
数据格式校验之正则表达式
共 1992字,需浏览 4分钟
·
2021-11-24 07:41

前言
现如今随着互联网需求的不断发展,用户体验显得越来越重要,自然而然,系统的各项性能要求也越来越多,其中有一个体现系统稳定性的特性——系统的健壮性要求也是水涨船高。
作为一名开发人,我们对于健壮性的最大贡献就是要尽可能减少NPE(空指针)情况的出现,毕竟一旦系统出现NPE异常,前台便会收到500错误响应,极其影响用户体验,所以为了避免这种情况的出现,提升系统的健壮性,我们在实际业务中经常需要对前端的各种数据进行校验,一般我们都会用到if-else的方式,甚至更粗暴的方式,虽然有一种数据校验的方式即方便又很优雅,但在实际开发中却似乎并不受大家的青睐,今天我想把这种方式介绍给各位小伙伴。
正则表达式
正则表达式是一种匹配规则,被广泛应用在各种系统中,其本身与语言无关,除了java、python等语言支持外,linux更是原生支持正则表达式,甚至连我们日常用到的各种编辑器、IDE都是支持正则表达式的。当然,最重要的是在,掌握了这种技能,可以极大提升你的工作效率,让你工作更高效。好了,废话少说,我们先看下正则表达式的基本语法规则。
基本规则
以下规则来源菜鸟教程,网上也都能搜到。
非打印字符
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列:
| 字符 | 描述 |
|---|---|
\cx | 匹配由x指明的控制字符。例如,\cM 匹配一个Control-M 或回车符。x的值必须为 A-Z或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
\f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
\n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
\r | 匹配一个回车符。等价于\x0d 和 \cM。 |
\s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\n\r\t\v]。注意 Unicode正则表达式会匹配全角空格符。 |
\S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
\t | 匹配一个制表符。等价于 \x09 和 \cI。 |
\v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
这里的特殊字符就是在正则表达式中有特殊含义中的字符,如果需要匹配特殊字符,需要进行转义
| 特别字符 | 描述 |
|---|---|
$ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline属性,则$ 也匹配 '\n'或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用\(和 \)。 |
* | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用\*。 |
+ | 匹配前面的子表达式一次或多次。要匹配+字符,请使用\+。 |
. | 匹配除换行符\n 之外的任何单字符。要匹配. ,请使用\.。 |
[ | 标记一个中括号表达式的开始。要匹配[,请使用\[。 |
? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
\ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如,'n'匹配字符'n'。'\n'匹配换行符。序列 '\\'匹配 "\",而'\('则匹配 "("。 |
^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配^字符本身,请使用\^。 |
{ | 标记限定符表达式的开始。要匹配{,请使用\{。 |
`|| 指明两项之间的一个选择。要匹配 |,请使用 |`。 |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有* 或 + 或 ?或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:
| 字符 | 描述 |
|---|---|
* | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
+ | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配"zo"以及"zoo",但不能匹配 "z"。+等价于{1,}。 |
? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。?等价于{0,1}。 |
{n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
{n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
{n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
正则表达式应用
上面我们展示了正则表达式的一些基本匹配规则,接下来我们看下如何在我们的项目中使用正则表达式,完成我们的数据校验,这里我们主要是以java为例。
这里是我们的公用方法:
/**
* 校验数据格式
* @param pattern 正则格式
* @param targetStr 目标值
* @return
*/
private static boolean pattern(String pattern, String targetStr) {
Pattern compile = Pattern.compile(pattern);
Matcher matcher = compile.matcher(targetStr);
return matcher.matches();
}
方法的第一个入参是我们数据的正则表达式,后面是我们要校验的数据
匹配手机号
不知道各位小伙伴有没有好的手机号格式验证方法,反正我见到的除了直接强转成数字,就是正则表达式了,强转的过于暴力了。
String pattern = "^\\d{11}";
String input = "13501234567";
System.out.println(pattern(pattern, input));
我们正则表达式的含义是匹配11位数字,更合理的表达式可以这样写:
String pattern = "^[1]\\d{10}";
运行结果:
true
如果把输入的数据改成9位、12位,第一位不为1,或者包含非数字的其他字符,返回结果均为false
匹配日期
日期格式,我一直觉得是一个很难校验的数据,在日常开发中经常看到小伙伴用try-catch来校验,即直接转换成日期,如果转换失败就返回数据格式错误,但是这种方式不够优雅,过于暴力。
正则表达式才是数据校验yyds
String pattern2 = "^\\d{4}-\\d{1,2}-\\d{1,2}";
String input2 = "2021-6-11";
System.out.println(pattern(pattern2, input2));
上面的正则表达式可以匹配2021-6-1或者2021-06-12这样的日期格式,当然对于2021-00-00这样的日期也是可以匹配的,这个日期格式在java中也是合法的日期,对应的日期是2020-11-30。
是不是很方便也很简单,即优雅,又友好,它不香吗?
总结
正则表达式真的用起来很方便,比如批量替换啥的,用正则表达式,简直不要太方便,比如最流行的IDEA、常用的编辑器:
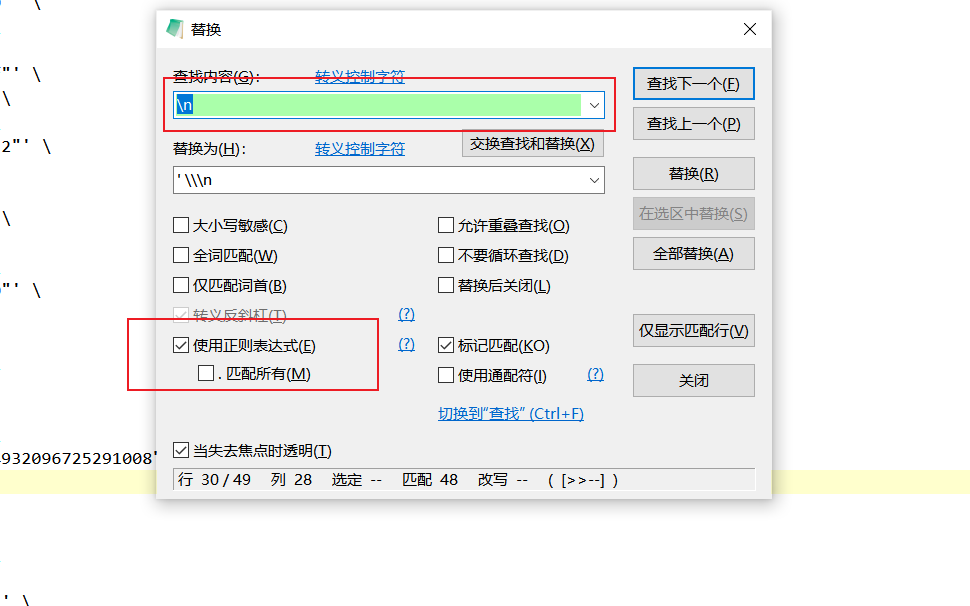
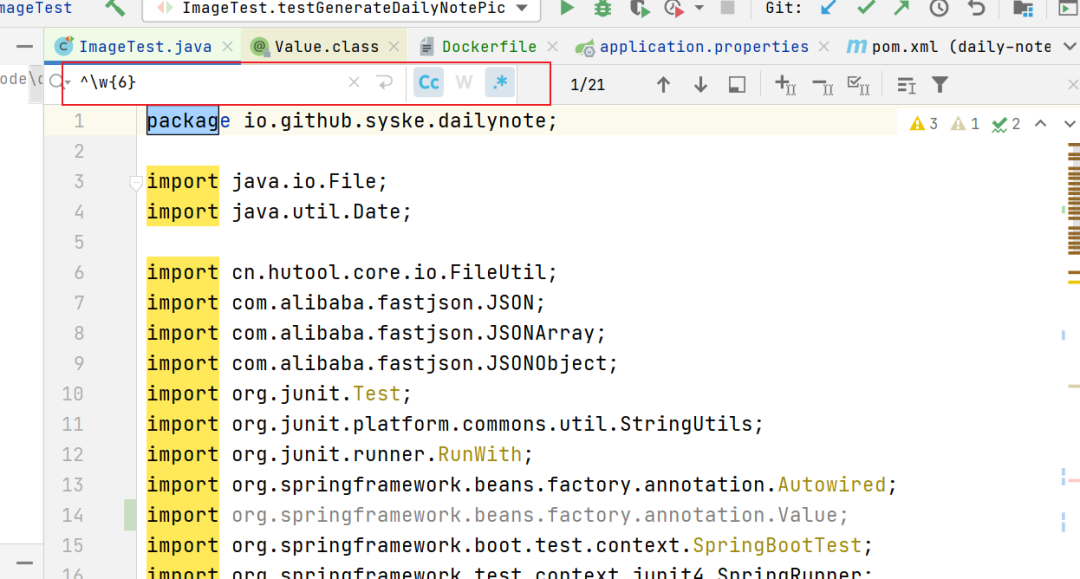
关于正则表达式的展示,就先分享这两个,其他的参照上面的规则,应该可以写出来,今天算是给大家校验数据提供一种思路,大家可以在自己的工作中用起来,毕竟正则表达式的应用太广泛了。好了,今天就到这里吧,各位小伙伴端午快乐。
- END -