
抖音 Android 性能优化:新一代全能型性能分析工具 Rhea!
微信改了推动机制,真爱请星标本公号 公众号回复加入BATcoder技术群 BAT
本文选自「抖音 Android 性能优化」系列文章。
「抖音 Android 性能优化」系列文章是由抖音 Android 基础技术部门技术专家倾力打造的技术干货内容,和大家分享基础技术团队在打造极致用户体验的抖音的过程中,收获的性能优化方法论、工具和实践,与各位技术同学一起交流成长。
用户交互响应的耗时,作为 Android 用户日常感知最深的一项性能指标,在日常开发中有着非常重要的意义。而抖音 Android 基础技术团队为打造极致的交互响应体验,一直在致力于极致性能的探索,其中就包括如何打造极致的耗时检测工具。
概述
俗话说,工欲善其事,必先利其器,我们要做好性能优化,首要是要能够发现性能的问题,这就需要有靠谱的工具来帮助我们做性能分析。市面上主流的性能分析工具有:Systrace、TraceView、Android Studio 的 CPU Profiler。相信做性能优化的同学对这些工具应该都是非常熟悉了,抖音最早也是用 Systrace 作为主要的分析工具,在优化前期也发挥了比较大的作用。随着抖音的性能优化来到了深水区,我们需要发现并解决更细粒度、更多维度的性能问题,我们会关注几毫秒的耗时,关注线上一些低端机用户遇到的锁阻塞和 IO 等待问题。而市面上这些主流的性能分析工具因其使用的局限性和较大的性能损耗,已经无法满足抖音性能优化的需求。为了能够百尺竿头更进一步,我们需要开发更加灵活、精细化以及多元的信息和工具来辅助我们进行高效的优化工作。
在这样的背景之下,抖音 Android 基础技术团队开发了 Rhea( [ˈriːə] 瑞亚,寓意时光女神)跟踪器(Tracer),其是一种通过静态代码插桩技术自动添加 Trace,用来分析 APP 运行时耗时的性能分析工具,意思是要做一个功能全面、追求效率、大家都喜欢的女神,也符合我们工具的核心设计原则。Rhea 跟踪器获取 Trace 不仅要性能损耗低,还要能脱离 PC 端工具在 App 侧直接抓取,跟踪更多常规函数耗时的同时还要可以跟踪系统调用,如:锁信息、I/O 耗时、Binder IPC 以及更多其他信息。最后,还提供转换脚本工具,用于将原始跟踪文件生成可视化报告,便于用户分析性能问题。
优势对比
Rhea 当前因其无侵入、高性能、信息全等优势已在字节多个 APP 上落地使用,效果明显,已多次帮助大家快速发现性能问题,其包含的信息包括不限层级的应用层函数、IO、锁、Binder、CPU 调度等耗时信息等,其部分效果如下所示:
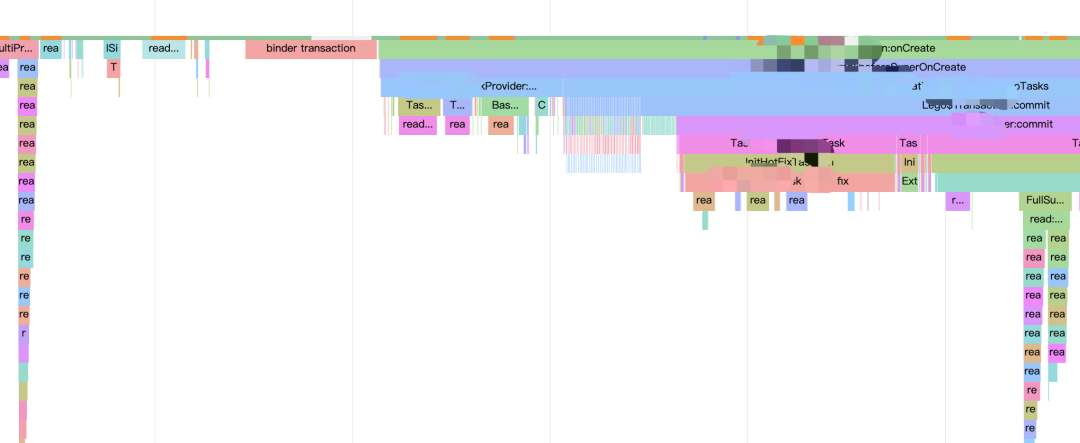
相对于其他 Android 性能排查工具,其具体优势表现为:
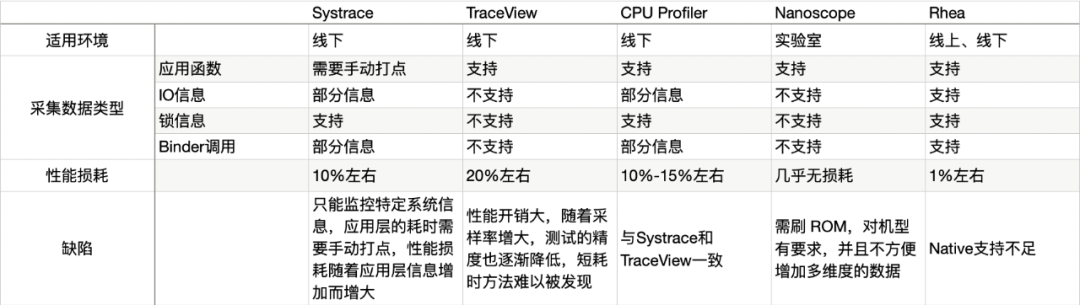
当前,Systrace 只能监控特定系统信息,监控应用层的耗时则需要手动打点;TraceView 性能跟采样率关系密切,采样过于频繁性能开销巨大,采样过低又难以精准发现问题函数;Nanoscope 虽然几乎没有性能损耗,但每次都需定制 ROM 刷机,使用成本非常高,并且这些工具都只支持 debugable 的应用程序线下分析,这些工具在针对 APP 性能优化都有不甚完美之处,而 Rhea 是一个集大成者,融合了各工具优势并弥补了相关缺陷。
架构演进之路
第一阶段:基于 Systrace 补充函数耗时 Trace
Systrace 是 Android 性能调试优化的常用工具,它可以收集进程的活动信息,如函数调用耗时、锁等;也可以收集内核信息,如 CPU 调度、IO 活动、Binder 调用信息等;这些信息会统一时间轴,在 Chrome 浏览器中显示出来,方便工程师性能调试、优化卡顿等工作。因此,抖音早期性能优化首选 Systrace 作为主要工具,其大致流程如下:

1. 功能改造
Systrace 工具只能监控特定系统调用的耗时情况,它不支持应用程序代码的耗时分析,所以在使用时有一些局限性。原生 Systrace 需要开发者在方法的起止位置手动加入 Trace.beginSection 与 Trace.endSection 方法对,这个过程就变成了开发者预判耗时位置,然后在手动加入监控函数对,通过不断重复添加监控点、打包、运行、采集数据,从而一步步完成耗时方法定位,这也使得 Systrace 的使用成本变得极高。
为了提高 Systrace 的易用性,我们开发了 Rhea 1.0 对 Systrace 功能进行了改造,加入了自动插桩机制:通过字节码插桩自动完成 Trace.beginSection 和 Trace.endSection 方法对的插入,并且通过运行时限制方法层级的方式,来有效控制因引入监控带来的性能损耗。
插桩类及桩方法伪代码:
class Tracer{
method_stack = list()
max_size = 6
methodIn(method_id, method_name){
if(method_stack.size()<=max_size){
method_stack.push(method_id)
Trace.beginSection(method_name)
}
}
methodOut(){
if(method_stack.size>0){
method_stack.pop()
Trace.end()
}
}
}
被插桩方法:
method1(){
Tracer.methodIn(1,method1)
...
Tracer.methodOut()
}
输出数据如下所示,指定层级内所有方法即可按照预期展示在输出 html 中: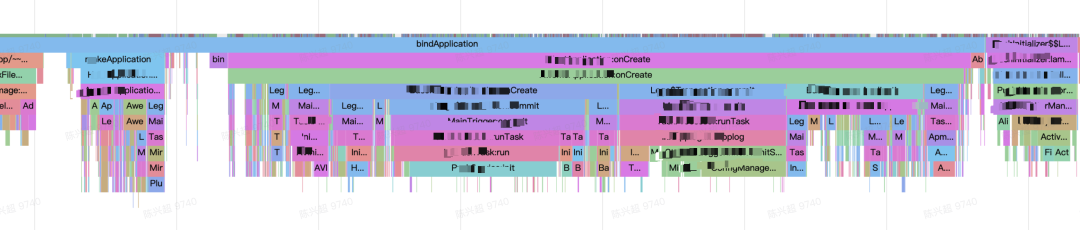
2. 方法 Did not finished 问题
在使用改造后的 systrace 时,我们时常会遇到如下问题:
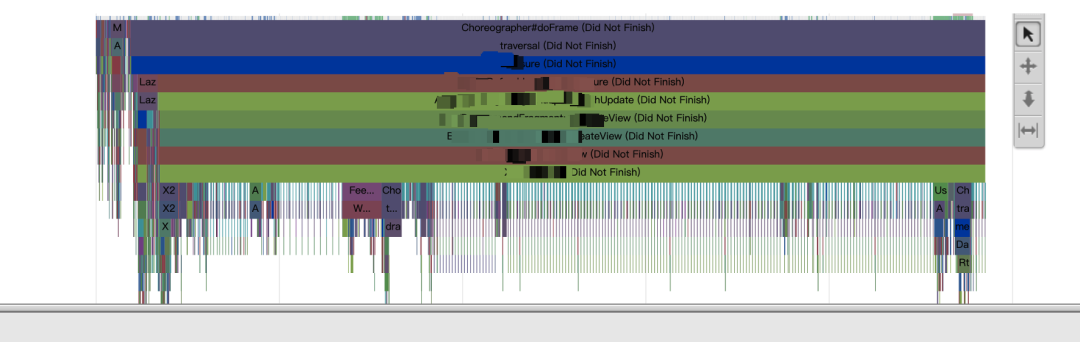
分析发现,主要原因在于方法在运行期执行中被中断,例如:方法执行过程中发生异常后,被其调用者方法捕获,发生异常方法的 Systracer.o 方法未被调用。如图:test 方法中的 error 方法执行时出现 arr[2]的数组越界,导致 test 方法中的插桩方法 SysTracer.o(13L)未调用,异常被 onCreate 中的 catch 块捕获,从而导致 test 的插桩方法没有被成对调用,最终导致了 test 外层所有的方法调用都无法正确闭合。(注意:本小结提到的桩方法,即 SysTracer 相关方法,均是通过字节码插桩自动插入)
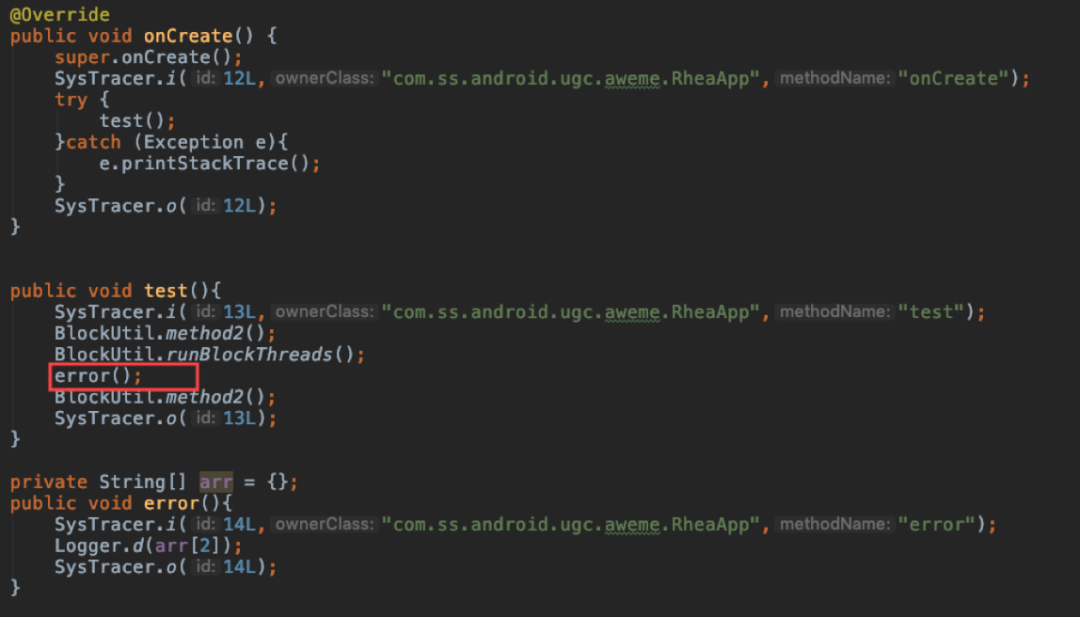
解决办法,在外层所有异常捕获的位置,额外插入桩方法,重新这种异常调用链下的桩方法不成对问题。如下图:
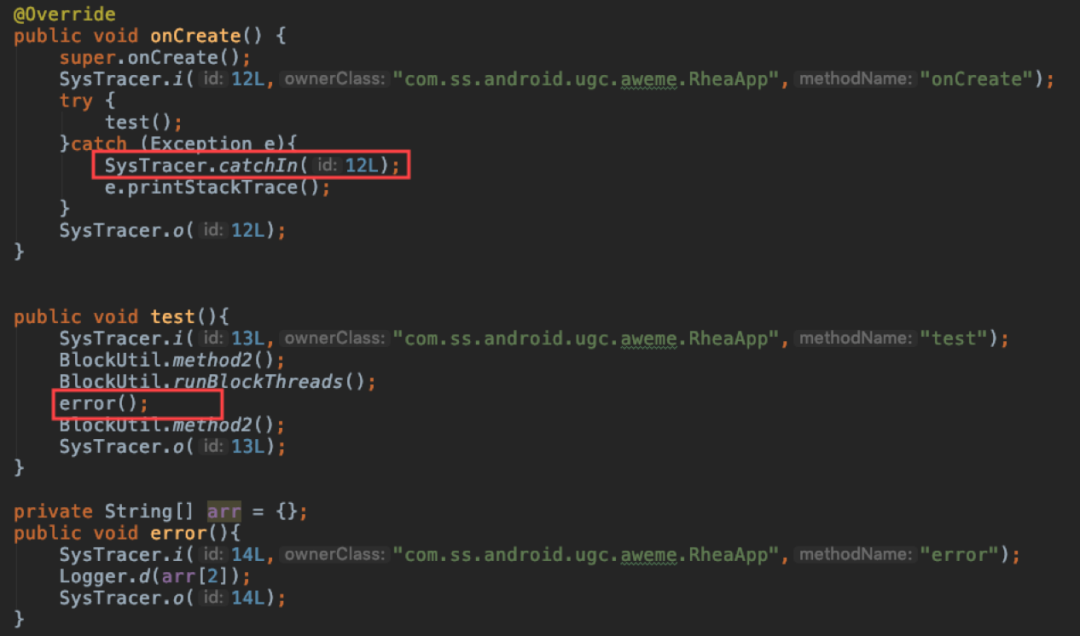
3. 依然存在的问题
性能问题
随着 Rhea 1.0 功能的深入使用,在带来极大便利的同时,功能本身的不足也逐渐暴露出来。在采集数据过程中,其本身的性能损耗会导致在一些实际性能优化过程中会带偏方向。经我们严格测试,其性能损耗有 11.5%左右,如下所示:
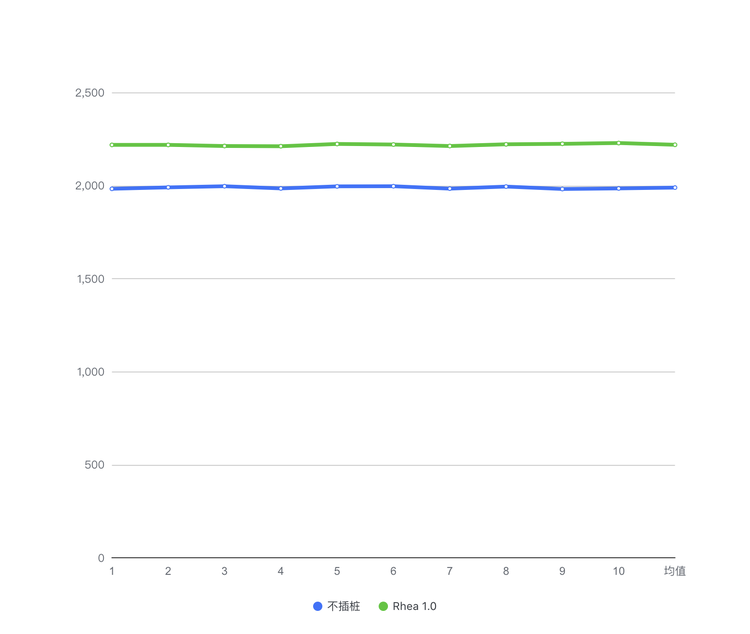
在实际使用过程中发现,在开启 Systrace 之后,对应 Sleep 耗时占比在极端情况下会超过 40%以上。一方面是 APP 锁带来的 Sleep 耗时。例如,在抖音启动路径上 SharedPreference 优化过程中,在开启 Rhea 1.0 的 Systrace 功能后,发现 SP 调用存在明显的锁耗时,当时针对 SP 进行了一番锁的优化后,上线发现效果并不明显,后续经过一系列排查,发现锁的耗时是由于开启 Systrace 功能后导致。另一方面是 IO 带来的 Uninterrupt Sleep 耗时。例如,我们在一次性能优化过程中看到了很多__fdget_pos 操作,对_fdget_pos 操作相对 Uninterruptible Sleep 的占比统计了下,至少占了 Uninterruptible Sleep 总耗时的 60%左右。我们花了比较长时间,额外加了很多 IO 的信息,最终定位原因是在开启 Systrace 后,由于所有线程的 trace 都会写入同一个文件,所有线程会同步竞争内核态的文件 pos 锁导致。工具本身的性能问题误导了我们的排查方向,同时也暴露了在排查这种 IO Wait 问题的时候由于 IO 信息不全导致排查效率不高的问题。
限制层级导致的调用缺失
Systrace 的原理决定了当我们在应用层插入更多函数插桩以定位应用层耗时问题的时候,会导致非常严重的性能问题,所以我们在线下使用该工具会通过限制插桩层级的方式以减少运行时性能损耗。但是层级的限制使得超过既定层级的函数调用数据缺失,在分析调用层级较深的函数耗时的时候,无法定位到准确的耗时点。
使用场景限制
由于 Systrace 在采集数据的过程中,需要依赖 PC,对于一些需要脱离 PC 采集数据的场景,Systrace 就无法满足需求了。比如我们产品运营同学经常会在线下场景实地测试抖音的使用性能,例如地铁、餐馆、咖啡厅等,这些实际使用场景下的性能数据,systrace 就无法支持到了。
低端机无法正常使用
我们在针对低端机进行耗时优化时,发现诸如三星、oppo 等一些早期的低端机型,systrace 也不能支持其数据抓取。
针对以上问题,我们对工具进行了深入的探索和优化。于是,工具的开发进入了第二阶段。
第二阶段:高性能全场景的 Trace 抓取工具
1. 功能升级
为了弥补第一阶段功能短板,进一步提高性能,同时能满足更多使用场景,我们找到了新的解决方案:在 Java 层,通过记录方法首末位置时间戳、所在线程等信息,过滤出大于指定耗时阈值的函数后,将数据异步记录到文件。数据采集结束后,将输出文件转换成指定格式后,便可通过 SDK 提供的 Systrace 工具转化成方便查看的 Html 格式,从而实现和 Systrace 相同的可视化效果。
2. 实现原理
Rhea 2.0 如何采集数据并生成和 Systrace 相同可视化效果的 html 呢?SDK 中 Systrace 工具的--from-file 命令可将原始的.trace 格式数据转成 html 格式,分析.trace 数据内部格式:
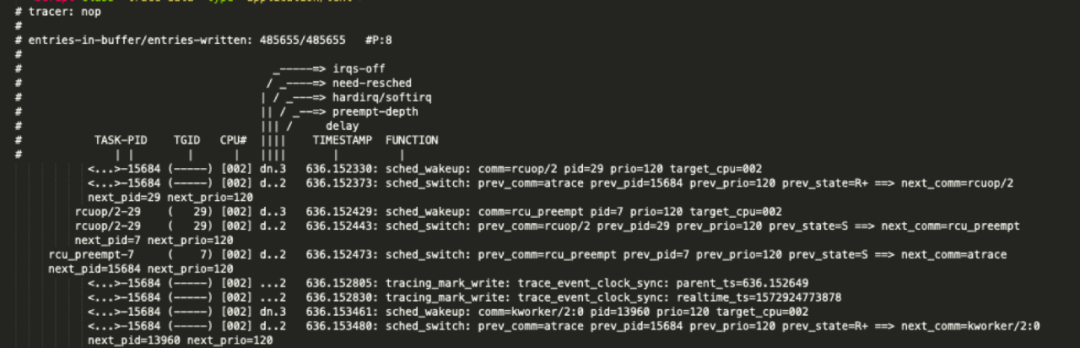
多次尝试后得出结论,可被 SDK Systrace 工具解析的 .trace 文件需满足如下格式:

格式说明:
<ThreadName>:线程名,若为主线程,可指定为包名。 <ThreadID>:线程 ID。 <Time seconds>:方法开始或者结束的时间,单位 s。 <B|E>:标记该条记录为方法开始(B)还是结束(E)。 <ProcessID>:所在进程 ID。 <TAG>:方法标记,字符长度不可超过 127。
由此可知,Mtrace 采集的数据至少需要包含以上内容。
以下则是对应 Trace 格式:
depth,methodID,inTime,outTime,threadName,threadID
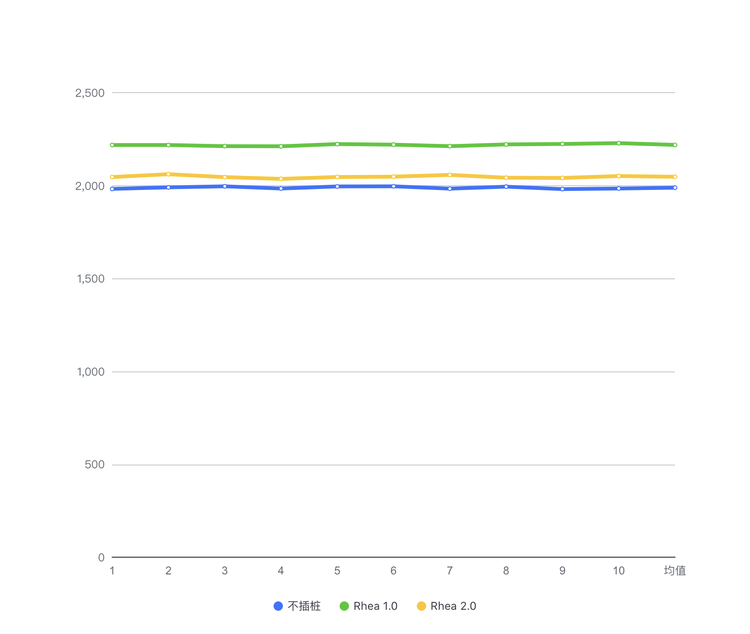
相较于 Rhea 1.0 的 Systrace,Rhea 2.0 的 Method Trace 性能损耗有了显著的降低,性能损耗也由 11.5%下降至 3%,效果如下所示:
3. 最佳实践
功能使用
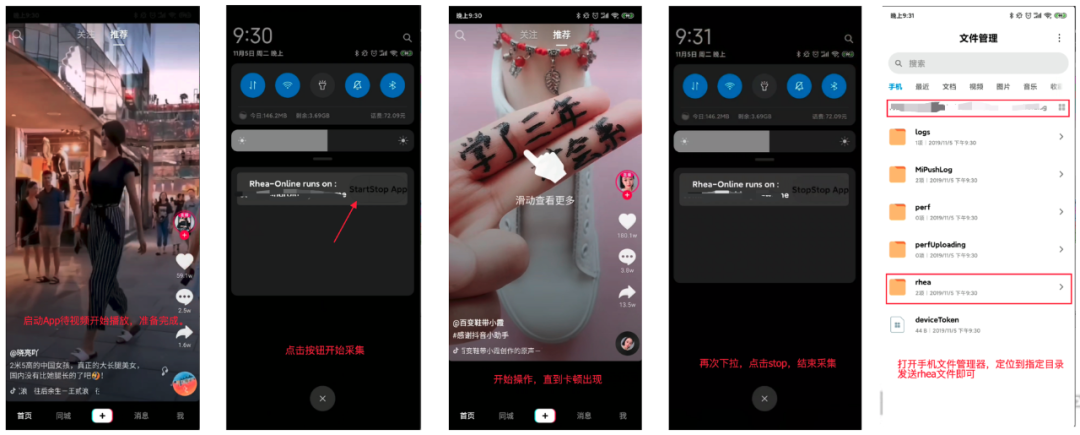
MTrace 相较于 Systrace,提供了更丰富的线下功能,其中包括:解决针对真实用户点对点的卡顿耗时问题反馈功能,解决产品、运营、QA 同学外出走查场景的问题反馈功能。
总之,不管你在哪,性能反馈都一触即达!如图为完整操作流程。
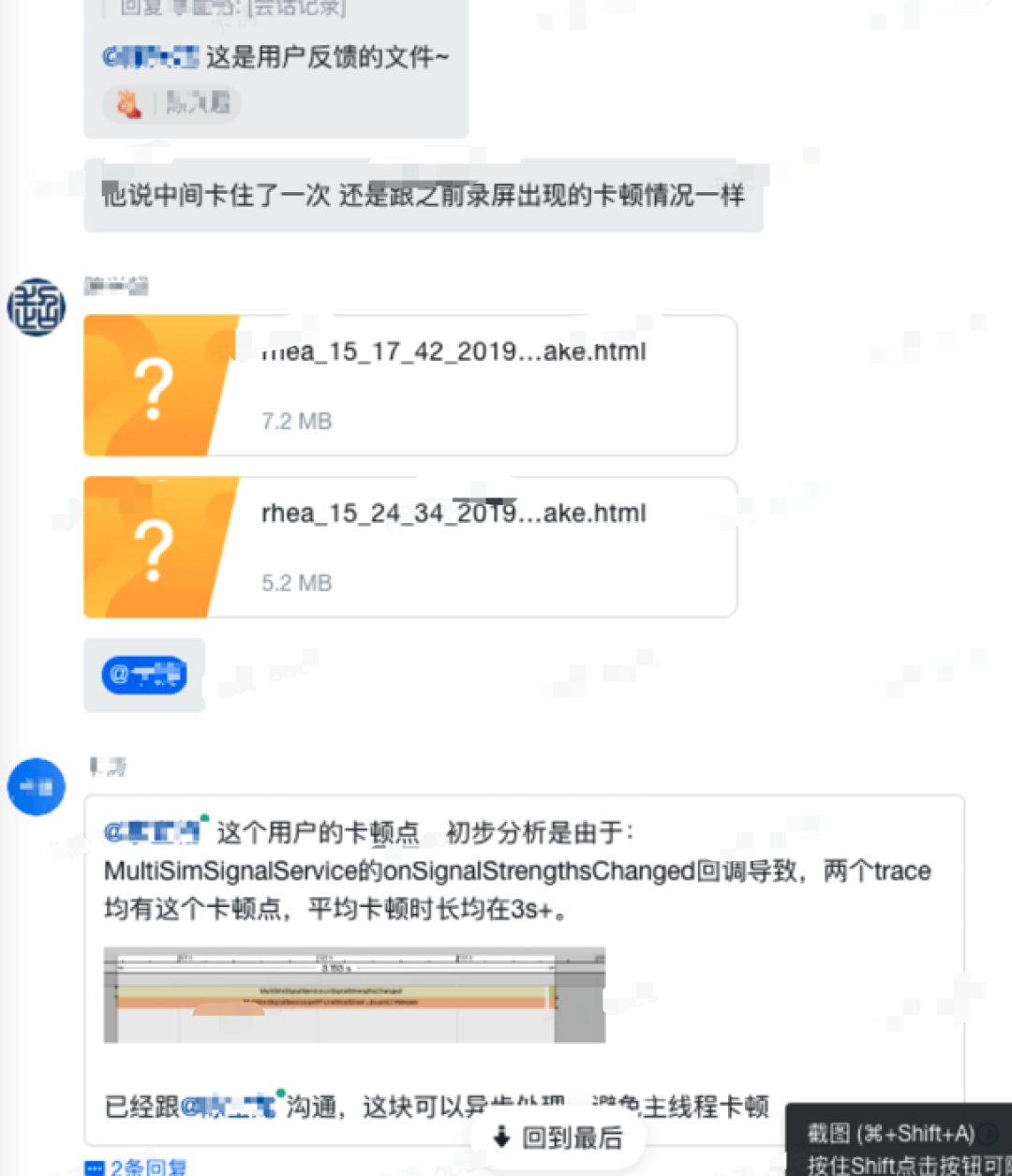
线上案例
一个真实的案例:抖音灰度版本线上用户反馈卡顿,通过 MTrace 功能包实现远程卡顿问题分析排查!以下则是通过用户配合回传的真实卡顿数据,经过解析即可发现耗时调用点:

4. 存在的问题
由于这个阶段采集的只有 Java 方法层的数据,在抖音启动 IO 耗时优化工作中,Method Trace 无法提供哪些函数进行了 IO 操作,以及 IO 操作读取/写入了哪些文件,给优化工作带来了较大的难度。另外在一些复杂场景中,Method Trace 只记录函数执行时长,但是不能准确定位是由于多线程同步等锁或者系统 IO 导致的执行时间变长。
针对上面的问题,我们意识到一套优秀的 Trace 工具还需要融合更多的系统事件,于是工具进入了第三阶段的打磨。
第三阶段:动态一体化 Trace 工具规划
Rhea 1.0 和 2.0 在抖音早期的性能优化工作中成绩显著,但随着优化工作的深入同时也暴漏诸多局限与不便。
一方面,使用常规的 Systrace 工具做性能优化,本身有诸多局限性。一是 Trace 信息少,在默认情况下,只包含系统预置的耗时打点信息,并不足以支持常规的耗时分析需要在 App 侧手动调用 Trace.beginSection 和 Trace.endSection 方法才能获取更多函数耗时信息,为避免影响线上包大小,使用完以后又需手动移除,一上一下事倍而功半。二是 Systrace 本身性能损耗大,特别是应用通过插桩的方式对业务代码进行大量的打点时,极端情况性能损耗会超过 50%。三是 Systrace 完全依赖 PC 端工具抓取,不够灵活。尤其是需要能够稳定复现性能问题的场景,对于一些特定区域或者特定用户群体才能复现的问题无法获直接高效的取到有效信息,依赖研发或者测试走查,甚至用户反馈的部分概率问题即使走查也无法通过 Systrace 获取到对应的信息,从而导致优化效率低。
另一方面,通过简单定制 Trace 的获取函数耗时相较于 Systrace,虽然有显著的性能提升,和更高的灵活性,但数据只包含基本的耗时信息,在部分复杂场景(如持有锁引起的耗时),数据仍存在局限。
如上工具都均已无法完全满足抖音的启动、首刷以及低端机等核心场景的性能优化工作,我们需要重新设计和规划功能更加强大的动态一体化 Trace 工具来辅助分析性能。
该工具要非常灵活,可以不依赖 PC 端的抓取脚本,同时支持线上线下,能够在应用任何想要抓取数据的时候运行,作为一个平台性工具,Rhea 还需要支持动态扩展,支持多种场景的配置和动态开关,可以将任意需要的信息进行采集。 该工具抓取的 Trace 信息要全面,能够采集和追踪包括 ATrace 插桩、等锁信息、I/O 信息以及 Binder 耗时等在内的多种信息。 要支持可视化,统一的格式进行输出和格式化,最终以兼容 Systrace 的结果进行前端展示和使用,尽量不要改变使用者习惯。 性能损耗要低,以免带偏性能优化方向。
因此,我们重新设计了新一代 Trace 分析工具:
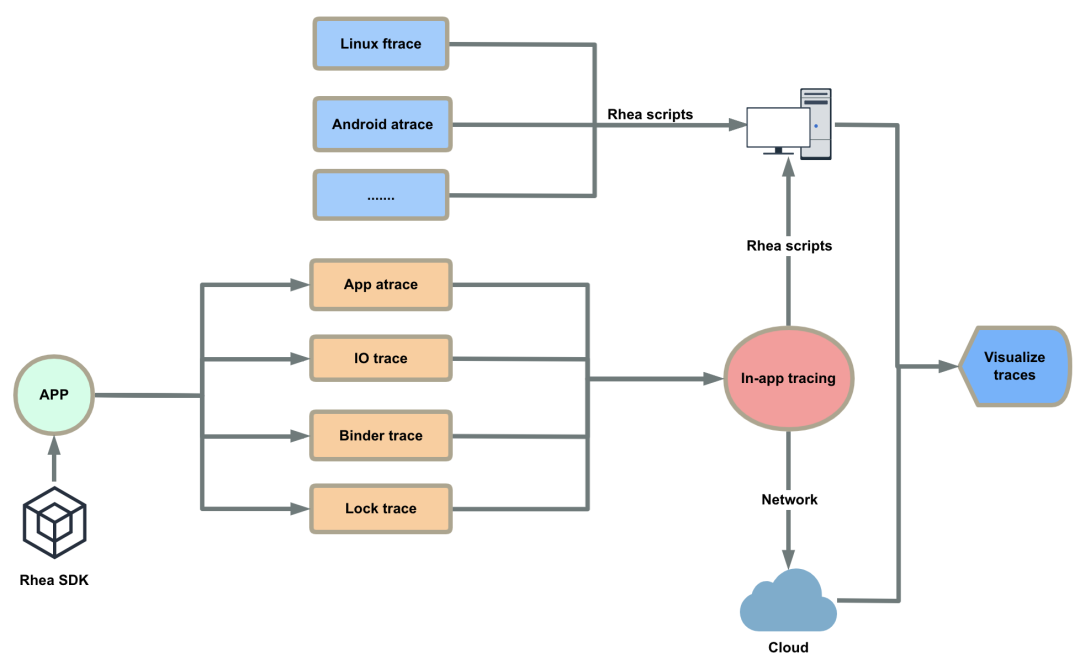
整体上,App 通过集成 Rhea SDK 在打包时不限层级插入函数耗时桩方法,在运行时插入 IO、Binder、Lock 等相关 Trace 信息,支持动态配置,统一 Trace 格式为 atrace,同时支持获取系统级别的 Linux ftrace、Android Framework atrace 和 App 插入的 atrace 信息,能够不依赖 PC 抓取,最终提供可视化显示。具体实现如下:
一、不依赖 PC 抓取 Trace
为了实现不依赖 PC 抓取 Trace,我们有必要先了解下 Android atrace 的实现机制。首先,是 atrace 包括的数据源包括:
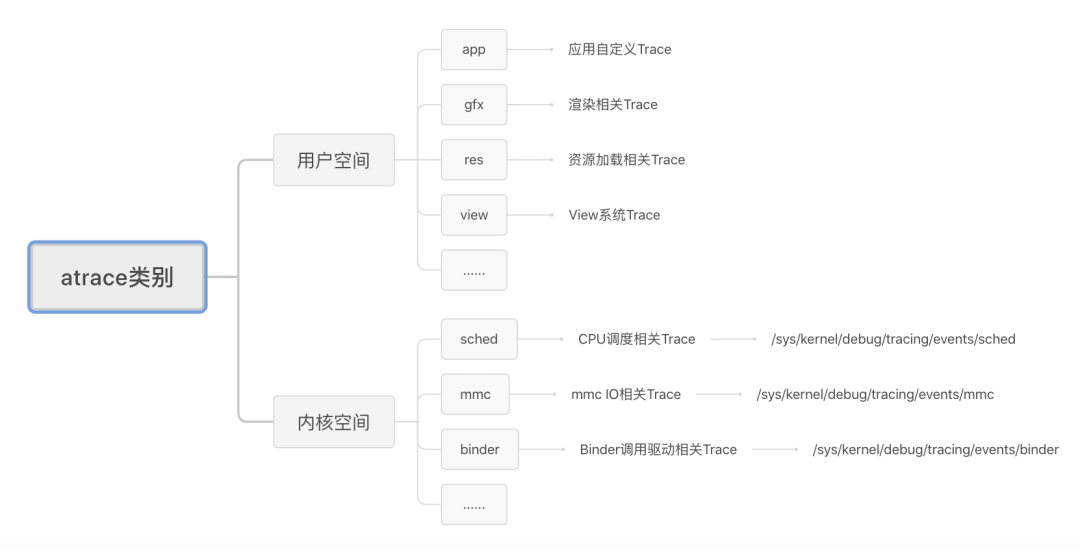
其中,用户空间的数据包括了应用层的自定义 Trace、系统层的 gfx 渲染相关 Trace、系统层打的锁相关的 Trace 信息等,其最终都是通过调用 Android SDK 提供的Trace.beginSection或者 ATRACE_BEGIN 记录到同一个文件点/sys/kernel/debug/tracing/trace_marker 中的。此节点允许用户层写入字符串,ftrace 会记录该写入操作时的时间戳,当用户在上层调用不同函数时,写入不同的调用信息,比如函数进入和退出分别写入,那么 ftrace 就可以记录跟踪函数的运行时间。atrace 在处理用户层的多种 trace 类别时,只是激活不同的 TAG,如选择了 Graphics,则激活 ATRACE_TAG_GRAPHICS,将渲染事件记录到 trace_marker。
而内核空间的数据主要是一些补充的分析数据 freq、sched、binder 等,常用的比如 CPU 调度的相关信息包括:
CPU 频率变化情况 任务执行情况 大小核的调度情况 CPU Boost 调度情况
这些信息是 App 可以通过直接读取/sys/devices/system/cpu 节点下相关信息获得,而另外一部分标识线程状态的信息则只能通过系统或者 adb 才能获取,且这些信息不是统一的一个节点控制,其需要激活各自对应的事件节点,让 ftrace 记录下不同事件的 tracepoint。内核在运行时,根据节点的使能状态,会往 ftrace 缓冲中打点记录事件。例如,激活线程调度状态信息记录,需要激活类似如下相关节点:
events/sched/sched_switch/enable
events/sched/sched_wakeup/enable
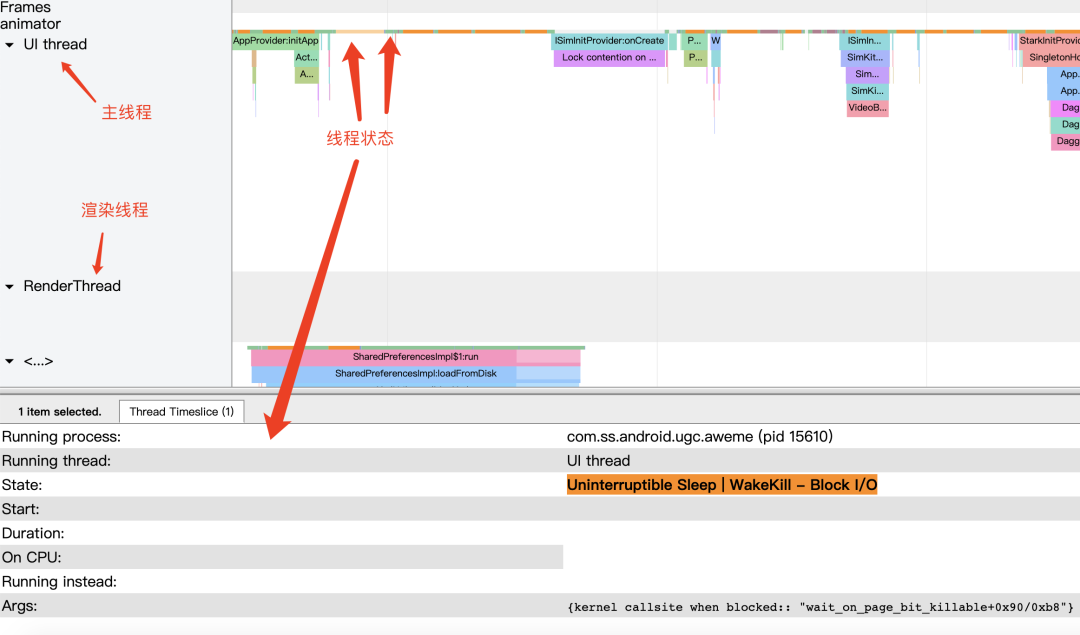
激活后,则可以获取到线程调度状态相关的信息,比如:
Running: 线程在正常执行代码逻辑Runnable: 可执行状态,等待调度,如果长时间调度不到,说明 CPU 繁忙Sleeping: 休眠,一般是在等待事件驱动Uninterruptible Sleep: 不可中断的休眠,需要看 Args 的描述来确定当时的状态Uninterruptible Sleep- Block I/O: IO 阻塞
最终,上述两大类事件记录都汇集到内核态的同一缓冲中,PC 端上 Systrace 工具脚本是通过指定抓取 trace 的类别等参数,然后触发手机端的/system/bin/atrace 开启对应文件节点的信息,接着 atrace 会读取 ftrace 的缓存,生成只包含 ftrace 信息的 atrace_raw 信息,最终通过脚本转换成可视化 HTML 文件。大致流程如下:
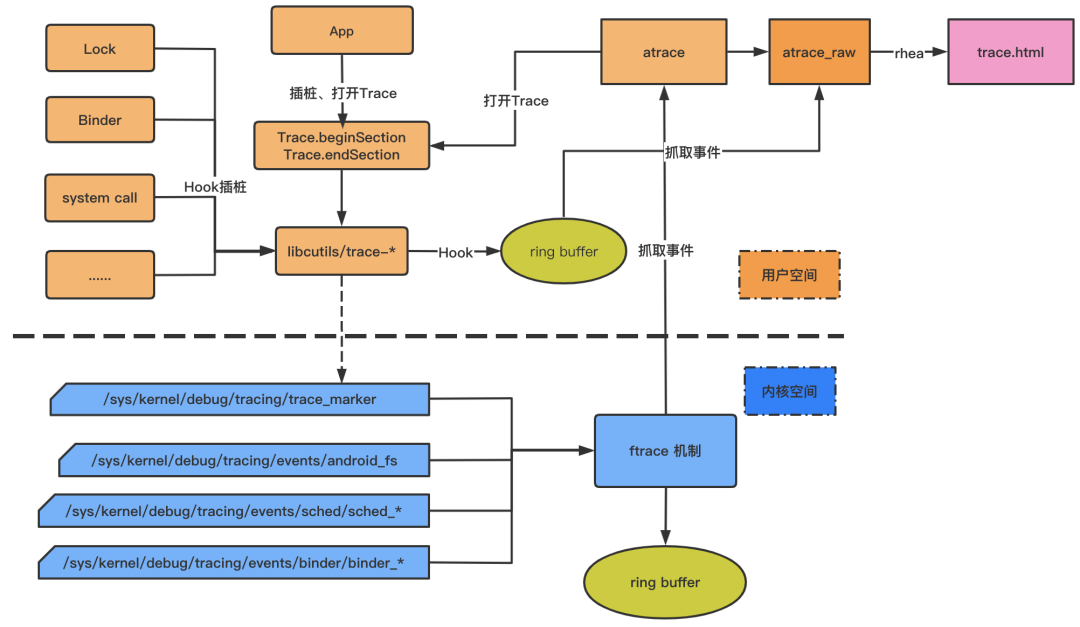
因此,我们基于 Android atrace 的实现原理,我们同步参考了 Facebook 的 profilo 用于在 APP 侧直接获取 atrace 的方案,实现了不依赖 PC 抓取 Trace 的方法。
我们通过 dlopen 获取 libcutils.so 对应句柄,通过对应 symbol 从中找到 atrace_enabled_tags 和 atrace_marker_fd 对应指针,从而设置 atrace_enabled_tags 用以打开 atrace 开关,具体实现如下:
std::string lib_name("libcutils.so");
std::string enabled_tags_sym("atrace_enabled_tags");
std::string marker_fd_sym("atrace_marker_fd");
if (sdk < 18) {
lib_name = "libutils.so";
// android::Tracer::sEnabledTags
enabled_tags_sym = "_ZN7android6Tracer12sEnabledTagsE";
// android::Tracer::sTraceFD
marker_fd_sym = "_ZN7android6Tracer8sTraceFDE";
}
if (sdk < 21) {
handle = dlopen(lib_name.c_str(), RTLD_LOCAL);
} else {
handle = dlopen(nullptr, RTLD_GLOBAL);
}
// safe check the handle
if (handle == nullptr) {
ALOGE("atrace_handle is null");
return false;
}
atrace_enabled_tags_ = reinterpret_cast<std::atomic<uint64_t> *>(
dlsym(handle, enabled_tags_sym.c_str()));
if (atrace_enabled_tags_ == nullptr) {
ALOGE("atrace_enabled_tags not defined");
goto fail;
}
atrace_marker_fd_ = reinterpret_cast<int*>(
dlsym(handle, marker_fd_sym.c_str()));
接下来,我们通过 hook libcutils 动态库中的 write、write_chk 方法通过判定 atrace_marker_fd 来将对应 atrace 信息拦截下来转储到到本地或上传到云端分析。实现如下所示:
ssize_t proxy_write_chk(int fd, const void* buf, size_t count, size_t buf_size) {
BYTEHOOK_STACK_SCOPE();
if (Atrace::Get().IsAtrace(fd, count)) {
Atrace::Get().LogTrace(buf, count);
return count;
}
ATRACE_BEGIN_VALUE("__write_chk:", FileInfo(fd, count).c_str());
size_t ret = BYTEHOOK_CALL_PREV(proxy_write_chk, fd, buf, count, buf_size);
ATRACE_END();
return ret;
}
二、提供更加全面 Trace 信息
1. 锁耗时
Java 层的锁,无论是同步方法还是同步块,最终都会走到虚拟机的 MonitorEnter 和 MonitorExit,在 MonitorEnter 中实现了多种锁状态的切换,包括从无锁到轻锁,轻锁中的偏向和重入,出现竞争并超过自旋的次数之后升级成重锁分配 monitor 对象,其中 art 现在的自旋不是真的自旋,而是用 sched_yield 主动让出 CPU 等待下次调度。
而我们需要首先关注的就是出现锁竞争升级成重锁后的等待耗时信息,这个信息从 Android 6.x 开始会通过 ATrace 的方式输出到 trace_marker 中。
但是想要轻锁的信息还需要做一些额外的工作,因为是否输出轻锁的 ATrace 信息除了 ATRACE_ENABLE 条件之外,还有另外一个 systrace_lock_logging 的开关变量控制,这个变量是虚拟机中一个全局变量的成员,这个成员变量的值正常情况下是由虚拟机启动的时候确定,默认是 false,可以通过启动虚拟机的时候传递-verbose:sys-locks 参数来打开,但是作为普通应用我们没有办法通过这种方式来打开,所以需要用非常规手段在运行时动态打开:
首先确认从 Android7.x 开始,这个结构的大小、成员顺序是否有发生变化; 如果没有变化,则可以自己定义一个相同的结构,因为里面都是原始的 bool 类型变量,不会引入其他依赖; 如果有变化,但是向前兼容,我们想要访问的成员位置没有变化,只是往后追加了成员,也同样可以自己定义相同的结构; 通过 dlsym 找到虚拟机的全局符号 gLogVerbosity;将其类型转换为预先定义的结构体类型; 访问 systrace_lock_logging成员并赋值为 true;轻锁的 ATrace 信息即可正常输出;
std::string lib_name("libart.so");
// art::gLogVerbosity
std::string log_verbosity_sym("_ZN3art13gLogVerbosityE");
void *handle = nullptr;
handle = npth_dlopen_full(lib_name.c_str());
if (handle == nullptr) {
ALOGE("libart handle is null");
return false;
}
log_verbosity_ = reinterpret_cast<LogVerbosity*>(
npth_dlsym(handle, log_verbosity_sym.c_str()));
if (log_verbosity_ == nullptr) {
ALOGE("gLogVerbosity not defined");
npth_dlclose(handle);
return false;
}
npth_dlclose(handle);
2. IO 耗时
在做抖音在启动路径上性能优化时,我们统计了冷启动的耗时,其中占比最长的是进程处于 D 状态(不可中断睡眠态,Uninterruptible Sleep ,通常我们用 PS 查看进程状态显示 D,因此俗称 D 状态)的时间,这部分耗时占比占总启动耗时的 40%左右,进程为什么会被置于 D 状态呢?处于 uninterruptible sleep 状态的进程通常是在等待 IO,比如磁盘 IO,其他外设 IO,正是因为得不到 IO 的响应,进程才进入了 uninterruptible sleep 状态,所以要想使进程从 uninterruptible sleep 状态恢复,就得使进程等待的 IO 恢复。类似如下:

但我们在使用 Systrace 进行优化时仅能得到如上内核态的调用状态,却无法得知具体的 IO 操作是什么。因此,我们专门设计了一套获取 IO 耗时信息的方案,其包括用户空间和内核空间两部分。
一是在用户空间,为了采集到需要的 I/O 耗时信息,我们通过 Hook I/O 操作时标准的关键函数族,包括 open,write,read,fsync,fdatasync 等,插入对应的 trace 埋点用于统计对应的 IO 耗时。以 fsync 为例:
int proxy_fsync(int fd) {
BYTEHOOK_STACK_SCOPE();
ATRACE_BEGIN_VALUE("fsync:", FileInfo(fd).c_str());
int ret = BYTEHOOK_CALL_PREV(proxy_fsync, fd);
ATRACE_END();
return ret;
}

二是在内核空间,除了可由 systrace 或 atrace 直接支持启用的功能之外,ftrace 还提供了其他功能,并且包含一些对调试性能问题至关重要的高级功能(这些功能需要 root 访问权限,通常可能也需要新的内核)。因此,我们基于此添加了显示定制 IO 信息等功能。在线下模式,我们开启了/sys/kernel/debug/tracing/events/android_fs 节点下 ftrace 信息,用于收集 IO 相关的信息,
这时候,我们追本溯源,先找到 Systrace 之母,Google Android 和 Chrome 团队的所有开源项目 Catapult 。正是 Catapult 生成了 Systrace 及其解析器的工具,在 Catapult 中,采用 javascript 实现了一个跨平台的 trace 解析工具,我们在此基础上开发了 Rhea 工具脚本将转换成 systrace 可显示化的格式,用于快速诊断发现 IO 性能瓶颈。
例如,我们线上监控发现我们某个 View 方法调用 setText 方法会导致 ANR,线下通过 Systrace 抓取 Trace 如下:

此时,看到主线程处于 D 状态,却束手无策,而通过我们的 Rhea 工具,获取 Trace 如下:
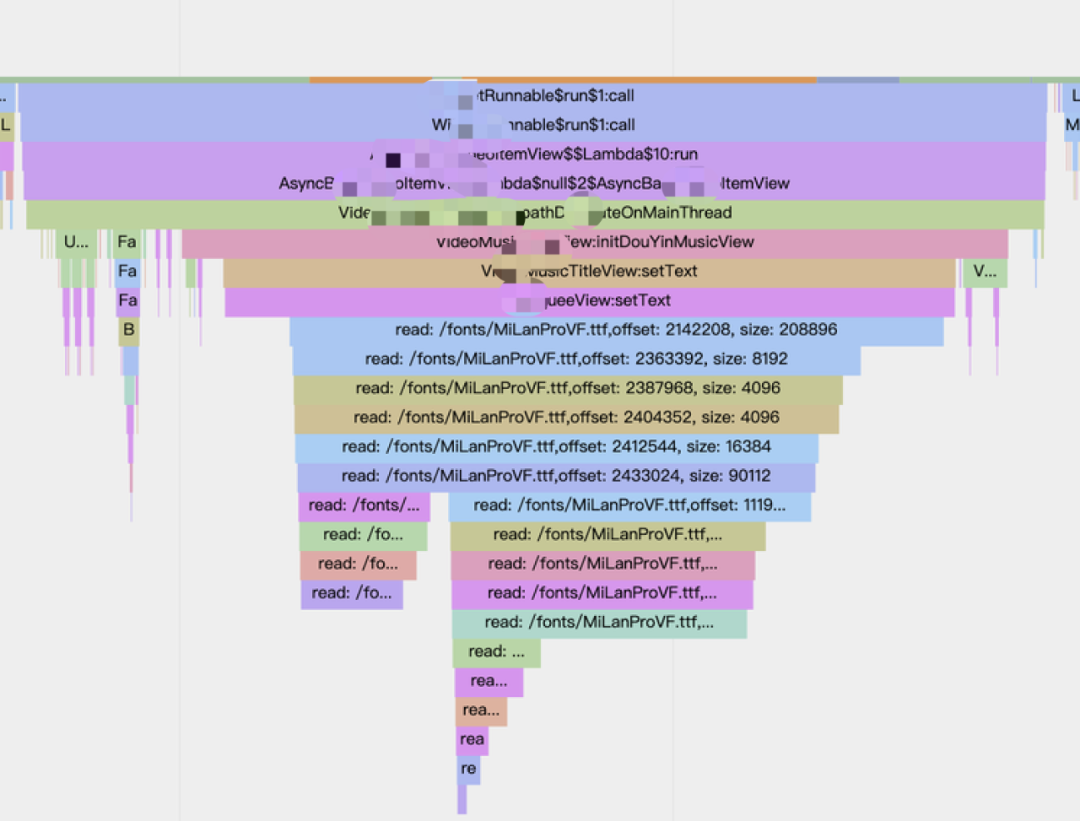
我们很容易就定位到此时是由于读取对应字体带来的 IO 耗时导致的问题。
3. Binder 耗时
在抖音启动性能性能优化过程中,我们通常还会遇到 Sleep 带来的耗时问题,这部分耗时通常占据总耗时的 30%左右,处在这种睡眠状态,进程通常是在等锁或是 Binder 调用耗时导致,通常在线下,我们可以通过开启 tracing/events/binder 节点获取到,但是在线上由于权限问题我们很难获取到这部分信息。因此,我们通过 Hook libbinder.so 对应的 android_os_BinderProxy_transact 方法来统计对应 binder 调用耗时。
if (TraceProvider::Get().isEnableBinder()) {
// static jboolean android_os_BinderProxy_transact(JNIEnv* env, jobject obj,jint code, jobject dataObj, jobject replyObj, jint flags)
bytehook_stub_t stub = bytehook_hook_single(
"libbinder.so",
NULL,
"_ZN7android14IPCThreadState8transactEijRKNS_6ParcelEPS1_j",
reinterpret_cast<void*>(proxy_transact),
NULL,
NULL);
stubs.push_back(stub);
}
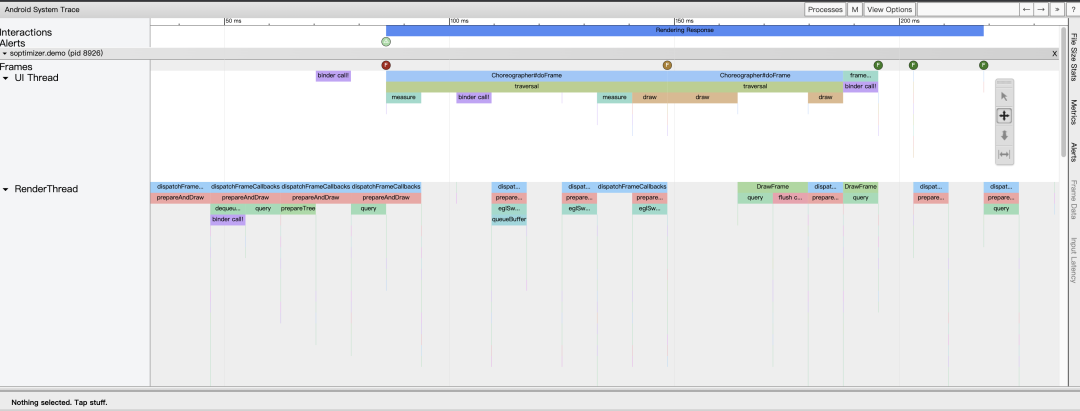
之后,统计对应 binder 耗时,如果耗时超过指定阈值,则将对应堆栈打印出来用于辅助分析 Sleep 耗时问题。
static void log_binder(int64_t start, int64_t end, int64_t flags) {
JNIEnv *env = context.env;
env->CallStaticVoidMethod(context.javaRef, context.logBinder, start, end, flags);
}
status_t proxy_transact(void *pIPCThreadState, int32_t handle, uint32_t code,
const void *data, void *reply, uint32_t flags) {
// todo: add more informations
nsecs_t start = systemTime();
status_t status = BYTEHOOK_CALL_PREV(proxy_transact, pIPCThreadState, handle, code, data, reply,
flags);
nsecs_t end = systemTime();
nsecs_t cost_us = ns2us(end - start);
if (is_main_thread() && cost_us > 10000) {
log_binder(ns2us(start), ns2us(end), flags);
nsecs_t end_ = systemTime();
}
return status;
}
trace 效果如图所示:
4. 支持后续增加更多数据源
当然,仅仅支持上述这些信息不可能完全覆盖我们性能优化过程中未来还可能遇到的其他问题,因此,我们支持了动态配置的功能,后续仅需要在现有框架下,简单添加对应配置项及其功能即可快速方便收集到我们所需要的信息。
enum TraceConfigKey {
kIO = 0,
kBinder,
kThinLock,
kStopTraceUnhook,
kLockStack,
kKeyEnd,
};
5. 不限层级插桩获取函数耗时
限制插桩的层级固然可以提升运行时性能,但是限制层级后面临两个问题:
函数调用数据采集不全面; 难以定位深层的耗时调用;
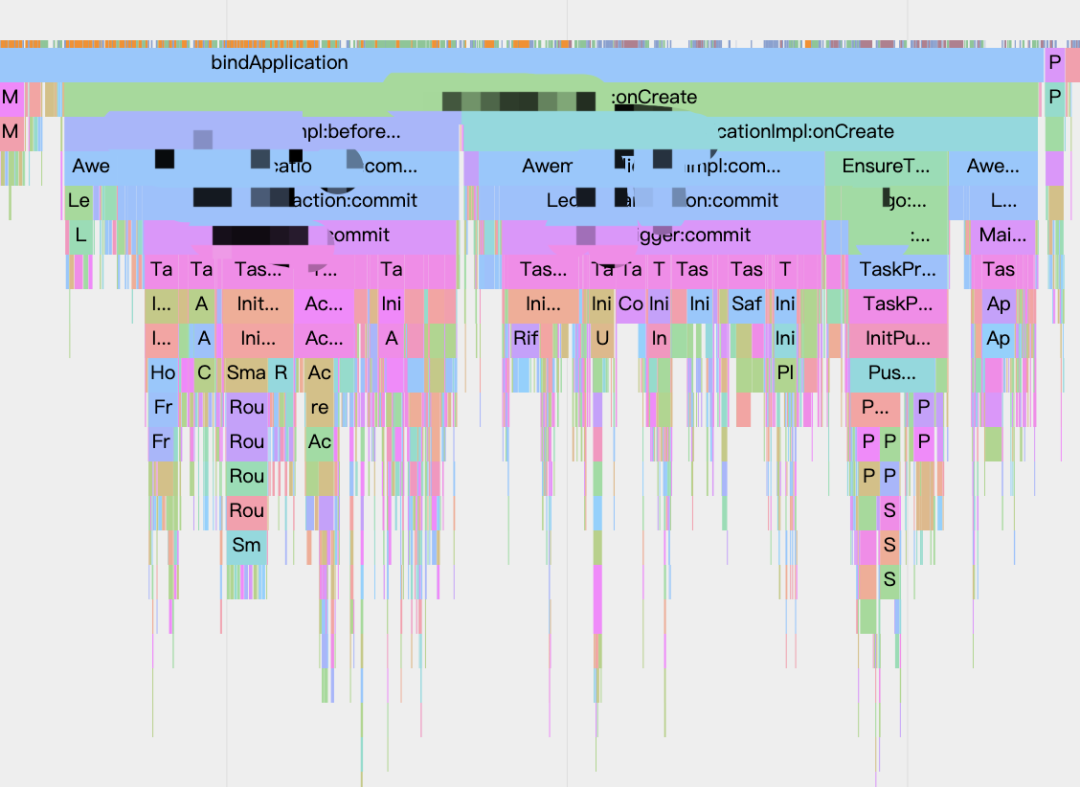
因此在用户态,为了获取 App 更多的 Trace 信息,便于性能优化。我们采用不限制层级的插桩方案。开发了在编译阶段不限制层级插桩的插件,通过静态代码插桩方式,在 App 调用方法的起始和结束位置分别插入 Trace.beginSection 和 Trace.endSection 。效果如下:
三、优化降低性能损耗
1. 插桩性能优化
在插桩阶段, 我们做了如下优化:
支持自定义插桩作用域, 减少 Trace 对于其他无关模块的运行损耗; 针对 Trace 数据出现不闭合的问题, 对 catch 代码块进行全插桩; 针对高频调用函数, 可以选择性的添加到黑名单中, 提升运行时性能; 为支持生产环境使用,我们采用在 proguard 后进行插桩,由于函数内联等优化, 相较于混淆前插桩插桩数量可以减少 2.6%。对于线上模式,直接插入方法 ID,收集 Trace 后需在主机端或服务端对方法 id 重新映射成方法名,但又考虑到线下用户的易用性,在线下模式打包阶段直接插入方法名; 在编译阶段通过分析字节码信息,过滤掉不耗时函数的插桩。
2. 优化 App 侧启停 Trace 性能
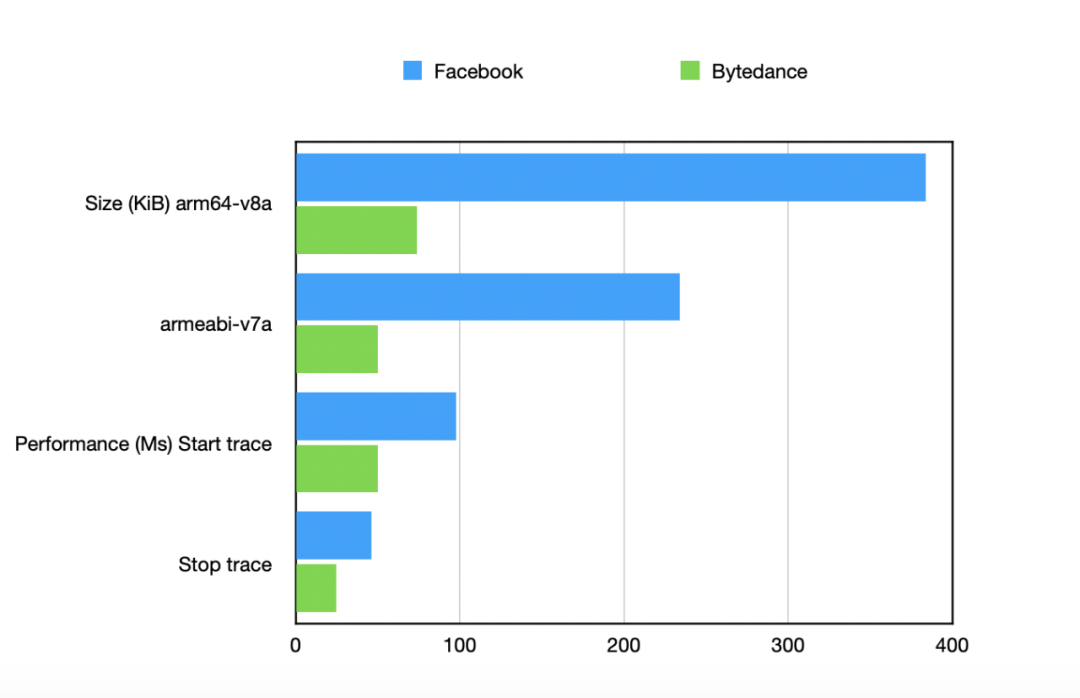
由于 App 侧抓取 Trace 的实现要依赖于 hook,我们参考了 Facebook Profilo 的实现,但其实现存在动态库过大、启停 Trace 耗时问题,因此我们进一步优化了 App 本地获取 atrace 依赖的动态库大小和性能。如下所示:
3. 优化 Trace 写入性能
由于在 App 方法中插入大量 Trace 信息,在开启 atrace 后,所有线程会将所有的 trace 都写入到 trace_marker 文件,会带来 IO 损耗剧增,会掩盖真实性能问题,原因是所有线程都在短时间向 trace_marker 文件进行写入操作,同时竞争内核态 pos 锁,导致获取到的 trace 文件无法真实反映性能问题,如下图所示:
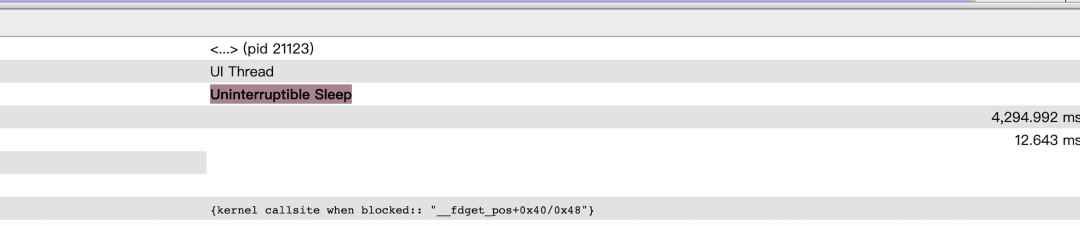
因此,我们将原本直接写入内核态文件的 Trace 在用户态进行拦截,缓存起来,再以异步 IO 的方式转储。既避免了大量用户态与内核态切换带来的上下文损耗,又避免了直接 IO 带来的 IO 损耗。效果如下所示:
四、可视化
由于我们将用户态 atrace 和内核态 ftrace 分别存储在对应空间下的 ringbuffer 中,原生的 systrace 只能分别进行可视化,因此我们开发了统一整合 trace 的脚本工具,将多个 trace 信息将成为单个的 html 文件,当浏览 trace 信息时,可在 Chrome(chrome://tracing 访问)中可视化显示。
未来规划
目前,Rhea 对 Native 的支持还不够全;性能优化还不够极致,特别在用于分析卡顿问题时需要定位几毫秒甚至更细粒度耗时的情况下,性能损耗仍然会有些偏大,在一定程度上会带偏优化方向;目前 Trace 工具更多的还是在线下使用,由于插桩过多影响了包大小,使得我们线上部分只能对小规模的用户群体定向打开,没法全量上线定位线上大规模用户的性能问题。未来我们会重点解决如上问题,将 Trace 工具打造到极致。
小结
目前新一代 Trace 分析工具 Rhea 其主要优势如下:
1、使用灵活,不依赖 PC 抓取脚本,同时支持线上线下多种模式和配置开关;
2、支持采集和追踪包括不限层级 ATrace 函数耗时插桩、等锁信息、I/O 信息以及 Binder 耗时等在内的多种信息;
3、兼容性高,支持 API 16~30 全机型的 trace 抓取;
4、零侵入代码,通过 gradle 完成插件全部配置,无任何代码直接调用。
推荐阅读
• 耗时2年,Android进阶三部曲第三部《Android进阶指北》出版!
• 『BATcoder』做了多年安卓还没编译过源码?一个视频带你玩转!
BATcoder技术群,让一部分人先进大厂
大家好,我是刘望舒,腾讯TVP,著有三本技术畅销书,连续四年蝉联电子工业出版社年度优秀作者,谷歌开发者社区特邀讲师。
前华为技术专家,现大厂技术负责人。
想要加入 BATcoder技术群,公号回复BAT 即可。
为了防止失联,欢迎关注我的小号
微信改了推送机制,真爱请星标本公号👇