
牛顿迭代法的可视化详解
数据派THU
共 2407字,需浏览 5分钟
·
2022-02-25 17:52

来源:DeepHub IMBA 本文约1800字,建议阅读10分钟
本文利用可视化方法,为你直观地解析牛顿迭代法。
Newton-Raphson公式
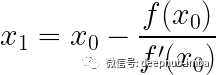

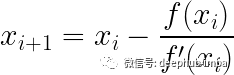
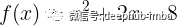
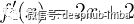
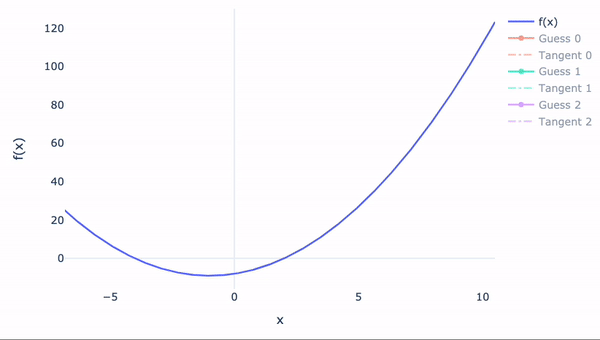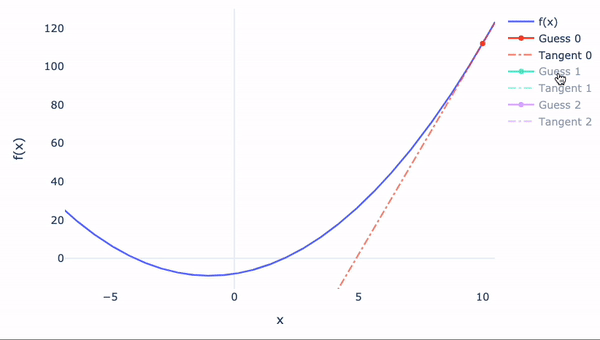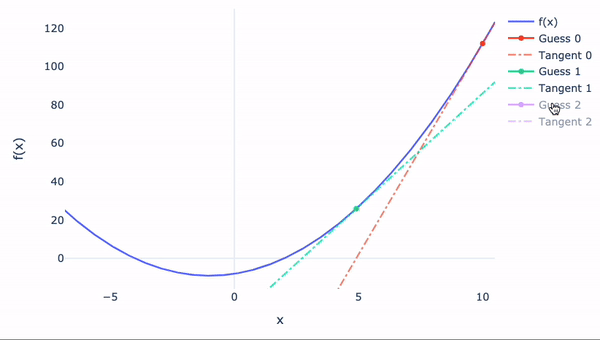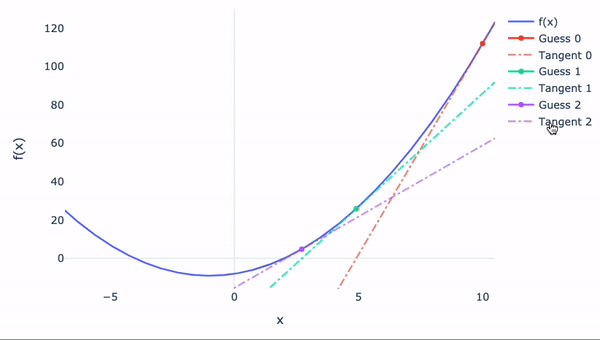
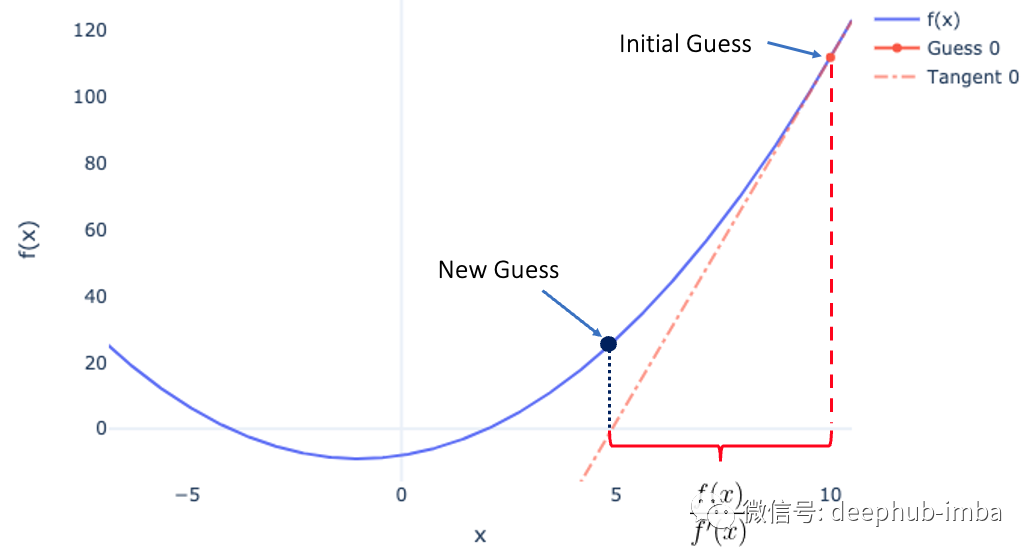
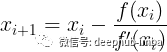
如果函数无法手动微分怎么办?
问题
牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。 牛顿法收敛速度为二阶,对于正定二次函数一步迭代即达最优解。 牛顿法是局部收敛的,当初始点选择不当时,往往导致不收敛; 二阶Hessian矩阵必须可逆,否则算法进行困难。
与梯度下降法的对比
牛顿法使用的是目标函数的二阶导数,在高维情况下这个矩阵非常大,计算和存储都是问题。 在小批量的情况下,牛顿法对于二阶导数的估计噪声太大。 目标函数非凸的时候,牛顿法容易受到鞍点或者最大值点的吸引。
评论