
汽车之家基于 Flink 的数据传输平台的设计与实践
背景与需求
技术选型与设计 —— Why Flink?
数据传输系统的设计架构
基于 Flink 的 Binlog 接入 SDK
平台使用
总结与展望
一、背景与需求
汽车之家(下称之家)作为一家数据智能驱动的公司,天然存在着对数据的各种复杂需求,之家的数据系统负责支撑这些业务需求的开展。数据传输系统,作为其中一环,承担了各类数据导入分发的需求,支持用户订阅数据变更。随着支撑的业务扩增与需求的增加。原来的接入系统暴露出了一定的问题和不足:
缺乏有效的任务与信息管理机制,依赖人工进行任务的管理和运维,信息的统计
接入程序资源使用浪费,缺乏弹性
针对 DDL 变更问题,不能很好的处理,必要时需要人工介入
传输系统依赖的组件比较多,比如 Zookeeper,Redis 等
代码的技术债累积,代码维护成本变高
针对上述问题,我们决定开发一套新的数据传输和分发系统,一举解决上述问题。
二、技术选型与设计 —— Why Flink?
在开展新系统的开发工作之前,我们分析的可选的方案思路大体分三种:
完全自研(类似于 otter)
复用市面上的开源组件(Maxwell/Canal/Debezium)进行二次开发和整合
基于 Flink 进行组件的开发
我们规约出以下主要设计使用目标:
架构设计上要运维管理是友好的,提供高可用以及故障恢复策略,支持异地多活
架构设计上要提供强数据准确性,至少承诺 at-least-once 语义
架构设计上要对扩缩容是友好的,可以按需分配资源
功能设计上要全面的监控覆盖和完善的报警机制,支持元数据信息管理
功能设计上要对实时计算是友好的(1)
功能设计上要能完全防御 DDL 变更带来的问题
此外,在性能指标上,接入系统的延时和吞吐至少要满足所有业务常规状态下的需求。
(1) 指与实时计算平台整合的能力
方案设计与对比
依照设计思路和目标,我们整理了方案主要功能的对比表格:
| 项目 | 完全自研 | 开源定制 | 基于Flink开发自研 |
(1)Flink 自带高可用和故障恢复,实时计算平台在此基础上提供更强的高可用服务
(2)良好的编码 + flink 机制即可实现 Exactly-Once
(3)实时计算平台自带任务部署管理能力
(4)实时计算平台自带完备的监控和管理
Flink DataStream 的编程模型和 API 在应对数据传输场景上,非常的自然与直接 Flink 在框架层面提供了一致性保证和 HA/稳定性/流量控制措施,让我们可以不必去处理这些开发上比较困难和复杂的问题,背靠框架即可较为轻松地完成相关工作 Flink 天然具备横向纵向扩容的能力,按需使用计算资源即可 完全复用了之家 Flink 实时计算平台已有的组件和能力——完备的监控报警/任务生命周期管理/异地多活/自助运维等功能
三、数据传输系统的设计架构
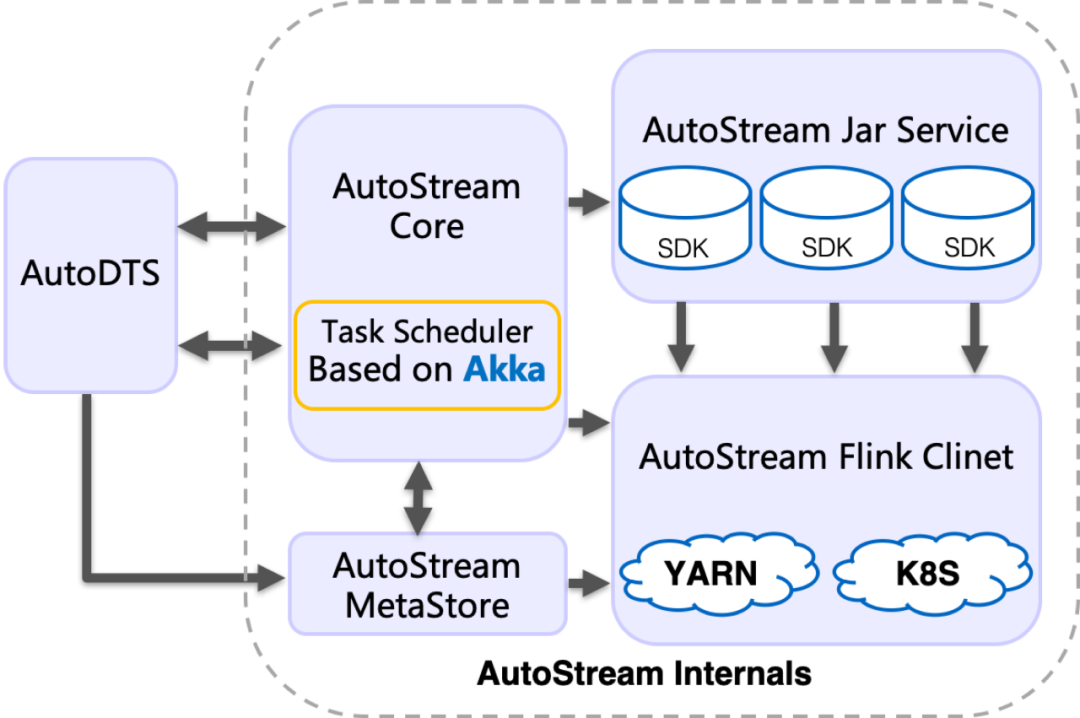
从逻辑层面来看,之家的实时数据传输平台分为 3 部分:
数据传输程序 接入任务信息管理模块 任务执行 Runtime 模块
数据传输程序是由固定的 Flink Jar 和 Flink SQL Codegen Service 生成的SQL Task 组成 管理模块作为一个微服务,负责与 Flink 平台组件通信,完成必要的任务管理和信息管理 执行层直接依赖 Flink 平台和 Flink 平台的集群
组件架构与交互逻辑
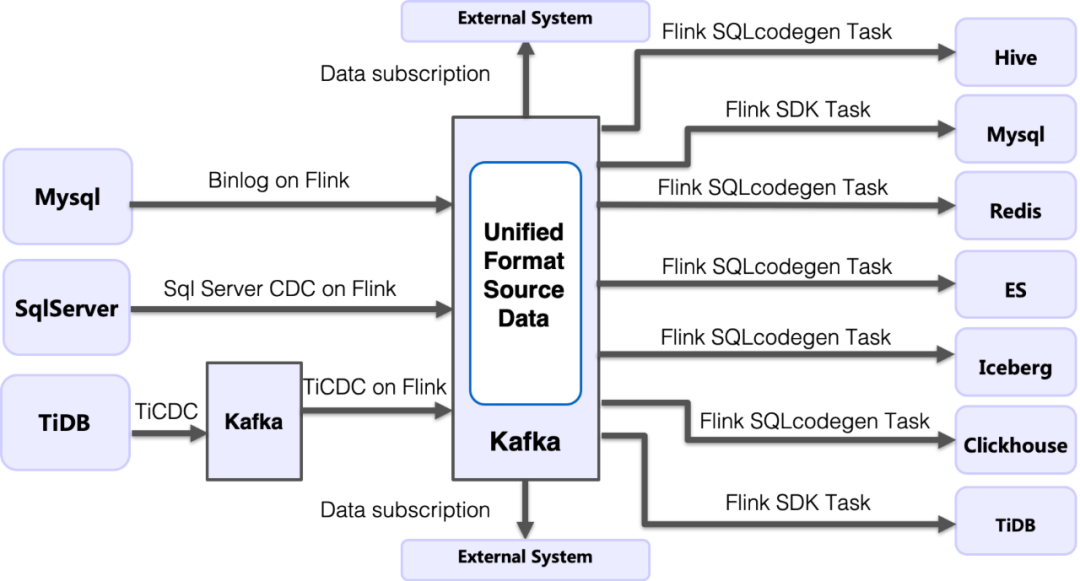
传输任务类型与构成
接入任务,负责从数据源实时接入 Changelog Stream 并处理成统一的格式写入 Kafka 中,每个表只会对用唯一个接入程序,作为公共数据资产,被下游程序进行使用和消费 分发任务, 负责读取公共的 Kafka 数据,并将数据写入指定的存储中,用户根据自己的需求去使用,拥有分发任务的所有权
四、基于 Flink 的 Binlog 接入 SDK
在这些接入和分发 SDK 中,Binlog 接入 SDK 是比较有难度的一个,下面我们以 Binlog 接入 SDK 为例,剖析接入 SDK 的主体设计思路和开发过程。
Stage 拆解

Binlog Source
保证 Source 端处理性能 保证 source 是可回溯的 保证 Mysql Transaction 的完整性
UnifiedFormatTransform
内嵌 Parser,用于解析 DDL SQL 解析出现的所有 DDL,根据解析的 DDL 内容更新内置的 Schema,并更新到 Flink 状态中 生成 DDL 对应的数据发送到下游
Kafka Sink
其他优化
gtid 支持与一键主从切换 程序运行信息定期备份到外部存储 Binlog 同步任务相关的监控指标覆盖
五、平台使用
用户在传输平台,只需要完成必要配置的设定,即可完成传输任务的创建和数据的使用,比较简单。
接入任务
分发任务
■ 字段筛选
六、总结与展望
实践证明,我们选择基于 Flink 进行输出传输系统的开发,是个明智且正确的决定。在最小的开发成本下,从功能和效率及可维护性上,完全解决了之前遗留的问题,全面提升了之家接入/分发/数据订阅的效率和用户体验,也提升了我们在数据传输方面的技术能力。