
有趣的对抗生成网络(六)二次元头像生成
关于对抗生成网络的概念,前面已经说了不少了,话不多说,直接开整!
我们的数据集如下(共2.1w+张图片,回复“动漫人脸”即可获取下载链接):
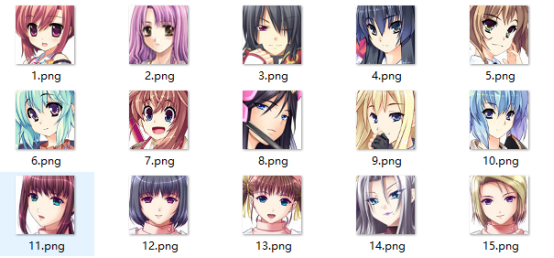
数据加载
DataSets
接着,我们加载这些二次元头像,然后进行数据处理,新建一个dcgan.py文件写入如下代码:
主要的作用是把图片加载进内存,内存比较小的同学可以将它改写成生成器的方式。
import tensorflow.keras as kerasfrom tensorflow.keras import layersimport numpy as npimport osimport cv2from tensorflow.keras.preprocessing import imageimport mathfrom PIL import Imageanime_path = './amine'# 导入数据集x_train = []for i in os.listdir(anime_path):image_path = os.path.join(anime_path, i)img = cv2.imread(image_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)x_train.append(img)# 数据集处理x_train = np.array(x_train)x_train = x_train.reshape(-1, 64, 64, 3)print(x_train.shape)
模型搭建
Model
接着,我们搭建网络模型,我们知道,生成对抗网络是由2个模型相互对抗得到的,所以在这里我们需要搭建2个网络,分别是生成网络和判别网络:
生成网络的结构大体如下,我们可以看到,生成网络的输入是一个长度为100的噪声,接着与一个4*4*1024的特征向量做全连接,然后使用反卷积一步一步进行上采样,最后得到一张64*64*3的图片:
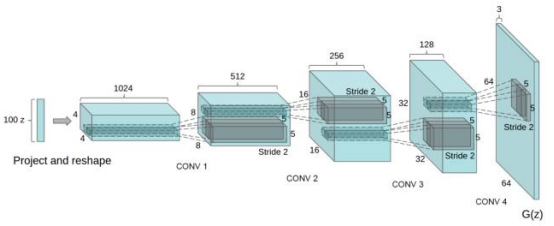
我们对这个网络进行稍微的修改,代码如下
# 定义网络参数latent_dim = 64 # 输入生成网络的噪声height = 64width = 64channels = 3generator_input = keras.Input(shape=(latent_dim,))# 首先,将输入转换为16 x 16 x 256通道的feature mapx = layers.Dense(256 * 16 * 16)(generator_input)x = layers.LeakyReLU()(x)x = layers.Reshape((16, 16, 256))(x)# 然后,添加卷积层x = layers.Conv2D(128, 5, padding='same')(x)x = layers.LeakyReLU()(x)# 上采样至 32 x 32x = layers.Conv2DTranspose(128, 5, strides=2, padding='same')(x)x = layers.LeakyReLU()(x)# 上采样至 64 x 64x = layers.Conv2DTranspose(128, 5, strides=2, padding='same')(x)x = layers.LeakyReLU()(x)# 添加更多的卷积层x = layers.Conv2D(64, 5, padding='same')(x)x = layers.LeakyReLU()(x)# 生成一个 64 x 64 1-channel 的feature mapx = layers.Conv2D(channels, 7, activation='tanh', padding='same')(x)generator = keras.models.Model(generator_input, x)generator.summary()
接着,我们搭建判别网络,判别网络其实和普通的图片分类网络没什么区别,输入是一张64*64*3的图片,经过一系列的卷积和下采样,最终得到分类结果。
判别网络代码如下:
discriminator_input = layers.Input(shape=(height, width, channels))x = layers.Conv2D(256, 3)(discriminator_input)x = layers.LeakyReLU()(x)x = layers.Conv2D(256, 3, strides=2)(x)x = layers.LeakyReLU()(x)x = layers.Conv2D(128, 3, strides=2)(x)x = layers.LeakyReLU()(x)x = layers.Conv2D(128, 3, strides=2)(x)x = layers.LeakyReLU()(x)x = layers.Flatten()(x)# 重要的技巧(添加一个dropout层)x = layers.Dropout(0.3)(x)# 分类层x = layers.Dense(1, activation='sigmoid')(x)discriminator = keras.models.Model(discriminator_input, x)keras.utils.plot_model(discriminator, 'dis.png', show_shapes=True)discriminator.summary()
我们对比以上两个网络,会发现一个有趣的问题,这两个网络其实是相反的,生成网络是给定一组噪声,通过上采样生成一张图片,而判别网络是给定一张图片,通过下采样生成概率。
接着我们编译判别器网络,并设置判别器为不训练状态,然后组装GAN网络:
optimizer = keras.optimizers.Adam(0.0002, 0.5)# 编译判断器网络discriminator_optimizer = keras.optimizers.RMSprop(lr=8e-4, clipvalue=1.0, decay=1e-8)discriminator.compile(optimizer=optimizer, loss='binary_crossentropy')# 设置判别器为不训练(单独交替迭代训练)discriminator.trainable = False# 组装GAN网络gan_input = keras.Input(shape=(latent_dim,))gan_output = discriminator(generator(gan_input))gan = keras.models.Model(gan_input, gan_output)gan_optimizer = keras.optimizers.Adam(lr=4e-4, clipvalue=1.0, decay=1e-8)gan.compile(optimizer=optimizer, loss='binary_crossentropy')
GAN网络的运作流程如下:1.输入一个长度为100的噪声,通过生成网络生成一张图片。2.将生成网络生成的图片送入判别网络中,得到判别结果。3.在这个过程中,需要平衡生成器与判别器,所以将判别网络设置为不训练状态。网络形如:
开始训练
Train
完成了这些,其实我们就可以开始训练函数的编写了,但是为了后面更好地观看生成的图片,我们再写一个组合图片的函数
# 将一个批次的图片合成一张图片def combine_images(generated_images):''':param generated_images: 一个批次的图片:return: 图片'''num = generated_images.shape[0] # 图片的数量(-1, 64, 64, 3)width = int(math.sqrt(num)) # 新创建图片的宽度height = int(math.ceil(float(num) / width))shape = generated_images.shape[1:3]# 生成一张纯黑色图片image = np.zeros((height * shape[0], width * shape[1], 3),dtype=generated_images.dtype)# 循环每张图片,并将图片内的像素点填充到生成的黑色图片中for index, img in enumerate(generated_images):i = int(index / width)j = index % width# 分别填充3个通道image[i * shape[0]:(i+1) * shape[0], j * shape[1]:(j+1) * shape[1], 0] = \img[:, :, 0]image[i * shape[0]:(i+1) * shape[0], j * shape[1]:(j+1) * shape[1], 1] = \img[:, :, 1]image[i * shape[0]:(i+1) * shape[0], j * shape[1]:(j+1) * shape[1], 2] = \img[:, :, 2]return image
接着定义训练参数:
# 归一化x_train = x_train.astype('float32') / 255.iterations = 50000batch_size = 16start = 0save_dir = './save'
然后使用for循环开始训练,在每一个批次的训练中,我们需要生成随机点送入生成器生成假图像,然后将假图像和真图像进行比较,并组合标签,然后单独训练判别器,接着训练GAN网络,这时候判别器的权重被冻结。最后我们每隔一定的周期保存好模型与生成的图片,便于观察生成器的效果
for step in range(iterations):# 在潜在空间中抽样随机点random_latent_vectors = np.random.normal(size=(batch_size, latent_dim))# print(random_latent_vecotors.shape)# 将随机抽样点解码为假图像generated_images = generator.predict(random_latent_vectors)# 将假图像与真实图像进行比较stop = start + batch_sizereal_images = x_train[start: stop]combined_images = np.concatenate([generated_images, real_images])# 组装区别真假图像的标签(真全为1 假全为0)labels = np.concatenate([np.ones((batch_size, 1)),np.zeros((batch_size, 1))])# 重要的技巧,在标签上添加随机噪声labels += 0.05 * np.random.random(labels.shape)# 训练鉴别器(discrimitor)d_loss = discriminator.train_on_batch(combined_images, labels)# 在潜在空间中采样随机点random_latent_vectors = np.random.normal(size=(batch_size, latent_dim))# 汇集标有“所有真实图像”的标签misleading_targets = np.zeros((batch_size, 1))# 训练生成器(generator) (通过gan模型,鉴别器(discrimitor)权值被冻结)a_loss = gan.train_on_batch(random_latent_vectors, misleading_targets)start += batch_sizeif start > len(x_train) - batch_size:start = 0if step % 500 == 0:gan.save('gan.h5')generator.save('generator.h5')print('step: %s, d_loss: %s, a_loss: %s' % (step, d_loss, a_loss))# 保存生成的图像img = combine_images(generated_images) # 组合图片img = image.array_to_img(img * 255., scale=False)img.save(save_dir + '/anime_' + str(step) + '.png')
最后,我们就可以右键运行程序了,GAN训练的时候需要大量的时间,所以要耐心等待!放几张图片感受一下:

测试
Test
在上面的训练中,我们一边训练一边保存了模型的权重,在使用的时候,我们只需要加载保存后的生成网络的权重即可进行测试:
import tensorflow.keras as kimport numpy as npimport matplotlib.pyplot as pltfrom tensorflow.keras.preprocessing import image#加载模型model=k.models.load_model('generator.h5')model.summary()#生成0~1的随机噪声random_latent_vectors = np.random.uniform(0,1,size=(1, 64))print(random_latent_vectors)#*255random_latent_vectors=random_latent_vectors*255.#转换成unit8格式random_latent_vectors.astype('uint8')plt.axis('off')plt.imshow(random_latent_vectors)#放入模型中预测generated_images = model.predict(random_latent_vectors)#数组转图片格式img = image.array_to_img(generated_images[0]* 255., scale=False)plt.imshow(img)
运行结果如下:

扫二维码|关注我们
微信号|深度学习从入门到放弃
长按关注|永不迷路