自动驾驶多目视觉感知
来自于点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
来源 | 巫婆塔里的工程师@知乎
转自 | 汽车电子与软件
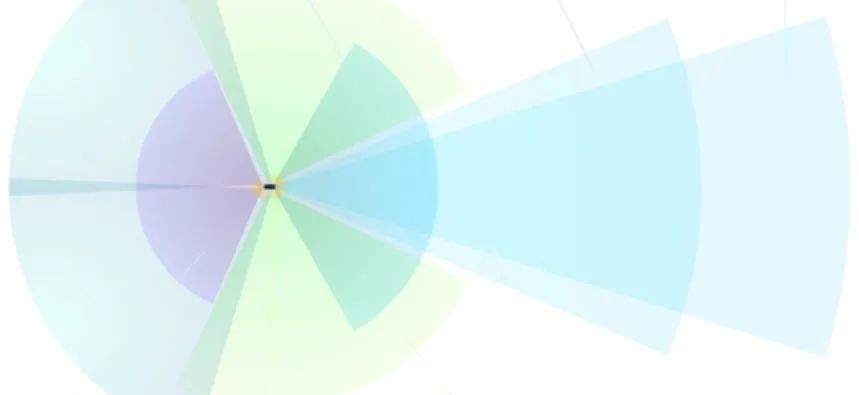
1 前言
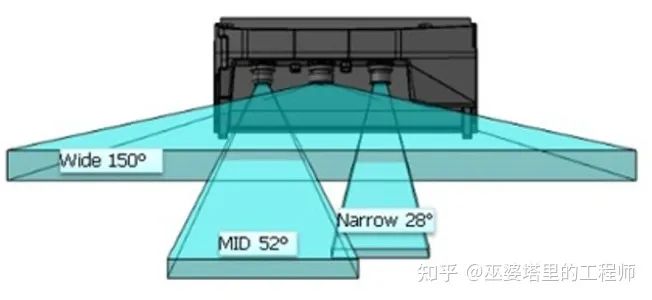
2 Mobileye的三目系统
3 Foresight的四目感知系统
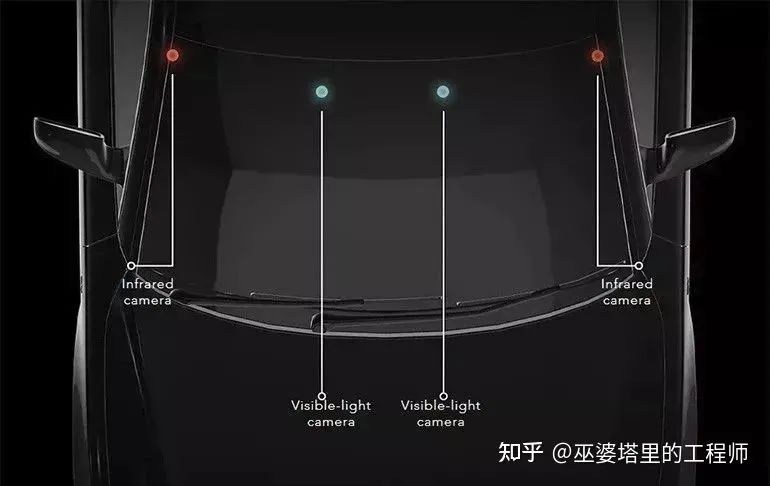
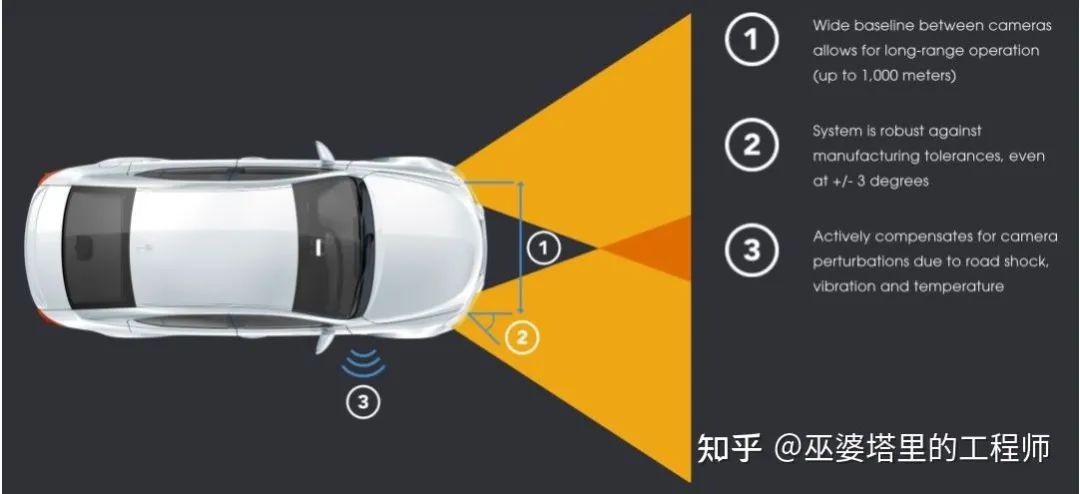
4 Tesla的全景感知系统
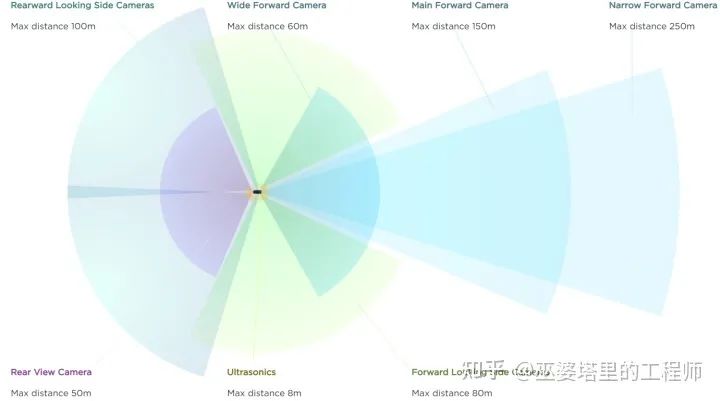
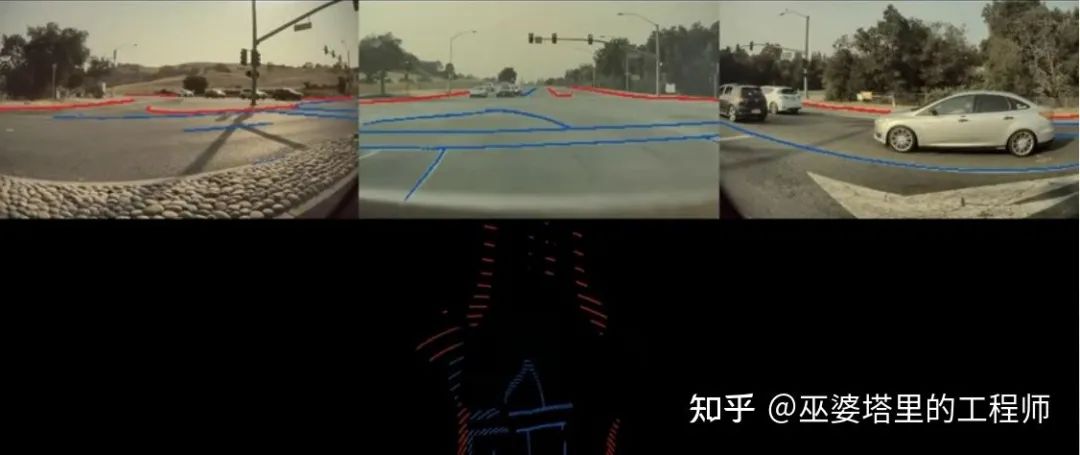

4.1 特征的空间变换

4.2 向量空间中的标注

阅读原文,关注作者知乎!
本文仅做学术分享,如有侵权,请联系删文。
评论

来自于点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
来源 | 巫婆塔里的工程师@知乎
转自 | 汽车电子与软件
阅读原文,关注作者知乎!
本文仅做学术分享,如有侵权,请联系删文。