MapReduce源码解析之MapTask
Mapper 源码
分析了MapReduce提交任务过程中主要的切片计算之后,接下来就要看计算程序到达切片所在数据节点后,该如何进行工作。
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
/**
* The Context passed on to the {@link Mapper} implementations.
*/
public abstract class Context
implements MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
}
/**
* Called once at the beginning of the task.
*/
protected void setup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
/**
* Called once at the end of the task.
*/
protected void cleanup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
* @param context
* @throws IOException
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
}MapTask源码
是否有Reduce
第一步先判断是否有reduce任务,如果没有,那么就单纯只是一个map任务,走map分支。如果有reduce任务,那么就是67%map任务,有33%是排序任务,之前分析过排序对于后续reduce拉取数据的影响极大。排序能够极大的减少reduce任务IO次数。
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, ClassNotFoundException, InterruptedException {
this.umbilical = umbilical;
if (isMapTask()) {
// If there are no reducers then there won't be any sort. Hence the map
// phase will govern the entire attempt's progress.
if (conf.getNumReduceTasks() == 0) {
mapPhase = getProgress().addPhase("map", 1.0f);
} else {
// If there are reducers then the entire attempt's progress will be
// split between the map phase (67%) and the sort phase (33%).
mapPhase = getProgress().addPhase("map", 0.667f);
sortPhase = getProgress().addPhase("sort", 0.333f);
}
}
TaskReporter reporter = startReporter(umbilical);
boolean useNewApi = job.getUseNewMapper();
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
if (useNewApi) {
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
done(umbilical, reporter);
}Run方法
接下来我们就需要看任务运行的细节了。主要过程一般都会包含在try catch代码块中。其中调用了上述Mapper的run方法。整体流程是,初始化输入,map计算,排序,然后输出。
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split);
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
try {
input.initialize(split, mapperContext);
mapper.run(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}获取任务配置
通过获取任务配置,得到Java编译的class文件,后续则可以通过反射来创建我们所写的Mapper类对象。然后会根据客户端输入的参数,获取输入格式化数据类型InputFormat。
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());INPUT_FORMAT_CLASS_ATTR 这个常量就是我们用来指定输入数据类型的 KEY,通过此常量来获取我们的输入参数的配置。
public Class extends InputFormat> getInputFormatClass()
throws ClassNotFoundException;
public Class extends InputFormat> getInputFormatClass()
throws ClassNotFoundException {
return (Class extends InputFormat>)
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}
public static final String INPUT_FORMAT_CLASS_ATTR = "mapreduce.job.inputformat.class";获取到自己相应的split(切片)
// rebuild the input split
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);记录读取器
我们知道map是从切片中一条一条读取数据的,根据上述参数配置,及切片信息获取,我们就可以创建一个对应的记录读取器。因为读取数据的数据类型不一样,记录读取器的读取方式自然也会不一样。因此就会出现各种各样的默认实现类。
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
TextInputFormat获取的是行记录读取器。
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}Map run方法
map的run方法是一个循环读取context记录的过程。实际上就是input中的LineRecordReader来获取一条一条的记录。
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split);
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}输入
LineRecordReader读取下一条记录。
public boolean nextKeyValue() throws IOException, InterruptedException {
long bytesInPrev = getInputBytes(fsStats);
boolean result = real.nextKeyValue();
long bytesInCurr = getInputBytes(fsStats);
if (result) {
inputRecordCounter.increment(1);
}
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
reporter.setProgress(getProgress());
return result;
}读取过程中,一遍判断改行记录又没有值,同时一边赋值记录下来。之后通过getCurrentKey和getCurrentValue来获取当前取得的key和value。其中key对应的就是每一行字符串自己第一个字符面向源文件的偏移量。
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
// We always read one extra line, which lies outside the upper
// split limit i.e. (end - 1)
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
@Override
public LongWritable getCurrentKey() {
return key;
}
@Override
public Text getCurrentValue() {
return value;
}反观初始化
map切片对应
上述过程中,保障分布式计算的代码,实际上就在初始化这一步。通过获取切片位置,以及长度,然后打开相应的文件,同时seek到切片的起始位置。每个map就对应到了自己得切皮上。
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
// open the file and seek to the start of the split
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}切断的数据
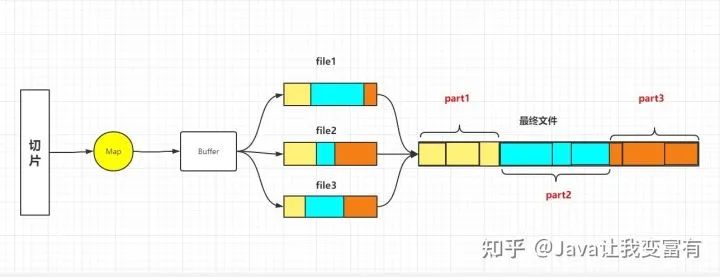
切断数据的解决方式,就是每个不是第一个切片的split,肯定是可能出现第一行数据被截断的。因此就直接读取一行,然后丢弃,从第二行开始读取。而每一个切片读取到最后一行之后,并不直接结束读取,而是去找下一个切片的第一行,把下一个切片丢弃的第一行拼接到自己的最后一行。这样就完成了切断数据拼接的工作,同时还能做到不重复,不丢失。不过此时如果下一个切片在不同的数据节点,那么就需要再远程请求一次,单独为了那一行数据。
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;根据reduce的操作
如下代码可以看到我们曾经提到的分区概念,有多少reduce就会有多少分区(partitions)。每个分区可以对应若干组。
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
collector = createSortingCollector(job, reporter);
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) {
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
}判定分区
判定key的分区采用的哈希算法,和我们学习过的HashMap一样。形同的key的hashcode一定相同,与上Integer的最大值获取非负整数,同时取模分区的大小,那么分区下标一定会落在这个范围内,并且相同的key分区下标将会相同。
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}输出
前边我们知道输入采取的LineRecordReader,输出采用的是MapOutputCollector的collect方法。整个链条如下
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}MapTask的内部私有类
private class NewOutputCollector<K,V>
extends org.apache.hadoop.mapreduce.RecordWriter<K,V> {
private final MapOutputCollector<K,V> collector;
private final org.apache.hadoop.mapreduce.Partitioner<K,V> partitioner;
private final int partitions;
@SuppressWarnings("unchecked")
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
collector = createSortingCollector(job, reporter);
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) {
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
}
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
@Override
public void close(TaskAttemptContext context
) throws IOException,InterruptedException {
try {
collector.flush();
} catch (ClassNotFoundException cnf) {
throw new IOException("can't find class ", cnf);
}
collector.close();
}
}map每次取到key,value的时候,都会调用写入方法,如下所示。
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}而写入方法的内部,调用的写入实现类,在本节内容中是NewOutputCollector。
我们可以看到不仅写入了key和value,同时还写入每个key value的所属分区,最终这些key,value要根据相应的分区号进入相应的reduce。
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}写入缓冲区
最终会由MapOutputBuffer写入缓冲区。同时我们可以看到,key,value会经过序列化放到缓冲区中。
public synchronized void collect(K key, V value, final int partition
) throws IOException {
reporter.progress();
if (key.getClass() != keyClass) {
throw new IOException("Type mismatch in key from map: expected "
+ keyClass.getName() + ", received "
+ key.getClass().getName());
}
if (value.getClass() != valClass) {
throw new IOException("Type mismatch in value from map: expected "
+ valClass.getName() + ", received "
+ value.getClass().getName());
}
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
checkSpillException();
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
final int distkvi = distanceTo(bufindex, kvbidx);
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
}
try {
// serialize key bytes into buffer
int keystart = bufindex;
keySerializer.serialize(key);
if (bufindex < keystart) {
// wrapped the key; must make contiguous
bb.shiftBufferedKey();
keystart = 0;
}
// serialize value bytes into buffer
final int valstart = bufindex;
valSerializer.serialize(value);
// It's possible for records to have zero length, i.e. the serializer
// will perform no writes. To ensure that the boundary conditions are
// checked and that the kvindex invariant is maintained, perform a
// zero-length write into the buffer. The logic monitoring this could be
// moved into collect, but this is cleaner and inexpensive. For now, it
// is acceptable.
bb.write(b0, 0, 0);
// the record must be marked after the preceding write, as the metadata
// for this record are not yet written
int valend = bb.markRecord();
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(
distanceTo(keystart, valend, bufvoid));
// write accounting info
kvmeta.put(kvindex + PARTITION, partition);
kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend));
// advance kvindex
kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity();
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}初始化收集器
看了大部分源码之后,会发现hadoop中什么东西其实都是可以进行自定义,我们可以选择通过参数指定自己的buffer,当然一开始选择默认就可以了。
private <KEY, VALUE> MapOutputCollector<KEY, VALUE>
createSortingCollector(JobConf job, TaskReporter reporter)
throws IOException, ClassNotFoundException {
MapOutputCollector.Context context =
new MapOutputCollector.Context(this, job, reporter);
Class[] collectorClasses = job.getClasses(
JobContext.MAP_OUTPUT_COLLECTOR_CLASS_ATTR, MapOutputBuffer.class);
int remainingCollectors = collectorClasses.length;
for (Class clazz : collectorClasses) {
try {
if (!MapOutputCollector.class.isAssignableFrom(clazz)) {
throw new IOException("Invalid output collector class: " + clazz.getName() +
" (does not implement MapOutputCollector)");
}
Class extends MapOutputCollector> subclazz =
clazz.asSubclass(MapOutputCollector.class);
LOG.debug("Trying map output collector class: " + subclazz.getName());
MapOutputCollector<KEY, VALUE> collector =
ReflectionUtils.newInstance(subclazz, job);
collector.init(context);
LOG.info("Map output collector class = " + collector.getClass().getName());
return collector;
} catch (Exception e) {
String msg = "Unable to initialize MapOutputCollector " + clazz.getName();
if (--remainingCollectors > 0) {
msg += " (" + remainingCollectors + " more collector(s) to try)";
}
LOG.warn(msg, e);
}
}
throw new IOException("Unable to initialize any output collector");
}之前在文章中记录过,缓冲区也是需要我们排序的,而系统默认的排序方式是快速排序,当然我们可以实现自己的排序类。

public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
job = context.getJobConf();
reporter = context.getReporter();
mapTask = context.getMapTask();
mapOutputFile = mapTask.getMapOutputFile();
sortPhase = mapTask.getSortPhase();
spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS);
partitions = job.getNumReduceTasks();
rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw();
//sanity checks
final float spillper =
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100);
indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT,
INDEX_CACHE_MEMORY_LIMIT_DEFAULT);
if (spillper > (float)1.0 || spillper <= (float)0.0) {
throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT +
"\": " + spillper);
}
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException(
"Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb);
}
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
// buffers and accounting
int maxMemUsage = sortmb << 20;
maxMemUsage -= maxMemUsage % METASIZE;
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length;
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer();
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
maxRec = kvmeta.capacity() / NMETA;
softLimit = (int)(kvbuffer.length * spillper);
bufferRemaining = softLimit;
LOG.info(JobContext.IO_SORT_MB + ": " + sortmb);
LOG.info("soft limit at " + softLimit);
LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "; length = " + maxRec);
// k/v serialization
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
// output counters
mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES);
mapOutputRecordCounter =
reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS);
fileOutputByteCounter = reporter
.getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES);
// compression
if (job.getCompressMapOutput()) {
Class extends CompressionCodec> codecClass =
job.getMapOutputCompressorClass(DefaultCodec.class);
codec = ReflectionUtils.newInstance(codecClass, job);
} else {
codec = null;
}
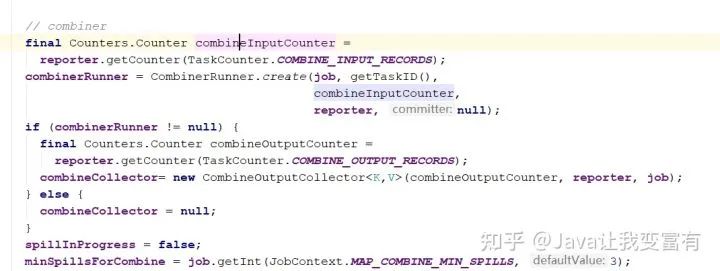
// combiner
final Counters.Counter combineInputCounter =
reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS);
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
if (combinerRunner != null) {
final Counters.Counter combineOutputCounter =
reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS);
combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, job);
} else {
combineCollector = null;
}
spillInProgress = false;
minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3);
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw new IOException("Spill thread failed to initialize",
sortSpillException);
}
}比较器
有了排序方式,我们需要指定对什么东西进行排序。因此就需要用到比较器。如果我们定义了比较器,就用自定义的,如果没有自定义,就取我们曾经设置的key类型的自己的比较器。
public RawComparator getOutputKeyComparator() {
Class extends RawComparator> theClass = getClass(
JobContext.KEY_COMPARATOR, null, RawComparator.class);
if (theClass != null)
return ReflectionUtils.newInstance(theClass, this);
return WritableComparator.get(getMapOutputKeyClass().asSubclass(WritableComparable.class), this);
}合并器
在reduce之前,如果有一些分组的数据聚集在一个分片中,我们可以提前对其进行合并,然后再通过reduce调取合并后的数据。可以极大的减少IO的次数。