
数据分析面试考点!敲黑板!划重点!
共 2141字,需浏览 5分钟
·
2020-11-25 17:09

xyjisaw | 作者
OmegaXYZ | 来源
https://www.omegaxyz.com/2020/02/17/data-analysis-interview/
1
业务逻辑
数据分析遵循一定的流程,不仅可以保证数据分析每一个阶段的工作内容有章可循,而且还可以让分析最终的结果更加准确,更加有说服力。一般情况下,数据分析分为以下几个步骤:
业务理解,确定目标、明确分析需求
数据理解,收集原始数据、描述数据、探索数据、检验数据质量
数据准备,选择数据、清洗数据、构造数据、整合数据、格式化数据
建立模型,选择建模技术、参数调优、生成测试计划、构建模型
评估模型,对模型进行较为全面的评价,评价结果、重审过程
成果部署,分析结果应用
2
特征工程
包括特征提取、特征构建、特征选择。特征工程的目的是筛选出更好的特征,获取更好的训练数据。因为好的特征具有更强的灵活性,可以用简单的模型做训练,更可以得到好的结果。
3
数据采集 / 清洗 / 采样
1. 数据采集
数据采集前需要明确采集哪些数据,一般的思路为:哪些数据对最后的结果预测有帮助?数据我们能够采集到吗?线上实时计算的时候获取是否快捷?
举例1:我现在要预测用户对商品的下单情况,或者我要给用户做商品推荐,那我需要采集什么信息呢?
店家:店铺的评分、店铺类别……
商品:商品评分、购买人数、颜色、材质、领子形状……
用户:历史信息(购买商品的最低价最高价)、消费能力、商品停留时间……
2. 数据清洗
数据清洗也是很重要的一步,机器学习算法大多数时候就是一个加工机器,至于最后的产品如何,取决于原材料的好坏。数据清洗就是要去除脏数据,比如某些商品的刷单数据。
那么如何判定脏数据呢?
简单属性判定:一个人身高3米+的人;一个人一个月买了10w的发卡。
组合或统计属性判定:你要判定一个人是否会买篮球鞋,样本中女性用户85%?
补齐可对应的缺省值:不可信的样本丢掉,缺省值极多的字段考虑不用。
数据清洗标准:
数据的完整性—-例如人的属性中缺少性别、籍贯、年龄等
数据的唯一性—-例如不同来源的数据出现重复的情况
数据的权威性—-例如同一个指标出现多个来源的数据,且数值不一样
数据的合法性—-例如获取的数据与常识不符,年龄大于150岁
数据的一致性—-例如不同来源的不同指标,实际内涵是一样的,或是同一指标内涵不一致
3. 数据采样
采集、清洗过数据以后,正负样本是不均衡的,要进行数据采样。采样的方法有随机采样和分层抽样。但是随机采样会有隐患,因为可能某次随机采样得到的数据很不均匀,更多的是根据特征采用分层抽样。
正负样本不平衡处理办法:
正样本 >> 负样本,且量都挺大 => downsampling
正样本 >> 负样本,量不大 =>
4
数据标准化和归一化
max-min:这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
Z-score:最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。也叫标准差标准化,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:x∗=x−μσ,其中μ为所有样本数据的均值,σ为所有样本数据的标准差。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
5
ROC与AOC
ROC(Receiver Operating Characteristic)曲线即受试者工作特征曲线 (receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve),用来评价一个二值分类器(binary classifier)的优劣。
AUC(Area Under Curve)被定义为ROC曲线下的面积,这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。为什么呢,因为ROC曲线越接近左上角,AUC面积就越大,分类器性能就越好。
6
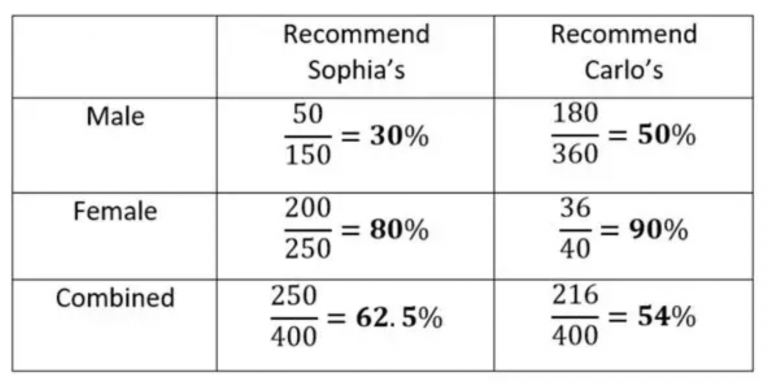
辛普森悖论
分组比较中都占优势的一方,在总评中有时反而是失势的一方。即,数据集分组呈现的趋势与数据集聚合呈现的趋势相反的现象。
如下图,按照性别分组的结果与总体的结果不同。
- END -
本文为转载分享&推荐阅读,若侵权请联系后台删除
后台回复关键字:破解,获取Pycharm 破解版,亲测有效哦 后台回复关键字:自学,获取一份精心整理的 5本 Python 经典用书 后台回复关键字:国庆,获取50本电子书。 后台回复关键字:1109,获取PYTHON进阶书。
