
【数学基础】简单易懂的张量求导和计算图讲解

斯蒂文买了一股京东,当京东变动 1 美元,斯蒂文的组合变动 1 美元。

这是“标量对标量”求导数。
斯蒂文买了一股京东,两股百度,三股脸书
当京东变动 1 美元,斯蒂文的组合变动 1 美元
当百度变动 1 美元,斯蒂文的组合变动 2 美元
当脸书变动 1 美元,斯蒂文的组合变动 3 美元
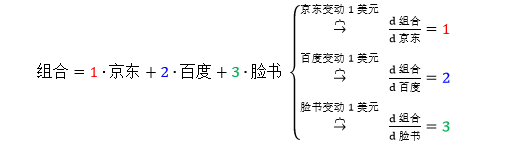
如果令将三只股票整合成列向量,股票 = [京东 百度 脸书],那么
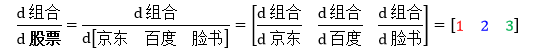
如果令将三只股票整合成行向量,股票 = [京东 百度 脸书]T,那么
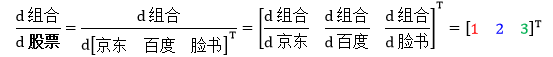
这是“标量对向量”求导数,行向量或列向量都不重要,向量只是一组标量的表现形式,重要的是导数“d组合/d股票”的“股票”的向量类型一致 (要不就是行向量,要不就是列向量)。
斯蒂文买了一股京东,雪莉买了四股京东。当京东变动 1 美元,斯蒂文的组合 A 变动 1 美元,雪莉的组合 B 变动 4 美元。

如果令将两个组合整合成列向量,组合 = [组合A 组合B],那么
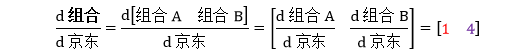
如果令将两个组合整合成行向量,组合 = [组合A 组合B]T,那么
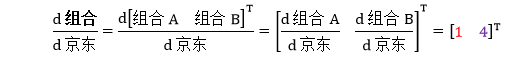
这是“向量对标量”求导数,行向量或列向量都不重要,向量只是一组标量的表现形式,重要的是导数“d组合/d京东”的“组合”的向量类型一致 (要不就是行向量,要不就是列向量)。
斯蒂文买了一股京东,两股百度,三股脸书;雪莉买了四股京东,五股百度,六股脸书,则
当京东变动 1 美元,斯蒂文的组合 A 变动 1 美元,雪莉的组合 B 变动 4 美元
当百度变动 1 美元,斯蒂文的组合 A 变动 2 美元,雪莉的组合 B 变动 5 美元
当脸书变动 1 美元,斯蒂文的组合 A 变动 3 美元,雪莉的组合 B 变动 6 美元
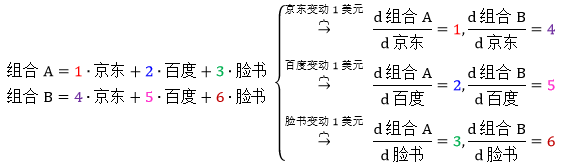
如果令将两个组合和三只股票整合成向量 (行或列),组合 = [组合A 组合B],那么
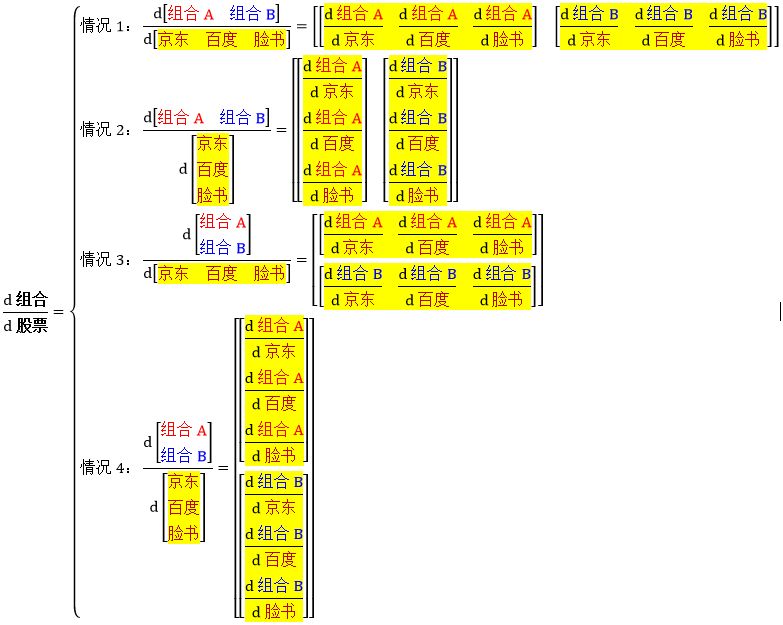
这是“向量对向量”求导数,上面四种情况乍一看眼花缭乱,实际上就是先将“d组合/d股票”写成和“组合”一样大小的向量,再根据“股票”的大小,把组合向量里每个元素展开。这样
情况 1 - 当组合和股票都是行向量,“d组合/d股票”是一个更长的行向量
情况 2 - 当组合是行向量,股票是列向量,“d组合/d股票”是一个矩阵
情况 3 - 当组合是列向量,股票是行向量,“d组合/d股票”是一个矩阵
情况 4 - 当组合和股票都是列向量,“d组合/d股票”是一个更高的列向量
通常使用情况 3 的形式来表示导数。

但是这只是一种惯例表示,具体表示要看具体问题,没有最好的表示,只有最方便的表示。
现在有四家基金,分别在组合 A 和 B 上投资 20% 和 80%,50% 和 50%,70% 和 30%,90% 和 10%,写成矩阵形式为F = U·P = U·(W·S)
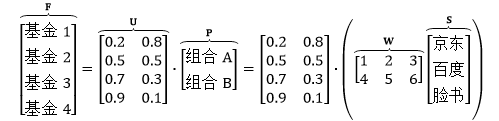
现在来看看所有基金对所有股票的敏感度,即推导“d基金/d股票”,根据上面的惯例得知应该是个 4×2 的矩阵。

注意力只放在红色的 3.4 上,它的计算过程是
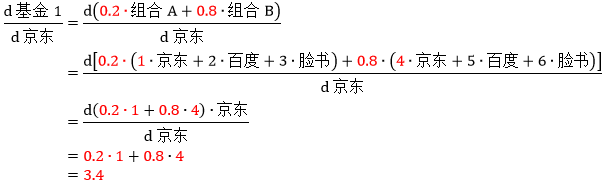
矩阵其他每个结果都可以用同样方法算出。上面矩阵可进一步表示成
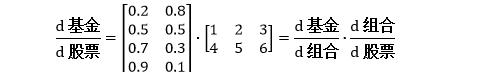
这个就是向量求导的链式法则。
在深度学习中求解中,两个问题最重要
怎样有效的推导出损失函数对所有函数的偏导数?
怎样有效的计算它们?
解决问题 1 需要了解张量求导 (第一节),解决问题 2 需要了解计算图(第二节)。要理解张量请参考《张量 101》。
本帖目录如下:
第一章 - 张量求导
1.1 类型一 ∂y/∂x
1.2 类型二 ∂y/∂x
1.3 类型三 ∂y/∂x
1.4 神经网络应用
第二章 - 计算图
2.1 数学符号
2.2 神经网络 I
2.3 神经网络 II
2.4 神经网络 III
总结
参考资料

从高层次来看,张量求导 ∂y/∂x 可分为三大类型:
类型一:y 或 x 中有一个是标量
类型二:y 和 x 中都不是标量
类型三:y 作用在元素层面作用上
1.1
类型一 ∂y/∂x
求类型一的偏导数,只需记住下面的形状规则。
规则 0 (形状规则):只要 y 或 x 中有一个是标量,那么导数 ∂y/∂x 的形状和非标量的形状一致。
读起来有点绕口,看下面的数学表达式更为直观。
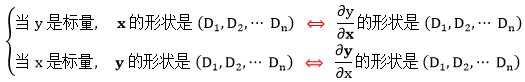
上面形状 (D1, D2, …, Dn) 代表的是 n 个维度,第一个维度有 D1 个元素,第二个维度有 D2 个元素,…,第 n 个维度有 Dn 个元素。比如
标量的形状为 ()
8 个元素的向量的形状为 (8,)
3×5 的矩阵的形状为 (3, 5)
4×2×5×3 的高维张量的形状为 (4, 2, 5, 3)
类型一再往下细分有 5 类
∂标量/∂标量
∂标量/∂向量
∂标量/∂矩阵
∂向量/∂标量
∂矩阵/∂标量
每一类只需用形状规则就可以写出其偏导数,下面来看看这五个具体实例。
当 y 和 x 都是标量。该求导类型在单变量微积分里面已学过,通俗的讲,就是求“y 的变化和 x 的变化”的比率,用符号 ∂y/∂x 来表示。严格来说,单变量导数应写成 dy/dx,但为了和后面偏导数符号一致,就用偏导 ∂ 符号。
注:“∂标量/∂标量”是张量求导基础,所有困难的求导都可以先从“∂标量/∂标量”开始,摸清规律后再推广到“∂张量/∂张量”。
当 y 是标量,x 是含有 n 个元素的向量。

该导数是 y 对 x 中的每个元素 (一共 n 个元素) 求导,然后按 x 的形状排列出来 (形状规则),即,x 是行 (列) 向量,∂y/∂x 就是行 (列) 向量。
注:神经网络的误差函数是 l 一个标量,在求参数最优解时,我们需要计算 l 对向量偏置 b 的偏导数 ∂l/∂b (∂标量/∂向量)。
当 y 是标量,x 是大小为 m×n 的矩阵。
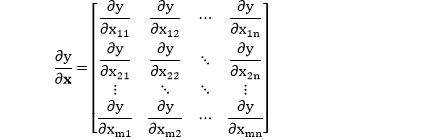
该导数是 y 对 x 中的每个元素 (一共 mn 个元素) 求导,然后按 x 的形状排列出来 (形状规则)。
注:神经网络的误差函数是 l 一个标量,在求参数最优解时,我们需要计算 l 对矩阵权重 W 的偏导数 ∂l/∂W (∂标量/∂矩阵)。
当 y 是含有 m 个元素的向量,x 是标量。
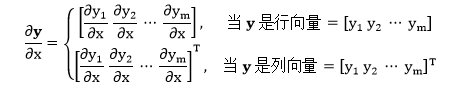
该导数是 y 中的每个元素 (一共 m 个元素) 对 x 求导,然后按 y 的形状排列出来 (形状规则),即,y 是行 (列) 向量,∂y/∂x 就是行 (列) 向量。
注:此类偏导数比较少见,通常我们研究的是单变量输出对多变量输入,而不是反过来的。
当 y 是大小为 m×n 的矩阵,x 是标量。
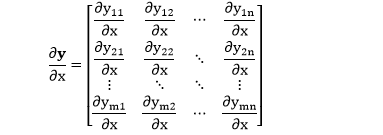
该导数是 y 中的每个元素 (一共 mn 个元素) 对 x 求导,然后按 y 的形状排列出来 (形状规则)。
注:此类偏导数比较少见,通常我们研究的是单变量输出对多变量输入,而不是反过来的。
1.2
类型二 ∂y/∂x
当 y 是含有 m 个元素的向量,x 是含有 n 个元素的向量。无论 y 和 x 是列向量还是行向量,通常偏导数 ∂y/∂x 写成矩阵形式,而且喜欢把 y 放在矩阵的行上,而 x 放在矩阵的列上 [1]。
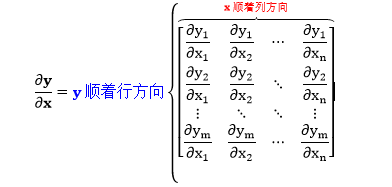
该矩阵的大小是 m×n,称为雅克比 (Jacobian) 矩阵。看个简单的具体例子:

在神经网络中,y 和 x 有两种线性关系用的最多,如下:

根据具体问题,y 和 x 会写成列向量或行向量。套用上面介绍的雅克比矩阵可以给出通解 [2]。
情况一:列向量 y 对 x 求导,其中 y = Wx
我们知道 ∂y/∂x 的结果是个矩阵,但是一次性写出它比较困难,不如来看看它第 i 行第 j 列的元素长成什么样,即求 ∂yi/∂xj
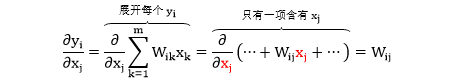
看到 ∂yi/∂xj = Wij 应该可以秒推出 ∂y/∂x = W 了吧,不信验证下。
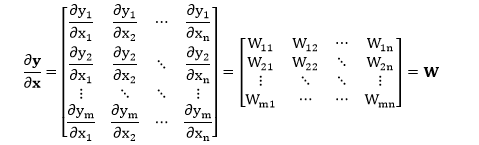
情况二:行向量 y 对 x 求导,其中 y = xW
我们知道 ∂y/∂x 的结果是个矩阵,但是一次性写出它比较困难,不如来看看它第 i 行第 j 列的元素长成什么样,即求 ∂yi/∂xj
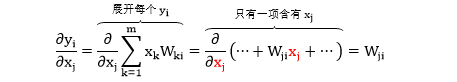
看到 ∂yi/∂xj = Wji 应该可以秒推出 ∂y/∂x = WT 了吧,不信验证下。
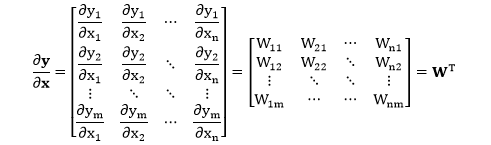
规则 1:当 y, x 都是列向量且 y = Wx,有 ∂y/∂x = W。
规则 2:当 y, x 都是行向量且 y = xW,有 ∂y/∂x = WT。
规则 1 和 2 是向量对向量求导,现在关注向量对矩阵求导 (当然困难一些)。接着上面 y 和 x 的关系,

情况一:列向量 y 对矩阵 W 求导,其中 y = Wx
根据向量 y (n×1) 和矩阵 W (n×m) 的大小,∂y/∂W 是个三维张量,大小为 n×(n×m)。类比于“向量对向量”的雅克比矩阵,∂y/∂W 是个雅克比张量,形式如下:
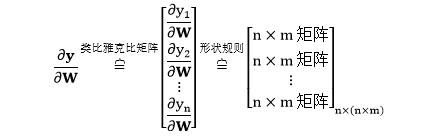
显然一次性写出上面这个三维张量很困难,我们按照 ∂yi/∂Wij ⇨ ∂yi/∂W ⇨ ∂y/∂W 层层推导
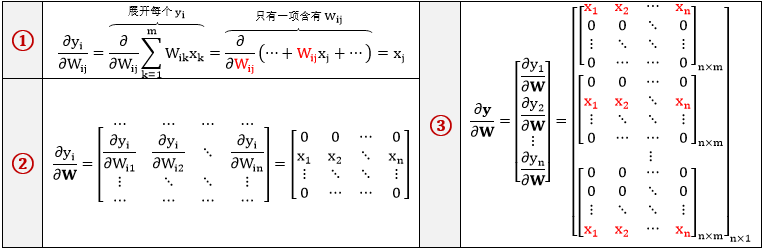
情况二:行向量 y 对矩阵 W 求导,其中 y = xW
根据向量 y (1×n) 和矩阵 W (m×n) 的大小,∂y/∂W 是个三维张量,大小为 n×(m×n) 。类比于“向量对向量”的雅克比矩阵,∂y/∂W 是个雅克比张量,形式如下:
显然一次性写出上面这个三维张量很困难,我们按照 ∂yj/∂Wij ⇨ ∂yj/∂W ⇨ ∂y/∂W 层层推导
注:实践中一般不会显性的把“向量对矩阵”的偏导数写出来,维度太高 (因为向量是一维张量,矩阵是二维张量,因此向量对矩阵的偏导是个三维张量),空间太费。我们只是把它当做中间产出来用。
对于误差函数 l ,它是 y 的标量函数。比起求 ∂y/∂W,我们更有兴趣求 ∂l/∂W (比如想知道变动权重 W 对误差函数l的影响有多大)。∂l/∂W 是和 W 一样大小的矩阵 (形状规则)。
接着上面讨论的两种情况,
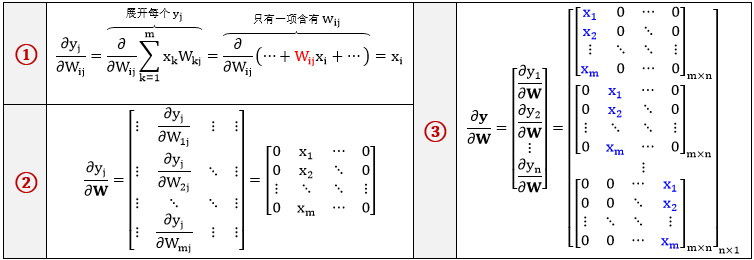
情况一:x 和 y 是列向量,按照 ∂l/∂Wij ⇨ ∂l/∂W 层层推导

情况二:y 和 x 是列向量,按照 ∂l/∂Wij ⇨ ∂l/∂W 层层推导
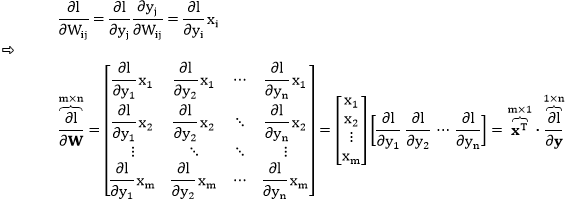
规则 3:当 y, x 都是列向量且 y = Wx,l 是 y 的标量函数,有 ∂l/∂W = ∂l/∂y · xT。
规则 4:当 y, x 都是行向量且 y = xW,l 是 y 的标量函数,有 ∂l/∂W = xT · ∂l/∂y。
本节的“矩阵对向量”和上节的“向量对矩阵”都是下节的“矩阵对矩阵”的特殊形式,因此研究最通用的“矩阵对矩阵”就足够了。
假设 X 是 d×m 的矩阵,W 是 n×d 的矩阵,而 Y = WX 是 n×m 的矩阵。在下面特殊例子里,d= 3, m = 2, n = 2 (以下推出的结果对一般的 d, m, n 也适用)。
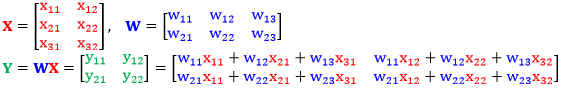
和“向量对矩阵”的道理一样,实践中不会像下面显性的把“矩阵对矩阵”的偏导数 (四维张量,矩阵里面套矩阵) 写出来。
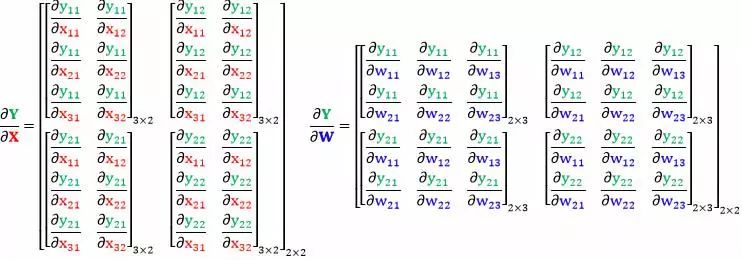
我们只是把它们当做中间产出来用。比如误差函数 l 是 Y 的标量函数,比起求 ∂Y/∂W 和 ∂Y/∂X,我们更有兴趣求 ∂l/∂W 和 ∂l/∂X。根据矩阵链式法则,我们有
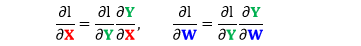
注:上面矩阵链式法则的表达式这样写可能不严谨,因为我们并不知道矩阵和四维张量之间的乘法是如何定义的。比如根据形状规则可推出 ∂l/∂Y, ∂l/∂X 和 ∂l/∂W 的大小,如下表所示:
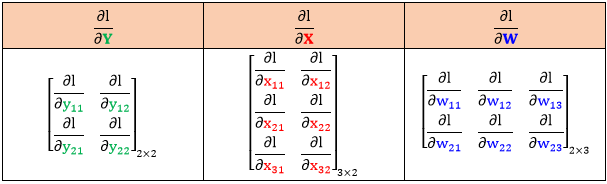
但是我们不知道
2×2 的 ∂l/∂Y 和 2×2×3×2 的 ∂Y/∂X 相乘如何等于 3×2 的 ∂l/∂X
2×2 的 ∂l/∂Y 和 2×2×2×3 的 ∂Y/∂W 相乘如何等于2×3 的 ∂l/∂W
因此要推导出矩阵链式法则还需回到基本的标量链式法则。
首先关注 ∂l/∂X,一个个元素来看

注:点乘“A⊙B”代表将 A 和 B 里所有元素相乘再加总成一个标量。
将 ∂yij/∂x11写成矩阵形式,后面是点乘!类比上式可写出
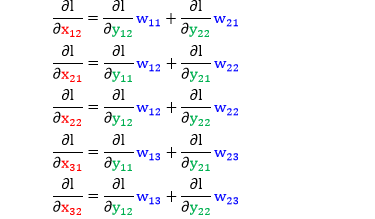
将这六项带入矩阵 ∂l/∂X 整理得到
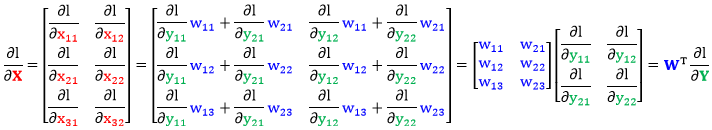
同理得到 ∂l/∂W
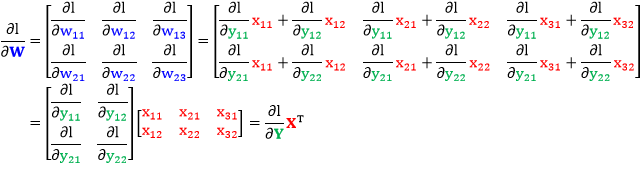
规则 5:Y, X 是矩阵且 Y = WX,l 是 Y 的标量函数,有 ∂l/∂W = ∂l/∂Y · XT。
规则 6:Y, X 是矩阵且 Y = WX,l 是 Y 的标量函数,有 ∂l/∂X = WT · ∂l/∂Y。
1.3
类型三 ∂y/∂x
这一类型的 y = f(x) 都是作用在元素层面上,比如一些基本函数 y = exp(x) 和 y = sin(x),还有神经网络用的函数 y = sigmoid(x) 和 y = relu(x),它们都是
标量进标量出
向量进向量出 (常见)
矩阵进矩阵出 (常见)
张量进张量出
拿 y = sin(x) 举例,整个推导还是可以用“∂向量/∂向量”那一套,但由于 y 和 x 一一对应,因此
y 和 x 是一样的形状
y1 只和 x1 有关,因为 ∂y1/∂xi = 0 当 i ≠ 1
首先写出雅可比矩阵
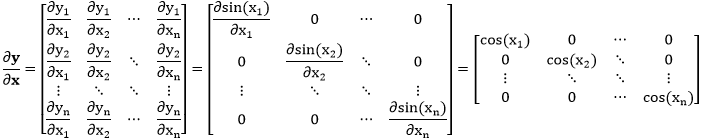
这种元素层面的函数求得的偏导数都是对角矩阵 (diagonal matrix)。
再次把误差函数 l 请出来 (l 是 y 的标量函数),通常更感兴趣的是求 ∂l/∂x。对某个 xi,根据链式法则得到
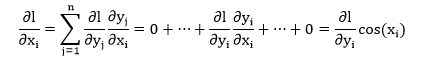
将上面 n 项整理成向量得到 (发现这种情况下“向量版链式法则”成立)
但在实操上,我们更喜欢用“元素层面操作”来描述上式,通常用 ◯ 加符号来表示,比如
⊗:元素层面相乘
⊘:元素层面相除
用此惯例,上式可写成
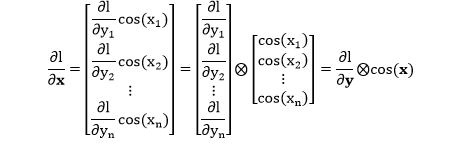
规则 7:当函数 y = f(x) 是在元素层面操作,l 是 y 的标量函数,有 ∂l/∂x = ∂l/∂y ⊗ f'(x)。
1.4
神经网络应用
神经网络里有两大类函数需要特别留意:
层与层之间的转换函数 (类型三求导)
输出结果和标签之间的误差函数 (类型一求导)
转换函数是将神经网络上一层输出转换成下一层输入的函数,常用的转换函数见下表。

其中 identity 函数是线性的,可用于回归问题的输出层,其他三个是非线性的,sigmoid 可用于二分类的输出层,而 tanh 和 relu 比较多用在隐藏层。此外多分类问题的输出层用到的函数是 softmax,其函数和导数如下:
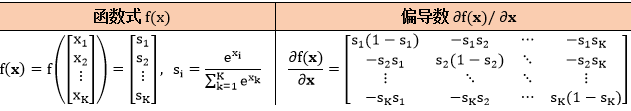
关于 softmax 的偏导数用“向量对向量”的方法可以轻松推出来。
回归问题的均方误差 (mean square error, MSE) 函数,和二分类、多分类问题的交叉熵 (cross entropy, CE) 函数。对 m 个数据点,假设真实值为 Y,预测值为 A,这三种误差函数的具体形式如下:
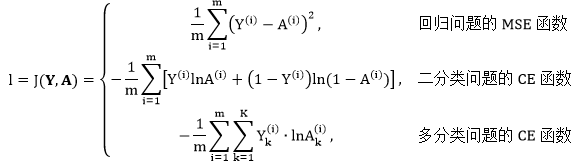
其中上标 (i) 代表第 i 个数据。
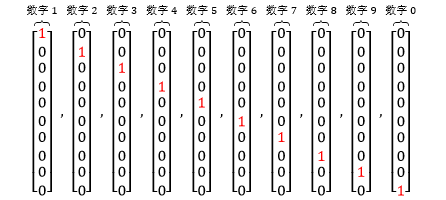
注意多分类问题 CE 函数中 Y 和 A 有下标 k,代表着是第 k 类输出。以数字分类为例,最后数字“零到九”一共有 10 类,因此 K = 10,而通常用独热编码 (one-hot encoding) 来表示“零到九”。具体来说,用 10×1 的向量代表数字 i,而该向量第 i 个元素是 1,其它元素为 0。如下图所示:
再回到求导这来,在神经网络里,误差函数的预测值 A 就是最后输出层的产出,通过某个转换函数而得到。具体来说,
回归问题的 A 由 identity 转换函数 f(x) 算出
二分类问题的 A 由 sigmoid 转换函数 f(x) 算出
多分类问题的 A 由 softmax 转换函数 f(x) 算出
那么标量 l 对 x 的偏导数可先由下面“不怎么严谨”的链式法则表示出来
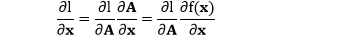
对第一项 ∂l/∂A,因为 l 是标量,A 是向量,由规则 0 (形状规则) 可知 ∂l/∂A 和 A 的形状一样。
对第二项 ∂f(x)/∂x,由规则 7 可知,∂f(x)/∂x 和 ∂l/∂A 的形状一样。
上面两项形状相同,因此 ∂l/∂x 就是将它们在元素层面相乘得到的结果,因此上面“不怎么严谨”的链式法则可严谨写成

但上面这种形式只对回归问题和二分类问题适用,多分类问题需要更细致的处理。下面一一来分析。
回归问题

二分类问题

多分类问题
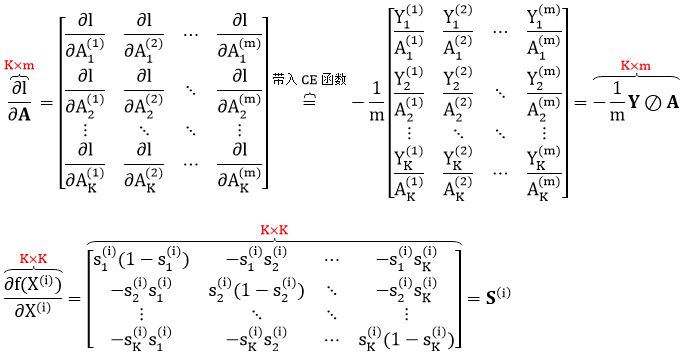
咋一看这两项形状不一样,不能像回归问题和二分类问题那样在元素层面操作了,而只能张量点乘了。
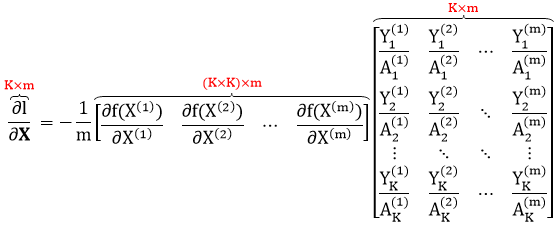
上面公式太复杂,我们把注意力先只放在第 i 个数据上。但细想一下 Y(i) 的元素,它是个 K×1 的向量,只有一个元素为 1 (假设第 j 个) 其余为 0,因此
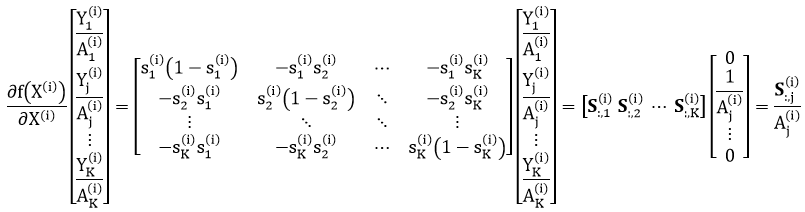
其中下标 :,j 表示矩阵 S(i) 的第 j 列。合并起来得

其中 n1, n2, …, nm 是标签 Y(1), Y(2), …, Y(m) 中元素为 1 的索引。比如 Y(1) 第 3 个元素为 1,Y(2) 第 6 个元素为 1,Y(m) 第 10 个元素为 1,那么 [n1, n2, …, nm] = [3 6 10]。
2.1
数学符号
以下数学符号务必认真看!惯例是用小括号 (i) 上标表示第 i 个数据,用中括号 [L] 上标表示神经网络的第 L 层。

本节只用两层神经网络来说明一些核心问题,比如正向传播、反向传播、计算图等等。我们由易到难的讨论以下三种情况:
一个数据点,单特征输入 x 和输出 y 都是标量 (以回归问题举例)
一个数据点,多特征输入 x 是向量,输出 y 是表量 (以二分类问题举例)
m 个数据点,输入 X 和输出 Y 都是矩阵 (以多分类问题举例)
关于神经网络结构里面基本元素的介绍,请参考《人工神经网络》和《正向传播和反向传播》。
注:情况一和情况二只有一个数据点,现实中几乎不会出现这样的神经网络。这样设计的情况就是为了能由易到难层层深入来解释正向传播和反向传播。
2.2
神经网络 I
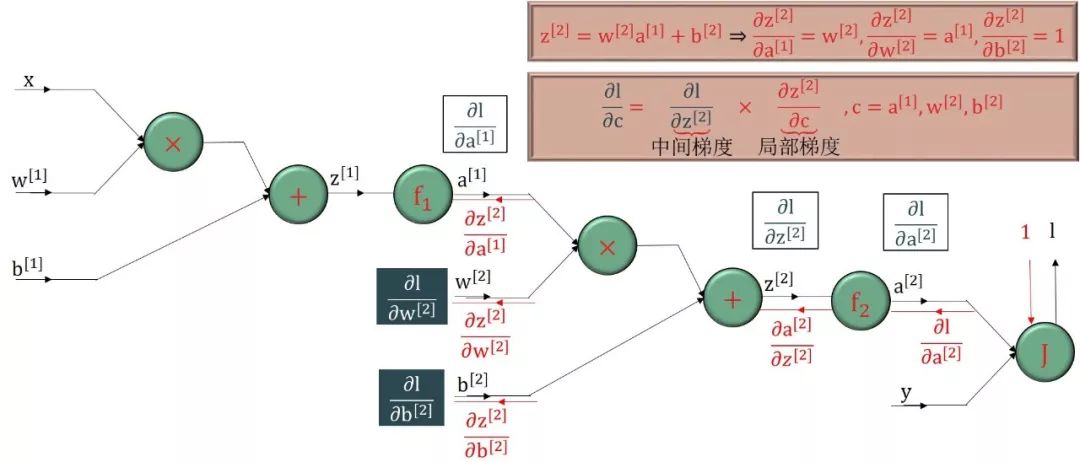
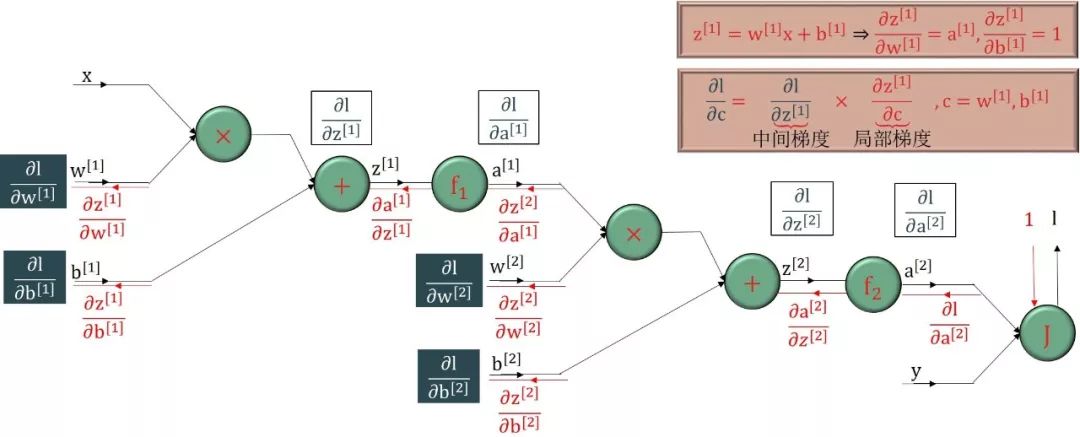
该神经网络只有单数据点(x, y),每个输入 x 只有单特征,只有单个输出 y。在下图中,所有 x, w[1], b[1], z[1], a[1], w[2], b[2], z[2], a[2], y 都是标量。下图用正向传播一步步计算出 a[2]。
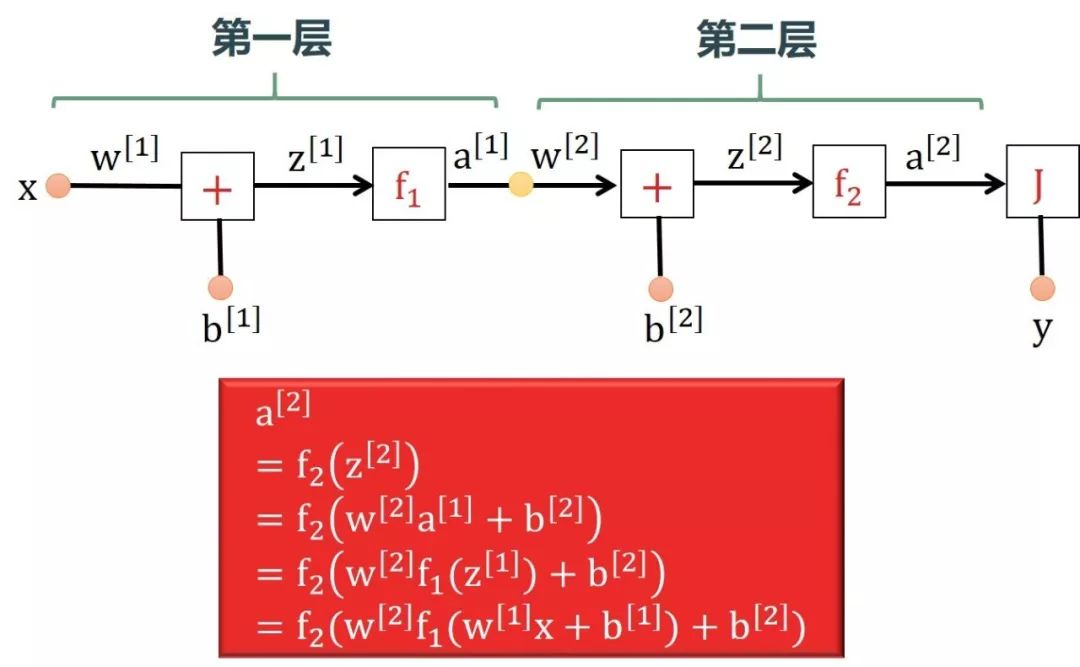
以回归问题为例,单个数据点的误差为
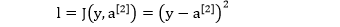
神经网络里面 w[1], b[1], w[2] 和 b[2] 都是标量型参数,通过链式法则以反向传播的方式解出它们
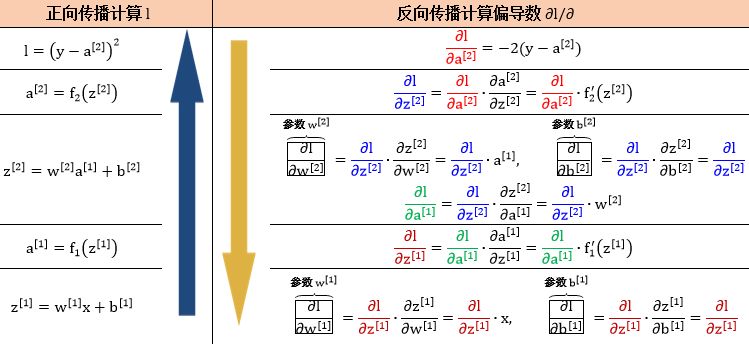
在反向传播过程中
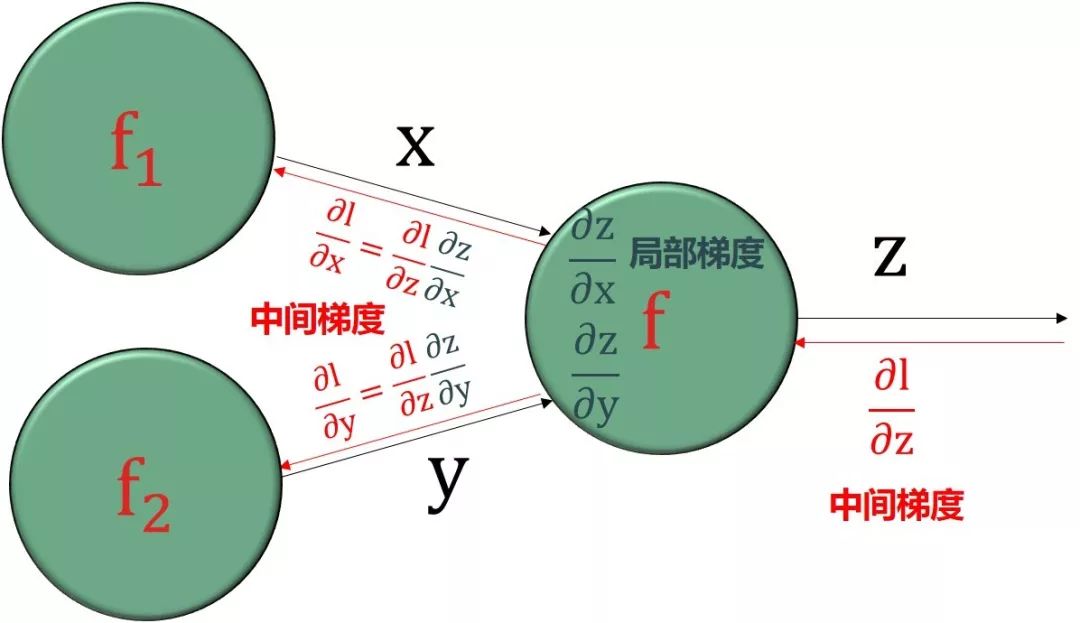
所有彩色的偏导数,∂l/∂a[2], ∂l/∂z[2], ∂l/∂a[1], ∂l/∂z[1],都可以重复使用,称为中间梯度 (intermediate gradient),格式为“∂损失/∂中间变量”
所有黑色的偏导数,∂a[2]/∂z[2], ∂z[2]/∂w[2], ∂z[2]/∂b[2], ∂a[1]/∂z[1], ∂z[1]/∂w[1], ∂z[1]/∂b[1],称为局部梯度 (local gradient),格式为“∂中间变量/∂中间变量”或“∂中间变量/∂参数”
所有带方框的偏导数,∂l/∂w[2], ∂l/∂b[2], ∂l/∂w[1], ∂l/∂b[1],是最终需要的,称为最终梯度 (final gradient),格式为“∂损失/∂参数”
整个反向传播的精髓就是使用局部梯度来计算中间梯度,再尽多不重复的用中间梯度计算最终梯度。
最终梯度 = 中间梯度 × 局部梯度
为了能更精确地描述反向传播算法,使用更精确的计算图 (computational graph) 是很有帮助的。
计算图就是将计算形式化图形的方法,由输入结点、输出结点、函数 (从输入到输出的) 三部分组成。
每个一节点来表示一个变量,可以是标量、向量、矩阵或张量。
每个函数表示一个操作,可以作用在单个变量上,也可以作用在多个变量上。
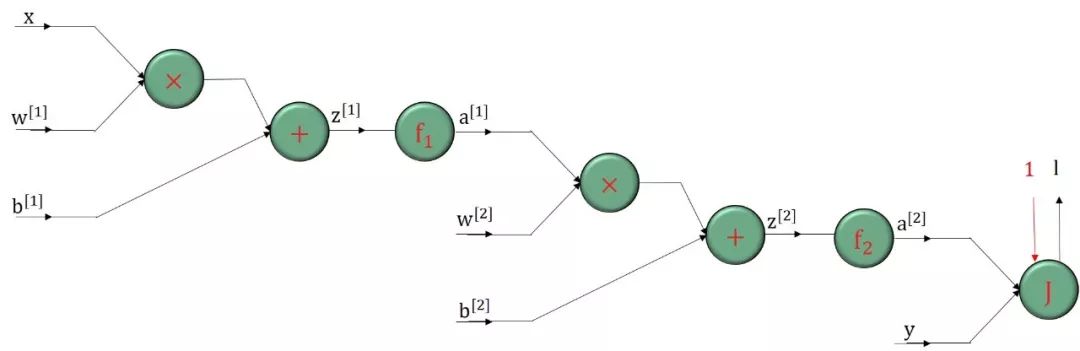
计算图的实例如下:
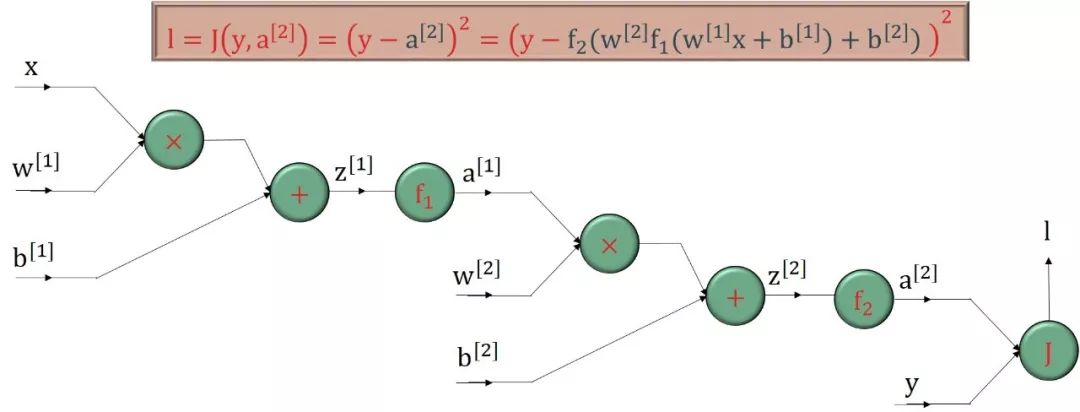
上图中
x, w[1], b[1], w[2], b[2], y 是输入节点,l 是输出节点,它们都是标量。
绿色圆框里面的函数 +, ×, f1, f2, J 都可看做操作,比如 +, ×, J 作用在两个变量上,而 f1, f2 作用在单变量上。
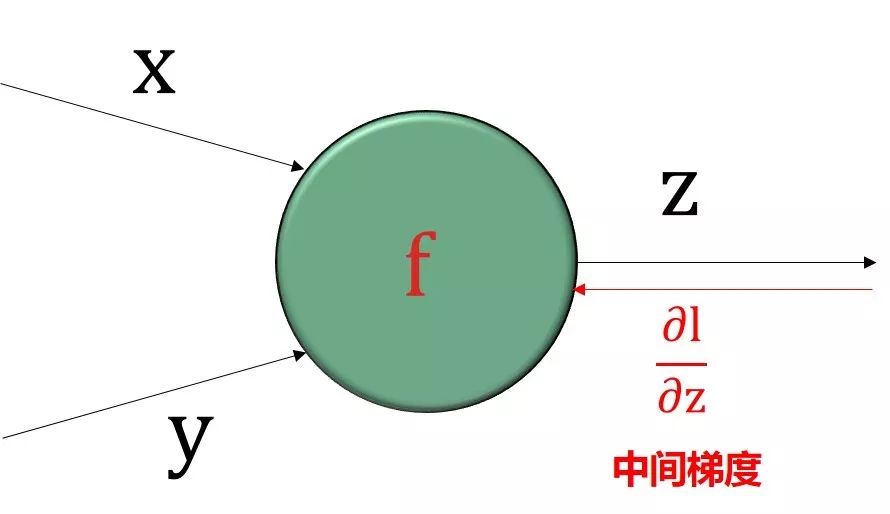
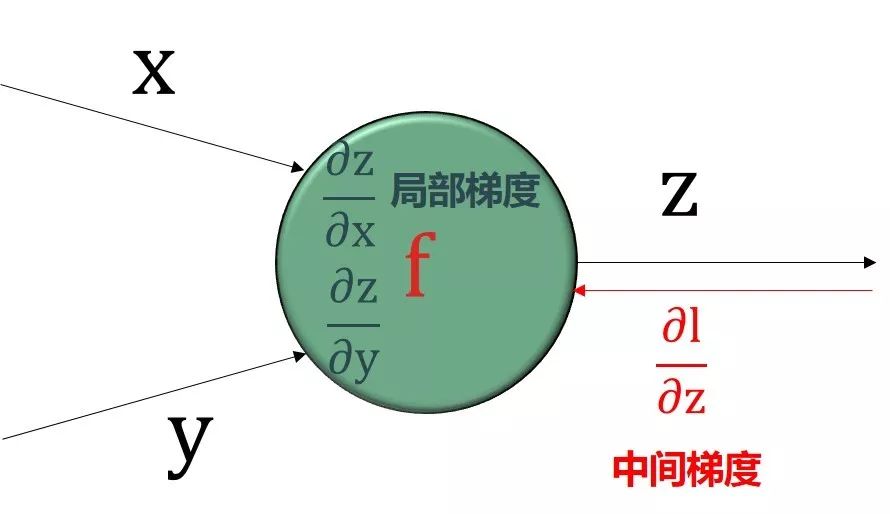
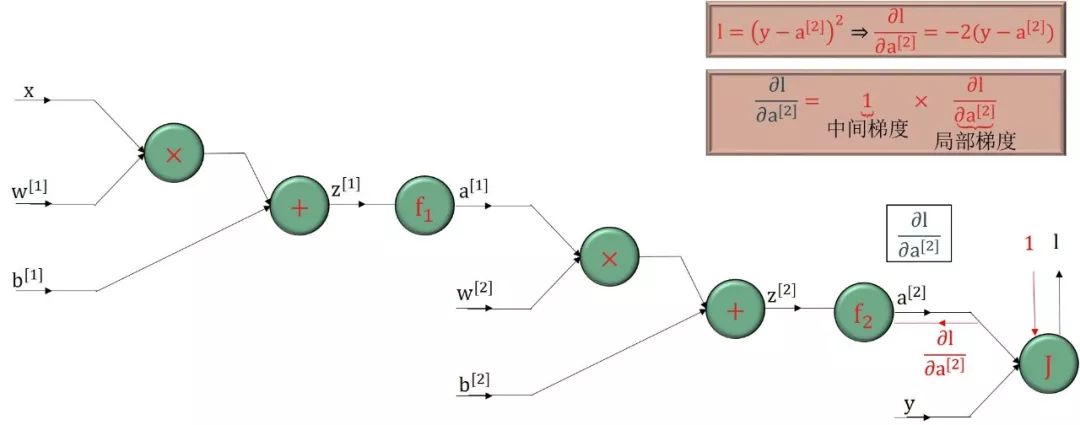
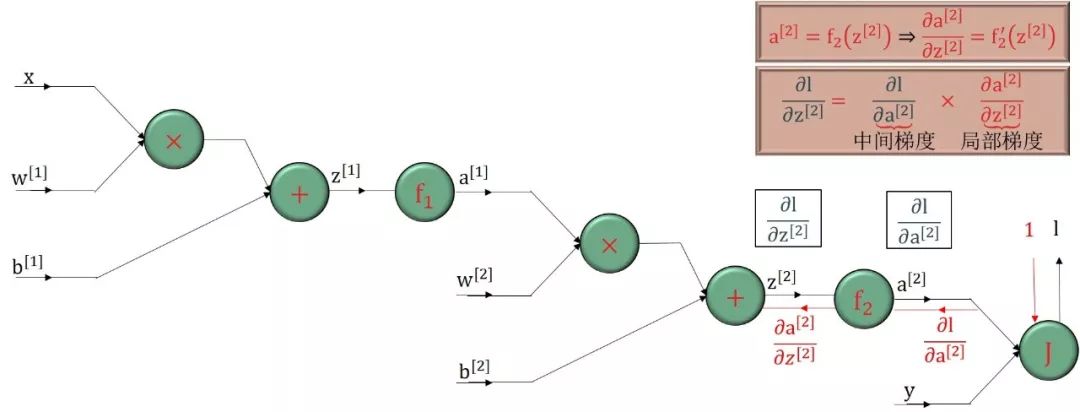
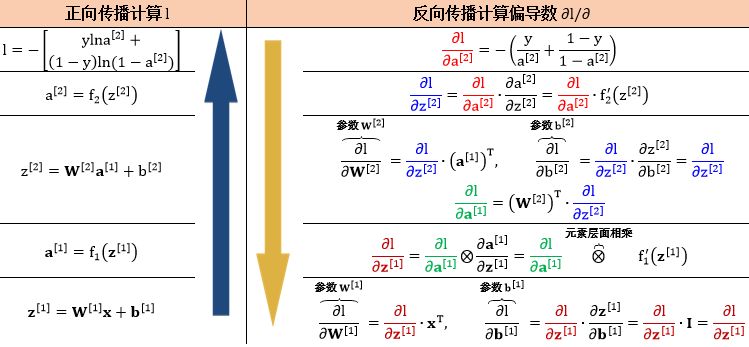
反向传播顾名思义就是从最后输出节点的梯度“∂l /∂l = 1”开始,沿着反方向计算梯度。核心基础就是
利用“上一个已算好的中间梯度”
根据绿色圆框的函数得到“局部梯度”
再用链式法则得到“下一个中间梯度”
把这个过程反向传播下去
四个步骤如下图:
步骤 1
步骤 2
步骤 3
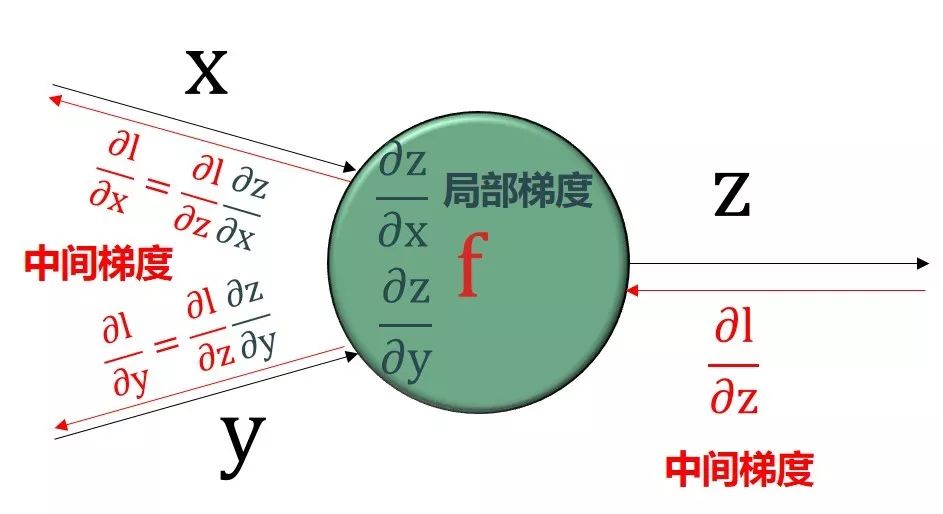
步骤 4
上面四个步骤图看懂之后,结合本节的神经网络实例,再理解下面六张图的解释就容易了 (点击看大图)。

2.3
神经网络 II
该神经网络只有单数据点 (x, y),每个输入 x 有多特征,还是单个输出 y。在下图中,W[1], W[2] 是矩阵,x, z[1], a[1], b[1] 是向量,b[2], z[2], a[2], y 是标量。下图用正向传播一步步计算出 a[2]。
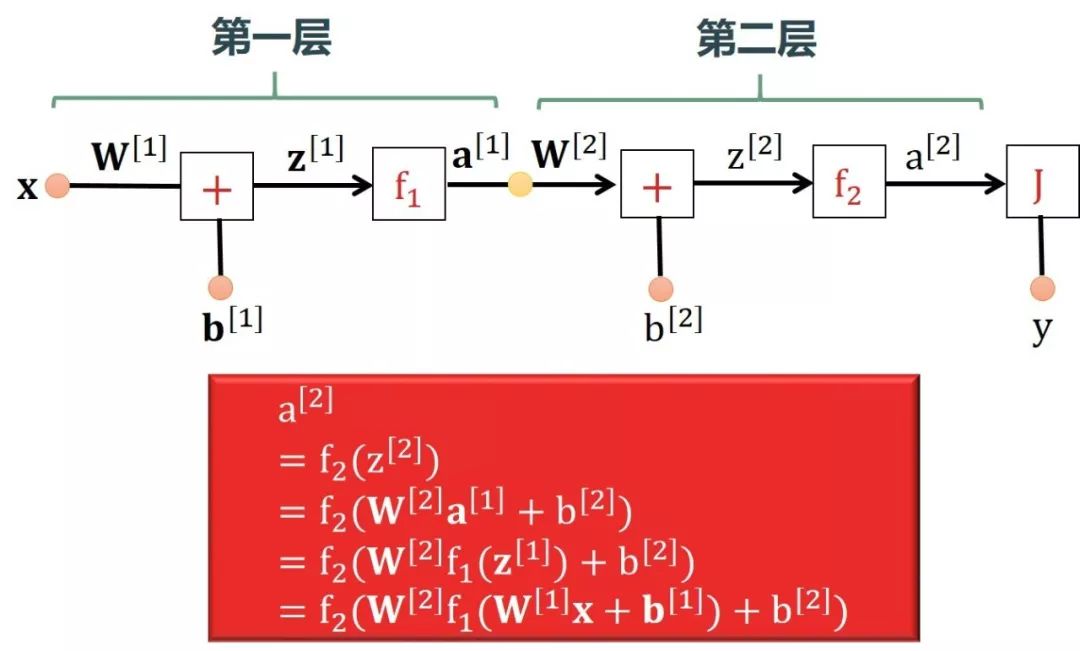
整个正向传播计算的变量之间的形状是匹配的,验证如下:
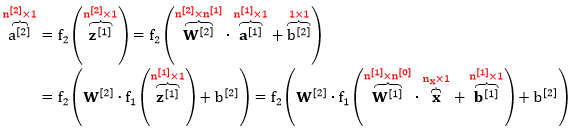
在上式中
输入层的神经元的个数 = 特征个数,n[0] = nx,这样看 W[1]x 的形状完全匹配
输出层的神经元的个数 = 单输出,n[2] = ny = 1,这样看 a[2] 是个标量
以二分类问题为例,单个数据点的误差为 (y = 0 或 1)
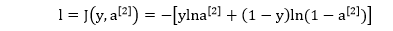
神经网络里面 W[1] 和 W[2] 是矩阵型参数,b[1] 是向量型参数,b[2] 是标量型参数,通过链式法则以反向传播的方式解出它们
根据第一章的张量求导规则,计算上表的偏导数不能更简单:
计算 ∂l/∂a[2],规则 0
计算 ∂l/∂z[2],标量链式法则
计算 ∂l/∂W[2],规则 5
计算 ∂l/∂b[2],标量链式法则
计算 ∂l/∂a[1],规则 6
计算 ∂l/∂z[1],规则 7
计算 ∂l/∂W[1],规则 5
计算 ∂l/∂b[1],规则 6
计算完上面偏导数之后可用规则 0 (形状规则) 来检查左右两边的形状是否吻合。
计算图对于非标量也适用,大致结构和上节的非常类似。需要注意的是有时“向量或矩阵版链式法则”不能自然以连乘的方式写出来,因为我们其显示表达式写出来了。如下图 (点击看大图),
2.4
神经网络 III
该神经网络考虑 m 个数据点 (X, Y),每个输入 X 有多特征,每个输出 Y 有多类值 (可以想成是 MNIST 手写数字分类问题,其中有 50000 个训练数据,X 有 784 个像素特征,Y 是数字零到九的 10 类)。在下图中,X, W[1], Z[1], A[1], W[2], Z[2], A[2], Y 都是矩阵,b[1] 和 b[2] 是向量。下图用正向传播一步步计算出 A[2]。
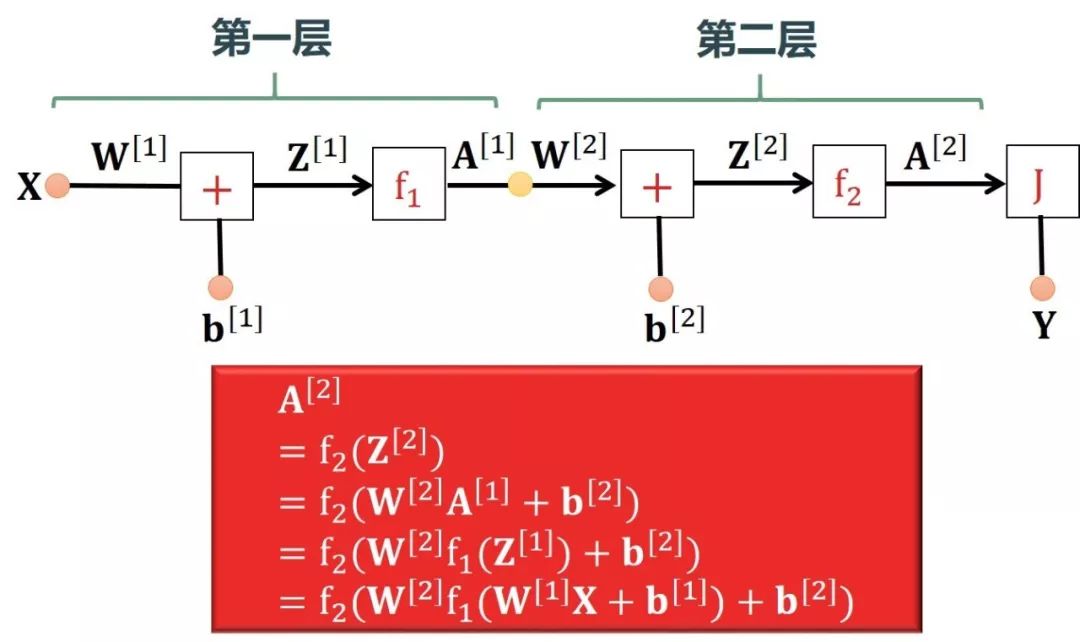
整个正向传播计算的变量之间的形状是匹配的,验证如下:
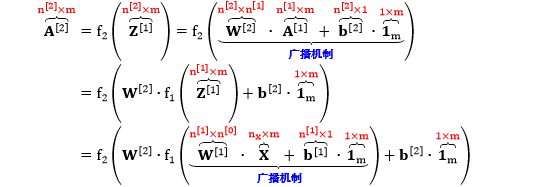
在上式中
输入层的神经元的个数 = 特征个数,n[0] = nx,这样看 W[1]X 的形状完全匹配
输出层的神经元的个数 = 10 类输出,n[2] = ny = 10
为了能达到广播机制一样的效果,在相应的 b 前面加入全部元素都为 1 的向量 1m
多分类问题下的误差函数为
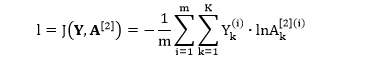
其中 Y 是真实值,A 是神经网络的预测值 (具体说明见小节 1.4)。
神经网络里面 W[1] 和 W[2] 是矩阵型参数,b[1] 和 b[2] 是向量型参数,通过链式法则以反向传播的方式解出它们。
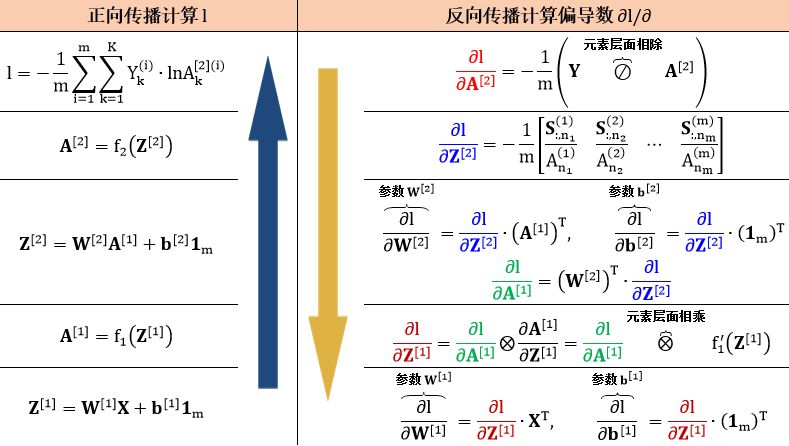
根据第一章的张量求导规则,计算上表的偏导数不能更简单:
计算 ∂l/∂A[2],规则 0
计算 ∂l/∂Z[2],见小节 1.4
计算 ∂l/∂W[2],规则 5
计算 ∂l/∂b[2],规则 5
计算 ∂l/∂A[1],规则 6
计算 ∂l/∂Z[1],规则 7
计算 ∂l/∂W[1],规则 5
计算 ∂l/∂b[1],规则 5
计算完上面偏导数之后可用规则 0 (形状规则) 来检查左右两边的形状是否吻合。
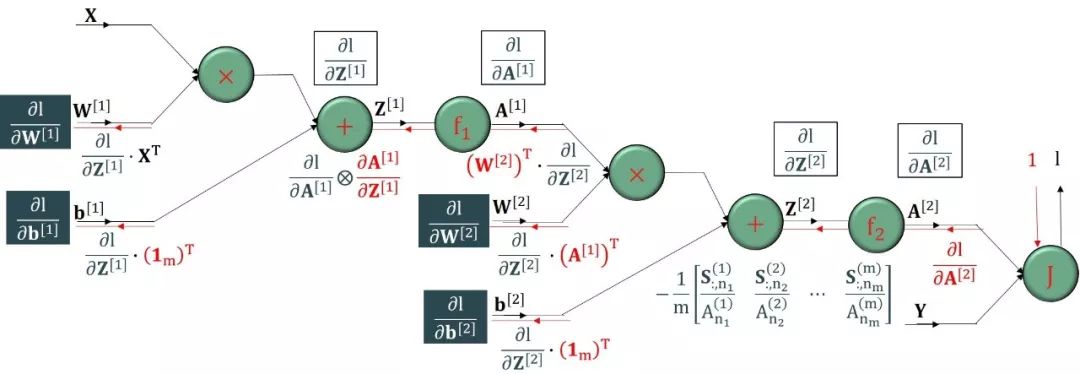
计算图对于非标量也适用,大致结构和上节的非常类似。需要注意的是有时“矩阵版链式法则”不能自然以连乘的方式写出来,因为我们其显示表达式写出来了。如下图 (点击看大图),
本帖除了文中参考的资料 [1] 和[2],还参考了 [3], [4], [5]。
深度学习可以不严谨的认为是各类架构神经网络,神经网络的正向传播就是张量计算,既一连串操作在张量上。做优化第一步是要求出损失函数对所有参数的导数 (张量形式)。我知道
写出张量导数表达式难,就精简出 8 条规则
串联张量导数在一起难,就用计算图来理解
这两点都会了,你会发现反向传播就是张量版链式法则。
注:l 是 y 或 Y 的标量函数

在这 8 条规则中
规则 0 (形状规则) 最重要,很多时候你只要检查各个张量的形状就知道公式推导的是否正确。
规则 1 和 2 是基础,做法就是每次对标量求导,再按照雅克比矩阵一个个填满就得到了答案。
有些人喜欢把 x 写成列向量,有些人喜欢把 x 写成行向量,规则 4 和 5 根据这些喜好给出相应的偏导数。
现实中 X 通常是个二维矩阵,一个维度是特征数,一个维度是数据数,因此规则 5 和 6 最普适,是规则 3 和 4 的推广。
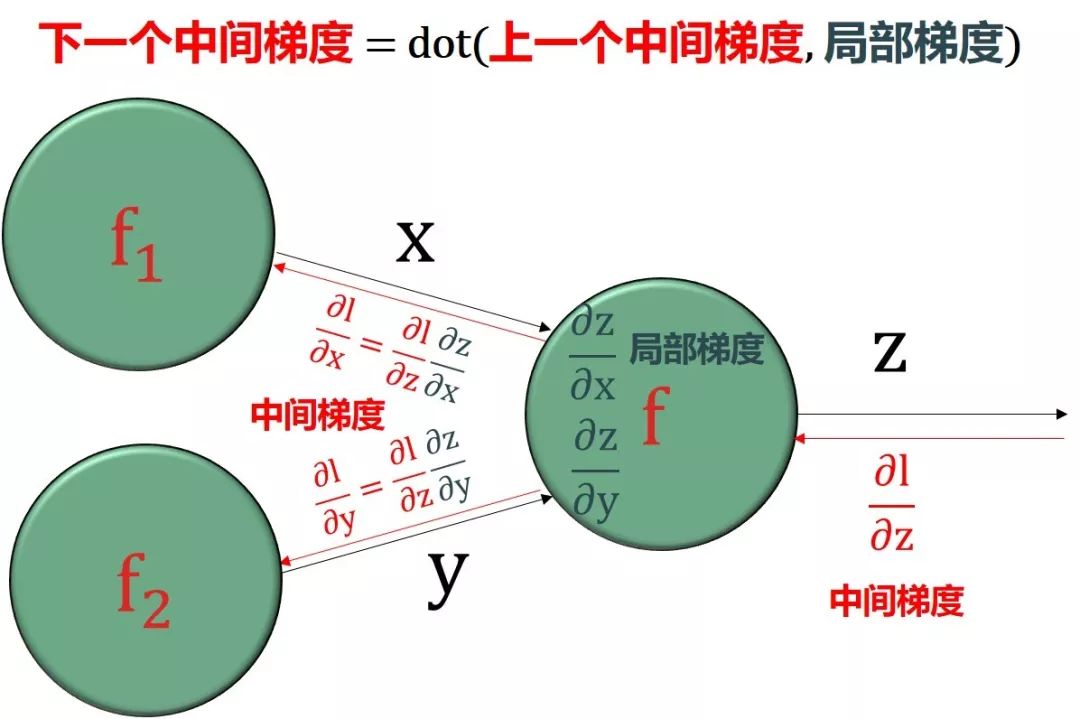
注意我把“中间梯度×局部梯度”该成 dot(中间梯度, 局部梯度),这个函数实际上是 numpy 里面张量点乘的操作。
本帖内容吃透,终于可以放手来研究深度学习中的各种网络结构了,最重要的是,再也不用悚各种反向传播推导了。你可以自信的说,不就是链式法则么,带张量的?Stay Tuned!

参考资料

往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):