
我是如何赢得吴恩达首届 Data-centric AI 竞赛的?

来源:AI科技评论 本文约3000字,建议阅读10分钟
本文作者与你分享参赛过程及体验。


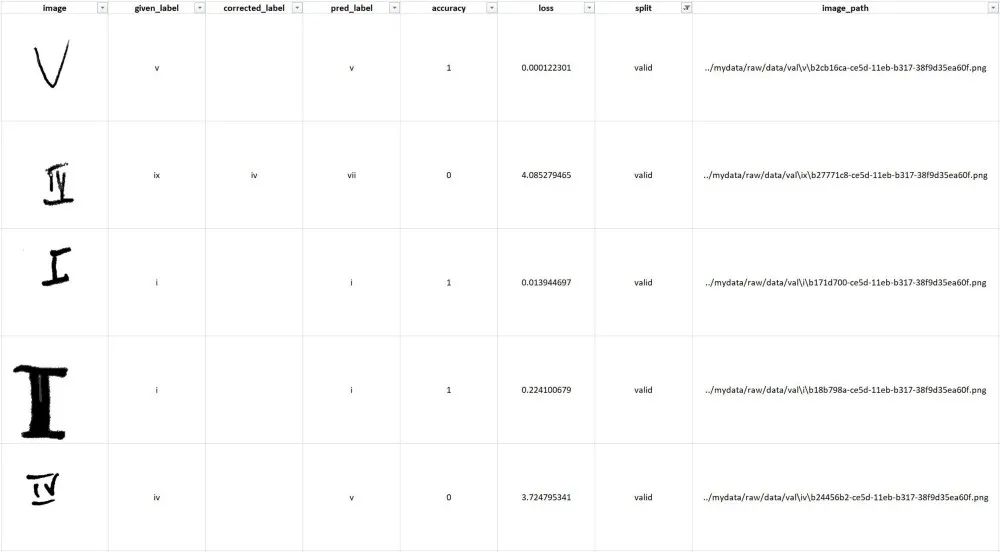
我的“数据增强”技术解决方案
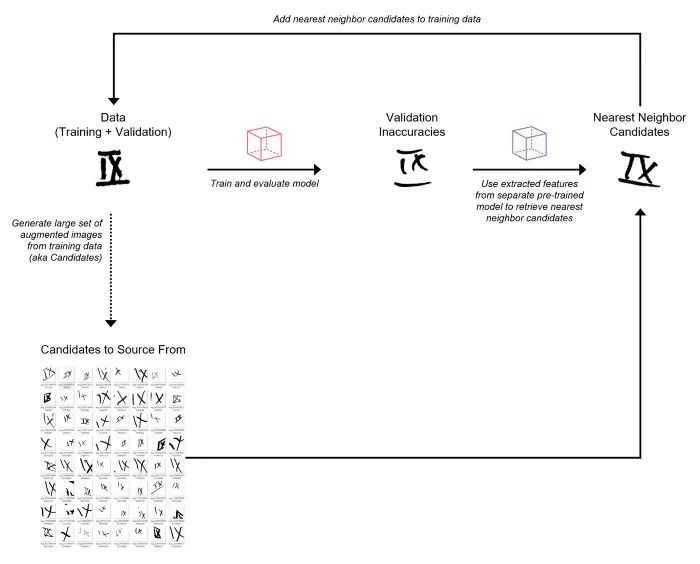
从训练数据中生成一组非常大的随机增强图像(将这些视为“候选”来源)。 训练初始模型并预测验证集。 使用另一个预训练模型从验证图像和增强图像中提取特征(即嵌入)。 对于每个错误分类的验证图像,利用提取的特征从增强图像集中检索最近邻(基于余弦相似度)。将这些最近邻增强图像添加到训练集。我将这个过程称为“数据增强”。 使用添加的增强图像重新训练模型并预测验证集。 重复步骤 4-6,直到达到 10K 图像的限制。
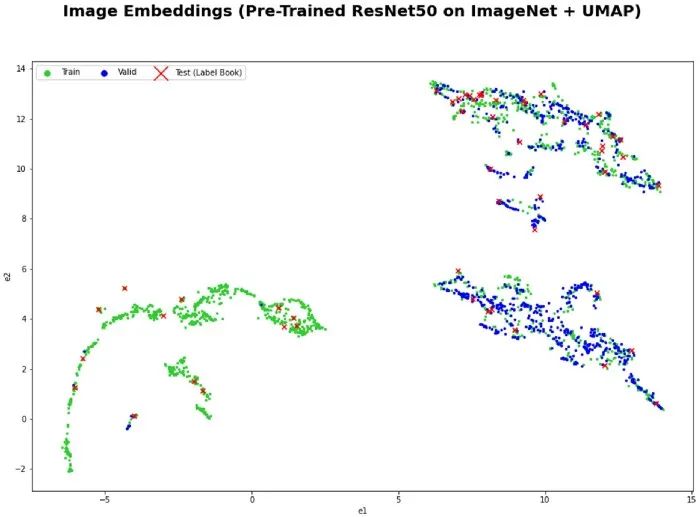
虽然我在这次竞赛中使用了增强图像,但在实践中我们可以使用任何大的图像集作为数据源。 我从训练集中生成了大约 1M 的随机增强图像作为候选来源。 数据评估电子表格用于跟踪不准确(错误分类的图像)并注释数据。另外,我还创建了一个带有PostgreSQL 后端的 Label Studio 实例,但由于不必要的开销,我决定不将其用于本次比赛。 对于预训练模型,我使用了在 ImageNet 上训练的 ResNet50。 我使用 Annoy 包来执行近似最近邻搜索。 每个错误分类的验证图像要检索的最近邻的数量是一个超参数。
我在原先的作品(见 2019 年的一篇博文)里构建了一个电影推荐系统,这个系统通过从关键字标签中提取电影嵌入并使用余弦相似度来查找彼此相似的电影。 我之前使用过预训练的深度学习模型将图像表示为嵌入。 在 Andrej Karpathy 2019 年的演讲中,他描述了如何有效地获取和标记从特斯拉车队收集的大量数据,以解决通常是边缘情况(分布的长尾)的不准确问题。 我想开发一种以数据为中心的增强算法(类似于梯度增强),其中模型预测中的不准确之处在每个步骤中通过自动获取与那些不准确之处相似的数据来迭代解决。这就是我称这种方法为“数据提升”的原因。

为实体(例如图像、文本文档)提取嵌入的预训练模型; 可供选择的大量候选数据集(例如特斯拉车队、网络上大量的文本语料库、合成数据)。
评论