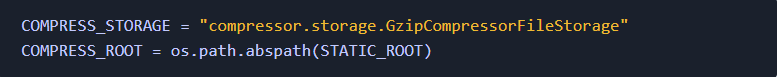英文原文:https://openfolder.sh/django-faster-speed-tutorial
译者:桃夭
↑ 关注 + 星标 ,每天学Python新技能
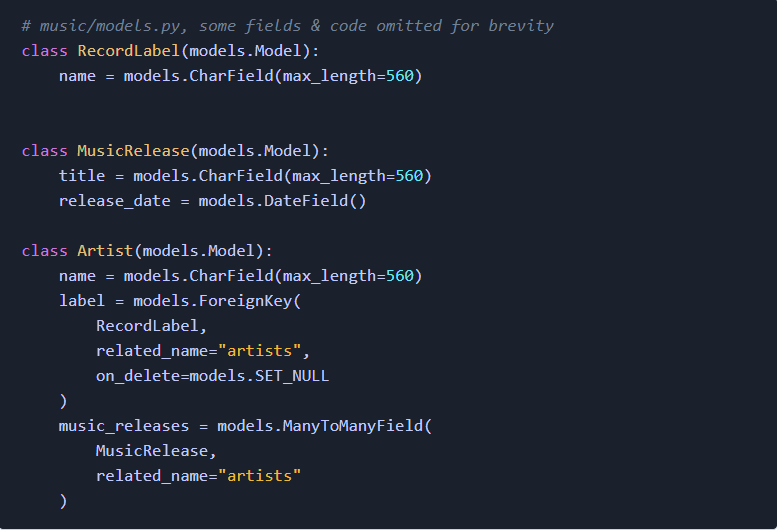
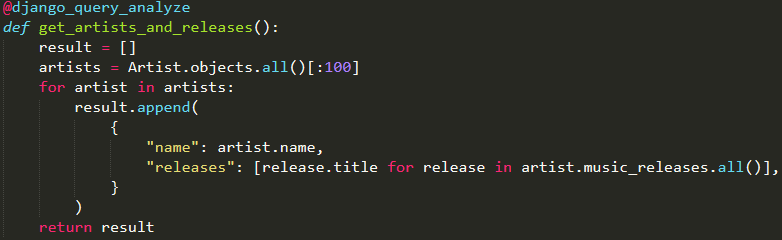
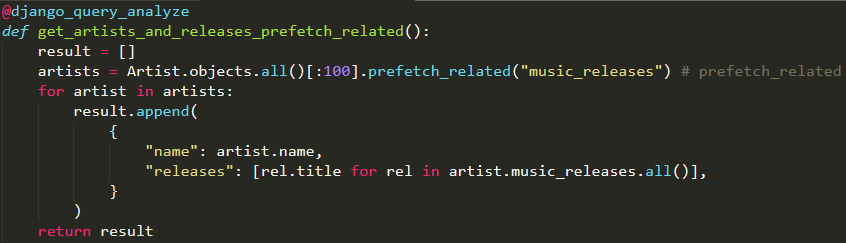
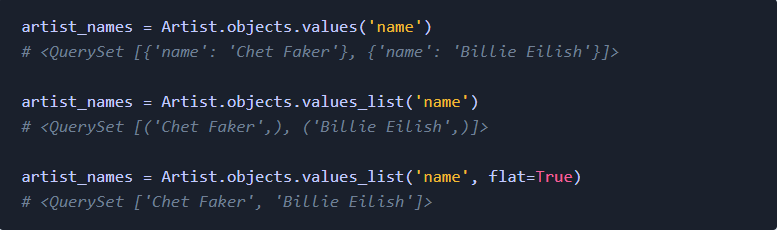
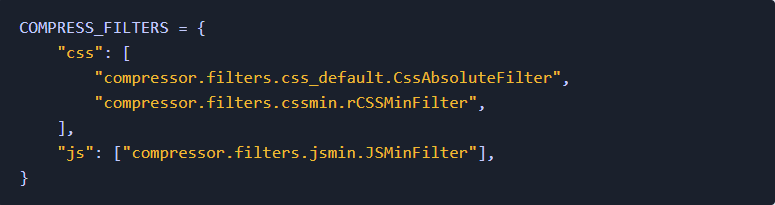
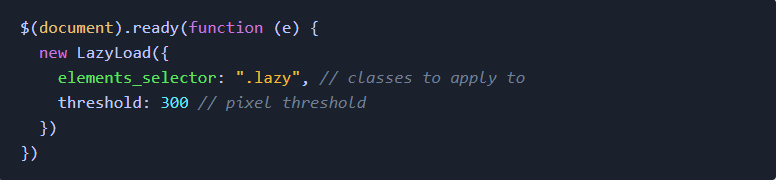
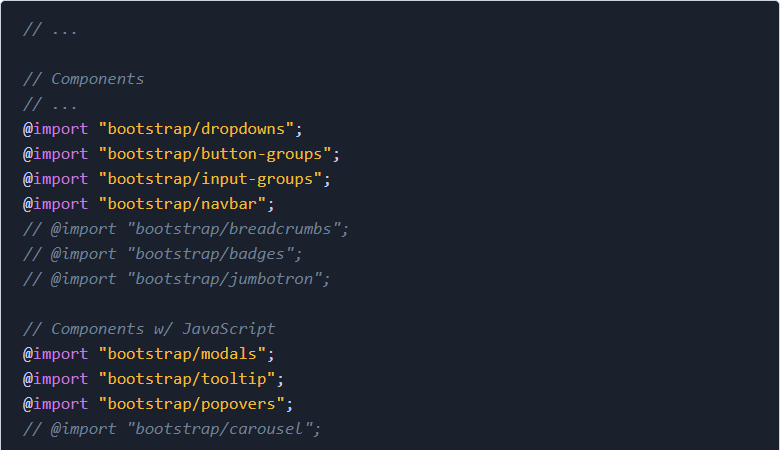
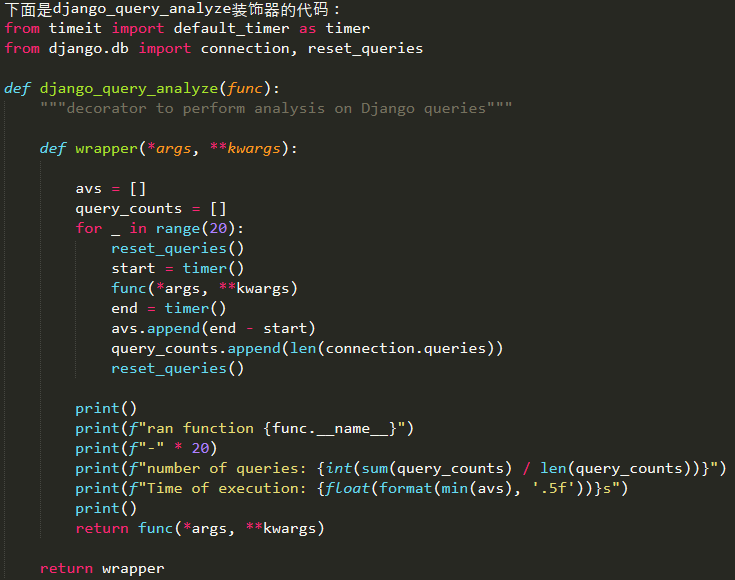
我在开发一些Django应用的过程中,学到了很多速度优化的知识。对于这些优化的过程(无论是前端或后端),都没有详细的文献记录它们。我决定在本文展示我了解的主要内容。
如果您还没有仔细了解您的Web应用的性能,那么您一定会在这里学到有用的内容。在网络中,100毫秒可能产生重大影响,而1秒则相当于一生的时间。无数的研究表明,更快的加载时间与更好的网站转化率、更高的用户保留率及更多来自搜索引擎的自然流量相关。最重要的是,它带来了更好的用户体验。有许多实践技术可以优化您的web应用的性能。这些很容易实现。我们需要寻求最高的回报率。不同的web应用有不同的瓶颈,因此,当这些瓶颈被解决时,它们将获得最大收益。根据您的应用的不同,某些技巧可能比其他技巧更有用。尽管本文是针对Django开发人员的,但此处的速度优化技巧调整后也可以适用于其他方面。在前端方面,它对于使用Heroku托管和无法访问CDN的人特别有用。在后端,我建议尝试使用django-debug-toolbar。它可以帮助您分析请求/响应周期,并查看大部分时间花在了哪里。它很有用,因为它提供了数据库查询执行所需的时间,并在浏览器显示的单独窗口中提供了不错的SQL EXPLAIN工具。Google PageSpeed主要提供与前端相关的建议,但是有些建议也可用于后端(例如服务器响应时间)。PageSpeed与加载时间并不直接相关,但它可以让您清楚了解您的应用中有哪些容易实现的目标。在开发环境中,您可以使用谷歌Chrome浏览器的Lighthouse,该插件提供类似的评估标准,并且支持通过本地URI进行测评工作。GTmetrix是另一个包含很多细节的分析工具。有人可能会告诉您,这里的某些建议是错误的或不完整的。这没关系。本文并不是想要成为大家的圣经或终极指南。把这些当做您可用的技术或技巧,而不是一定要用。不同的需求需要进行不同的设置。从后端开始是一个好主意,因为通常应该由这一层来完成后台大部分的繁重工作。毫无疑问我首先想到的是两个ORM功能:select_related和prefetch_related。它们都专门用于检索相关对象,并且通常通过减少数据库查询数来提高速度。让我们以一个音乐web应用为例,它可能具有以下模型:因此每个艺术家都只与一个唱片公司相关,并且每个唱片公司可以与多位艺术家签约:这是典型的一对多关系。艺术家有很多音乐发行,每个发行的音乐可以属于一个或多个艺术家。现在让我们使用一个很标准的函数来获取我们的艺术家和他们的公司。django_query_analyze是我编写的装饰器,用于计算数据库查询数和运行该函数的时间。它的实现方式可以在附录中找到。get_artists_and_labels是您可以在Django中使用的常规函数。它返回一个字典列表,每个字典包含艺术家的姓名和公司。我正在访问artist.label.name,这样迫使Django对label属性求值;您还可以尝试在Jinja模板中访问这些对象,这会达到同样的目的:我们在0.36秒内获取了500位艺术家及他们的公司,但有趣的是,我们查询了数据库501次。1次是对于所有艺术家进行的,另外500次是对每个艺术家的公司各进行一次。这就是所谓的“ N+1”问题。我们让Django使用select_related命令在同一次查询中检索每个艺术家的公司:让我们看看另一个功能,用来获取每个艺术家的前100首音乐:为获取100个艺术家和他们的100首音乐需要多长时间?让我们在此函数中添加select_related来更改artists变量,如此我们可以减少查询数并提高速度:那是因为select_related只能用于缓存ForeignKey或OneToOneField属性。音乐家和发行的音乐之间的关系是多对多的,这是prefetch_ related可以解决的:select_related 只能缓存“一对多”关系中的那个“一”,或 “一对一”关系中任意的“一”。您可以将prefetch_related用于所有其他的缓存,包括一对多关系及多对多关系里的“多”。下面是我们示例中的改进:关于select_related和prefetch_related需要了解的事情:·如果您不建立数据库连接池,那么由于到数据库的来回次数减少,这会获得收益。·对于非常大的结果集,运行prefetch_related可能会使速度变慢。为数据库创建索引可能会对查询性能产生很大影响。为什么会这样呢,这不应该是本节的第一部分吗?因为相比于在你模型的字段上简单加上db_index=True,创建索引要复杂得多。在经常访问的栏目里创建索引可以提高相关内容的查找速度。创建索引要以额外的写入和存储空间为代价,所以您应该始终衡量收益与成本的比率。通常,在表格上创建索引会减慢插入/更新的速度。如果可能,请使用values()(或是values_list()),这样仅获取你所需的数据库对象属性。继续我们的示例,如果我们只想显示艺术家的名字列表并且不需要完整的ORM对象,通常最好这样编写查询:真正的数据库专家(不是我)Haki Benita回顾了本节的某些部分。您可以阅读Haki的博客(http://hakibenita.com/)。我们要研究的下一层是请求层。这些包括您的Django视图,上下文处理器和中间件。此处的正确决策也会带来更好的性能。在关于select_related的部分中,我们使用该函数返回了500位艺术家及其公司。在许多情况下,返回这么多对象是不现实的或不需要的。Django文档中有关分页的部分清楚地介绍了如何使用Paginator对象。当您不希望向用户返回过多对象时,请使用它,否则这会使您的Web应用运行得很慢。有时某些动作不可避免地会花费很多时间。例如,用户请求将大量对象从数据库导出到XML。如果我们在同一流程中进行所有操作,那么流程如下所示:假设处理此文件需要45秒。您并不会真的让用户一直等待这么长时间获取响应。首先,从用户体验的角度来看这实在太可怕了,其次,如果您的应用在N秒后没有产生适当的HTTP响应,那么某些主机实际上会切断进程。在大多数情况下,明智的做法是从请求-响应循环中移除此功能,把它放到其他进程里:后台任务不在本文的讨论范围之内,但是如果您需要执行上述操作,我相信您听说过Celery之类的库。压缩Django的HTTP/JSON响应可以节省用户的等待时间。具体是多少呢?让我们不进行任何压缩,去检查一下响应主体的字节数:我们的HTTP响应大小约为67KB。我们可以做得更好吗?很多人使用Django内置的GZipMiddleware用于gzip的压缩,但今天更新、更有效的brotli在不同的浏览器上都可以被支持(当然除了IE11)。重要提示:如Django文档的GZipMiddleware部分所述,压缩过程可能会使您的网站产生安全漏洞。让我们安装优秀的django-compression-middleware库。它通过检查请求的Accept-Encoding标头,从而选择浏览器支持的最快的压缩方式:现在主体大小为7.24KB,缩小了89%。您当然可以说这种操作应该委托给专门的服务器(例如Ngnix或Apache)。我认为这都是为了简单性与资源之间的平衡。缓存是存储特定计算结果以适于更快检索的过程。Django具有出色的缓存框架,可以让您在各种层级上使用,并能使用不同的存储后端。在由数据驱动的应用中,缓存可能会很棘手:您应该不会想要缓存需要显示最新实时信息的页面。因此,最大的挑战不是设置缓存,而是确定要缓存的内容,储存多长时间以及了解什么时候或如何使缓存无效。在使用缓存之前,请确保已在数据库层面/前端进行了适当的优化。如果设计和查询得当,从数据库大量提取相关信息会相当快。减少静态文件(资产)的大小可以大大加快您Web应用的速度。即使您在后端一切都做得很好,但传递图像、CSS和JavaScript文件效率低也会降低应用的速度。在编译,最小化,压缩和清除之间,很容易弄糊涂。我们不要迷失方向。对于在哪里以及如何提供静态文件,您有多种选择。Django的文档(https://docs.djangoproject.com/en/2.2/howto/static-files/deployment/#deploying-static-files)提到了运行Ngnix和Apache的专用服务器、Cloud/CDN或类似的服务器途径。我有很多混合的想法:从CDN提供图像,将大型文件上传到S3,但是所有其他静态资产(CSS,JavaScript等)的服务和处理都是使用WhiteNoise(后面会详述)完成的。为了确保我们的想法在同一页上,下面是我想表达的内容:·编译:如果您在样式表中使用SCSS,则必须先将其编译为CSS,因为浏览器不懂SCSS。·最小化:减少空白字符,并从CSS和JS文件中删除可能会对文件大小有影响的注释。有时这个过程涉及麻烦的事情:如将长变量名重命名为短变量名等。·压缩/合并:对于CSS和JS,将多个文件合并为一个。对于图像,通常意味着从图像中删除一些数据使文件变得更小。·清除:删除不需要/不用的代码。例如在CSS中删除未使用的选择器。使用WhiteNoise从Django提供静态文件WhiteNoise允许您的Python Web应用自己提供静态资产。就像它的作者说的(http://whitenoise.evans.io/en/stable/index.html#what-s-the-point-in-whitenoise-when-i-can-do-the-same-thing-in-a-few-lines-of-apache-nginx-config),当其他选项(例如Nginx/Apache)不可用时,我们就可以这样做。在启动WhiteNoise之前,请确保已在settings.py中定义您的STATIC_ROOT:为了启动WhiteNoise,在settings.py中,添加SecurityMiddleware下面的WhiteNoise中间件:在生产过程中,为了WhiteNoise能正常工作,您必须运行manage.py collectstatic。尽管此步骤不是必需的,但强烈建议添加缓存和进行压缩:现在,每当它在模板中遇到{% static %}标签时,WhiteNoise都会为您压缩和缓存文件。它还负责使缓存失效。更重要的一步:为了确保我们在开发和生产环境之间获得相同的体验,我们需要添加runserver_nostatic:不管DEBUG显示True或not,它都可以被添加进来,因为你在生产中通常不会通过runserver运行Django。这会不会导致缓存无效?不会。因为当你运行collectstatic时,WhiteNoise会创建版本化文件:因此,当您再次部署应用时,您的静态文件将被覆盖并具有不同的名称,因此以前的缓存就不重要了。WhiteNoise已经压缩了静态文件,因此django-compressor变成了可选项。但后者提供了额外的增强功能:合并文件。为了让压缩器与WhiteNoise一起工作,我们需要采取一些额外的步骤。假设用户加载具有三个.css文件链接的HTML文档:您的浏览器将对这些位置发出三个不同的请求。在许多情况下,在部署时对这些不同的文件进行合并会更加有效,并且django-compressor可以使用它的{% compress css %}模板标签来进行实现:让我们回顾使django-compressor和WhiteNoise良好合作的步骤。先安装:由于这两个库拦截请求-响应周期的方式,它们与它们的默认配置不兼容。我们可以通过修改某些设置来解决问题。我更喜欢在.env文件中使用环境变量并设置Django settings.py,但是如果使用settings/dev.py和settings/prod.py,您就会知道如何转换这些值:main_project/settings.py:COMPRESS_OFFLINE在生产中为True,在开发中则显示为False。而COMPRESS_ENABLED在二者中都是True。使用离线压缩时,您必须在每个部分上运行manage.py compress。在Heroku上,希望您禁止该平台自动运行collectstatic(默认自动运行),还要选择在post_compile钩函数中执行此操作,而Heroku将在您这样部署时运行。如果没有这个文件的话,请在项目的根目录创建一个名为bin的文件夹,并在其内部创建一个叫做post_compile的文件,包含以下内容:Compressor的另一个好处是它可以压缩SCSS/SASS文件:讨论加载时间和带宽占用时要使用的另一重要方法是最小化:通过消除空白字符和删除注释来缩小代码文件的过程。这里有几种方法,但是如果您使用的是django-compressor特定方法,那也可以自由实现。您只需要在settings.py文件中添加以下内容(或压缩器支持的其他筛选器):导致性能降低的另一个原因是加载外部脚本。其要点是,浏览器在加载和解析页面其余部分之前,会尝试获取并执行标签中的JavaScript文件:我们可以使用async和defer关键字来缓解这种情况:async和defer都允许脚本在异步获取中不中断。它们之间的主要区别之一是,当该脚本允许执行时:使用async时,一旦脚本已被下载,直到脚本执行完毕,才会开始解析;使用defer时,只有HTML被解析后,脚本才会执行。我建议参考 Flavio Copes关于aysnc和defer的文章(https://flaviocopes.com/javascript-async-defer/)。其一般结论是:“使用脚本时,加快页面加载速度的最佳方法是将脚本放在head中,并为script标签添加defer属性。”延迟加载图像意味着我们仅在其进入客户端(用户端)界面之后(或早一点点)才请求它们。它为您节省了时间和带宽(在cellular networks上是$)。较好的、无依赖性的JavaScript库(如LazyLoad),确实没有任何理由不延迟加载图像。毕竟从版本76开始,Google Chrome就支持lazy属性。使用前面提到的LazyLoad非常简单,并且该库可以自定义。在我自己的应用中,我希望只应用在具有lazy类的图像,并在进入界面之前开始加载300像素的图像:我们用src替换src属性,并将lazy添加到类属性中:如果该图像在界面内为300像素,那么客户端将请求此图像。如果某些页面上有很多图像,那么使用延迟加载将大大改善你的加载时间。要考虑的另一件事是图像优化。除了压缩以外,这里还有另外两种技术可以考虑。首先,文件格式优化。新的格式(像WebP)可能比相同质量的JPEG图像平均要小25-30%。从2020.02开始,WebP具有不错的浏览器支持,但它不完整,因此如果要使用它,那您必须提供标准格式的备用方案。其次,将不同尺寸的图像提供给不同尺寸的屏幕:如果某些移动设备的最大视野宽度为650像素,那么为什么还要向它们提供13英寸2560像素显示屏需要用的1050像素图片呢?您也可以在此处选择适合您应用的图片粒度和自定义等级。对于更简单的情况,可以使用srcset属性来控制图片大小并依次完成操作,但是如果您用JPEG为WebP提供备份,则可以在多个源和源集中使用元素。如果您和我一样对上述内容感到困惑,那么这个指南(https://dev.to/jsco/a-comprehensive-guide-to-responsive-images-picture-srcset-source-etc-4adj)有助于解释术语和用例。如果您正在使用Bootstrap之类的CSS框架,那么不要盲目地加组件进来。实际上,我一开始就注释掉所有非必需组件,仅仅在需要时逐渐添加这些组件。下面是我的bootstrap.scss,其中所有部分都已加载:我不用badges或jumbotron之类的东西,因此我可以放心地将其注释掉。更激进、复杂的方法是使用PurgeCSS之类的库,检测文件中不用的CSS内容并将其删除。PurgeCSS是一个NPM软件包,因此,如果要在Heroku上托管Django,那你需要在Python上并行安装Node.js buildpack。我希望您至少已经找到一个方面可以使Django应用提速。如果您有任何疑问,建议或反馈,请随时在Twitter(https://twitter.com/SHxKM)上给我留言。