辑
new CacheLoader<Integer, String>() {
@Override
public String load(Integer cityId) throws Exception {
String cityName = readFromHbase(cityId);
return cityName;
}
}
);
}
private String readFromHbase(Integer cityId) {
//读取hbase
//这里写死,模拟从hbase读取数据
Map<Integer, String> temp = new HashMap<>();
temp.put(1001, "beijing");
temp.put(1002, "shanghai");
temp.put(1003, "wuhan");
temp.put(1004, "changsha");
String cityName = "";
if (temp.containsKey(cityId)) {
cityName = temp.get(cityId);
}
return cityName;
}
@Override
public Tuple3<String, Integer, String> map(Tuple2<String, Integer> value) throws Exception {
//在map方法中进行主流和维表的关联
String cityName = "";
if (dim.get(value.f1) != null) {
cityName = dim.get(value.f1);
}
return new Tuple3<>(value.f0, value.f1, cityName);
}
}
}
(2) 使用异步IO来提高访问吞吐量
Flink与外部存储系统进行读写操作的时候可以使用同步方式,也就是发送一个请求后等待外部系统响应,然后再发送第二个读写请求,这样的方式吞吐量比较低,可以用提高并行度的方式来提高吞吐量,但是并行度多了也就导致了进程数量多了,占用了大量的资源。
Flink中可以使用异步IO来读写外部系统,这要求外部系统客户端支持异步IO,不过目前很多系统都支持异步IO客户端。但是如果使用异步就要涉及到三个问题:
超时:如果查询超时那么就认为是读写失败,需要按失败处理; 并发数量:如果并发数量太多,就要触发Flink的反压机制来抑制上游的写入。 返回顺序错乱:顺序错乱了要根据实际情况来处理,Flink支持两种方式:允许乱序、保证顺序。
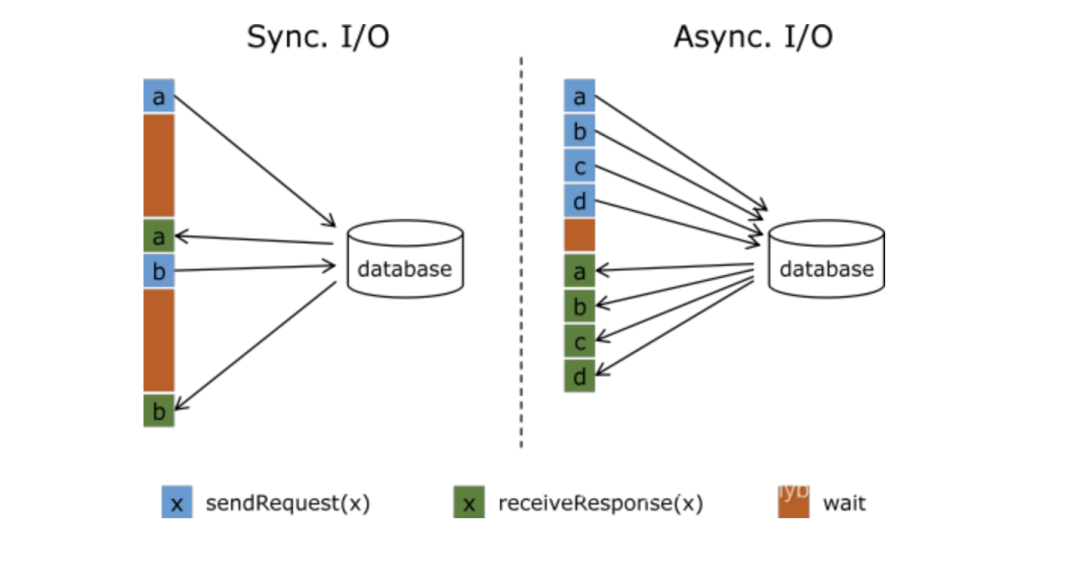
下面是一个实例,演示了试用异步IO来访问维表:
package join;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* Create By 鸣宇淳 on 2020/6/1
**/
public class JoinDemo3 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> textStream = env.socketTextStream("localhost", 9000, "\n")
.map(p -> {
//输入格式为:user,1000,分别是用户名称和城市编号
String[] list = p.split(",");
return new Tuple2<String, Integer>(list[0], Integer.valueOf(list[1]));
})
.returns(new TypeHint<Tuple2<String, Integer>>() {
});
DataStream<Tuple3<String,Integer, String>> orderedResult = AsyncDataStream
//保证顺序:异步返回的结果保证顺序,超时时间1秒,最大容量2,超出容量触发反压
.orderedWait(textStream, new JoinDemo3AyncFunction(), 1000L, TimeUnit.MILLISECONDS, 2)
.setParallelism(1);
DataStream<Tuple3<String,Integer, String>> unorderedResult = AsyncDataStream
//允许乱序:异步返回的结果允许乱序,超时时间1秒,最大容量2,超出容量触发反压
.unorderedWait(textStream, new JoinDemo3AyncFunction(), 1000L, TimeUnit.MILLISECONDS, 2)
.setParallelism(1);
orderedResult.print();
unorderedResult.print();
env.execute("joinDemo");
}
//定义个类,继承RichAsyncFunction,实现异步查询存储在mysql里的维表
//输入用户名、城市ID,返回 Tuple3<用户名、城市ID,城市名称>
static class JoinDemo3AyncFunction extends RichAsyncFunction<Tuple2<String, Integer>, Tuple3<String, Integer, String>> {
// 链接
private static String jdbcUrl = "jdbc:mysql://192.168.145.1:3306?useSSL=false";
private static String username = "root";
private static String password = "123";
private static String driverName = "com.mysql.jdbc.Driver";
java.sql.Connection conn;
PreparedStatement ps;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
Class.forName(driverName);
conn = DriverManager.getConnection(jdbcUrl, username, password);
ps = conn.prepareStatement("select city_name from tmp.city_info where id = ?");
}
@Override
public void close() throws Exception {
super.close();
conn.close();
}
//异步查询方法
@Override
public void asyncInvoke(Tuple2<String, Integer> input, ResultFuture<Tuple3<String,Integer, String>> resultFuture) throws Exception {
// 使用 city id 查询
ps.setInt(1, input.f1);
ResultSet rs = ps.executeQuery();
String cityName = null;
if (rs.next()) {
cityName = rs.getString(1);
}
List list = new ArrayList<Tuple2<Integer, String>>();
list.add(new Tuple3<>(input.f0,input.f1, cityName));
resultFuture.complete(list);
}
//超时处理
@Override
public void timeout(Tuple2<String, Integer> input, ResultFuture<Tuple3<String,Integer, String>> resultFuture) throws Exception {
List list = new ArrayList<Tuple2<Integer, String>>();
list.add(new Tuple3<>(input.f0,input.f1, ""));
resultFuture.complete(list);
}
}
}
3、 广播维表
利用Flink的Broadcast State将维度数据流广播到下游做join操作。特点如下:
优点:维度数据变更后可以即时更新到结果中。 缺点:数据保存在内存中,支持的维度数据量比较小。
下面是一个实例:
package join;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Create By 鸣宇淳 on 2020/6/1
* 这个例子是从socket中读取的流,数据为用户名称和城市id,维表是城市id、城市名称,
* 主流和维表关联,得到用户名称、城市id、城市名称
* 这个例子采用 Flink 广播流的方式来做为维度
**/
public class JoinDemo4 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//定义主流
DataStream<Tuple2<String, Integer>> textStream = env.socketTextStream("localhost", 9000, "\n")
.map(p -> {
//输入格式为:user,1000,分别是用户名称和城市编号
String[] list = p.split(",");
return new Tuple2<String, Integer>(list[0], Integer.valueOf(list[1]));
})
.returns(new TypeHint<Tuple2<String, Integer>>() {
});
//定义城市流
DataStream<Tuple2<Integer, String>> cityStream = env.socketTextStream("localhost", 9001, "\n")
.map(p -> {
//输入格式为:城市ID,城市名称
String[] list = p.split(",");
return new Tuple2<Integer, String>(Integer.valueOf(list[0]), list[1]);
})
.returns(new TypeHint<Tuple2<Integer, String>>() {
});
//将城市流定义为广播流
final MapStateDescriptor<Integer, String> broadcastDesc = new MapStateDescriptor("broad1", Integer.class, String.class);
BroadcastStream<Tuple2<Integer, String>> broadcastStream = cityStream.broadcast(broadcastDesc);
DataStream result = textStream.connect(broadcastStream)
.process(new BroadcastProcessFunction<Tuple2<String, Integer>, Tuple2<Integer, String>, Tuple3<String, Integer, String>>() {
//处理非广播流,关联维度
@Override
public void processElement(Tuple2<String, Integer> value, ReadOnlyContext ctx, Collector<Tuple3<String, Integer, String>> out) throws Exception {
ReadOnlyBroadcastState<Integer, String> state = ctx.getBroadcastState(broadcastDesc);
String cityName = "";
if (state.contains(value.f1)) {
cityName = state.get(value.f1);
}
out.collect(new Tuple3<>(value.f0, value.f1, cityName));
}
@Override
public void processBroadcastElement(Tuple2<Integer, String> value, Context ctx, Collector<Tuple3<String, Integer, String>> out) throws Exception {
System.out.println("收到广播数据:" + value);
ctx.getBroadcastState(broadcastDesc).put(value.f0, value.f1);
}
});
result.print();
env.execute("joinDemo");
}
}
4、 Temporal table function join
Temporal table是持续变化表上某一时刻的视图,Temporal table function是一个表函数,传递一个时间参数,返回Temporal table这一指定时刻的视图。
可以将维度数据流映射为Temporal table,主流与这个Temporal table进行关联,可以关联到某一个版本(历史上某一个时刻)的维度数据。
Temporal table function join的特点如下:
优点:维度数据量可以很大,维度数据更新及时,不依赖外部存储,可以关联不同版本的维度数据。 缺点:只支持在Flink SQL API中使用。
(1) ProcessingTime的一个实例
package join;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;
/**
* Create By 鸣宇淳 on 2020/6/1
**/
public class JoinDemo5 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, bsSettings);
//定义主流
DataStream<Tuple2<String, Integer>> textStream = env.socketTextStream("localhost", 9000, "\n")
.map(p -> {
//输入格式为:user,1000,分别是用户名称和城市编号
String[] list = p.split(",");
return new Tuple2<String, Integer>(list[0], Integer.valueOf(list[1]));
})
.returns(new TypeHint<Tuple2<String, Integer>>() {
});
//定义城市流
DataStream<Tuple2<Integer, String>> cityStream = env.socketTextStream("localhost", 9001, "\n")
.map(p -> {
//输入格式为:城市ID,城市名称
String[] list = p.split(",");
return new Tuple2<Integer, String>(Integer.valueOf(list[0]), list[1]);
})
.returns(new TypeHint<Tuple2<Integer, String>>() {
});
//转变为Table
Table userTable = tableEnv.fromDataStream(textStream, "user_name,city_id,ps.proctime");
Table cityTable = tableEnv.fromDataStream(cityStream, "city_id,city_name,ps.proctime");
//定义一个TemporalTableFunction
TemporalTableFunction dimCity = cityTable.createTemporalTableFunction("ps", "city_id");
//注册表函数
tableEnv.registerFunction("dimCity", dimCity);
//关联查询
Table result = tableEnv
.sqlQuery("select u.user_name,u.city_id,d.city_name from " + userTable + " as u " +
", Lateral table (dimCity(u.ps)) d " +
"where u.city_id=d.city_id");
//打印输出
DataStream resultDs = tableEnv.toAppendStream(result, Row.class);
resultDs.print();
env.execute("joinDemo");
}
}
(2) EventTime的一个实例
package join;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;
import java.sql.Timestamp;
import java.util.ArrayList;
import java.util.List;
/**
* Create By 鸣宇淳 on 2020/6/1
**/
public class JoinDemo9 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//指定是EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, bsSettings);
env.setParallelism(1);
//主流,用户流, 格式为:user_name、city_id、ts
List<Tuple3<String, Integer, Long>> list1 = new ArrayList<>();
list1.add(new Tuple3<>("user1", 1001, 1L));
list1.add(new Tuple3<>("user1", 1001, 10L));
list1.add(new Tuple3<>("user2", 1002, 2L));
list1.add(new Tuple3<>("user2", 1002, 15L));
DataStream<Tuple3<String, Integer, Long>> textStream = env.fromCollection(list1)
.assignTimestampsAndWatermarks(
//指定水位线、时间戳
new BoundedOutOfOrdernessTimestampExtractor<Tuple3<String, Integer, Long>>(Time.seconds(10)) {
@Override
public long extractTimestamp(Tuple3<String, Integer, Long> element) {
return element.f2;
}
}
);
//定义城市流,格式为:city_id、city_name、ts
List<Tuple3<Integer, String, Long>> list2 = new ArrayList<>();
list2.add(new Tuple3<>(1001, "beijing", 1L));
list2.add(new Tuple3<>(1001, "beijing2", 10L));
list2.add(new Tuple3<>(1002, "shanghai", 1L));
list2.add(new Tuple3<>(1002, "shanghai2", 5L));
DataStream<Tuple3<Integer, String, Long>> cityStream = env.fromCollection(list2)
.assignTimestampsAndWatermarks(
//指定水位线、时间戳
new BoundedOutOfOrdernessTimestampExtractor<Tuple3<Integer, String, Long>>(Time.seconds(10)) {
@Override
public long extractTimestamp(Tuple3<Integer, String, Long> element) {
return element.f2;
}
});
//转变为Table
Table userTable = tableEnv.fromDataStream(textStream, "user_name,city_id,ts.rowtime");
Table cityTable = tableEnv.fromDataStream(cityStream, "city_id,city_name,ts.rowtime");
tableEnv.createTemporaryView("userTable", userTable);
tableEnv.createTemporaryView("cityTable", cityTable);
//定义一个TemporalTableFunction
TemporalTableFunction dimCity = cityTable.createTemporalTableFunction("ts", "city_id");
//注册表函数
tableEnv.registerFunction("dimCity", dimCity);
//关联查询
Table result = tableEnv
.sqlQuery("select u.user_name,u.city_id,d.city_name,u.ts from userTable as u " +
", Lateral table (dimCity(u.ts)) d " +
"where u.city_id=d.city_id");
//打印输出
DataStream resultDs = tableEnv.toAppendStream(result, Row.class);
resultDs.print();
env.execute("joinDemo");
}
}
结果输出为:
user1,1001,beijing,1970-01-01T00:00:00.001
user1,1001,beijing2,1970-01-01T00:00:00.010
user2,1002,shanghai,1970-01-01T00:00:00.002
user2,1002,shanghai2,1970-01-01T00:00:00.015
通过结果可以看到,根据主流中的EventTime的时间,去维表流中取响应时间版本的数据。
(3) Kafka Source的EventTime实例
package join.temporaltablefunctionjoin;
import lombok.Data;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;
import java.io.Serializable;
import java.util.Properties;
/**
* Create By 鸣宇淳 on 2020/6/1
**/
public class JoinDemo10 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//指定是EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, bsSettings);
env.setParallelism(1);
//Kafka的ip和要消费的topic,//Kafka设置
String kafkaIPs = "192.168.***.**1:9092,192.168.***.**2:9092,192.168.***.**3:9092";
Properties props = new Properties();
props.setProperty("bootstrap.servers", kafkaIPs);
props.setProperty("group.id", "group.cyb.2");
//读取用户信息Kafka
FlinkKafkaConsumer<UserInfo> userConsumer = new FlinkKafkaConsumer<UserInfo>("user", new UserInfoSchema(), props);
userConsumer.setStartFromEarliest();
userConsumer.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<UserInfo>(Time.seconds(0)) {
@Override
public long extractTimestamp(UserInfo userInfo) {
return userInfo.getTs();
}
});
//读取城市维度信息Kafka
FlinkKafkaConsumer<CityInfo> cityConsumer = new FlinkKafkaConsumer<CityInfo>("city", new CityInfoSchema(), props);
cityConsumer.setStartFromEarliest();
cityConsumer.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<CityInfo>(Time.seconds(0)) {
@Override
public long extractTimestamp(CityInfo cityInfo) {
return cityInfo.getTs();
}
});
//主流,用户流, 格式为:user_name、city_id、ts
Table userTable = tableEnv.fromDataStream(env.addSource(userConsumer),"userName,cityId,ts.rowtime" );
//定义城市维度流,格式为:city_id、city_name、ts
Table cityTable = tableEnv.fromDataStream(env.addSource(cityConsumer),"cityId,cityName,ts.rowtime");
tableEnv.createTemporaryView("userTable", userTable);
tableEnv.createTemporaryView("cityTable", cityTable);
//定义一个TemporalTableFunction
TemporalTableFunction dimCity = cityTable.createTemporalTableFunction("ts", "cityId");
//注册表函数
tableEnv.registerFunction("dimCity", dimCity);
Table u = tableEnv.sqlQuery("select * from userTable");
u.printSchema();
tableEnv.toAppendStream(u, Row.class).print("用户流接收到:");
Table c = tableEnv.sqlQuery("select * from cityTable");
c.printSchema();
tableEnv.toAppendStream(c, Row.class).print("城市流接收到:");
//关联查询
Table result = tableEnv
.sqlQuery("select u.userName,u.cityId,d.cityName,u.ts " +
"from userTable as u " +
", Lateral table (dimCity(u.ts)) d " +
"where u.cityId=d.cityId");
//打印输出
DataStream resultDs = tableEnv.toAppendStream(result, Row.class);
resultDs.print("\t\t关联输出:");
env.execute("joinDemo");
}
}
package join.temporaltablefunctionjoin;
import java.io.Serializable;
/**
* Create By 鸣宇淳 on 2020/6/4
**/
@Data
public class UserInfo implements Serializable {
private String userName;
private Integer cityId;
private Long ts;
}
package join.temporaltablefunctionjoin;
import java.io.Serializable;
/**
* Create By 鸣宇淳 on 2020/6/4
**/
@Data
public class CityInfo implements Serializable {
private Integer cityId;
private String cityName;
private Long ts;
}
package join.temporaltablefunctionjoin;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/**
* Create By 鸣宇淳 on 2020/6/4
**/
public class UserInfoSchema implements DeserializationSchema<UserInfo> {
@Override
public UserInfo deserialize(byte[] message) throws IOException {
String jsonStr = new String(message, StandardCharsets.UTF_8);
UserInfo data = JSON.parseObject(jsonStr, new TypeReference<UserInfo>() {});
return data;
}
@Override
public boolean isEndOfStream(UserInfo nextElement) {
return false;
}
@Override
public TypeInformation<UserInfo> getProducedType() {
return TypeInformation.of(new TypeHint<UserInfo>() {
});
}
}
package join.temporaltablefunctionjoin;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/**
* Create By 鸣宇淳 on 2020/6/4
**/
public class CityInfoSchema implements DeserializationSchema<CityInfo> {
@Override
public CityInfo deserialize(byte[] message) throws IOException {
String jsonStr = new String(message, StandardCharsets.UTF_8);
CityInfo data = JSON.parseObject(jsonStr, new TypeReference<CityInfo>() {});
return data;
}
@Override
public boolean isEndOfStream(CityInfo nextElement) {
return false;
}
@Override
public TypeInformation<CityInfo> getProducedType() {
return TypeInformation.of(new TypeHint<CityInfo>() {
});
}
}
依次向user和city两个topic中写入数据,
用户信息格式:
{“userName”:“user1”,“cityId”:1,“ts”:11}
城市维度格式:
{“cityId”:1,“cityName”:“nanjing”,“ts”:15}
测试得到的输出如下:
城市流接收到:> 1,beijing,1970-01-01T00:00
用户流接收到:> user1,1,1970-01-01T00:00
关联输出:> user1,1,beijing,1970-01-01T00:00
城市流接收到:> 1,shanghai,1970-01-01T00:00:00.005
用户流接收到:> user1,1,1970-01-01T00:00:00.001
关联输出:> user1,1,beijing,1970-01-01T00:00:00.001
用户流接收到:> user1,1,1970-01-01T00:00:00.004
关联输出:> user1,1,beijing,1970-01-01T00:00:00.004
用户流接收到:> user1,1,1970-01-01T00:00:00.005
关联输出:> user1,1,shanghai,1970-01-01T00:00:00.005
用户流接收到:> user1,1,1970-01-01T00:00:00.007
用户流接收到:> user1,1,1970-01-01T00:00:00.009
城市流接收到:> 1,shanghai,1970-01-01T00:00:00.007
关联输出:> user1,1,shanghai,1970-01-01T00:00:00.007
城市流接收到:> 1,wuhan,1970-01-01T00:00:00.010
关联输出:> user1,1,shanghai,1970-01-01T00:00:00.009
用户流接收到:> user1,1,1970-01-01T00:00:00.011
城市流接收到:> 1,nanjing,1970-01-01T00:00:00.015
关联输出:> user1,1,wuhan,1970-01-01T00:00:00.011
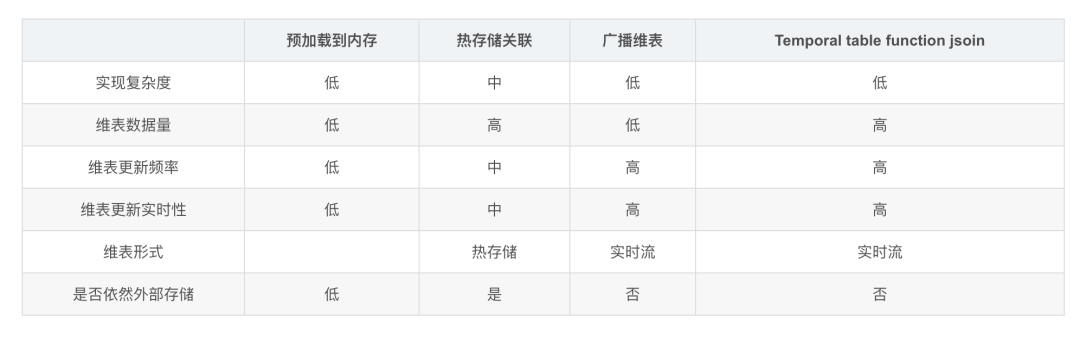
5、四种维表关联方式比较
本文转载自:https://blog.csdn.net/chybin500/article/details/106482620